scrapy安装和框架内容
在cdm中:直接,pip install scrapy
有可能让你升级一下pip先,就输入这个:python -m pip install --upgrade pip
当它报错的话,看看它是缺了什么,少啥补啥(我的是Python3.6.6,安装scrapy的时候报错,缺了twisted),注意选对Python版本就好,下面是各个模块的下载地址:
lxml:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
pyOpenSSL:
https://pypi.org/project/pyOpenSSL/#files
twisted:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
pywin32(这个不会提示你安装,但如果缺了的话,scrapy执行爬虫的时候会报错):
sourceforge.net/projects/pywin32/files/pywin32/Build%20220/(不一定能自动检测到Python3.6的exe)
https://pypi.org/project/pypiwin32/220/
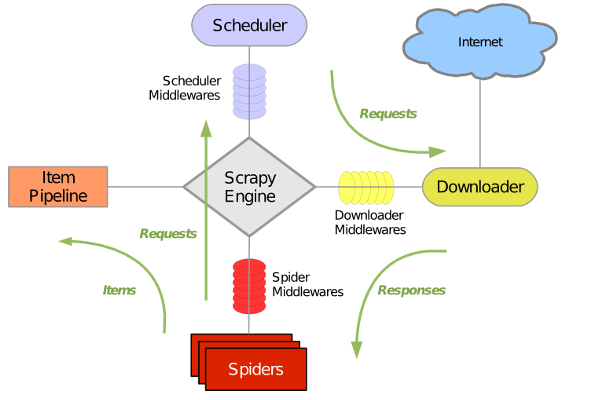
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
scrapy安装和框架内容的更多相关文章
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- Python的两个爬虫框架PySpider与Scrapy安装
Python的两个爬虫框架PySpider与Scrapy安装 win10安装pyspider: 最好以管理员身份运行CMD,不然可能会出现拒绝访问文件夹的情况! pyspider:pip instal ...
- python爬虫框架—Scrapy安装及创建项目
linux版本安装 pip3 install scrapy 安装完成 windows版本安装 pip install wheel 下载twisted,网址:http://www.lfd.uci.edu ...
- python Scrapy安装和介绍
python Scrapy安装和介绍 Windows7下安装1.执行easy_install Scrapy Centos6.5下安装 1.库文件安装yum install libxslt-devel ...
- 在windows下如何新建爬虫虚拟环境和进行scrapy安装
Scrapy是Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改.Sc ...
- Windows下安装Scrapy方法及常见安装问题总结——Scrapy安装教程
这几天,很多朋友在群里问Scrapy安装的问题,其实问题方面都差不多,今天小编给大家整理一下Scrapy的安装教程,希望日后其他的小伙伴在安装的时候不再六神无主,具体的教程如下. Scrapy是Pyt ...
- python网络爬虫(14)使用Scrapy搭建爬虫框架
目的意义 爬虫框架也许能简化工作量,提高效率等.scrapy是一款方便好用,拓展方便的框架. 本文将使用scrapy框架,示例爬取自己博客中的文章内容. 说明 学习和模仿来源:https://book ...
- 第五篇 scrapy安装及目录结构,启动spider项目
实际上安装scrapy框架时,需要安装很多依赖包,因此建议用pip安装,这里我就直接使用pycharm的安装功能直接搜索scrapy安装好了. 然后进入虚拟环境创建一个scrapy工程: (third ...
随机推荐
- Model View Controller (MVC) Overview
By Rakesh Chavda on Jul 01, 2015 What is MVC?Model View Controller is a type of user interface archi ...
- 第19章-使用Spring发送Email
1 配置Spring发送邮件 Spring Email抽象的核心是MailSender接口.顾名思义,MailSender的实现能够通过连接Email服务器实现邮件发送的功能,如图19.1所示. 图1 ...
- Linq to SQL Like Operator
As a response for customer's question, I decided to write about using Like Operator in Linq to SQL q ...
- MongoDB整理笔记の安装及配置
1.官网下载 地址:http://www.mongodb.org/downloads mongodb-linux-x86_64-2.4.9.tgz (目前为止,64位最新版本) 2.解压 切换到下载目 ...
- Glide4.0使用
导入 dependencies { compile 'com.github.bumptech.glide:glide:4.0.0' compile 'com.android.support:suppo ...
- HTML5 Canvas核心技术图形动画与游戏开发 ((美)David Geary) 中文PDF扫描版
<html5 canvas核心技术:图形.动画与游戏开发>是html5 canvas领域的标杆之作,也是迄今为止该领域内容最为全面和深入的著作之一,是公认的权威经典.amazon五星级超级 ...
- 百度地图离线API及地图数据下载工具
全面介绍,请看下列介绍地址,改写目前最新版本的百度V2.0地图,已全面实现离线操作,能到达在线功能的95%以上 http://api.jjszd.com:8081/apituiguang/gistg. ...
- 「HAOI2016」放棋子
题目链接 戳这 前置知识 错位排序 Solution 我们可以观察发现,每一行的障碍位置对答案并没有影响. 于是我们可以将此时的矩阵化成如下形式: \[ 1\ \ 0\ \ 0\ \ 0\\ 0\ \ ...
- C++ TIM或者QQ 自动发送消息
简单写了一下 很简单的demo 闲着没事干 #include "stdafx.h" #include <thread> #include <Windows.h&g ...
- C# LINQ(7)
大部分的LINQ的关键字都说了,最后说一下排序吧. LINQ的是查询的利器. 那么查询就会有排序. 所有LINQ提供了两种简单的排序.倒序和默认排序. 关键字是: orderby ascending ...