攻城狮在路上(陆)-- 配置hadoop本地windows运行MapReduce程序环境
本文的目的是实现在windows环境下实现模拟运行Map/Reduce程序。最终实现效果:MapReduce程序不会被提交到实际集群,但是运算结果会写入到集群的HDFS系统中。
一、环境说明:
操作系统:win7
eclipse:Version: Mars Release (4.5.0)
hadoop:2.5.1
二、预备文档(仅是说明,以第三步为准):
System.setProperty("HADOOP_USER_NAME", "root");
本地测试环境(windows):
在windows的hadoop目录bin目录有一个winutils.exe
1、在windows下配置hadoop的环境变量
2、拷贝debug工具(winutils.exe)到HADOOP_HOME/bin
3、修改hadoop的源码 ,注意:确保项目的lib需要真实安装的jdk的lib
4、MR调用的代码需要改变:
a、src不能有服务器的hadoop配置文件
b、在调用是使用:
Configuration config = new Configuration();
config.set("fs.defaultFS", "hdfs://node7:8020");
config.set("yarn.resourcemanager.hostname", "node7");
三、基本步骤说明:
1、首先下载hadoop包,这里使用的是hadoop-2.5.1。解压后的路径是:E:\hadoop\hadoop-2.5.1
2、下载winutils.exe。将该软件拷贝到E:\hadoop\hadoop-2.5.1\bin下
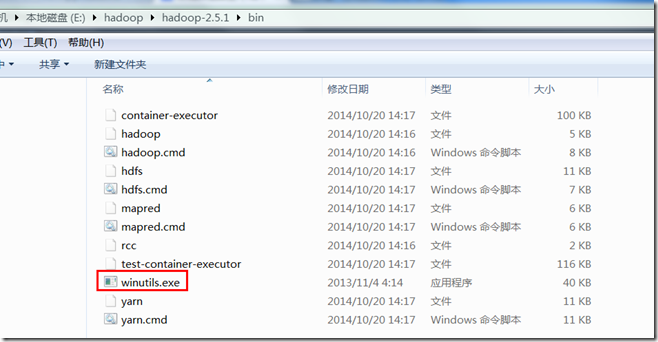
3、在windows中配置HADOOP_HOME环境变量为E:\hadoop\hadoop-2.5.1,并加入到path环境变量中。
4、修改hadoop源码,在新建的Java project中拷贝下面路径的Java代码。路径保持和原来一致。
org/apache/hadoop/io/nativeio/NativeIO.java
org/apache/hadoop/mapred/YARNRunner.java
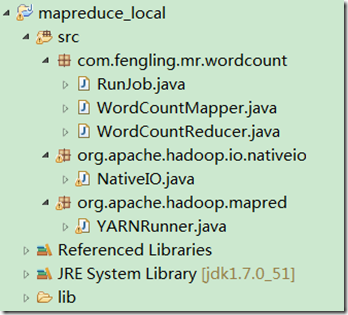
5、在java project的buildpath中设置,jdk不要使用eclipse自带的,修改为自己本地安装的Jdk。
6、其他限制条件:
A、src中不能有服务器的hadoop配置文件。
B、在调用时使用下面的代码:根据实际配置进行修改下面的参数
System.setProperty("HADOOP_USER_NAME", "root");
Configuration config = new Configuration();
config.set("fs.defaultFS", "hdfs://node7:8020");
config.set("yarn.resourcemanager.hostname", "node7");
7、运行代码:在eclipse中以DEBUG执行main方法即可。可以在Mapper和Reduce中打断点调试。
攻城狮在路上(陆)-- 配置hadoop本地windows运行MapReduce程序环境的更多相关文章
- 攻城狮在路上(壹) Hibernate(一)--- 软件环境、参考书目等一览表
1.环境配置: web容器:tomcat6.0 JDK:1.7.0_51 hibernate:4.2.0.Final 操作系统:WIN8 64位 数据库:mysql Ver 14.12 Distri ...
- 攻城狮在路上(叁)Linux(零)--- 软件环境、参考书目等一览表
1.参考书目:鸟哥的Linux私房菜. 2.环境: Cent_os.
- 攻城狮在路上(贰) Spring(一)--- 软件环境、参考书目等一览表
一.软件环境: 二.参考书目: <Spring 3.X 企业应用开发实战> 陈雄华.林开雄著 电子工业出版社出版 三.其他说明: spring 源码地址:https://github.co ...
- 高可用Hadoop平台-运行MapReduce程序
1.概述 最近有同学反应,如何在配置了HA的Hadoop平台运行MapReduce程序呢?对于刚步入Hadoop行业的同学,这个疑问却是会存在,其实仔细想想,如果你之前的语言功底不错的,应该会想到自动 ...
- 攻城狮在路上(陆)-- hadoop分布式环境搭建(HA模式)
一.环境说明: 操作系统:Centos6.5 Linux node1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 ...
- Hadoop YARN上运行MapReduce程序
(1)配置集群 (a)配置hadoop-2.7.2/etc/hadoop/yarn-env.sh 配置一下JAVA_HOME export JAVA_HOME=/home/hadoop/bigdata ...
- 攻城狮在路上(陆)-- hadoop单机环境搭建(一)
一.环境说明: 操作系统:Centos6.5 Linux node1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86 ...
- 攻城狮在路上(陆)-- 提交运行MapReduce程序到hadoop集群运行
此种方式不能直接在eclipse中调试代码. 首先需要在src下放置服务器上的hadoop配置文件:core-site.xml\yarn-site.xml\hdfs-site.xml\mapred-s ...
- 攻城狮在路上(叁)Linux(十一)--- 用户与用户组、文件权限、目录配置
一.用户与用户组: 3个概念:文件所有者(user).用户组(group).其他人(others). /etc/passwd <==存放所有的用户名 /etc/shadow <==存放 ...
随机推荐
- EmployeeTest
package fourthf; public class EmployeeTest { public static void main(String[] args) { // TODO Auto-g ...
- 原生JS会跳动的电子表
一个会跳动的电子表,源码--time.html 图片--img github地址:https://github.com/1056237661/practiceCode <!DOCTYPE h ...
- 2.3switch case 语句注意事项。
#include<stdio.h> int main() { void action1(int, int),action2(int, int); char ch; , b=; ch = g ...
- 【译】使用 CocoaPods 模块化iOS应用
原文翻译自:Using CocoaPods to Modularize a Big iOS App 为你的移动应用选择正确的架构是一件相当大的事情,这会对你的工作流程造成影响,陷入面对的问题,可能是一 ...
- 代码质量管理工具——SonarQube
写在前面 SonarQube(简称Sonar)是管理代码质量的开放平台,它可以快速地对代码质量进行分析,并给出合理的解决方案,提高管理效率,保证代码质量. SonarQube的流行,在于以下几点: 开 ...
- DX系列之TreeList
参考资料: DevXpress控件: 第三篇: 将 父子 关系进行到底
- FSM(状态机)、HFSM(分层状态机)、BT(行为树)的区别
游戏人工智能AI中最常听见的就是这三个词拉: FSM 这个不用说拉,百度一大堆解释, 简单将就是将游戏AI行为分为一个一个的状态,状态与状态之间的过渡通过事件的触发来形成. 比如士兵的行为有“巡逻”, ...
- Hash算法专题
1.[HDU 3068]最长回文 题意:求一个字符串(len<=110000)的最长回文串 解题思路:一般解法是manacher,但是这一题用hash也是可以ac的 假设当前判断的是以i为中心偶 ...
- centos7 使用updatedb和locate命令
centos7默认是没有安装mlocate的,所以无法使用这两个命令 yum install mlocate 就可以了 参考:https://fedorahosted.org/mlocate/
- Spark 官方文档(2)——集群模式
Spark版本:1.6.2 简介:本文档简短的介绍了spark如何在集群中运行,便于理解spark相关组件.可以通过阅读应用提交文档了解如何在集群中提交应用. 组件 spark应用程序通过主程序的Sp ...