阿里Tree-based Deep Match(TDM) 学习笔记
阅读文献:https://zhuanlan.zhihu.com/p/35030348
参考文献:https://www.leiphone.com/news/201803/nlG3d4sZnRvgAqg9.html
阿里Tree-based Deep Match(TDM)
背景
工业界的技术发展也经历了几代的演进,从最初的基于统计的启发式规则方法,逐渐过渡到基于内积模型的向量检索方法。如何在匹配阶段的计算效率约束下引入更先进的复杂深度学习模型成为了下一代匹配技术发展的重要方向。
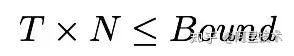 公式(1)
公式(1)
I)第一代——基于统计的启发式规则方法
经典代表就是Item-based Collaborative Filtering(以下简称Item-CF)。首先通过统计计算得到Item to Item(I2I)的相似关系,其次启发式地获取用户近期行为作为Trigger Item集合,用它们进行I2I扩展,最后以某种打分规则对扩展后的Item集合进行排序,截断得到TopK。
我们可以知道这种方法有效的控制了总体计算次数N,因为用户的Trigger Item集合是有限的,相似关系圈定的候选集合也是有限的。
II)第二代——基于内积模型的向量检索方法
以向量距离的方式衡量用户和商品兴趣度的方法,用户和商品被表示成向量形式,并以此为基础建立基于向量聚类的索引结构进一步加速衡量效率,于是这个计算问题变成了在有限时间内是可解的(近似求解),具体实现也落到了向量引擎的范畴。结合公式(1),T代表简单的向量内积计算时间,而N则通过建立向量索引结构从而控制在O(桶候选集规模)的较小范围内。
所以内积式模型和向量引擎成为了最近几年匹配领域技术革新的最重要技术(图像检索问题最早就是采用的这种方法)。尤其是去年Facebook的Faiss框架开源。
高阶深度学习大部分都不可划成内积形式,比如CTR预估里用户和商品特征交叉非常有用,大部分不可用内积表示。
在具体实践中,向量检索算法要求User和Item能够映射到统一的向量空间。User输入信息和Item输入信息一般并不同质,如何保证映射到统一目标向量空间下的检索精度对映射算法提出了严格的要求,换言之,统一的向量空间映射对运用向量检索来解决推荐问题带来了精度损失的风险。
III)下一代匹配和推荐技术
一种更通用的匹配和推荐算法框架,它允许容纳任意先进模型而非限定内积形式,并且能够对全量候选集进行更好的匹配。
技术方案
概率连乘树并不适用匹配问题:
第二代基于内积模型向量检索的方案,限定模型结构以实现检索效率的提升,因此要想进一步释放模型能力就必须使得整体检索结构的设计与模型结构的设计解耦(向量内积检索与内积模型即是一种强耦合关联)。面对一个复杂问题,人脑常有的一个思考方式是先从大的层面入手,确定大方向后具体细化。我们也从这个角度入手,思考是否可以有一种从粗到细的检索方式,逐步判断并细化,最后给出最优推荐。基于这个思考,我们把探索方向定位在了使用层次化树结构增加检索效率上。
一系列的问题要解决:1、树结构是如何构建的;2,如何基于树进行匹配建模;3、如何围绕树结构实现高效的兴趣计算和检索。
1)HS方法解决了给定上文进行节点概率快速计算的问题,即通过引入Hierarchical Structure避免了对全量候选集的逐一计算和归一化,直接计算得到节点概率。而任何贪心的检索方法如BeamSearch,都无法保证检索得到的TopK是全局最优的,即HS建模方式下每一层的最优连乘并不保证全局最优。
2)与此同时,HS方法在建树时往往会考虑将某种具有相似关系(语义、词频等)的节点靠近组成兄弟。而HS方法在计算路径概率时把每一个节点的概率计算看作是二分类问题,用于判断接下来选择哪个孩子节点继续走下去。在单层节点上,匹配和推荐要求的是该层上的全局序判别问题,而HS方法解决的是同一父亲下两个孩子节点谁更优的问题。
在采用HS方法进行匹配和推荐的实践中,包括YouTube团队在他们的内积模式向量检索做匹配的文章中提到了他们采用HS方法学习用户和候选Video的偏好关系,但是效果并不理想。而我们最先也在阿里妈妈广告测试集上进行了HS方法的尝试,效果也不如预期。
最大堆树的提出和构建:
假定全量候选集中的每一个商品都是一个叶子节点,当前用户对所有叶子节点背后都存在一个真实的兴趣度,用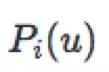 表示。我们并不知道其具体值,只有根据概率采样出来的样本(用户真实反馈)。因此我们创新性的提出了兴趣最大堆树(Max-heap like Tree)的概念,其定义树上节点的概率如下:
表示。我们并不知道其具体值,只有根据概率采样出来的样本(用户真实反馈)。因此我们创新性的提出了兴趣最大堆树(Max-heap like Tree)的概念,其定义树上节点的概率如下:
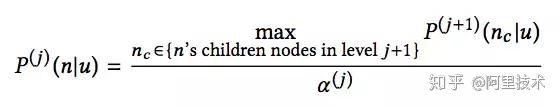 公式(2)
公式(2)
即用户对第j层父亲节点兴趣的偏好概率正比于用户对第j+1层孩子节点兴趣的偏好概率最大值。
对于任意一个用户有行为的叶子节点采样i,隐含了叶子层的序:。根据我们的树节点概率定义(最大堆性质),可以向上递归推出每层节点概率的序。根据这个序我们进行负样本采样,用深度学习模型基于这个采样去学习,以逼近最大堆树上每层的序。
全局分类器的设计理念:
在检索过程中,我们只需要每一层的节点概率序确定TopK即可,这里面需要特别说明的是虽然每一层的TopK候选集由上层父亲决定,但该层TopK的排序选取本身并不受父辈的影响,也即每一层的TopK排序都是独立的,父辈的排序分数不参与子辈的排序计算,这一点也是我们的方案区别与概率连乘树在计算形式上的不同。
以上的综合设计使得对全库TopK检索的计算次数限制在log(候选集规模)量级,有效控制了N的大小,而且单次计算并不要求限定于内积等简单形式,从而允许其容纳更先进的模型。
最大堆树背后的方法论:
最大堆树结构定义背后描述的直观意义是用户兴趣的层次结构,如果用户对具体的商品感兴趣,例如iPhone,那么用户对更高层的节点,例如iPhone所在的类别--手机,也是感兴趣的。用户的兴趣结构具有天然的层次性。
综上所述,从最大堆树结构定义出发,我们提出了Tree-based Deep Match(以下简称TDM)算法框架(图1)。TDM以淘宝商品体系为初始化依托,自顶向下构造从粗到细的兴趣层次树(Tree),并在此基础上应用深度学习网络进行用户兴趣的推荐建模,赋能单点计算上的复杂模型,运用层次检索方法实现全量候选上的用户TopK商品兴趣推荐。
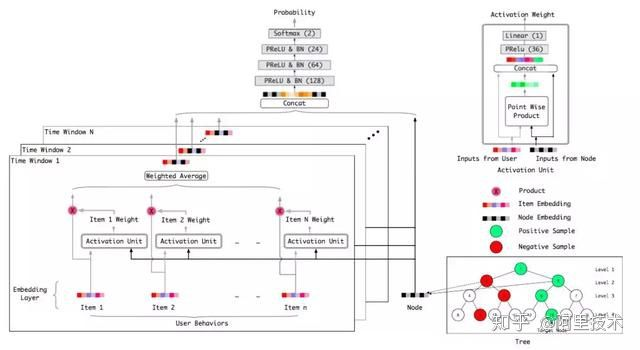
方案细节
一,模型训练
我们需要在树的每一层建立一个全局分类器,计算该层节点概率的序,得到最优TopK个候选。我们选择负样本采样(Negative Sampling)的方式进行样本生成,以最大似然估计的方式对这些分类器进行训练。

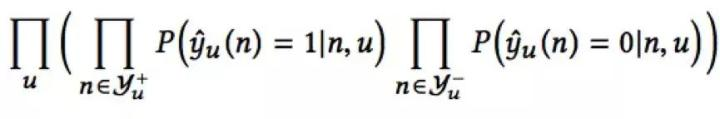
相对应的,我们有损失函数为:
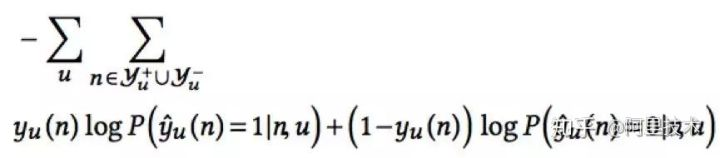
其中,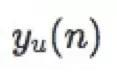 代表用户u对节点n偏好的真实Label(0或1)。
代表用户u对节点n偏好的真实Label(0或1)。
在实际的样本构建中,我们采用了用户当天的行为叶子节点及其上溯路径上的祖先节点为正样本,而随机采样各个正样本节点的同层兄弟为负样本。在特征上我们使用了(0,8 * 24)小时的行为特征作为用户特征输入。
二,结果预测
层次检索算法:对于最终要求K个叶子目标推荐的情况下,选择当前层概率最高的K个节点,然后往下层扩展他们的孩子节点,对下层孩子节点进行概率估计,选取概率最高的K个,递归计算和选取直至所有路径都到达叶子层,最后从候选叶子集合(可能大于2K个)中取概率最高的K个返回即可。在TDM的实验中,层次TopK的检索被实验证明是有效的,甚至是优于平层暴力(Brute-force)检索的,这一点也侧面验证了兴趣树的层次结构可以有效促进检索的精度提升.

三,树联合训练
在实践中我们发现,基于淘宝商品体系为依托构造的树所得的TDM模型,在离线评估指标(召回率等)上会显著的优于随机构造的树所得的TDM模型,这一结果印证了树结构对TDM的巨大影响。我们在这基础上进行了树-模型联合训练的迭代实验,实验结果证明联合训练的模型可以取得比初始模型更优的效果提升(10%+),具体而言我们建立了如下的联合训练迭代方法:

图3具体展现了树联合训练在离线测试上的效果。
 图3 联合训练树模型和初始树模型的测试结果对比
图3 联合训练树模型和初始树模型的测试结果对比
实验效果
我们在公开数据集MovieLens和阿里妈妈构建的广告数据集UserBehavior上进行了TDM的实验对比,评价指标包括精度、召回率、精度召回率调和F1和新颖性等方面。
一,召回率评估
对比效果中我们可以看出:
1)无论是MovieLens上还是UserBehavior上,带Attention的TDM在召回率上都显著超越了现有推荐匹配算法,包括YouTube向量检索方法和Item-CF统计规则方法;
2)在基础product-DNN版本上引入更复杂和先进的深度模型(节点Embedding进入输入层和引入Attention)可以进一步大幅提升召回率。
二,新颖性评估
可以看到,attention-DNN的TDM方案在全部的指标上都有极大提升,包括相对于广泛使用的Item-CF方案召回率提升292%,相对于业界主流YouTube方案召回率提升34%,而经过树联合训练后Learnt Tree TDM方案效果进一步得到提升,包括相对于广泛使用的Item-CF方案召回率提升355%,相对于业界主流YouTube方案召回率提升56%。
三,树结构对效果的促进
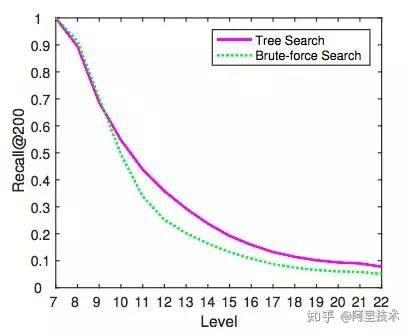 图4 树检索和暴力检索在每一层上的召回率对比
图4 树检索和暴力检索在每一层上的召回率对比
在实验中我们发现树的这种层次化结构可以更加促进效果的提升。从图4我们可以看到在树层数达到一定高度(9+)后TopK层次检索方法(图2)在召回率上会显著优于在该层上的暴力检索方法。究其原因,我们认为TDM的层次化树检索有效防止了上层差的节点对下层节点序计算的影响,将下层候选圈定在上层好的(TopK)节点的孩子中,相对于暴力检索大大降低了序计算的难度,使其具有更好的分类能力,实现召回效果的提升。
PS: 我们也对TDM进行了系统总结并撰写成了论文发表于arXiv上,请大家不吝指正! Learning Tree-based Deep Model for Recommender Systems https://arxiv.org/abs/1801.02294
阿里Tree-based Deep Match(TDM) 学习笔记的更多相关文章
- Deep Learning.ai学习笔记_第五门课_序列模型
目录 第一周 循环序列模型 第二周 自然语言处理与词嵌入 第三周 序列模型和注意力机制 第一周 循环序列模型 在进行语音识别时,给定一个输入音频片段X,并要求输出对应的文字记录Y,这个例子中输入和输出 ...
- Deep Learning.ai学习笔记_第一门课_神经网络和深度学习
目录 前言 第一周(深度学习引言) 第二周(神经网络的编程基础) 第三周(浅层神经网络) 第四周(深层神经网络) 前言 目标: 掌握神经网络的基本概念, 学习如何建立神经网络(包含一个深度神经网络), ...
- 深度学习在美团点评推荐平台排序中的应用&& wide&&deep推荐系统模型--学习笔记
写在前面:据说下周就要xxxxxxxx, 吓得本宝宝赶紧找些广告的东西看看 gbdt+lr的模型之前是知道怎么搞的,dnn+lr的模型也是知道的,但是都没有试验过 深度学习在美团点评推荐平台排序中的运 ...
- Deep Learning.ai学习笔记_第四门课_卷积神经网络
目录 第一周 卷积神经网络基础 第二周 深度卷积网络:实例探究 第三周 目标检测 第四周 特殊应用:人脸识别和神经风格转换 第一周 卷积神经网络基础 垂直边缘检测器,通过卷积计算,可以把多维矩阵进行降 ...
- Deep Learning.ai学习笔记_第三门课_结构化机器学习项目
目录 第一周 机器学习策略(1) 第二周 机器学习策略(2) 目标:学习一些机器学习优化改进策略,使得搭建的学习模型能够朝着最有希望的方向前进. 第一周 机器学习策略(1) 搭建机器学习系统的挑战:尝 ...
- Deep Learning.ai学习笔记_第二门课_改善深层神经网络:超参数调试、正则化以及优化
目录 第一周(深度学习的实践层面) 第二周(优化算法) 第三周(超参数调试.Batch正则化和程序框架) 目标: 如何有效运作神经网络,内容涉及超参数调优,如何构建数据,以及如何确保优化算法快速运行, ...
- SP10707 COT2 - Count on a tree II [树上莫队学习笔记]
树上莫队就是把莫队搬到树上-利用欧拉序乱搞.. 子树自然是普通莫队轻松解决了 链上的话 只能用树上莫队了吧.. 考虑多种情况 [X=LCA(X,Y)] [Y=LCA(X,Y)] else void d ...
- Linux命令学习笔记目录
Linux命令学习笔记目录 最近正在使用,linux,顺便将用到的命令整理了一下. 一. 文件目录操作命令: 0.linux命令学习笔记(0):man 命令 1.linux命令学习笔记(1):ls命令 ...
- springmvc学习笔记--支持文件上传和阿里云OSS API简介
前言: Web开发中图片上传的功能很常见, 本篇博客来讲述下springmvc如何实现图片上传的功能. 主要讲述依赖包引入, 配置项, 本地存储和云存储方案(阿里云的OSS服务). 铺垫: 文件上传是 ...
随机推荐
- Django项目运行时出现self.status.split(' ',1)[0], self.bytes_sent,ConnectionAbortedError: [WinError 10053] 你的主机中的软件中止了一个已建立的连接。
[02/Nov/2018 09:46:51] "GET /new_industry/category HTTP/1.1" 200 2891792 Traceback (most r ...
- HackThirteen 在onCreate()方法中获取View的宽度和高度
1.概要: Android源代码中很多模块都使用了post()方法,深入理解框架曾运行机制对于避开类似于本例中的小陷阱是很重要的 2.问题提出: 如果开发一些依赖于UI控件的宽和高的功 ...
- ZeroSSL,支持多域名的在线 Let's Encrypt SSL 证书申请工具
前言: 微信需要ssl证书,很多网站都有免费一年的证书:免费一年的证书叫做单域名证书,iis没办法配置多个子站点443端口:我有很多客户需要用我的的域名,同一个域名配置多个ssl,或者支持多个子域名: ...
- MVC 路由调试工具-RouteDebugger
MVC 路由调试工具-RouteDebugger 方案一: 在程序包控制台中执行命令 PM> Install-Package routedebugger 自动会在你的项目webconfig中& ...
- 内存布局------c++程序设计基础、编程抽象与算法策略
图中给出了在一个典型c++程序中如何组织内存的框架.程序中的指令(在底层都是按位存储的).全局变量.静态对象和只读常量往往被存储在静态去(static area)(第二个图中的数据段.代码段.值得注意 ...
- 201621123012 《Java程序设计》第7周学习总结
1. 本周学习总结 1.1 思维导图:Java图形界面总结 答: 1.2 可选:使用常规方法总结其他上课内容. 2.书面作业 1. GUI中的事件处理 1.1 写出事件处理模型中最重要的几个关键词. ...
- 《javascript 高级程序设计》 笔记2 8~章
chapter 8 BOM(浏览器对象模型) window对象 表示浏览器的一个实例. 直接在window对象上定义的属性可以通过delete操作符删除,而全局变量不可以. 窗口关系及框架 位置操作 ...
- 解决低版本Xcode不支持高版本iOS真机调试的问题
1.现象截图 Could not locate device support files. This iPhone 6s is running iOS 11.1 (15B93), which may ...
- 搭建 docker + nginx + keepalived 实现Web应用的高可用(亲测)
1. 环境准备 下载 VMware : https://www.vmware.com/go/getplayer-win 下载 Centos : https://mirrors.a ...
- EOS 智能合约 plublic key 转换
在做一个EOS 的action接口时,定义如下: void setbplist(const account_name bp_name, const uint64_t bp_time, const ...