安装部署ELK系统监控Azure China的NSG和WAF Log
ELK是一个开源的产品,其官网是:https://www.elastic.co/
ELK主要保护三个产品:
- Elasticsearch:是基于 JSON 的分布式搜索和分析引擎,专为实现水平扩展、高可用和管理便捷性而设计。
- Logstash :是动态数据收集管道,拥有可扩展的插件生态系统,能够与 Elasticsearch 产生强大的协同作用。
- Kibana :能够以图表的形式呈现数据,并且具有可扩展的用户界面,供您全方位配置和管理。
本文将介绍ELK三个组件的安装和配置,并介绍如何通过ELK监控Azure China的NSG Log。具体的拓扑结构如下:

最左边的Azure China上开启了Network Watcher功能,NSG的各种日志信息将发送到Azure Storage存储账户。
中间是ELK组件,包括上面提到的Logstash,并安装了Azure Blob的插件,Logstash会从指定的Azure存储账户获得NSG的log文件。Logstash把log获取后,以一定的格式发送到两台Elastic Search组成的集群。Kibana
一 环境准备
1 安装Java环境
本环境安装的是1.8.0的jdk:
yum install -y java-1.8.-openjdk-devel
2 修改hosts文件
echo "10.1.4.4 node1" >> /etc/hosts
echo "10.1.5.4 node2" >> /etc/hosts
3 修改iptables和selinux
iptables -F
setenforce
二 Elasticsearch的安装和配置
1 添加YUM源
导入key:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
添加YUM源文件:
vim /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-.x]
name=Elasticsearch repository for5.x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=
autorefresh=
type=rpm-md
2 安装elasticsearch
yum install elasticsearch -y
systemctl enable elasticsearch
3 配置elasticsearch
编辑配置文件:
vim /etc/elasticsearch/elasticsearch.yml
cat ./elasticsearch.yml | grep -v "#"
cluster.name: es-cluster
node.name: node1
path.data: /var/lib/elasticsearch
path.logs: /var/lib/elasticsearch
network.host: 0.0.0.0
http.port:
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
discovery.zen.minimum_master_nodes:
在node2上的node.name配置成node2
4 启动elasticsearch
systemctl start elasticsearch
systemctl status elasticsearch
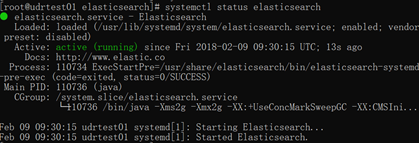
可以看到访问是running状态。
通过netstat -tunlp查看ES的端口9200和9300是否启动:
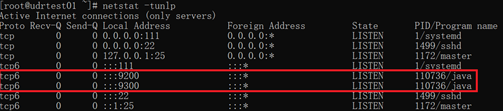
通过下面的命令查看节点信息:
curl -XGET 'http://10.1.4.4:9200/?pretty'
curl -XGET 'http://10.1.4.4:9200/_cat/nodes?v'
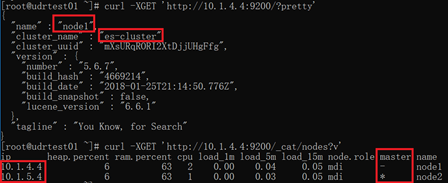
其中*号的标识是master节点。
当然通过浏览器也可以浏览相应的信息:

日志在配置文件中定义的/var/lib/elasticsearch内,可以查看这里ES启动是否正常。
三 logstash的安装
Logstash是整个ELK安装过程中比较复杂的一个。具体安装配置过程如下:
1 安装logstash
Logstash可以安装在一个节点上,也可以安装在多个节点上。本文将安装在node1上:
yum install -y logstash
systemctl enable logstash
ln -s /usr/share/logstash/bin/logstash /usr/bin/logstash
2 配置logstash
vim /etc/logstash/logstash.yml
cat ./logstash.yml | grep -v "#"
path.data: /var/lib/logstash
path.config: /etc/logstash/conf.d
path.logs: /var/log/logstash
3 更改logstash相关文件的权限
在安装的过程中会发现logstash安装后,其文件的权限设置有问题,需要把相关的文件和文件夹的设置正确:
chown logstash:logstash /var/log/logstash/ -R
chmod /var/log/messages
mkdir -p /usr/share/logstash/config/
ln -s /etc/logstash/* /usr/share/logstash/config
chown -R logstash:logstash /usr/share/logstash/config/
mkdir -p /var/lib/logstash/queue
chown -R logstash:logstash /var/lib/logstash/queue
3 配置pipeline
Logstash的相关培训和文档可以在elk的官网上找到,简单来说,logstash包含input,filter和output几个区域,其中input和output是必须配置的。
以官网教程https://www.elastic.co/guide/en/logstash/current/getting-started-with-logstash.html 为例:
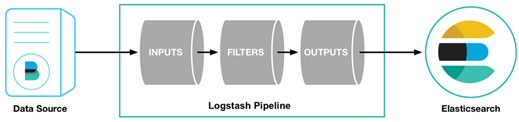
/usr/share/logstash/bin/logstash -e 'input { stdin { } } output { stdout {} }'

将filebeat作为输入组件的例子:
安装filebeat:
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.1-x86_64.rpm
rpm -vi filebeat-6.2.-x86_64.rpm
下载demo文件:
wget https://download.elastic.co/demos/logstash/gettingstarted/logstash-tutorial.log.gz
gzip -d logstash-tutorial.log.gz
配置filebeat:
vim /etc/filebeat/filebeat.yml
cat /etc/filebeat/filebeat.yml |grep -v "#"
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/ logstash-tutorial.log
output.logstash:
hosts: ["localhost:5044"]
配置pipeline文件:
vim /etc/logstash/conf.d/logstash.conf
input
{
beats { port => "" }
}
output
{
file { path => "/var/log/logstash/output.out" }
stdout { codec => rubydebug }
}
测试配置:
cd /etc/logstash/conf.d
logstash -f logstash.conf --config.test_and_exit
logstash -f logstash.conf --config.reload.automatic
通过netstat -tunlp可以看到5044端口已经打开,等待filebeatd 输入。
运行filebeat:
filebeat -e -c /etc/filebeat/filebeat.yml -d "publish"
需要注意的是,在第二次运行时,需要删除register文件:
cd /var/lib/filebeat/
rm registry
此时可以看到logstash的console有日志输出,定义的文件也有记录。格式如下:
{
"@timestamp" => --10T02::.166Z,
"offset" => ,
"@version" => "",
"beat" => {
"name" => "udrtest01",
"hostname" => "udrtest01",
"version" => "6.2.1"
},
"host" => "udrtest01",
"prospector" => {
"type" => "log"
},
"source" => "/var/log/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /reset.css HTTP/1.1\" 200 1015 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"tags" => [
[] "beats_input_codec_plain_applied"
]
}
更改input,改为文件输入:
input
{
file { path => "/var/log/messages" }
beats { port => "" }
}
可以看到新增加的日志会输出到logstash的console,同时记录到output.out文件中。
三. Kibana的安装和配置
1 Kibana的安装
yum install kibana -y
systemctl enable kibana
2 配置Kibana
vim /etc/kibana/kibana.yml
cat /etc/kibana/kibana.yml -v "#"
server.port:
server.host: "0.0.0.0"
elasticsearch.url: "http://10.1.5.4:9200"
启动kibana
systemctl start kibana
3 查看Kibana
通过VM的metadata查看VM的PIP地址:
curl -H Metadata:true http://169.254.169.254/metadak?api-version=2017-08-01
查找到公网IP地址后,在浏览器中浏览Kibana:
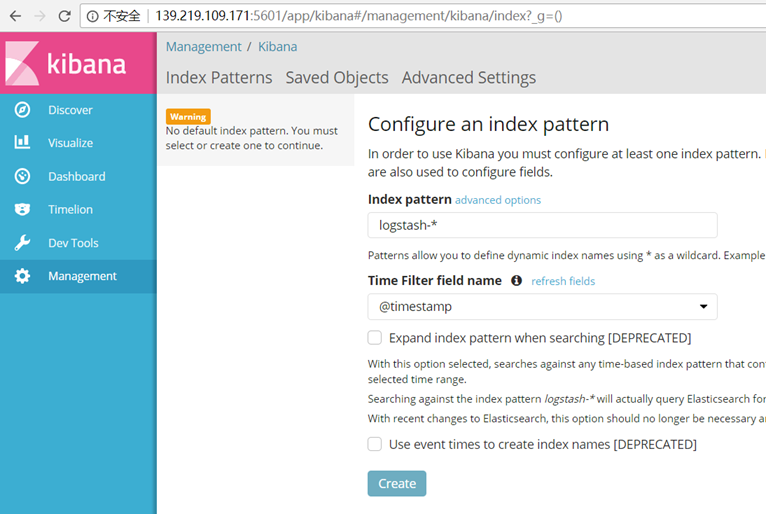
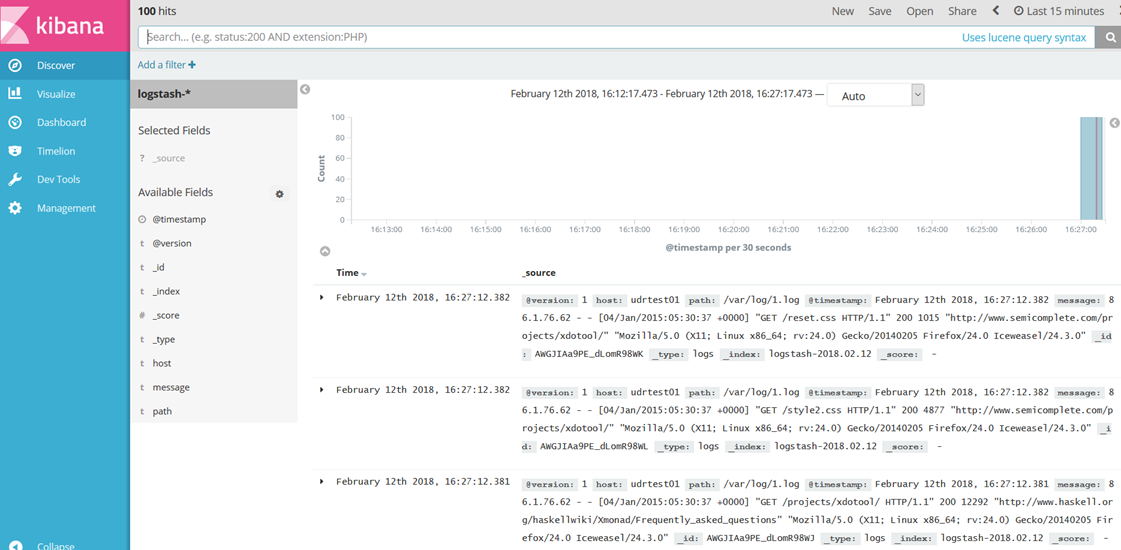
创建一个index,在discover中可以看到相关的日志:
在Kibana的Dev Tools上可以查看和删除相关的信息:

四 Logstash支持Azure Blob作为input查看NSG Log
1 Logstash的Azure Blob插件的安装
具体的信息请参考:
https://github.com/Azure/azure-diagnostics-tools/tree/master/Logstash/logstash-input-azureblob
安装命令为:
logstash-plugin install logstash-input-azureblob
2 配置
根据上面链接的文档,把相关信息填入。
其中需要填写endpoint,把其指向China的endpoint:
vim /etc/logstash/conf.d/nsg.conf
input {
azureblob
{
storage_account_name => "xxxx"
storage_access_key => "xxxx"
container => "insights-logs-networksecuritygroupflowevent"
endpoint => "core.chinacloudapi.cn"
codec => "json"
file_head_bytes =>
file_tail_bytes =>
}
}
filter {
split { field => "[records]" }
split { field => "[records][properties][flows]"}
split { field => "[records][properties][flows][flows]"}
split { field => "[records][properties][flows][flows][flowTuples]"}
mutate {
split => { "[records][resourceId]" => "/"}
add_field => {"Subscription" => "%{[records][resourceId][2]}"
"ResourceGroup" => "%{[records][resourceId][4]}"
"NetworkSecurityGroup" => "%{[records][resourceId][8]}"}
convert => {"Subscription" => "string"}
convert => {"ResourceGroup" => "string"}
convert => {"NetworkSecurityGroup" => "string"}
split => { "[records][properties][flows][flows][flowTuples]" => ","}
add_field => {
"unixtimestamp" => "%{[records][properties][flows][flows][flowTuples][0]}"
"srcIp" => "%{[records][properties][flows][flows][flowTuples][1]}"
"destIp" => "%{[records][properties][flows][flows][flowTuples][2]}"
"srcPort" => "%{[records][properties][flows][flows][flowTuples][3]}"
"destPort" => "%{[records][properties][flows][flows][flowTuples][4]}"
"protocol" => "%{[records][properties][flows][flows][flowTuples][5]}"
"trafficflow" => "%{[records][properties][flows][flows][flowTuples][6]}"
"traffic" => "%{[records][properties][flows][flows][flowTuples][7]}"
}
convert => {"unixtimestamp" => "integer"}
convert => {"srcPort" => "integer"}
convert => {"destPort" => "integer"}
}
date{
match => ["unixtimestamp" , "UNIX"]
}
}
output {
elasticsearch {
hosts => "localhost"
index => "nsg-flow-logs"
}
}
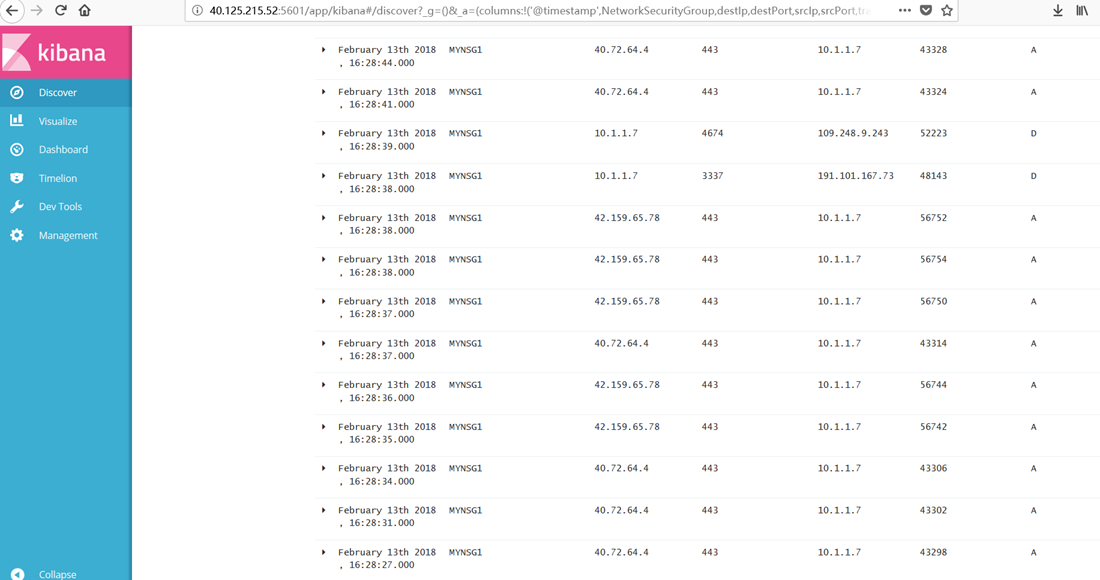
在Kibana上可以看到相关信息:
五 Logstash支持Azure Blob作为input查看WAF Log
类似的,把WAF的log发送到Azure Storage中,命令为:
Set-AzureRmDiagnosticSetting -ResourceId /subscriptions/<subscriptionId>/resourceGroups/<resource group name>/providers/Microsoft.Network/applicationGateways/<application gateway name> -StorageAccountId /subscriptions/<subscriptionId>/resourceGroups/<resource group name>/providers/Microsoft.Storage/storageAccounts/<storage account name> -Enabled $true
在cu存储账户有了日志后,通过配置logstash,把日志读入logstash,再发送给ES,在Kibana上展现。
Firewall log的配置为:
input {
azureblob
{
storage_account_name => "xxxxx"
storage_access_key => "xxxxxx"
container => "insights-logs-applicationgatewayaccesslog"
endpoint => "core.chinacloudapi.cn"
codec => "json"
}
}
filter {
date{
match => ["unixtimestamp" , "UNIX"]
}
}
output {
elasticsearch {
hosts => "localhost"
index => "waf-access-logs"
}}
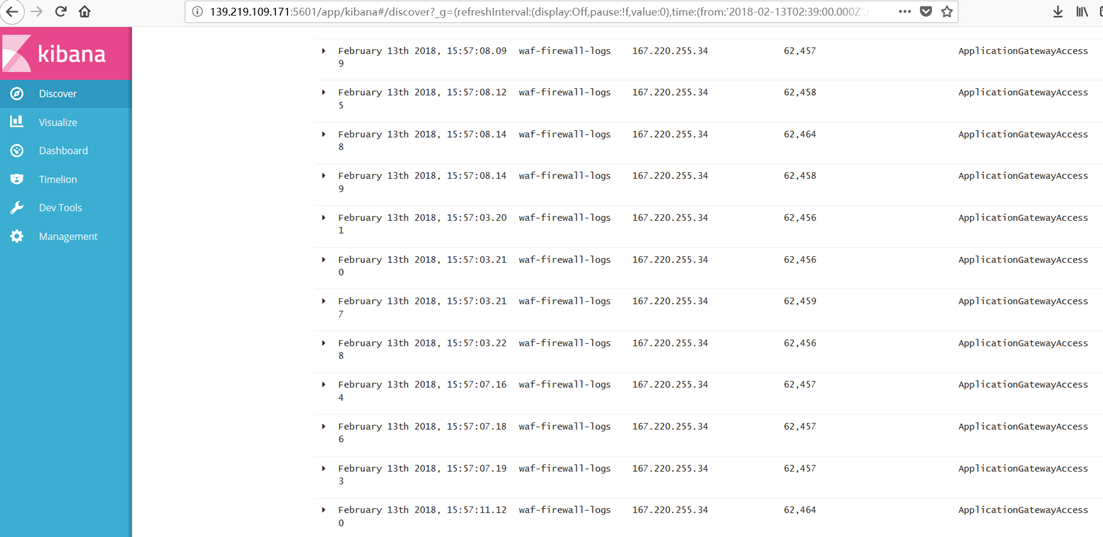
可以看到相关的信息:
六总结
通过ELK工具,可以把Azure上的相关服务日志进行图形化的分析。
安装部署ELK系统监控Azure China的NSG和WAF Log的更多相关文章
- Cobbler全自动批量安装部署Linux系统
说明: Cobbler服务器系统:CentOS 5.10 64位 IP地址:192.168.21.128 需要安装部署的Linux系统: eth0(第一块网卡,用于外网)IP地址段:192.168.2 ...
- CentOS 7安装部署ELK 6.2.4-SUCCESS
一.ELK介绍 ELK是三款开源软件的缩写,即:ElasticSearch + Logstash + Kibana.这三个工具组合形成了一套实用.易用的监控架构,可抓取系统日志.apache日志.ng ...
- zabbix的安装部署及自定义监控的实现
此篇感谢我的小师傅. 1. Zabbix主要功能和优劣势说明 1. Zabbix主要功能和优劣势说明 1.1 Zabbix主要功能: 1)Application monitoring 应用监控 数据库 ...
- Azkaban2.5安装部署(系统时区设置 + 安装和配置mysql + Azkaban Web Server 安装 + Azkaban Executor Server安装 + Azkaban web server插件安装 + Azkaban Executor Server 插件安装)(博主推荐)(五)
Azkaban是什么?(一) Azkaban的功能特点(二) Azkaban的架构(三) Hadoop工作流引擎之Azkaban与Oozie对比(四) 不多说,直接上干货! http://www.cn ...
- Ubuntu Server 安装部署 Cacti 服务器监控
本文的英文版本链接是 http://xuri.me/2013/10/20/install-the-cacti-server-monitor-on-ubuntu-server.html Cacti是一套 ...
- shell脚本安装部署反向代理 监控进程 计划任务
1.编写脚本自动部署反向代理.web.nfs: 要求: I.部署nginx反向代理三个web服务,调度算法使用加权轮询: 反向代理服务器脚本配置脚本 #!/bin/bash #安装eple和nginx ...
- JMeter的安装部署——Linux系统
1.配置Java环境 在官网https://www.oracle.com/technetwork/java/javase/downloads/jdk10-downloads-4416644.html下 ...
- CentOS安装Netdata进行系统监控
偶然间在知乎看到了Netdata这个东西 看到它华丽的界面 顿时心动 gkd gkd #准备 yum install autoconf automake curl gcc git libmnl-dev ...
- Docker安装部署ELK教程(Elasticsearch+Kibana+Logstash+Filebeat)
Elasticsearch 是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等. Logstash 是一个完全开 ...
随机推荐
- https网站无法加载http路径的js和css
在https的网站中引用http路径的js或css会导致不起作用,其形如: <script src="http://code.jquery.com/jquery-1.11.0.min. ...
- ACM训练小结-2018年6月15日
今天题目情况如下:A题:给出若干条边的边长,问这些边按顺序能否组成一个凸多边形,并求出这个多边形的最小包含圆.答题情况:无思路.正解(某种):第一问很简单.对第二问,如果R大于可行的最小R,那么按照放 ...
- Go Log模块生成日志文件
使用log模块示例代码: package main import ( "fmt" "time" "log" "os" ) ...
- Bootstrap3全局CSS样式
目录 1. 概览 2. 栅栏系统 3. 文本 4. 列表 5. 代码 6. 表格 7. 表单 7.1 基本实例 7.2 内联表单 7.3 水平排列的表单 8. 按钮 9. 图片 10. 辅助类 10. ...
- each方法的简单使用
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN""http://www.w3.org/TR/html4/stric ...
- php记录代码执行时间
$t1 = microtime(true); // ... 执行代码 ... $t2 = microtime(true); echo '耗时'.round($t2-$t1,3).'秒'; 简单说一下. ...
- 算法总结之 在数组中找到出现次数 > N/K的数
题目1 给定一个整型数组arr, 打印其中出现次数大于一半的数, 如果没有这样的数,打印提示信息 进阶 给定一个整型数组arr, 再给定一个整数K, 打印所有出现次数大于 N/K的数,如果没有这样的 ...
- 【转载】树链剖分.By.Xminh
轻重链剖分 其实就是俗称的树链剖分. PS:树链剖分不止有轻重链剖分.但是大多数时候的树链剖分指的就是轻重链剖分. dfs序 给树的节点重新编号,使得任意一个节点满足子树的dfs序都比它要大,而且它子 ...
- 安装,配置webpack.
1.下载node.js 2.在需要用到webpack的项目下打开命令窗口运行npm init生成package.js 3.安装webpack,使用npm install webpack --save- ...
- Java -- JDBC 数据库连接池
1. 原理代码示例 public class JdbcPool implements DataSource { private static LinkedList<Connection> ...