【ML系列】简单的二元分类——Logistic回归
对于了解机器学习中二元分类问题的来源与分析,我认为王树义老师这篇文章讲的非常好,通俗且易懂:
http://blog.sciencenet.cn/blog-377709-1121098.html
但王树义老师的这篇文章并未详细的展开说明二元分类的具体实现方法,只是在宏观上的一个概述。在阅读这篇文章后,我便心生实现一个简单的二元分类并把前后过程记录下来的念头,所以本篇的主体以算法实现为主,略带分析,并不会涉及太多的理论知识。本篇以线性Logistic Regression为主要的模型工具来做一个简单的二元分类,关于Logistic Regression理论部分,我认为下面这篇文章讲的不错:
Logistic Regression(逻辑回归)原理及公式推导
数据生成与标记
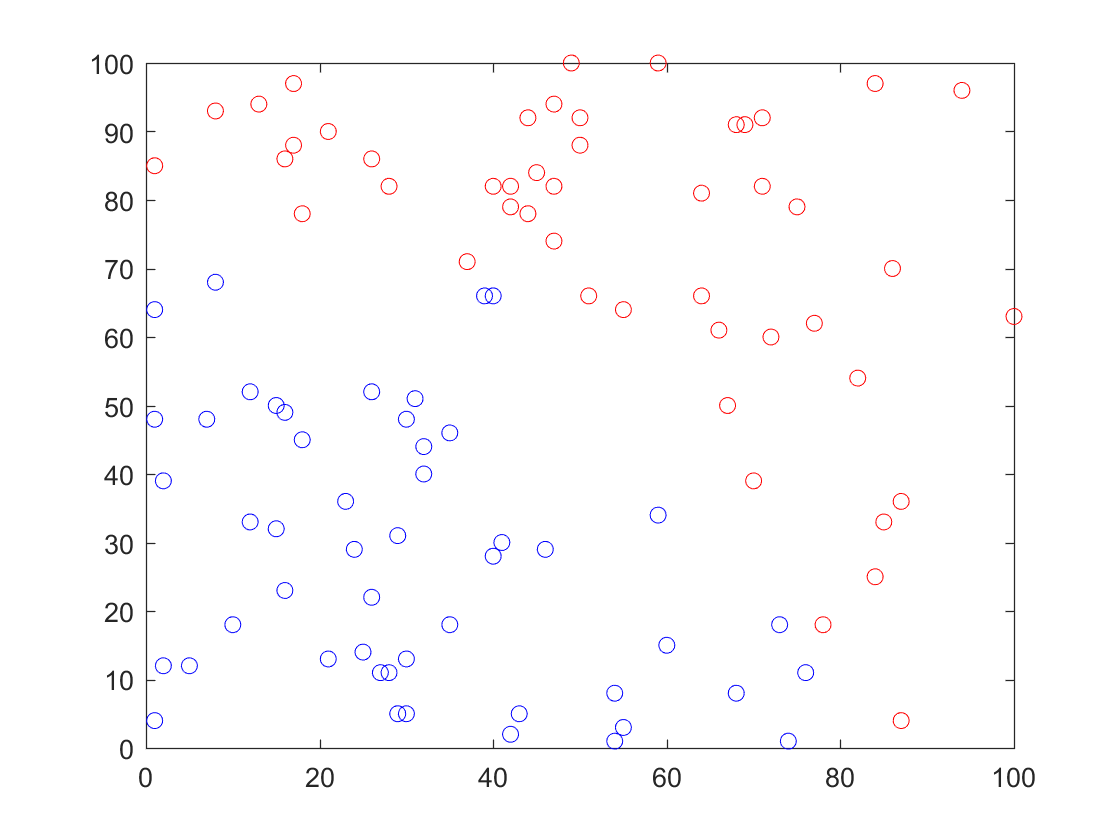
Logistic Regression也是有监督学习中的一种,需要一定的训练样本,并且这些训练样本还需要预先进行标记分类。在本次试验中,从坐标(0, 0)到坐标(100, 100)这么一个矩形范围内随机生成100个整数坐标$(X_1, X_2)$作为训练样本,其中$ 0\leq X_1 \leq 100,\ \ 0\leq X_2 \leq 100 $。在生成样本的同时进行标记,为了使得样本分类显得不那么规整,又分布比较均匀,设定当样本坐标满足$ (X_{1}^2 + X_{2}^2) <80^2 $标记为0,否则标记为1。这么做恰好满足了刚刚提到的样本生成的两个要求,分界线为弧线,所以在样本量不大的情况下就不会显得那么规整,半径为80的1/4圆又恰好将100x100的矩形分为面积相等的两个部分。下图为生成并标记好的样本数据:
Cost Function计算
Cost Function在这里是我们判断模型准确性的主要依据,来源于单个样本Loss Function的总和平均,也就是说如果训练样本有M个,Cost Funciton可以写为:
$$ \mathrm{Cost} = \frac{1}{M} \sum \mathrm{Loss} $$
但是实际上有没有平均或者求和前的系数为多少对于后面权重参数的更新是没有影响的,所以有时为了方便后续的计算,会对这个系数做一些改变。这里需要着重提及的是Loss Function的计算。
在应用与二元分类的Logistic Regression中,常用的Loss Function主要是两种,方差$Loss_{Sq}$与交叉熵$Loss_{Lg}$,分别可以写为:
$$ Loss_{Sq} = (H(X, \theta) - y)^2 \\ Loss_{Lq} = y\ln(H(X, \theta)) + (1 - y)\ln(1 - H(X, \theta))$$
下面我们会简单的比较一下这两种Loss Fucntion计算方法的优劣,不过这里需要先提一下的是Loss Function本身,$Y$是样本标记矩阵,函数$H(X, \theta)$中的$X$为输入样本矩阵,$\theta$为权重矩阵。本质上来说,$H(X, \theta)$是训练样本关于权重$\theta$的线性回归再映射到sigmoid函数。这一部分的解释在Logistic Regression(逻辑回归)原理及公式推导 中已经被描述的很清楚了,便不再赘述。
梯度下降法
Cost Function计算出来后,这个二元分类问题就转变为了一个无约束优化问题,即找寻使得Cost尽可能小的权重矩阵$\theta$,梯度下降法便是一个常用的解决无约束优化问题的方法。关于梯度下降法的具体理论与简单实现,我认为这篇文章写的很详细,可以参考:深入浅出--梯度下降法及其实现。
梯度下降法的核心部分用Matlab描述出来实际上是很简单的:
while(True)
theta = theta - alpha * gradient
[cost, gradient] = CostFunction(theta, X, Y)
end
这算法中的gradient便是Cost Function关于权重$\theta$的梯度,如果用数学表示出来,设$J$为Cost Fucntion,则有(假设样本维度为3):
$$\mathrm{gradient} = \nabla J = \left< \frac{\partial J}{\partial \theta_1}, \frac{\partial J}{\partial \theta_2}, \frac{\partial J}{\partial \theta_3} \right>$$
这里尝试计算一下Loss Function方差形式的梯度,交叉熵形式的梯度计算较为复杂,不过原理相同,就不再展开了,这篇文章给出了详细的推导过程,可以参考:https://www.cnblogs.com/alfred2017/p/6627824.html
$$ \begin{align} \nabla Loss_{Sq}(x) & = \nabla (H(x, \theta) - y)^2 \\ & = 2(H(x, \theta) - y) \nabla H(x, \theta)\\ & = 2(H(x, \theta) - y) \frac{\exp(-\theta^T x)}{(1 + \exp(-\theta^T x))^2} \left< x^{(1)}, x^{(2)}, x^{(3)} \right> \end{align}$$
在这里关于样本x的函数$\frac{\exp(-\theta^T x)}{(1 + \exp(-\theta^T x))^2}$的存在予否实际上并不影响梯度下降的方向,这个函数在实数域上始终大于0,如在gradient的计算中考虑该项,则影响的仅仅是学习速率,最终结论并不会有太大的的变化,所以实际应用中可将其舍弃或看作为常数。
如果将这里的Loss Function以求和方式替换为Cost Function,则可以将其写为:
$$\begin{align} \nabla Cost_{Sq} & = \sum_{i = 1}^{i = M} \nabla Loss_{Sq}(x_i)\\ & =2 \sum \frac{\exp(-\theta^T x_i)}{(1 + \exp(-\theta^T x_i))^2} (H(x_i, \theta) - y_i) \left< x^{(1)}_i, x^{(2)}_i, x^{(3)}_i \right>\\& = 2K X^T (H(x_i, \theta) - Y) \end{align}$$
分类结果
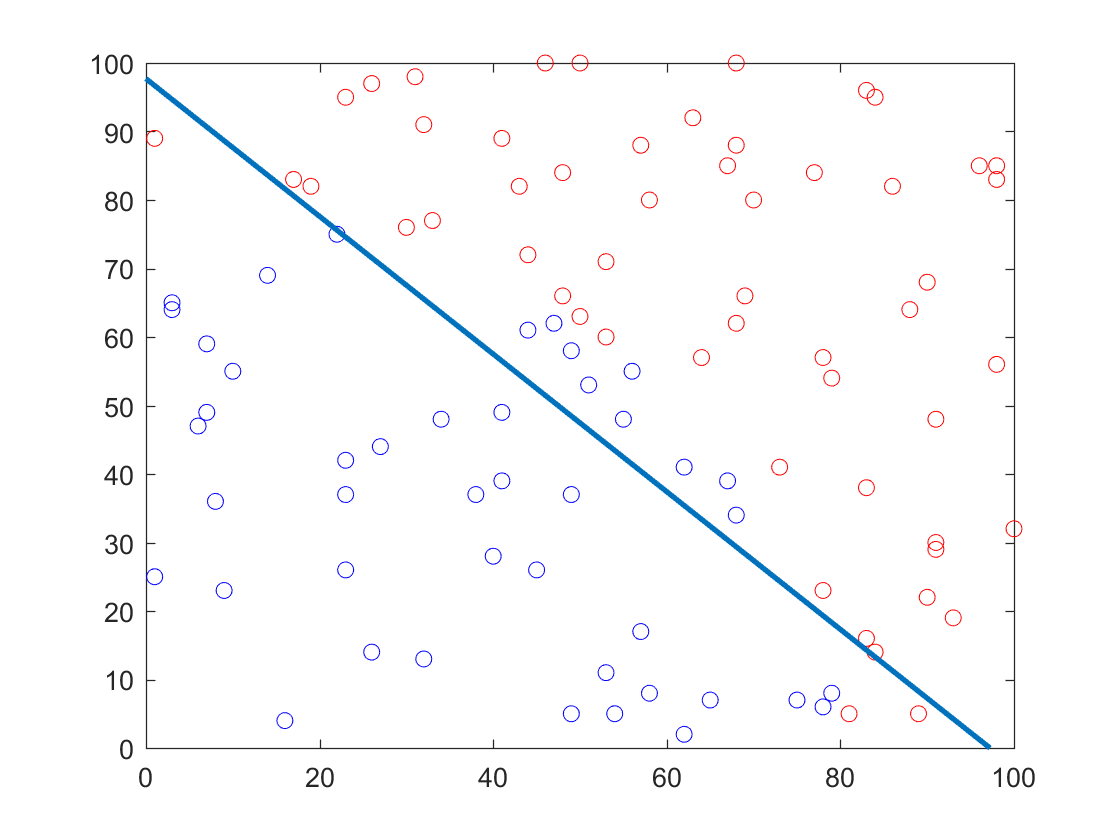
中间蓝线为分界线
这条分界线是以sigmoid函数阈值为0.5计算出来的,也就是说落在分界线上的样本坐标点应当满足$H(x, \theta) = 0.5$,也意味着满足条件$\theta^TX = 0$,这里样本的特征维度皆为3,所以该条件可以写为(样本特征的第一维度皆为值为1的Bias,即$x_1 = 1$。$x_2$与$x_3$为样本坐标点),这同时也是分界线的函数表达式:
$$ \theta_1 + \theta_2 x_2 + \theta_3 x_3 = 0 $$
【ML系列】简单的二元分类——Logistic回归的更多相关文章
- SPSS数据分析—二分类Logistic回归模型
对于分类变量,我们知道通常使用卡方检验,但卡方检验仅能分析因素的作用,无法继续分析其作用大小和方向,并且当因素水平过多时,单元格被划分的越来越细,频数有可能为0,导致结果不准确,最重要的是卡方检验不能 ...
- Logistic回归分析之多分类Logistic回归
Logistic回归分析(logit回归)一般可分为3类,分别是二元Logistic回归分析.多分类Logistic回归分析和有序Logistic回归分析.logistic回归分析类型如下所示. Lo ...
- SPSS数据分析—多分类Logistic回归模型
前面我们说过二分类Logistic回归模型,但分类变量并不只是二分类一种,还有多分类,本次我们介绍当因变量为多分类时的Logistic回归模型. 多分类Logistic回归模型又分为有序多分类Logi ...
- 二分类Logistic回归模型
Logistic回归属于概率型的非线性回归,分为二分类和多分类的回归模型.这里只讲二分类. 对于二分类的Logistic回归,因变量y只有“是.否”两个取值,记为1和0.这种值为0/1的二值品质型变量 ...
- ML.NET 示例:二元分类之信用卡欺诈检测
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
- ML.NET 示例:二元分类之用户评论的情绪分析
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
- ML.NET 示例:二元分类之垃圾短信检测
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
- SAS学习笔记36 二分类logistic回归
这里所拟合模型的AIC和SC统计量的值均小于只有截距的模型的相应统计量的值,说明含有自变量的模型较仅含有常数项的要好 但模型的最大重新换算 R 方为0.0993,说明模型拟合效果并不好,可能有其他危险 ...
- 过拟合/欠拟合&logistic回归等总结(Ng第二课)
昨天学习完了Ng的第二课,总结如下: 过拟合:欠拟合: 参数学习算法:非参数学习算法 局部加权回归 KD tree 最小二乘 中心极限定律 感知器算法 sigmod函数 梯度下降/梯度上升 二元分类 ...
随机推荐
- Redhat7.2 ----team网卡绑定
我先声明一下,team和bonding是一样的作用,只不过team多了几项功能bonding没有, 做team我们要最少准备两个网卡,我们这里主要显示主备模式. 首先我们先把网卡配置文件删除 nmcl ...
- Ionic3项目实践记录
Ionic3首次项目实践记录 标签(空格分隔): Angular Ionic Ionic3踩坑 1. 路由懒加载(lazy load) 如果设置了懒加载,就必须全部懒加载(包括TabsPage),否则 ...
- MySQL+MyCat分库分表 读写分离配置
一. MySQL+MyCat分库分表 1 MyCat简介 java编写的数据库中间件 Mycat运行环境需要JDK. Mycat是中间件.运行在代码应用和MySQL数据库之间的应用. 前身 : cor ...
- Centos 批量分发脚本
## Centos / ## #!/bin/sh file="$1" remotedir="$2" filename=$(|awk -F '/' '{print ...
- laravel when 的用法
当你在使用where语句有前提条件时,比如某值为1的时候才执行where子句,否则不执行,这个时候,laravel5.5新出了一个简便方法when($arg,fun1[,fun2]). 具体用法如下: ...
- 利用RTTI实现Delphi的多播事件代理研究
我们知道Delphi的每个对象可以包含多个Property,Property中可以是方法,例如TButton.OnClick属性.Delphi提供的仅仅是 一对一的设置,无法直接让TButton.On ...
- C++ —— 非类中使用const定义常量的初始化,以及#define和typedef的区别
总结一下在非类中使用const关键字定义常量时的初始化问题,亲测VS2015.顺便记录#define宏和typedef的区别. 1 首先对const声明的常量的初始化做简单小结: , w2 = , w ...
- bmob关联表
var DDB_User = Bmob.Object.createWithoutData("DDB_User", "b2fd2fe68f"); // var T ...
- 20155217 《Java程序设计》第三次实验报告
20155217 <Java程序设计>第三次实验报告 实验内容 XP基础 XP核心实践 相关工具 实验要求 没有Linux基础的同学建议先学习<Linux基础入门(新版)>&l ...
- # 20155224 课堂实践 MyOD
20155224 课堂实践 MyOD 要求 编写MyOD.java 用java MyOD XXX实现Linux下od -tx -tc XXX的功能 提交测试代码和运行结果截图,加上学号水印,提交码云代 ...