参加2018之江杯全球人工智能大赛 :视频识别&问答(四)
很遗憾没有在规定的时间点(2018-9-25 12:00:00)完成所有的功能并上传数据,只做到写了模型代码并只跑了一轮迭代,现将代码部分贴出。
import keras
from keras.layers import Conv2D, MaxPooling2D, Flatten, Conv3D, MaxPooling3D
from keras.layers import Input, LSTM, Embedding, Dense, Dropout, Reshape
from keras.models import Model, Sequential
from keras.preprocessing import image
from keras.preprocessing.text import Tokenizer vision_model = Sequential()
vision_model.add(Conv3D(32, (3, 3, 3), activation='relu', padding='same', input_shape=(15, 28, 28, 3)))
vision_model.add(MaxPooling3D((2, 2, 2)))
# vision_model.add(Dropout(0.1))
vision_model.add(Conv3D(64, (3, 3, 3), activation='relu', padding='same'))
vision_model.add(MaxPooling3D((2, 2, 2)))
# vision_model.add(Dropout(0.1))
vision_model.add(Conv3D(128, (3, 3, 3), activation='relu', padding='same'))
vision_model.add(MaxPooling3D((2, 2, 2)))
# vision_model.add(Conv3D(256, (3, 3, 3), activation='relu', padding='same'))
# vision_model.add(MaxPooling3D((3, 3, 3)))
vision_model.add(Flatten()) image_input = Input(shape=(15, 28, 28, 3))
encoded_image = vision_model(image_input) question_input = Input(shape=(19,), dtype='int32')
embedded_question = Embedding(input_dim=10000, output_dim=256, input_length=19)(question_input)
encoded_question = LSTM(256)(embedded_question) merged = keras.layers.concatenate([encoded_image, encoded_question])
# output = Dense(500, activation='softmax')(merged)
output = Dense(7554, activation='softmax')(merged) vqa_model = Model(inputs=[image_input, question_input], outputs=output)
adam = keras.optimizers.adam(lr=0.00001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
vqa_model.compile(optimizer=adam, loss='categorical_crossentropy', metrics=['accuracy'])
vqa_model.summary()
import pandas as pd
import numpy as np
import os
import random
import collections FRAMES_NUM = 15
max_len = 5 def toarray(str, maxlen):
arr = str.split(' ')
length = len(arr)
if (length < maxlen):
for _ in range(maxlen-length):
arr.append('$')
return arr def tovector(qqarr):
global max_len
qq_all_words = []
qq_all_words += ['$'] for itv in qqarr:
qq_all_words += [word for word in itv]
max_len = max(max_len, len(itv))
print("maxlen:",max_len)
qqcounter = collections.Counter(qq_all_words)
print("qqcounter:",len(qqcounter))
qq_counter_pairs = sorted(qqcounter.items(), key = lambda x : -x[1])
qqwords,_ = zip(*qq_counter_pairs) qq_word_num_map = dict(zip(qqwords, range(len(qqwords))))
qq_to_num = lambda word:qq_word_num_map.get(word, len(qqwords))
qq_vector = [list(map(qq_to_num, word)) for word in qqarr]
return qq_vector, qq_word_num_map, qq_to_num def tolabel(labels):
all_words = []
for itv in labels:
all_words.append([itv])
counter = collections.Counter(labels)
print("labelcounter:",len(counter))
counter_pairs = sorted(counter.items(), key = lambda x : -x[1])
words, _ = zip(*counter_pairs)
print(words)
print("wordslen:",len(words)) word_num_map = dict(zip(words, range(len(words))))
to_num = lambda word: word_num_map.get(word, len(words))
vector = [list(map(to_num, word)) for word in all_words]
return vector, word_num_map, to_num def randomsample(list, count, dicdir):
if len(list) > count:
sampleintlist = random.sample(range(len(list)), count)
else:
sampleintlist = []
for i in range(count):
sampleintlist.append(i % len(list))
sampleintlist.sort()
samplelist = []
for i in sampleintlist:
samplelist.append(os.path.join(dicdir, str(i) + ".jpg"))
return samplelist def getvideo(key):
dicdir = os.path.join(r"D:\ai\AIE04\tianchi\videoanswer\image", key)
list = os.listdir(dicdir)
samplelist = randomsample(list, FRAMES_NUM, dicdir)
return samplelist path = r"D:\ai\AIE04\VQADatasetA_20180815"
data_train = pd.read_csv(os.path.join(path, 'train.txt'), header=None) length= len(data_train)*FRAMES_NUM frames = []
qqarr = []
aaarr = []
qq = []
aa = []
labels = []
paths = []
for i in range(len(data_train)):
label, q1, a11, a12, a13, q2, a21, a22, a23, q3, a31, a32, a33, q4, a41, a42, a43, q5, a51, a52, a53 = data_train.loc[i]
print(label)
[paths.append(label) for j in range(15)] [qqarr.append(toarray(str(q1), 19)) for j in range(3)]
[qqarr.append(toarray(str(q2), 19)) for j in range(3)]
[qqarr.append(toarray(str(q3), 19)) for j in range(3)]
[qqarr.append(toarray(str(q4), 19)) for j in range(3)]
[qqarr.append(toarray(str(q5), 19)) for j in range(3)] labels.append(a11)
labels.append(a12)
labels.append(a13)
labels.append(a21)
labels.append(a22)
labels.append(a23)
labels.append(a31)
labels.append(a32)
labels.append(a33)
labels.append(a41)
labels.append(a42)
labels.append(a43)
labels.append(a51)
labels.append(a52)
labels.append(a53) qq_vector, qq_word_num_map, qq_to_num = tovector(qqarr) # print(labels)
vector, word_num_map, to_num = tolabel(labels)
# print(vector)
# print(word_num_map)
# print(to_num)
from nltk.probability import FreqDist
from collections import Counter
import train_data
from keras.preprocessing.text import Tokenizer
import numpy as np
from PIL import Image
from keras.utils import to_categorical
import math
import videomodel
from keras.callbacks import LearningRateScheduler, TensorBoard, ModelCheckpoint
import keras.backend as K
import keras
import cv2 def scheduler(epoch):
if epoch % 10 == 0 and epoch != 0:
lr = K.get_value(videomodel.vqa_model.optimizer.lr)
K.set_value(videomodel.vqa_model.optimizer.lr, lr * 0.9)
print("lr changed to {}".format(lr * 0.9))
return K.get_value(videomodel.vqa_model.optimizer.lr) def get_trainDataset(paths, question, answer, img_size):
num_samples = len(paths)
X = np.zeros((num_samples, 15, img_size, img_size, 3))
Q = np.array(question)
for i in range(num_samples):
# image_paths = frames[i]
image_paths = train_data.getvideo(paths[i])
# print("len:",len(image_paths))
for kk in range(len(image_paths)):
path = image_paths[kk]
# print(path)
img = Image.open(path)
img = img.resize((img_size, img_size))
# print(img)
X[i, kk, :, :, :] = np.array(img)
img.close()
Y = to_categorical(np.array(answer), 7554)
# print(X.shape)
# print(Q)
# print(Y)
return [X, Q], Y
def generate_for_train(paths, question, answer, img_size, batch_size):
while True:
# train_zip = list(zip(frames, question, answer))
# np.random.shuffle(train_zip)
# print(train_zip)
# frames, question, answer = zip(*train_zip)
k = len(paths)
epochs = math.ceil(k/batch_size)
for i in range(epochs):
s = i * batch_size
e = s + batch_size
if (e > k):
e = k
x, y = get_trainDataset(paths[s:e], question[s:e], answer[s:e], img_size)
yield (x, y) split = len(train_data.paths) - 6000
qsplit = split*15
print("split:", split)
batch_size = 10
reduce_lr = LearningRateScheduler(scheduler)
tensorboard = TensorBoard(log_dir='log', write_graph=True)
checkpoint = ModelCheckpoint("max.h5", monitor="val_acc", verbose=1, save_best_only="True", mode="auto")
h = videomodel.vqa_model.fit_generator(generate_for_train(train_data.paths[:split], train_data.qq_vector[:split], train_data.vector[:split], 28, batch_size),
steps_per_epoch=math.ceil(len(train_data.paths[0:split]) / batch_size), validation_data=generate_for_train(train_data.paths[split:], train_data.qq_vector[split:], train_data.vector[split:], 28, batch_size),
validation_steps=math.ceil(len(train_data.paths[split:]) / batch_size),
verbose=1, epochs=100, callbacks=[tensorboard, checkpoint])
计算图如下:
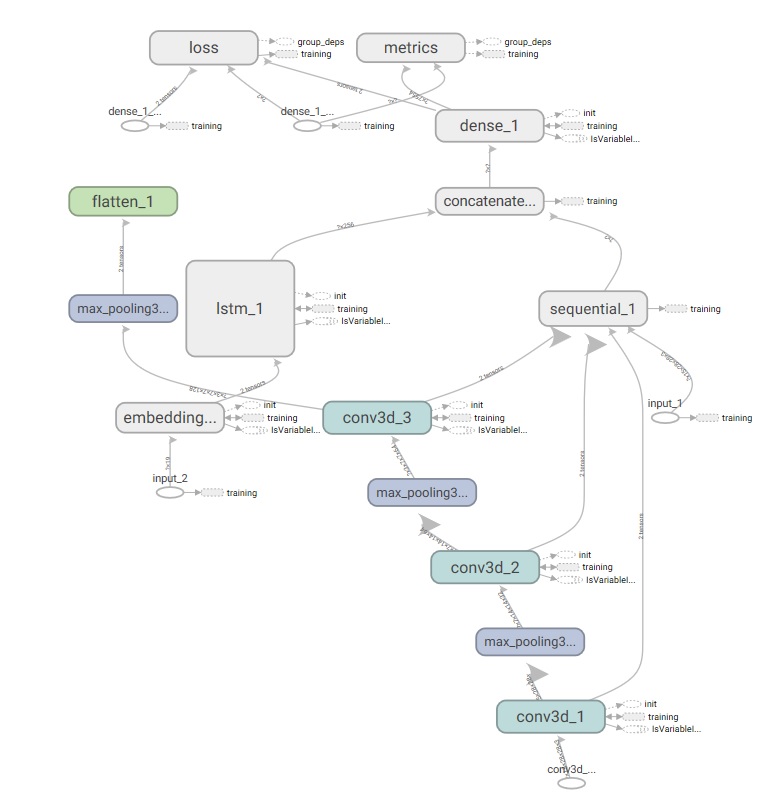
每段视频只取了15帧,每帧图片大小压缩到28*28,之所以这样是因为内存不够。即使这样在跑第二轮时也报了内存错误。看样子对个人来说,gpu(本人GTX1050)还不算是大的瓶颈(虽然一轮就需要5个小时),反而内存(本人8g内存,gpu2g)成了瓶颈。
下一篇文章再对此次参加的过程做下总结。
参加2018之江杯全球人工智能大赛 :视频识别&问答(四)的更多相关文章
- 参加2018之江杯全球人工智能大赛
:视频识别&问答
学习了一段时间的AI,用天池大赛来检验一下自己的学习成果. 题目:参赛者需对给定的短视频进行内容识别和分析,并回答每一个视频对应的问题.细节请到阿里天池搜索. 两种思路 1 将视频截成一帧一帧的图片, ...
- Imagine Cup 微软“创新杯”全球学生科技大赛
一. 介绍 微软创新杯微博:http://blog.sina.com.cn/u/1733906825 官方站点:https://www.microsoft.com/china/msdn/student ...
- 2018科大讯飞AI营销算法大赛全面来袭,等你来战!
AI技术已成为推动营销迭代的重要驱动力.AI营销高速发展的同时,积累了海量的广告数据和用户数据.如何有效应用这些数据,是大数据技术落地营销领域的关键,也是检测智能营销平台竞争力的标准. 讯飞AI营销云 ...
- 深圳即将启动首届「全国人工智能大赛」:超过 500 万大奖 & 政府资助,潜信息你读懂了吗!
人工智能加速“视频/视觉”发展,近期,深圳市即将迎来人工智能领域权威赛事之一——首届「全国人工智能大赛」(The First National Artificial Intelligence Chal ...
- 2015游戏蛮牛——蛮牛杯第四届开发者大赛 创见VR未来开启报名
蛮牛杯启动了,大家开始报名! http://cup.manew.com/ 这不是一篇普通的通稿,别着急忽略它.它是一篇可以让你梦想变现的通稿! 从某一天开始,游戏蛮牛就立志要为开发者服务,我们深知这一 ...
- [服务器]Gartner:2018年第四季度全球服务器收入增长17.8% 出货量增长8.5%
Gartner:2018年第四季度全球服务器收入增长17.8% 出货量增长8.5% Gartner 是不是也是花钱买榜的主啊.. 简单看了一下 浪潮2018Q4的营收18亿刀 (季度营收110亿人民币 ...
- 卓豪ManageEngine参加2018企业数字化转型与CIO职业发展高峰论坛
卓豪ManageEngine参加2018企业数字化转型与CIO职业发展高峰论坛 2018年10月20日,78CIO APP在北京龙城温德姆酒店主办了主题为“新模式.新动能.新发展”的<2018企 ...
- 第十一届GPCT杯大学生程序设计大赛完美闭幕
刚刚过去的周六(6月7号)是今年高考的第一天,同一时候也是GPCT杯大学生程序设计大赛颁奖的日子,以下我们用图文再回想一下本次大赛颁奖的过程. 评审过程的一些花絮<感谢各位评审这些天的付出!&g ...
- 2019CCF-GAIR全球人工智能与机器人峰会于7月在深圳召开
全球人工智能与机器人峰会(CCF-GAIR)是由中国计算机学会(CCF)主办,雷锋网.香港中文大学(深圳)承办,得到了深圳市政府的大力指导,是国内人工智能和机器人学术界.工业界及投资界三大领域的顶级交 ...
随机推荐
- 三种方法解决android帮助文档打开慢
三种方法解决android帮助文档打开慢 经查是因为本地文档中的网页有如下两段js代码会联网加载信息,将其注释掉后就好了 <link rel="stylesheet" h ...
- redis的事务、主从复制、持久化
redis事务 和其它数据库一样,Redis作为NoSQL数据库也同样提供了事务机制.在Redis中, MULTI/EXEC/DISCARD/WATCH这四个命令是我们实现事务的基石.Redis中事务 ...
- 使用带有字符串的data-ng-bind
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content=&q ...
- nineoldandroid 详细使用并且实现drawerlayout侧滑动画
nineoldandroid.view.ViewHelpe是一个为了兼容3.0以下的一个动画开源库 相关函数解读:(第一个参数都为动画对象,第二个为动画属性值的变化表达式) ViewHelper.se ...
- 课时11.HTML基本机构详解(掌握)
通过观察我们发现,HTML基本结构中所有标签都是成对出现的.这些成对出现的标签中有一个带/有一个不带/,那么这些不带/的标签我们称之为开始标签,这些带/的标签,我们称之为结束标签. html标签 作用 ...
- node学习----Promise 初见
今天在网上查看promise资料,发现promise有三种状态,pending,fullfilled,rejected.分别对应了初始化状态,成功状态及失败状态.为了理解写测试代码来实验:functi ...
- C++的抽象类、虚函数、虚基类和java的抽象类和接口
简单整理如下: C++虚函数 == java普通函数 C++纯虚函数 == java抽象函数 C++抽象类 == java抽象类 C++虚基类(全都是纯虚函数) == java接口
- c# 开发可替换的通用序列化库
开篇继续吹牛.... 其实没有什么可吹的了,哈哈哈哈哈 主要是写一个通用库,既可以直接用,又方便替换,我的序列化都是采用第三方的哈. 我不上完整代码了,只是给大家讲讲过程. 1.写一个序列化的类,我是 ...
- 【杂题总汇】HDU-5215 Cycle
◆HDU-5215◆ Cycle 国庆节集训的第三天……讲图论,心情愉快……刷了一堆水题,不过也刷了一些有意思的题 +传送门+ HDU ▶ 题目 给出一个无向图(无自环,无重边),求该无向图中是否存在 ...
- ABAP术语-Customer Exit
Customer Exit 原文:http://www.cnblogs.com/qiangsheng/archive/2008/01/19/1045231.html Pre-planned enhan ...