Coursera 机器学习 第9章(上) Anomaly Detection 学习笔记
9 Anomaly Detection
9.1 Density Estimation
9.1.1 Problem Motivation
异常检测(Density Estimation)是机器学习常见的应用,主要用于非监督学习,但在某些方面又类似于监督学习。
异常检测最常见的应用是欺诈检测和在工业生产领域。

具体来说工业生产飞机发动机的例子:这个的特征量假设只有2个,对于不同训练集数据进行坐标画图,预测模型p(x)和阈值ε。对于一个新的测试用例xtest,如果p(xtest)<ε,就预测该实例出现错误;否则预测该实例正常。

做道题:

B
9.1.2 Gaussian Distribution
认识高斯分布,或者是正态分布。学会计算高斯分布公式中的参数。
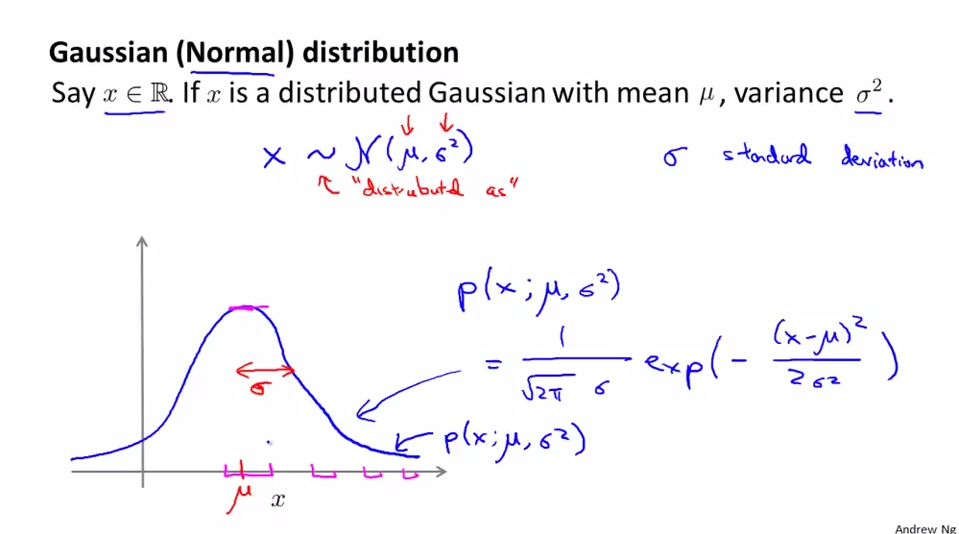
x~N(μ,σ^2)意为x属于高斯分布,σ是标准差,σ^2是方差。在高斯分布图中的意义:μ控制高斯图的中心位置;σ控制图形的宽度。p(x;μ;σ^2)表示的是x的概率分布由μ和σ^2两个参数控制,表示的是高斯分布的概率密度函数。注意高斯分布的阴影面积的积分是1。
下面是不同μ,σ取值下的高斯图像对比:
参数估计问题。在这个例子中,参数估计就是给定数据集,能够估计出μ和σ^2的值,在这里其实就是对μ和σ的极大似然估计。
μ=1/m*∑mx(i)
σ=1/m*∑m(x(i)-μ),这里的m在统计公式写作m-1,机器学习中写成m,最后不影响效果。
注意:上面的μ、σ和x(i)都是向量化。

做道题:

9.1.3 Algorithm
利用高斯分布开发异常检测算法。
一个无标签的训练集,共有m个训练样本。利用p(x)的概率模型来计算出哪些特征出现的概率比较高。p(x)对应一个从x1到xn(xi是特征向量的第i维)的独立假设,其实如果这些样本不独立,算法的效果也还是不错的。估计p(x)就是密度估计问题。

异常检测算法描述:
1.选择认为可以反映出异常例子的特征xi。
2.利用训练集和公式拟合参数μ和σ,不同的特征对应不同的参数和高斯分布。
3.对于一个新的例子x,利用高斯分布公式、拟合的参数以及p(x)的公式计算出p(x),p(x)<阈值ε,则认为该例子为异常。

做道题:
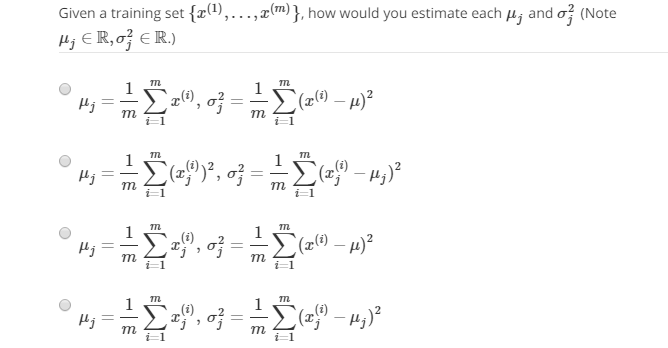
D
9.2 Building an Anomaly Detection System
9.2.1 Developing and Evaluating an Anomaly Detection System
用特定检测算法的例子来展现如何利用实数评价法来评价一个异常检测算法的步骤。
1.明确数据分布。6:2:2的训练集、交叉验证集和测试集的分法。事先有标记的数据,在训练时认为是无标记的,在交叉验证集可以利用标记选择特征以及ε参数,测试时又可以利用标记来衡量算法。

训练集、交叉验证集和测试集的数据一定要相互无关,不可以交叉,下面的数据分布是错误的:
2.选择评价指标(不用准确率是因为存在偏斜率问题)。

在这个例子中,选择ε的一种方法是循环使用交叉验证集选取不同ε下的F1-积分最大的ε。可以使用交叉验证集来辅助做出决定,比如确定ε取多大合适,快速确定σ,应该包括哪些特征下算法的效果最佳。
具体的算法的实施如下:

3.最后用测试集来评估这个算法。
做道题:

C 偏斜率。
9.2.2
讨论什么时候使用异常检测,什么时候使用监督学习。
异常检测和监督学习的样本分布的不同。异常检测:y=1的正例非常少(与y=0的负例比较),新不同类型的正例还会出现(之前的样本中并没出现),当前的正例样本没有基本覆盖所有可能的正例情况;监督学习:正例与负例的数量差不多,在样例中基本覆盖了正例和负例的所有情况。

异常检测和监督学习的应用场景的不同:随着正例样本与负例样本的数量变化,异常检测问题可以向监督学习问题转换。

做道题:

BD
9.2.3 Choosing What Features to Use
对异常检测算法的效率影响较大的因素之一是选择什么样的特征向量来输入异常检测算法。下面讨论如何设计或者选择异常检测算法的特征变量。以下两步可以交替进行。
1.变换数据形式,使每维的特征的分布服从正态分布(高斯分布):得到数据先针对特征向量为每一维绘图,看每一维是否看起来像高斯分布;如果数据的某一维分布不像高斯分布,就利用对数或者根指数将该维数据转换,使转换后的数据的分布有高斯分布的特征,然后再使用转换后的新数据到算法中。matlab中可以使用hist()函数来形成直方图。

2.选择异常检测的特征变量:通过一个误差分析,这个和之前学习监督学习算法时的误差分析步骤是类似的,先完整地训练出一个学习算法,然后再一组交叉验证集上运行算法,找出那些预测错误的样本,然后再看看能否找到一些其他的特征变量,来帮助学习,让它在那些交叉验证时判断出错的样本中表现得更好。

如果已存在的特征不足以判断出异常实例,可以通过组合特征变量来捕捉异常。比如下面的关于网络中心检测的例子:当网络中堵塞,对于特定的机器,除了CPU负载较大,其他情况正常,这时就可以组装出新的特征变量x5=(CPU load)/(network traffic)来反映network traffic正常而CPU负载较大的情况。

做道题:

B
9.3 Multivariate Gaussian Distribution (Optional)
9.3.1 Multivariate Gaussian Distribution
介绍多元高斯分布(multivariate Gaussian distribution):改良的异常检测,能捕捉到一些之前的算法检测不出来的异常。
比如上一节最后"关于网络中心检测的例子:当网络中堵塞,对于特定的机器,除了CPU负载较大,其他情况正常,这时就可以组装出新的特征变量x5=(CPU load)/(network traffic)来反映network traffic正常而CPU负载较大的情况。"
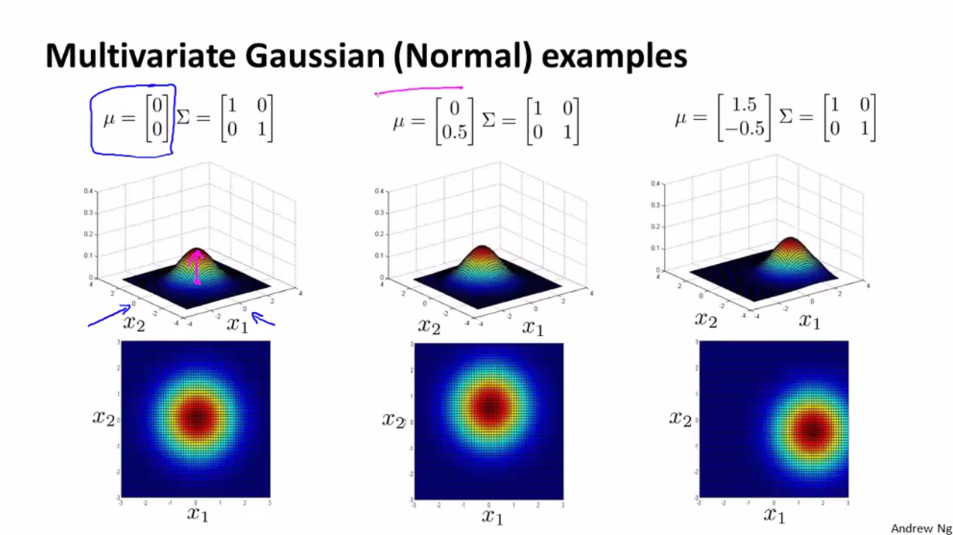
多元高斯分布构造方法:不再单独构造不同特征变量对应的高斯函数,一次性构造p(x),其中参数是μ和描述变量之间相关性的协方差矩阵Σ。其中


看一下取不同μ和Σ时,对多元高斯分布图形的影响情况:




9.3.2
将多元高斯分布应用于异常检测中:
1.计算μ和Σ。
2.计算新实例x的p(x),比较p(x)和的大小,预测是否异常。

与原来模型的联系:
1.当协方差矩阵是对角矩阵时,使用多元高斯分布和不使用多元高斯分布的异常检测算法的检测公式相同。

2.1 原来的模型手动创建新的特征变量来计算异常值;新的模型自动计算不同特征之间的相关性。
2.2 原来的模型计算量小,适合于大规模的特征变量(n较大);新的模型计算代价较大。
2.3 原来的模型在m较小的时候仍可以使用;新的模型要求样本数量m要大于特征变量n的数量,因为要保证Σ矩阵是可逆的。实际应用中,当m远远大于n的时候,差不多m>=10n,采用多元高斯分布。

实际应用中原来的模型更为常用,一般人会手动增加额外变量。
如果在实际应用中,发现Σ矩阵是不可逆,可能有以下2个方面的原因:
1. 没有满足m大于n的条件。
2. 有冗余变量(至少有2个变量完全一样,xi=xj,xk=xi+xj)。其实就是特征变量的线性相关造成的。
做道题:

ACD
练习:





下面2题做错,不知道正确答案:


Coursera 机器学习 第9章(上) Anomaly Detection 学习笔记的更多相关文章
- Coursera 机器学习 第7章 Support Vector Machines 学习笔记
7 Support Vector Machines7.1 Large Margin Classification7.1.1 Optimization Objective支持向量机(SVM)代价函数在数 ...
- Coursera 机器学习 第5章 Neural Networks: Learning 学习笔记
5.1节 Cost Function神经网络的代价函数. 上图回顾神经网络中的一些概念: L 神经网络的总层数. sl 第l层的单元数量(不包括偏差单元). 2类分类问题:二元分类和多元分类. 上 ...
- 【机器学习】决策树(Decision Tree) 学习笔记
[机器学习]决策树(decision tree) 学习笔记 标签(空格分隔): 机器学习 决策树简介 决策树(decision tree)是一个树结构(可以是二叉树或非二叉树).其每个非叶节点表示一个 ...
- Coursera 机器学习 第6章(上) Advice for Applying Machine Learning 学习笔记
这章的内容对于设计分析假设性能有很大的帮助,如果运用的好,将会节省实验者大量时间. Machine Learning System Design6.1 Evaluating a Learning Al ...
- Coursera 机器学习 第8章(上) Unsupervised Learning 学习笔记
8 Unsupervised Learning8.1 Clustering8.1.1 Unsupervised Learning: Introduction集群(聚类)的概念.什么是无监督学习:对于无 ...
- Coursera 机器学习 第8章(下) Dimensionality Reduction 学习笔记
8 Dimensionality Reduction8.3 Motivation8.3.1 Motivation I: Data Compression第二种无监督问题:维数约简(Dimensiona ...
- Coursera 机器学习 第6章(下) Machine Learning System Design 学习笔记
Machine Learning System Design下面会讨论机器学习系统的设计.分析在设计复杂机器学习系统时将会遇到的主要问题,给出如何巧妙构造一个复杂的机器学习系统的建议.6.4 Buil ...
- Coursera 机器学习 第9章(下) Recommender Systems 学习笔记
9.5 Predicting Movie Ratings9.5.1 Problem Formulation推荐系统.推荐系统的问题表述:电影推荐.根据用户对已看过电影的打分来推测用户对其未打分的电影将 ...
- 郑捷《机器学习算法原理与编程实践》学习笔记(第四章 推荐系统原理)(二)kmeans
(上接第二章) 4.3.1 KMeans 算法流程 算法的过程如下: (1)从N个数据文档随机选取K个文档作为质心 (2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类 (3)重新计 ...
随机推荐
- 【EfF】 贪婪加载和延迟加载 (virtual去掉关闭延迟加载)
EntityFramework(EF)贪婪加载和延迟加载的选择和使用 贪婪加载:顾名思议就是把所有要加载的东西一 次性读取 1 using (var context = new MyDbContext ...
- .NET平台的资源文件管理
可以管理文本.图片等不同类型的资源 管理方式(增删改) 可以直接修改XXX.resx源文件(XML格式,文本直接管理内容,图片需要指定路径,资源名和图片名可以不同) 也可以在VS的可视化界面上进行操作 ...
- vs2015 使用 Eazfuscator.NET 3.3
出现问题: Unable to cast object System.Xml.XmlComment’ to type ‘System.Xml.XmlElement’ 解决办法: 打开 *.csproj ...
- 「BJOI2012」连连看
题目链接 戳我 \(Solution\) 我们首先进行拆点操作,将每个点都拆成\(x\)和\(y\),将满足条件的两个点连起来就好了(记得要将\(x\)连\(y'\)的同时要将\(y\)联向\(x'\ ...
- NSProcessInfo系统进程信息
前言 NSProcessInfo 类中包含一些方法,允许你设置或检索正在运行的应用程序(即进程)的各种类型的信息. 1.获取系统进程信息 // 创建系统进程信息对象 NSProcessInfo *pr ...
- vi/vim使用总结
第一部份:一般模式可用的按钮说明,光标移动.复制粘贴.搜索取代等 移动光标的方法: h 或 向左箭头键(←) 光标向左移动一个字符 j 或 向下箭头键(↓) 光标向下移劢一个字符 k 或 向上箭头键( ...
- 321. Create Maximum Number (c++ ——> lexicographical_compare)
Given two arrays of length m and n with digits 0-9 representing two numbers. Create the maximum numb ...
- PHP选项和运行
PHP运行模式 五大运行模式 1.cgi 通用网关接口 2.fast-cgi cgi升级 3.cli (Command Line Interface) 4.isapi 微软提供的面向Internet服 ...
- 使用C#实现SSLSocket加密通讯 Https
原文链接 http://blog.csdn.net/wuyb_2004/article/details/51393290 using System; using System.Collections; ...
- win7/win8/win10 系统
WIN7/WIN8/WIN10 系统安装 http://www.windows7en.com/Win7/18572.html