flink学习笔记-flink实战
说明:本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
2.4字段表达式实例-Java
以下定义两个Java类:
public static class WC {
public ComplexNestedClass complex;
private int count;
public int getCount() {
return count;
}
public void setCount(int c) {
this.count = c;
}
}
public static class ComplexNestedClass {
public Integer someNumber;
public float someFloat;
public Tuple3<Long, Long, String> word;
public IntWritable hadoopCitizen;
}
我们一起看看如下key字段如何理解:
1."count": wc 类的count字段
2."complex":递归的选取ComplexNestedClass的所有字段
3."complex.word.f2": ComplexNestedClass类中的tuple word的第三个字段;
4."complex.hadoopCitizen":选择Hadoop IntWritable类型。
2.5字段表达式实例-Scala
以下定义两个Scala类:
3.1实现接口
大多数的转换操作需要用户自己定义函数,可以通过实现MapFunction接口,并重写map函数来实现。

3.2匿名类
也可以直接使用匿名类,不需要定义类名称,直接new接口重写map方法即可。

3.3 Lambda表达式
使用Lambda表达式比自定义函数更方便,更直接。

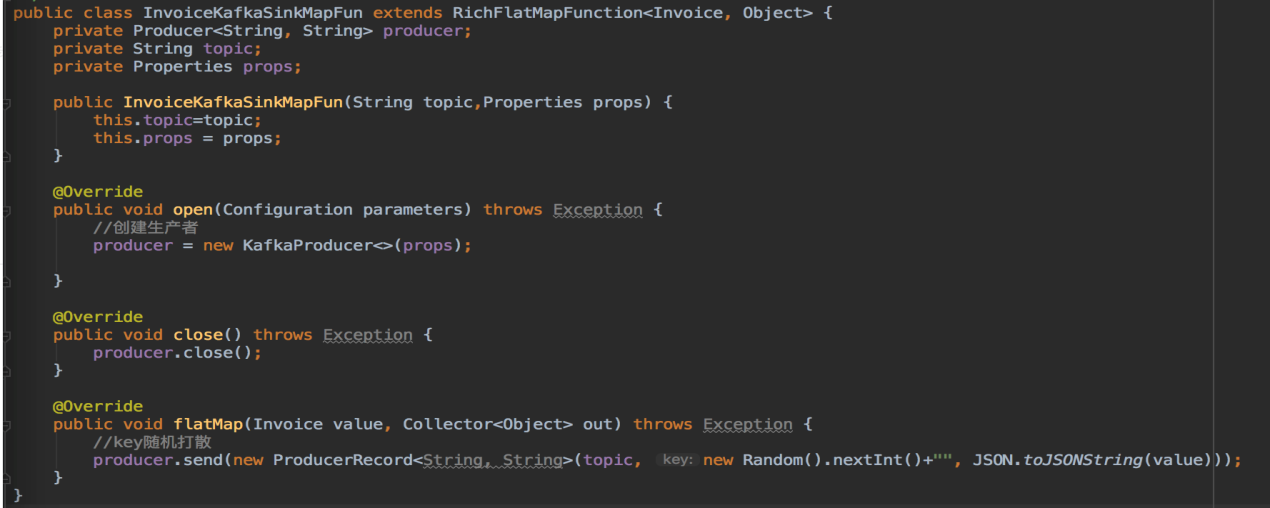
3.4 Rich Functions
遇到特殊的需求,比如读取数据库中的数据,如果数据库连接放在map函数里面迭代循环,实现谱图mapFunction接口无法满足要求。

我们需要继承RichMapFunction,将获取数据库连接放在open方法中,具体转换放在map方法中。

当然它也可以使用匿名类:

Rich Function拥有非常有用的四个方法:open,close,getRuntimeContext和setRuntimecontext
这些功能在参数化函数、创建和确定本地状态、获取广播变量、获取运行时信息(例如累加器和计数器)和迭代信息时非常有帮助。
4. 支持的数据类型
Flink对DataSet和DataStream中可使用的元素类型添加了一些约束。原因是系统可以通过分析这些类型来确定有效的执行策略和选择不同的序列化方式。
有7中不同的数据类型:
1.Java Tuple 和 Scala Case类;
2.Java POJO;
3.基本类型;
4.通用类;
5.值;
6.Hadoop Writables;
7.特殊类型
4.1Java Tuple
Tuple是包含固定数量各种类型字段的复合类。Flink Java API提供了Tuple1-Tuple25。Tuple的字段可以是Flink的任意类型,甚至嵌套Tuple。
访问Tuple属性的方式有以下两种:
1.属性名(f0,f1…fn)
2.getField(int pos)

4.2Scala Case类
Scala的Case类(以及Scala的Tuple,实际是Case class的特殊类型)是包含了一定数量多种类型字段的组合类型。Tuple字段通过他们的1-offset名称定位,例如 _1代表第一个字段。Case class 通过字段名称获得:
case class WordCount(word: String, count: Int)
val input = env.fromElements(
WordCount("hello", 1),
WordCount("world", 2)) // Case Class Data Set
input.keyBy("word")// key by field expression "word"
val input2 = env.fromElements(("hello", 1), ("world", 2)) // Tuple2 Data Set
input2.keyBy(0, 1) // key by field positions 0 and 1
4.3POJOs
Java和Scala的类在满足下列条件时,将会被Flink视作特殊的POJO数据类型专门进行处理:
1.是公共类;
2.无参构造是公共的;
3.所有的属性都是可获得的(声明为公共的,或提供get,set方法);
4.字段的类型必须是Flink支持的。Flink会用Avro来序列化任意的对象。
Flink会分析POJO类型的结构获知POJO的字段。POJO类型要比一般类型好用。此外,Flink访问POJO要比一般类型更高效。
public class WordWithCount {
public String word;
public int count;
public WordWithCount() {}
public WordWithCount(String word, int count) { this.word = word; this.count = count; }
}
DataStream<WordWithCount> wordCounts = env.fromElements(
new WordWithCount("hello", 1),
new WordWithCount("world", 2));
wordCounts.keyBy("word");
4.4基本类型
Flink支持Java和Scala所有的基本数据类型,比如 Integer,String,和Double。
4.5一般通用类
Flink支持大多数的Java,Scala类(API和自定义)。包含不能序列化字段的类在增加一些限制后也可支持。遵循Java Bean规范的类一般都可以使用。
所有不能视为POJO的类Flink都会当做一般类处理。这些数据类型被视作黑箱,其内容是不可见的。通用类使用Kryo进行序列/反序列化。
4.6值类型Values
通过实现org.apache.flinktypes.Value接口的read和write方法提供自定义代码来进行序列化/反序列化,而不是使用通用的序列化框架。
Flink预定义的值类型与原生数据类型是一一对应的(例如:ByteValue, ShortValue, IntValue, LongValue, FloatValue, DoubleValue, StringValue, CharValue, BooleanValue)。这些值类型作为原生数据类型的可变变体,他们的值是可以改变的,允许程序重用对象从而缓解GC的压力。
4.7 Hadoop的Writable类
它实现org.apache.hadoop.Writable接口的类型,该类型的序列化逻辑在write()和readFields()方法中实现。
4.8特殊类型
Flink比较特殊的类型有以下两种:
1.Scala的 Either、Option和Try。
2.Java ApI有自己的Either实现。
4.9类型擦除和类型推理
注意:本小节内容仅针对Java
Java编译器在编译之后会丢弃很多泛型类型信息。这在Java中称为类型擦除。这意味着在运行时,对象的实例不再知道其泛型类型。
例如,在JVM中,DataStream<String>和DataStream<Long>的实例看起来是相同的。
List<String> l1 = new ArrayList<String>();
List<Integer> l2 = new ArrayList<Integer>();
System.out.println(l1.getClass() == l2.getClass());
泛型:一种较为准确的说法就是为了参数化类型,或者说可以将类型当作参数传递给一个类或者是方法。
Flink 的Java API会试图去重建(可以做类型推理)这些被丢弃的类型信息,并将它们明确地存储在数据集以及操作中。你可以通过DataStream.getType()方法来获取类型,这个方法将返回一个TypeInformation的实例,这个实例是Flink内部表示类型的方式。
5. 累加器和计数器
5.1累加器和计数器
计数器是最简单的累加器。
内置累加器主要包含以下几类:
1.IntCounter, LongCounter 和 DoubleCounter
2.Histogram(柱状图)
5.2如何使用累加器
第一步:在自定义的转换操作里创建累加器对象:
private IntCounter numLines = new IntCounter();
第二步:注册累加器对象,通常是在rich function的open()方法中。这里你还需要定义累加器的名字getRuntimeContext().addAccumulator(“num-lines”, this.numLines);
第三步:在operator函数的任何地方使用累加器,包括在open()和close()方法中
this.numLines.add(1);
第四步:结果存储在JobExecutionResult里:
JobExecutionResult JobExecutionResult =env.execute("Flink Batch Java API Skeleton")
5.3自定义累加器
为了实现你自己的累加器,我们需要实现Accumulator接口,如果你想让你自定义的累加器需要被Flink所收录,请创建一个提交请求。可以选择实现Accumulator或者SimpleAccumulator。
1.Accumulator<V, R>是最灵活的:它定义了需要进行累加的值的类型V以及最后结果的类型R,例如:对于一个histogram,v是数值类型的而R是一个histogram。
2.SimpleAccumulator则是在进行累计数据类型和返回的数据类型一致的情况下使用的,例如计数器。
(7)DataSream API
1.执行计划Graph
Flink 通过Stream API (Batch API同理)开发的应用,底层有四层执行计划,我们首先来看Flink的四层执行计划如下图所示。

通过Stream API开发的Flink应用,底层首先转换为StreamGraph,然后再转换为JobGraph,接着转换为ExecutionGraph,最后生成“物理执行图”。
StreamGraph
1.根据用户代码生成最初的图
2.它通过类表示程序的拓扑结构
3.它是在client端生成
JobGraph
1.优化streamgraph
2.将多个符合条件的Node chain在一起
3.在client端生成,然后交给JobManager
ExecutionGraph
JobManger根据JobGraph 并行化生成ExecutionGraph
物理执行图
实际执行图,不可见
1.1 StreamGraph
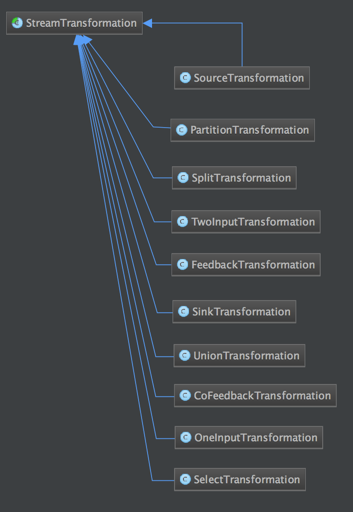
StreamGraph
通过Stream API提交的文件,首先会被翻译成StreamGraph。StreamGraph的生成的逻辑是在StreamGraphGenerate类的generate方法。而这个generate的方法又会在StreamExecutionEnvironment.execute方法被调用。
1.env中存储 List<StreamTransformation<?> ,里面存储了各种算子操作。
2.StreamTransformation(是一个类)
a)它描述DataStream之间的转化关系 。
b)它包含了StreamOperator/UDF 。
c)它包含了很多子类,比如OneInputTransformation/TwoInputTransform/ SourceTransformation/ SinkTransformation/ SplitTransformation等。
3.StreamNode/StreamEdge
StreamNode(算子)/StreamEdge(算子与算子之间的联系)是通过StreamTransformation来构造。
1.2 StreamGraph转JobGraph

1.3 JobGraph
从StreamGraph到JobGraph转换过程中,内部角色也会进行转换
1.StreamNode->JobVertex:StreamNode转换为JobVertex
2.StreamEdge->JobEdge:StreamEdge转换为JobEdge
3.将符合条件的StreamNode chain成一个JobVertex(顶点)
a)没有禁用Chain
b)上下游算子并行度一致
c)下游算子的入度为1(也就是说下游节点没有来自其他节点的输入)
d)上下游算子在同一个slot group下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)
e)上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
f)上下游算子之间没有数据shuffle (数据分区方式是 forward)
4.根据group指定JobVertex所属SlotSharingGroup
5.配置checkpoint策略
6.配置重启策略

flink学习笔记-flink实战的更多相关文章
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- Hadoop学习笔记(8) ——实战 做个倒排索引
Hadoop学习笔记(8) ——实战 做个倒排索引 倒排索引是文档检索系统中最常用数据结构.根据单词反过来查在文档中出现的频率,而不是根据文档来,所以称倒排索引(Inverted Index).结构如 ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink Runtime
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink API 通用基本概念
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记:DataSream API
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Time的故事
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
随机推荐
- OpenGL3.x,4.x中使用FreeImage显示图片的BUG-黑色,或颜色分量顺序错乱
//参照FreeImage官网给出的CTextrueManager写的加载函数 //官方给的例子是用opengl3.0以下的旧GL写的,没有使用glGenerateMipmap(GL_TEXTURE_ ...
- ubuntu apt-get用法
如何在ubuntu下面直接查找想要安装的软件?比如我想安装tomcat,但是我又不知道ubuntu里面有哪些版本,也不知道都需要装什么,但是我能确认我装的是tomcat,那么我就可以用搜索命令:例如: ...
- zookeeper更进一步(数据模型、watcher及shell命令)
ZooKeeper数据模型 ZooKeeper 的数据模型,在结构上和标准文件系统的非常相似,拥有一个层次的命名空间,都是采用树形层次结构,ZooKeeper 树中的每个节点被称为—Znode.和文件 ...
- Catalan数计算及应用
Catalan数列是非常奇妙的一列数字,因为很多问题的解就是一个Catalan数.知道了这一规律,很多看似复杂的问题便可迎刃而解.那么什么是Catalan数,什么样的问题的解是Catalan数呢? 1 ...
- 【HDU5187】zhx's contest
[问题描述] 作为史上最强的刷子之一,zhx的老师让他给学弟(mei)们出n道题.zhx认为第i道题的难度就是i.他想要让这些题目排列起来很漂亮. zhx认为一个漂亮的序列{ai}下列两个条件均需满足 ...
- yii2 源码分析1从入口开始
我是在 backend 一步步打印的 很多地方我也是很模糊 .后来发现一位大神的文章(http://www.yiichina.com/tutorial/773) 参考文章自己动手开始写的 至于后来的 ...
- Hadoop完全分布式环境搭建(三)——基于Ubuntu16.04安装和配置Java环境
[系统环境] 1.宿主机OS:Win10 64位 2.虚拟机软件:VMware WorkStation 12 3.虚拟机OS:Ubuntu16.04 4.三台虚拟机 5.JDK文件:jdk-8u201 ...
- Mock Server实践
转载自 https://tech.meituan.com/mock-server-in-action.html 背景 在美团服务端测试中,被测服务通常依赖于一系列的外部模块,被测服务与外部模块间通过R ...
- java日期和时间转换字符
日期和时间转换字符 字符 描述 例子 c 完整的日期和时间 Mon May 04 09:51:52 CDT 2009 F ISO 8601 格式日期 2004-02-09 D U.S. 格式日期 (月 ...
- Apache apxs命令
一.简介 apxs是一个为Apache HTTP服务器编译和安装扩展模块的工具,用于编译一个或多个源程序或目标代码文件为动态共享对象,使之可以用由mod_so提供的LoadModule指令在运行时加载 ...