Packet filtering with Linux & NAT
http://www.linuxfocus.org/ChineseGB/May2003/article289.shtml
Gateway, Proxy-Arp 和 Ethernet Bridge ?
过滤机构可以被考虑成一张能够过滤有害的数据包的网。最重要要的是找到合适大 小的网孔和安装他的正确位置。
防火墙在网络中的位置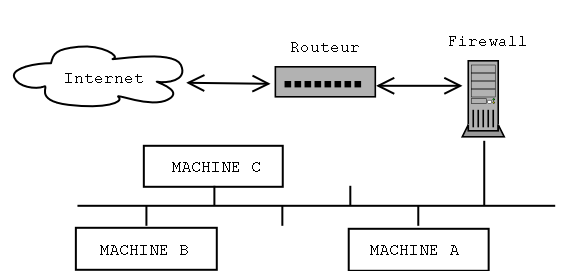
为了能够完全的过滤数据包,这个过滤机构必须无缝的插入他所要保护的网络和“其 余的世界”之间。在实践上,这个可以用一台带有两块网络接口(通常是以太网卡)的 设备来完成 ,一个连接内部的网络,另一块连接外部作为路由转发。这种方式,通信 将不得不通过防火墙,这样防火墙可以阻止他们或不依照他们的内容进行发送。
设备运行过滤机构可以被配置成3种不同的方式:
- "simple" Gateway: 这是最普通的配置。设备被用作两个网络或子网之间的网关。在本地网络内的电脑将使 用防火墙代替他们的默认路由。
- "Proxy-ARP" Gateway: 前面那个配置暗示着把一个网络划分成两个子网,这个 会造成一半可利用的 ip 地址失效了。这是有点恼人的。举个例子,一个16个地址的子 网(28位子网掩码),除去网络地址和广播地址只有14个是有效的,子网添加一位,有 效地址将从14减少到6(8个ip减去网络地址和广播地址)。当你不能够接受失去一半有 效ip地址的情况,你可以使用这种技术,我们将会在稍后的文章里解释他。此外,这种 技术不需要对网络中存在的路由器和被保护的电脑做的任何改变。
- Ethernet bridge: 作为一个以太网网关安装 (不是ip网关),使过滤机构对于 其他设备来说是透明的。因此不分配ip地址给以太网接口是妥当的。于是,设备将不会 被ping,traceroute等工具发现。让我们注意一个数据包过滤执行,在2.4.x内核还 还没完成前提下,基于这个端口的特性需要2.2.x的内核。
过滤基本规则
既然我们知道什么地方安装过滤器,那么我们必须定义什么应该阻止什么应该接受。
这里有两种方式去配置一个过滤器:
- 好的方法:没有数据被允许通过,除了规则允许的。
- 坏的方法:(不幸的是经常被使用)明确地阻止被禁止数据包,所有的数据包被接受。
这有一个简单的解释:在第一种情况,遗忘规则导致服务不完全工作或根本不工作。通 常,这会被很快的注意到,然后添加适当的规则使服务再运行起来。
在第二中情况,遗忘一个规则会造成一个潜在的弱点,如果我们去找,很难去发现...
Netfilter
在linux 2.4内核上使用的最多的包过滤软件是Netfilter:它很好的取代了使 用在2.2内核的‘ipchains’。Netfilter由两部分组成:内核支持这需要编译你的 内核和在你系统中可用到的‘iptables’命令
安装实例
一个实例的注释比一段长时间的演讲要好的多,下面我们将描述怎样去安装和配置 一个过滤器设备。首先,设备要先配置成一个网关,使用Proxy-ARP来限定ip地址的 数量,我们将配置过滤系统。
著者偏好选择了Debian发布版来构建一个这样的系统,任何linux发行版都可以。
首先,检查你的内核已经支持Netfilter。如果是的,引导信息将包含:
ip_conntrack (4095 buckets, 32760 max)
ip_tables: (c)2000 Netfilter core team
另外,当Netfilter支持被激活后你不得不反编译内核。相应的选项将会在 "Networking Options"菜单里的"Network Packet Filtering" 子菜单里找到。从"Netfilter Configuration"选项,选择你需要的。 如果不能确定,你可以全部选择。此外,最好把Netfilter包含至内核,而不是作为加 载模块。如果因为一些原因或者Netfilter一个模块出错或不能加载,过滤器将不能工 作,我们不更多的谈论关于这么做所冒的风险了。
你也应该安装‘iproute2’包(这在最后是不必要做的,但是我们的实例将使 用从它允许我们建立配置脚本文件开始。)对于Debian,‘apt-get install iproute’ 命令足够了。
其他的发行版,获得相应的软件包。用通常的方法,或从源程序安装。你可以在下面的 地址下载到相应的软件包:
ftp://ftp.inr.ac.ru/ip-routing/
现在对两块以太网卡配置。我们必须注意Liunx的内核,自动检测硬件程序到检测 网络卡的这一步时就会发现它。可是,仅仅第一块被探测到。
一个简单的解决方案是在lilo.conf文件里添加一句话:
append="ether=0,0,eth1"
现在,我们配置以太网接口。我们选择对两块网卡使用同一个ip地址的方法,因而 可以节约一个地址。
我们假定有一个10.1.2.96/28的子网。它的地址从10.1.2.96到10.1.2.111 路由器的地址是10.1.2.97,我们的过滤器设备的地址的10.1.2.98。eth0 接口之间如果没有通过hub或switch相连,那么将通过RJ45双绞线直接连接路由器; eth1接口将连接hub或switch, 通过他它到达本地网络设备。
因此,两个接口将会被配置成下列参数:
address : 10.1.2.98
netmask : 255.255.255.240
network : 10.1.2.96
broadcast: 10.1.2.111
gateway : 10.1.2.97
接下来,我们使用下面的脚本,它必须在网卡初始化配置以后运行。
net.vars: configuration variables PREFIX=10.1.2
DMZ_ADDR=$PREFIX.96/28
# Interface definitions
BAD_IFACE=eth0
DMZ_IFACE=eth1
ROUTER=$PREFIX.97 net-config.sh: network configuration script #!/bin/sh
# Comment out the next line to display the commands at execution time
# set -x
# We read the variables defined in the previous file
source /etc/init.d/net.vars
# We remove the present routes from the local network
ip route del $PREFIX.96/28 dev $BAD_IFACE
ip route del $PREFIX.96/28 dev $DMZ_IFACE
# We define that the local network can be reached through eth1
# and the router through eth0.
ip route add $ROUTER dev $BAD_IFACE
ip route add $PREFIX.96/28 dev $DMZ_IFACE
# We activate Proxy-ARP for both interfaces
echo 1 > /proc/sys/net/ipv4/conf/eth0/proxy_arp
echo 1 > /proc/sys/net/ipv4/conf/eth1/proxy_arp
# We activate the IP forwarding to allow the packets coming to one card
# to be routed to the other one.
echo 1 > /proc/sys/net/ipv4/ip_forward
让我们返回Proxy-ARP机制对我们的配置所必需的。
当一个设备在同一个网段里同另一台设备会话时,他需要知道以太网地址(或者MAC地 址或者硬件地址)相应的ip地址。当源设备广播请求”ip地址位1.2.3.4的MAC地址是 什么?”目标设备必须回答。
这里有一个“会话”的实例,是通过tcpdump检测到的:
- the request: the machine 172.16.6.72 asks the MAC address corresponding to the IP address IP 172.16.6.10.
19:46:15.702516 arp who-has 172.16.6.10 tell 172.16.6.72
- the answer: the machine 172.16.6.10 provides its card number.
19:46:15.702747 arp reply 172.16.6.10 is-at 0:a0:4b:7:43:71
通过这个简略的解释将引导我们到达目的地:ARP请求通过广播传播,因此它被限 定在同一个物理网段里。因此,受保护的设备想要去查找路由器MAC地址的请求将会被 过滤器设备阻止。激活着的Proxy-ARP的特色就是解决这个问题,它将传 输ARP请求。
这下一阶段里,你将有一个运行着的网络,它是由一台设备管理整个本地网络和外 网的通信。
现在,我们必须使用Netfilter建立过滤。
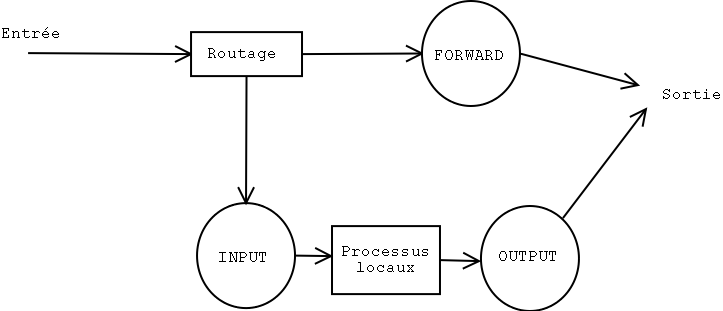
Netfilter允许直接对经过的数据包有所行动。在基本配置里,数据包被3条规则链管理:
- INPUT:数据包通过一个接口进来。
- FORWARD:把所有的数据包从一个接口转发到另一个接口。
- OUTPUT:数据包通过一个接口出去。
‘iptables’命令允许对这些链添加,改变或者移除规则从而修改过滤器的动作。
此外,每一个链有一个默认的策略,换句话说,它知道当一个数据包没有规则匹配时该 怎么处理。
当前有四个选项:
- ACCEPT:允许通过数据包。
- REJECT:拒绝数据包通过,关联的错误信息被传送(ICMP端口不能到达,TCP重置 关于这些的),
- LOG:把数据包记录写在syslog。
- DROP:忽略数据包,不发送回答。
数据流通过标准链
这里有一些操作整个链常用到的iptables选项。我们将在稍后解释他们:
-N:创建一条新链。
-X:移除一条空链。
-P:改变一条链的默认策略。
-L:列出一条链的规则。
-F:清空一条链里所的规则。
-Z:清除已经通过这条链的字节和数据包包的计算器。
修改一条链,下面的命令将会有用的:
-A:添加一条规则在链的最后。
-I:插入一条新规则在链的给定位置。
-R:取代一条给定规则。
-D:删除链里的规则,可以使用规则的编号或它的具体描述。
让我们看一个简单的实例:我们将阻止对给定设备PING回应(这是一个'echo-reply' 类型的ICMP数据包)。
首先,让我们检测能"ping"通所给定的设备:
# ping -c 1 172.16.6.74
PING 172.16.6.74 (172.16.6.74): 56 data bytes
64 bytes from 172.16.6.74: icmp_seq=0 ttl=255 time=0.6 ms --- 172.16.6.74 ping statistics --- 1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.6/0.6/0.6 ms
现在,我们对INPUT链添加一条规则,这将截取来自172.16.6.74('-s 172.16.6.74') 的ICMP-Reply数据包('-p icmp --icmp-type echo-reply')这些数据包将会被 忽略('-j DROP')。
# iptables -A INPUT -s 172.16.6.74 -p icmp --icmp-type echo-reply -j DROP
让我们再PING那个设备:
# ping -c 3 172.16.6.74
PING 172.16.6.74 (172.16.6.74): 56 data bytes --- 172.16.6.74 ping statistics --- 3 packets transmitted, 0 packets received, 100% packet loss
这和我们所期望的一样,回应没有通过。我们检查已经被阻止的3个回 应。(3个数据包共252字节)
# iptables -L INPUT -v
Chain INPUT (policy ACCEPT 604K packets, 482M bytes)
pkts bytes target prot opt in out source destination
3 252 DROP icmp -- any any 172.16.6.74 anywhere
如果想返回到初始状态,我们要做的仅仅是移除INPUT链里的第一条规则:
# iptables -D INPUT 1
我们再PING一次:
# ping -c 1 172.16.6.74
PING 172.16.6.74 (172.16.6.74): 56 data bytes
64 bytes from 172.16.6.74: icmp_seq=0 ttl=255 time=0.6 ms --- 172.16.6.74 ping statistics --- 1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.6/0.6/0.6 ms
#
运行了!
你可以对3条存在链添加其他的链(这3条链你无论如何不能移除),使通信通过他 们。这是有用,举个例子,可以避免在不同的链里重复规则。
让我们设置一个最小化的防火墙所必需的规则。他将允许ssh,域(DNS),http, smtp服务和其他一些无关紧要的。
为了简单化,将设置命令写在shell脚本比配置更容易一点。当这个脚本设立一个新的 规则前应当清空当前配置。这里有一个小诀窍去运行脚本,就是在配置没有副本规则下 被激活。
rc.firewall #!/bin/sh # Flushing out the rules
iptables -F
iptables -F INPUT
iptables -F OUTPUT
iptables -F FORWARD # The chain is built according to the direction.
# bad = eth0 (outside)
# dmz = eth1 (inside)
iptables -X bad-dmz
iptables -N bad-dmz
iptables -X dmz-bad
iptables -N dmz-bad
iptables -X icmp-acc
iptables -N icmp-acc
iptables -X log-and-drop
iptables -N log-and-drop # Specific chain used for logging packets before blocking them
iptables -A log-and-drop -j LOG --log-prefix "drop "
iptables -A log-and-drop -j DROP # The packets having the TCP flags activated are dropped
# and so for the ones with no flag at all (often used with Nmap scans)
iptables -A FORWARD -p tcp --tcp-flags ALL ALL -j log-and-drop
iptables -A FORWARD -p tcp --tcp-flags ALL NONE -j log-and-drop # The packets coming from reserved addresses classes are dropped
# and so for multicast
iptables -A FORWARD -i eth+ -s 224.0.0.0/4 -j log-and-drop
iptables -A FORWARD -i eth+ -s 192.168.0.0/16 -j log-and-drop
iptables -A FORWARD -i eth+ -s 172.16.0.0/12 -j log-and-drop
iptables -A FORWARD -i eth+ -s 10.0.0.0/8 -j log-and-drop # The packets belonging to an already established connexion are accepted
iptables -A FORWARD -m state --state INVALID -j log-and-drop
iptables -A FORWARD -m state --state RELATED,ESTABLISHED -j ACCEPT
# The corresponding chain is sent according to the packet origin
iptables -A FORWARD -s $DMZ_ADDR -i $DMZ_IFACE -o $BAD_IFACE -j dmz-bad
iptables -A FORWARD -o $DMZ_IFACE -j bad-dmz
# All the rest is ignored
iptables -A FORWARD -j log-and-drop # Accepted ICMPs
iptables -A icmp-acc -p icmp --icmp-type destination-unreachable -j ACCEPT
iptables -A icmp-acc -p icmp --icmp-type source-quench -j ACCEPT
iptables -A icmp-acc -p icmp --icmp-type time-exceeded -j ACCEPT
iptables -A icmp-acc -p icmp --icmp-type echo-request -j ACCEPT
iptables -A icmp-acc -p icmp --icmp-type echo-reply -j ACCEPT
iptables -A icmp-acc -j log-and-drop # Outside -> Inside chain
# mail, DNS, http(s) and SSH are accepted
iptables -A bad-dmz -p tcp --dport smtp -j ACCEPT
iptables -A bad-dmz -p udp --dport domain -j ACCEPT
iptables -A bad-dmz -p tcp --dport domain -j ACCEPT
iptables -A bad-dmz -p tcp --dport www -j ACCEPT
iptables -A bad-dmz -p tcp --dport https -j ACCEPT
iptables -A bad-dmz -p tcp --dport ssh -j ACCEPT
iptables -A bad-dmz -p icmp -j icmp-acc
iptables -A bad-dmz -j log-and-drop # Inside -> Outside chain
# mail, DNS, http(s) and telnet are accepted
iptables -A dmz-bad -p tcp --dport smtp -j ACCEPT
iptables -A dmz-bad -p tcp --sport smtp -j ACCEPT
iptables -A dmz-bad -p udp --dport domain -j ACCEPT
iptables -A dmz-bad -p tcp --dport domain -j ACCEPT
iptables -A dmz-bad -p tcp --dport www -j ACCEPT
iptables -A dmz-bad -p tcp --dport https -j ACCEPT
iptables -A dmz-bad -p tcp --dport telnet -j ACCEPT
iptables -A dmz-bad -p icmp -j icmp-acc
iptables -A dmz-bad -j log-and-drop # Chains for the machine itself
iptables -N bad-if
iptables -N dmz-if
iptables -A INPUT -i $BAD_IFACE -j bad-if
iptables -A INPUT -i $DMZ_IFACE -j dmz-if # External interface
# SSH only accepted on this machine
iptables -A bad-if -p icmp -j icmp-acc
iptables -A bad-if -p tcp --dport ssh -j ACCEPT
iptables -A bad-if -p tcp --sport ssh -j ACCEPT
ipchains -A bad-if -j log-and-drop # Internal interface
iptables -A dmz-if -p icmp -j icmp-acc
iptables -A dmz-if -j ACCEPT
关于服务质量的几点说明。Linux能够修改ToS("Type of Service")字段,对 一个数据包赋予不同的优先权。举例:下面的命令改善流出的SSH数据包的连接响应。
iptables -A OUTPUT -t mangle -p tcp --dport ssh -j TOS --set-tos Minimize-Delay
用同样的方法,对于FTP连接你可以使用'--set-tos Maximize-Throughput' 选项来改善传输速度。
这就是Netfilter。现在你知道设置一个有效的数据包过滤系统的基础知识。但是, 紧记当涉及安全时防火墙并不是万能药。他仅仅是一种预防。你还需使用强壮的密码, 最新的安全补丁,入侵检测系统等等。
涉及资料
- Proxy-ARP Mini-HOWTO: http://www.linuxdoc.org/HOWTO/mini/Proxy-ARP-Subnet/index.html
- Netfilter: http://netfilter.samba.org/
http://blog.chinaunix.net/uid-26495963-id-3279216.html
点击(此处)折叠或打开
- DEVICE=eth0:0
- IPADDR=192.168.164.100
- NETMASK=255.255.255.0
- ONBOOT=yes
- BOOTPROTO=static
其中192.168.164.100为内网的代理网关的ip,保存刚才新建的文件,然后运行命令: service network restart,重启网络。

点击(此处)折叠或打开
- echo 1 > /proc/sys/net/ipv4/ip_forward
- iptables -F
- iptables -F -t nat
- iptables -P FORWARD DROP
- iptables -A FORWARD -s 192.168.164.0/24 -j ACCEPT
- iptables -A FORWARD -i eth0 -m state --state ESTABLISHED,RELATED -j ACCEPT
- iptables -t nat -A POSTROUTING -o eth0 -s 192.168.164.0/24 -j SNAT --to 211.69.198.191
在另一台主机上进行配置:

0. 本次配置的网络的拓扑结构:
1. 配置IP地址
. 1.1 正确配置学校分配的IP使能正常上网
. 1.2 新增eth0别名设备eth0:0
. 1.3 配置后 查看一下是否配置成功:
2. 配置路由
3. 配置NAT
4. 大功告成
5. 配置客户机(可以是windows或linux等其它系统)
0. 本次配置的网络的拓扑结构:
#
# |
# |
# ========+===============
# |10.3.10.0/24
# |
# |
# |10.3.10.19
# +----+----+ +-------+ +-------+
# | | | | | |
# | linux | | win1 | | win2 |
# | (NAT) | | | | |
# +----+----+ +---+---+ +---+---+
# |192.168.50.1 |192.168.50.2 |192.168.50.3
# | | |
# | | |
# | | |
# ==========+=====================+================+============
# 192.168.50.0/24
#
#
1. 配置IP地址
1.1 正确配置学校分配的IP使能正常上网
1) 按学校分配的IP地址配置好Linux主机
[~]# cat /etc/sysconfig/network-scripts/ifcfg-eth0
| DEVICE=eth0 |
| BOOTPROTO=none |
| HWADDR=00:1E:90:13:E0:25 |
| IPADDR=10.3.10.19 |
| NETMASK=255.255.255.0 |
| GATEWAY=10.3.10.254 |
| ONBOOT=yes |
| TYPE=Ethernet |
| DNS1=211.64.120.2 |
| DEFROUTE=yes |
| DOMAIN=168.96.1.1 |
2) 重起网卡
[~]# servie network restart
note: 经过以上的配置, Linux主机应该能够正常上网了!
1.2 新增eth0别名设备eth0:0
[~]# cat /etc/sysconfig/network-scripts/ifcfg-eth0:0
| # eth0:0 必须要用''括起来: 'eth0:0' |
| DEVICE='eth0:0' |
| ONBOOT=yes |
| BOOTPROTO=static |
| IPADDR=192.168.50.1 |
| NETMASK=255.255.255.0 |
| USERCTL=no |
1.3 配置后 查看一下是否配置成功:
[~]# ifconfig
| eth0 Link encap:Ethernet HWaddr 00:1E:90:13:E0:25 |
| inet addr:10.3.10.19 Bcast:10.3.10.255 Mask:255.255.255.0 |
| inet6 addr: fe80::21e:90ff:fe13:e025/64 Scope:Link |
| UP BROADCAST RUNNING PROMISC MULTICAST MTU:1500 Metric:1 |
| RX packets:187685 errors:0 dropped:0 overruns:0 frame:0 |
| TX packets:137327 errors:0 dropped:0 overruns:0 carrier:0 |
| collisions:0 txqueuelen:1000 |
| RX bytes:134816893 (128.5 MiB) TX bytes:56066393 (53.4 MiB) |
| Interrupt:27 Base address:0xa000 |
| eth0:0 Link encap:Ethernet HWaddr 00:1E:90:13:E0:25 |
| inet addr:192.168.50.1 Bcast:192.168.50.255 Mask:255.255.255.0 |
| UP BROADCAST RUNNING PROMISC MULTICAST MTU:1500 Metric:1 |
| Interrupt:27 Base address:0xa000 |
2. 配置路由
由于在配置网卡接口时, 已自动配置一定的路由, 所以我们只需查看一下其信息, 验证其
是否已经被正确配置:
[root ~]$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.50.0 * 255.255.255.0 U 0 0 0 eth0
10.3.10.0 * 255.255.255.0 U 1 0 0 eth0
link-local * 255.255.0.0 U 1002 0 0 eth0
default 10.3.10.254 0.0.0.0 UG 0 0 0 eth0
3. 配置NAT
1) 新建nat.sh脚本文件并保存在 /usr/local/nat/ 目录下:
[~]# cat /usr/local/nat/nat.sh
| #!/bin/bash |
| # 0. 设定你的参数值 |
| EXIF='eth0' # 这个是对外的网卡接口, 可能是'ppp0'等 |
| EXNET='192.168.50.0/24' # 这个是对内的网段 |
| # 底下如无需要, 请不要改动了! |
| # 1. 启动routing等 |
| echo 1 > /proc/sys/net/ipv4/ip_forward |
| /sbin/iptables -F |
| /sbin/iptables -X |
| /sbin/iptables -Z |
| /sbin/iptables -F -t nat |
| /sbin/iptables -X -t nat |
| /sbin/iptables -Z -t nat |
| /sbin/iptables -P INPUT ACCEPT |
| /sbin/iptables -P OUTPUT ACCEPT |
| /sbin/iptables -P FORWARD ACCEPT |
| /sbin/iptables -t nat -P PREROUTING ACCEPT |
| /sbin/iptables -t nat -P POSTROUTING ACCEPT |
| /sbin/iptables -t nat -P OUTPUT ACCEPT |
| # 2. 载入模组 |
| /sbin/modprobe ip_tables 2> /dev/null |
| /sbin/modprobe ip_nat_ftp 2> /dev/null |
| /sbin/modprobe ip_nat_irc 2> /dev/null |
| /sbin/modprobe ip_conntrack 2> /dev/null |
| /sbin/modprobe ip_conntrack_ftp 2> /dev/null |
| /sbin/modprobe ip_conntrack_irc 2> /dev/null |
| # 3. 启动ip伪装 |
| /sbin/iptables -t nat -A POSTROUTING -o $EXIF -s $EXNET -j MASQUERADE |
2) 增加可执行权限
[~]# chmod +x /usr/local/nat/nat.sh
4. 大功告成
1) Linux主机配置完成, 现在只需重新启动一下刚才的配置:
[~]# servie network restart
[~]# /usr/local/nat/nat.sh
2) 为了使得开机即可运行, 可在 /etc/rc.d/rc.local 文件加入相应的命令:
[~]# echo "/usr/local/nat/nat.sh" >> /etc/rc.d/rc.local
5. 配置客户机(可以是windows或linux等其它系统)
1. network 设定需要为: 192.168.50.0
2. broadcast 设定需要为: 192.168.50.255
3. netmask 设定需要为 255.255.255.0
4. IP 设定需要为 192.168.50.1 ~ 192.168.50.254 之一, 且『不能重复』
5. Gateway 或者要设定为你的 Linux 的对内 IP , 以我的例子来说, 就是
192.168.50.1
6. DNS 的设定: 这个最容易出错了, 你的 DNS 设定需要是你的 ISP 给你的 DNS
IP, 如果你不知道的话, 可以填入 168.95.1.1 这一个中华电信的 DNS 或者是
139.175.10.20 这一个 SeedNet 的 DNS 即可!千万不要设定为 192.168.1.2 呦!会
连不出去!
see also:
http://www.chinaitlab.com/www/special/linux11.asp#7
Packet filtering with Linux & NAT的更多相关文章
- CentOS下配置iptables防火墙 linux NAT(iptables)配置
CentOS下配置防火墙 配置nat转发服务CentOS下配置iptables防火墙 linux NAT(iptables)配置 CentOS下配置iptables 1,vim /etc/syscon ...
- vmware linux NAT CON
NAT上网 vmware设置nat上网: 1.设置本地可提供上网网卡为共享方式到vmware 8(NAT)如下图: 2.设置本地虚拟网卡vmware8 IP地址如下图: 3.设置vmware网络设置启 ...
- vmware linux nat模式设置静态ip
网上资料很多,但是都不怎么实用,这里给大家总结一下.nat模式上网.因为nat本身就能上网为什么还要设置ip.这有点自找麻烦.但是在集群这是必须的.要么你搭建伪分布,要么至少具有三台物理机器.为了节省 ...
- Linux NAT网络连接权威指南
[1]准备工作,写在前面 1.1)检查服务(cmd>>services.msc,我用的是VM) 1.2)确保Vmnet8 连接处于启动状态 + 获取ipv4(ipv6)地址 (在网络连接不 ...
- linux nat style
1● nat style 2● link style
- vware 中 red hat linux NAT模式上网配置
NAT模式的具体配置NAT方式:虚拟机可以上外网,可以访问宿主计算机所在网络的其他计算机(反之不行). 未修改之前的eth0
- linux nat网络配置
1. 2 . 3. BOOTPROTO = static ONBOOT=yes #开启自动启用网络连接 IPADDR0=192.168.21.128 #设置IP地址 PREFIXO0=24 #设 ...
- NAT(未验证,后续见Linux服务器架构篇)
通常小型企业或是学校单位大多数仅有一条对外的联机,然后全公司内的计算机全部通过这条联机连到因特网上,此时我们更需使用IP分享器来让这一条对外联机分享给所有公司内部员工使用,那么Linux能不能达到此一 ...
- Static NAT with iptables on Linux
本文的名字取的比较有意义,因为本文并不是真的要讨论如何在Linux上使用iptables实现static nat!之所以这么命名本文,是想引起别人的注意,因为中文资料,以及国内的搜索引擎,基本上没有人 ...
随机推荐
- 对UIImageView+WebCache的封装
UIImageView+SDWebImage.h #import <UIKit/UIKit.h> typedef void(^DownloadImageSuccessBlock)(UIIm ...
- mongo复制集脑裂问题如何处理
mongo replication 脑裂问题如何处理: 一.问题描述:一套mongo replication有4个节点.1个仲裁节点.在停止实例(或实例毁坏)的时候,导致所有节点都变为SECONDAR ...
- 高级同步器:交换器Exchanger
引自:https://blog.csdn.net/Dason_yu/article/details/79764467 一.定义每个线程将条目上的某个方法呈现给 exchange 方法,与伙伴线程进行匹 ...
- iframe中的页面在IE全屏模式下没有滚动条,正常模式有滚动条
这个问题在其他浏览器都不会出现,唯独IE不行,搜遍了百度以及各大论坛网站,都找不到这个问题的解决方案,只好自己整了. 造成这个问题的原因很简单,就是刚开始的滚动条我用的是iframe的滚动条,ifra ...
- PHP中对字符串的一些操作
php中判断字符串在另一个字符串中是否存在(strpos): if(strpos('www.baidu.com', 'www') !== false){ // 存在 }else{ // 不存在 } p ...
- 带cookie请求数据
经常会用到一些采集网上的资源,普通网站很好采,get_file_contents()/c_url(). 有的网站会有登陆后才能采集,需要带cookie请求获取(登陆网站相同方法),下面记录一下使用方法 ...
- ajax提交时 富文本CKEDITOR 获取不到内容
ckeditor数据向content(页面用以替换的编辑框)的同步 问题: 我们发现,在数据通过ajaxSubmit提交的过程中,并不能将最新的数据进行提交.换句话说,最新的数据无法被jQuery.f ...
- JavaSE 第二次学习随笔(四)
---------------------------------------------------------------------------------------------------- ...
- 网站安全检测 漏洞检测 对thinkphp通杀漏洞利用与修复建议
thinkphp在国内来说,很多站长以及平台都在使用这套开源的系统来建站,为什么会这么深受大家的喜欢,第一开源,便捷,高效,生成静态化html,第二框架性的易于开发php架构,很多第三方的插件以及第三 ...
- IO复用——epoll系列系统调用
1.内核事件表 epoll是Linux特有的I/O复用函数.epoll把用户关心的文件描述上的事件放在内核里的一个事件表中,并用一个额外的文件描述符来标识该内核事件表.这个额外文件描述符使用函数epo ...