ofo容器pass架构分享
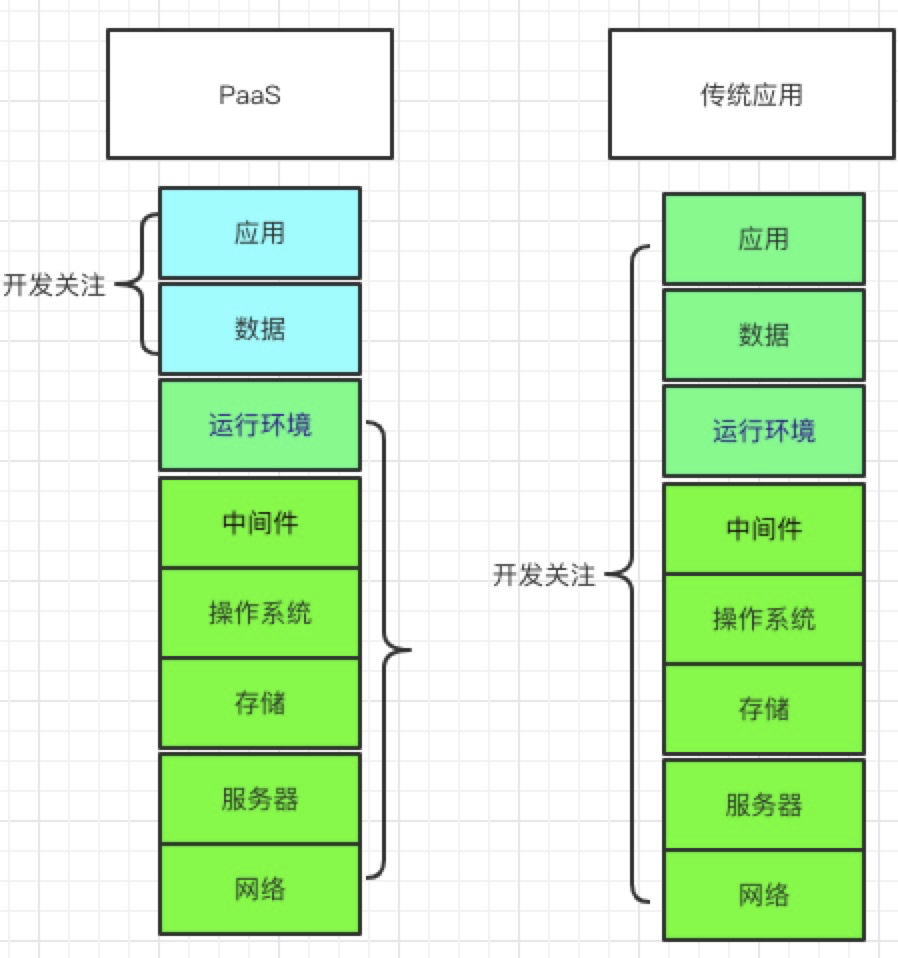
一、我们先要了解一下,为什么企业需要一个paas平台?或者可以说paas到底能做什么?
1.1 我们先来了解一下paas到底是什么?
PaaS是Platform-as-a-Service的缩写,意思是平台即服务,
首先,在了解Paas之前需要知道什么是云计算,云计算是指基于互联网网络,通过虚拟化(xen OpenStack)统一管理和调度计算,国内厂商如:阿里云/aws/ucloud/等等
目前云计算三大类:
1.基础设施即服务(IaaS)
2.平台即服务(PaaS)
3.软件即服务(SaaS)
1.2企业为什么需要一个PaaS?
平台即服务(PaaS)
PaaS提供应用服务引擎,将软件研发测试和运维的平台作为一种服务提供,应用程序接口,开发人员基于这些服务构建业务应用。从运维和开发角度来说,这意味着无需运维搭建环境,开发也不会因为不同平台兼容性方面遇到困扰。
二、ofo for PaaS(kubernetes)平台介绍
2.1 平台简介
- 提供多种应用发布方式和持续交付能力并支持微服务架构。
- 平台自身组件支持实时横向扩展,一键式应用快速部署。
- PaaS简化了集群管理,监控、日常运维操作简化
- 整合了CI/CD/以及云厂商的虚拟化、存储、网络和安全
- 业务高峰自动扩缩容,根据应用的负载情况,动态加载应用实例;
- kubernetes HPA pod根据配置阀值自动扩缩容,node节点cpu配置阀值,集成各个云厂商api,自动扩容node节点。
- 保证公司业务1分钟内自动恢复。全年故障率降低。
- 更高的资源利用率 node节点单机性能最大化
- 节省服务器成本百分之40-60。
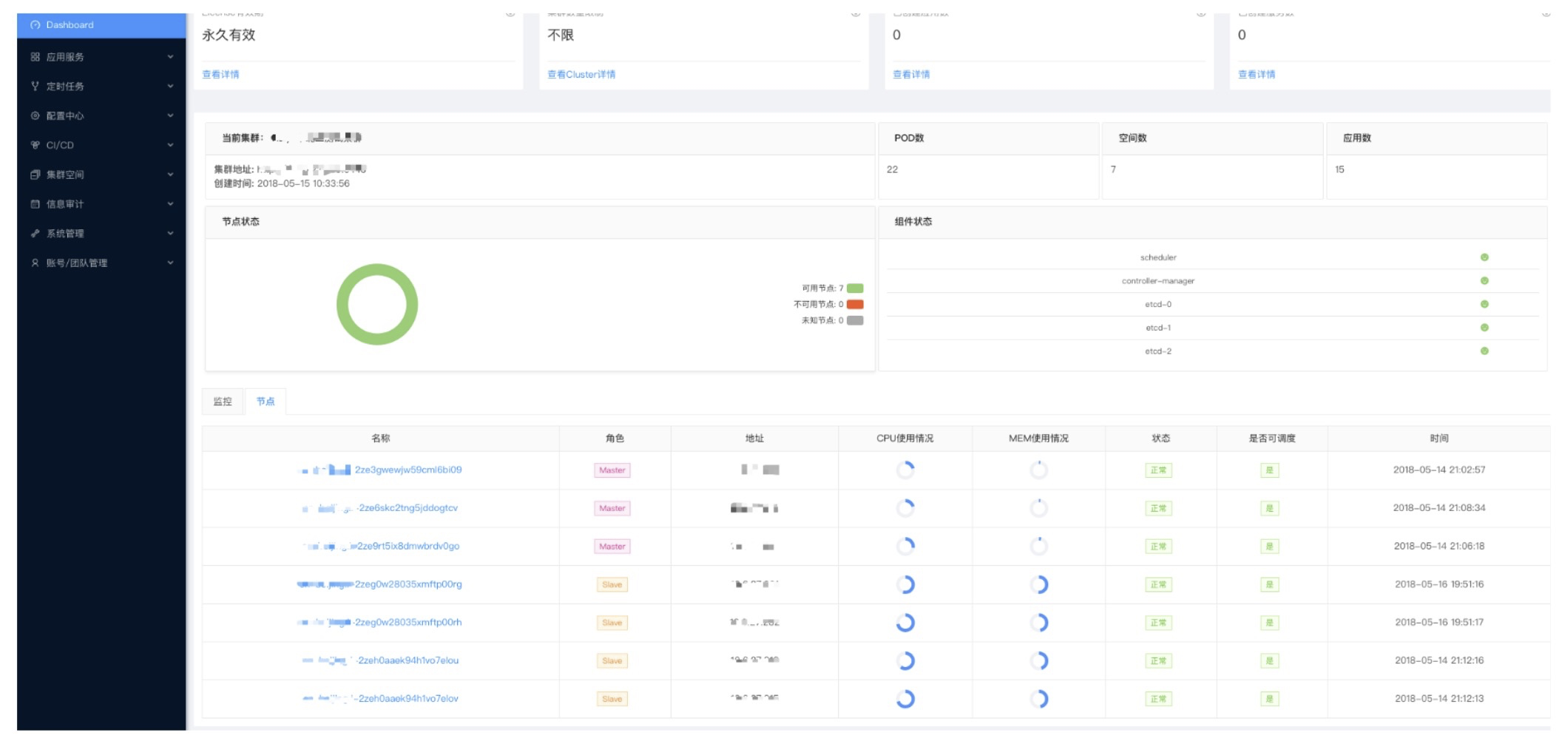
2.2 Dashboard
- 显示当前集群
- 节点状态
- 节点监控
- 组件状态
- POD、namespace等等
2.3 应用服务
- pod管理
- service管理
2.4 定时任务
- kubernetes 、cronjob管理
2.5 配置中心
- configmap管理
2.6 CI/CD
- DevOps 持续交付
- 配合 Jenkins 自动完成从代码提交到应用部署的 DevOps
- 实现从代码变更到代码构建,镜像构建和应用部署的全流程自动化,持续反馈
- 每次集成或交付,都会第一时间将结果实时反馈
2.7 资源审计监控
- PAAS平台操作审计
- Webshell操作审计
- 资源利用率Dashboard
- 容器资源使用报表
2.8 高级功能
- 特权容器:容器性能优化,问题诊断strace
- 主机网络:使用宿主机网络环境
- 初始化容器:性能优化,容器内最小权限
- 创建网络服务:对集群内(外)提供网络服务
- 容器Webshell:登录容器,问题诊断
 

三、生产环境高并发线上业务容器化
我们在生产环境下运维kubernetes 已经有一段时间了,我们7*24 全天候 为每一个业务保驾护航ofo容器云 (简称Ruly)我们底层基于某云容器基础服务,以及自建机房IDC、通过调用云平台API以及RO模板快速创建管理docker实例。
- 我们team在高并发业务场景下做了哪些优化
- 容器化后比之前性能要好,同配置下延迟更低、故障恢复时间更快,服务成本降低
- 分享个线上case 我们team在高并发业务场景下做了哪些优化 3.1 优化:基础篇性能测试
 

 

我们team在高并发业务场景下做了哪些优化
  3.1 优化:基础篇性能测试
 3.1 优化:基础篇性能测试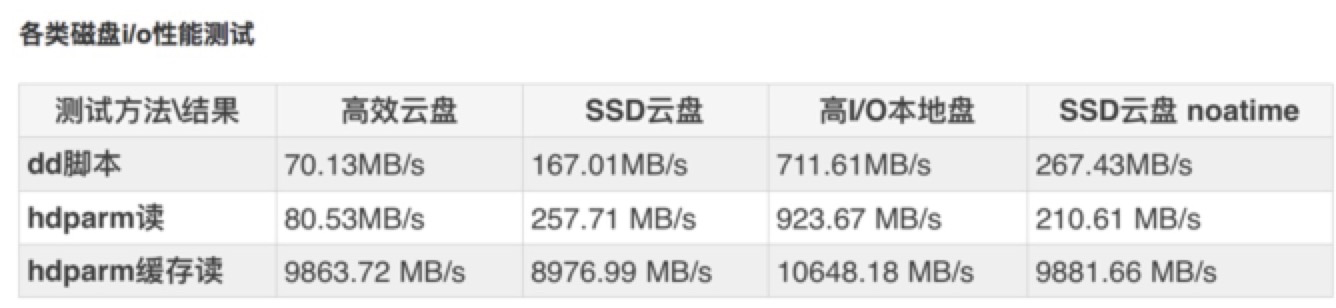

选择比较适合的实例规格或机器型号. 云服务器需支持多队列网卡
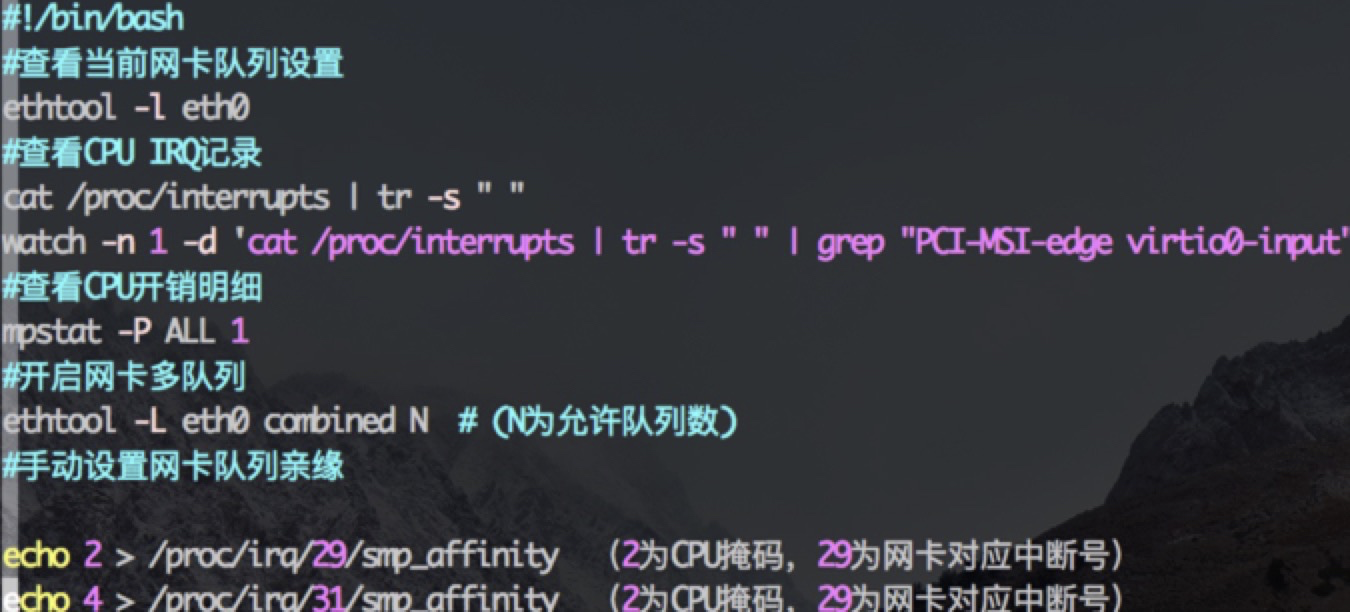
3.2 系统层面优化
操作系统优化:支持大并发,单集群2000节点
K8s&容器层面优化:支持大并发,基础镜像制作优化等等
Principle:最小权限,优先跑满容器资源限制
docker宿主目录直接跑在默认/var/lib/docker下 长期跑下来会导致系统盘异常。导致down机等。因此我们做了一下调整,自定义镜像(lvm) 增加可扩展性
3.3 内核参优化
docker进程异常Dead状态 at centos 7.4
* 增加fs.may_detach_mounts
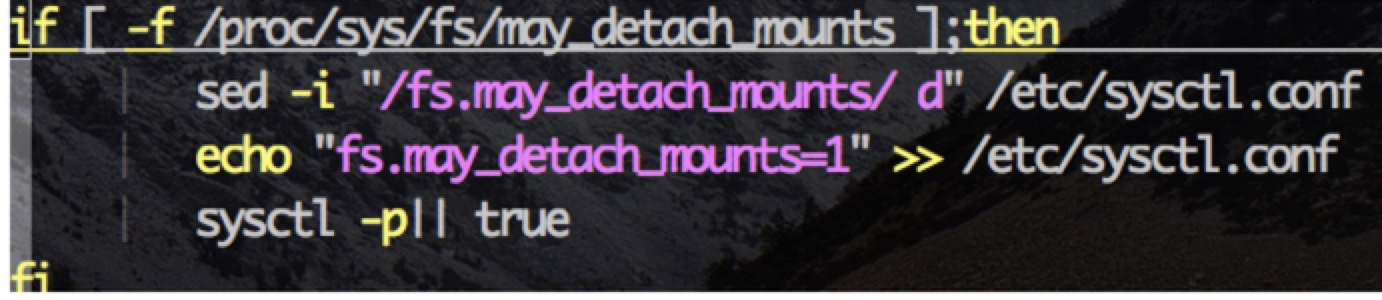
 

总结:我们做了大量业务压测,以及云平台slb 、ecs idc 机器做了大量的性能调优,对业务的优化,配合开发同学做了大量的debug 才使得我们业务能在容器稳定的运行
3.4 容器化后比之前性能要好,同配置下延迟更低、故障恢复时间更快,服务成本降低
容器vs传统部署模式 (最后两个0.98ms 和0.96ms 为容器
 
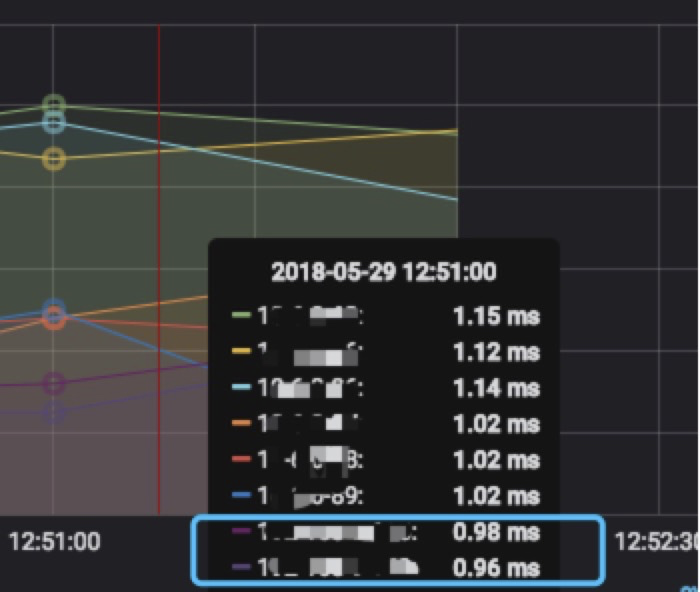
3.5 分享个线上case
在某某天一个凌晨4点,突然接到短信报警,此时大家都在深睡,早上八点起床后发现收到了两条报警,一条是磁盘80%的告警,一条是磁盘恢复的报警,我们可以想象一下哈,如果你业务部署到了服务器,将会发生什么,4-8点完全可以吧机器磁盘空间写满,导致业务异常。机器oom 为什么容器会自动恢复呢。原因和简单,kubernetes自带有异常的pod自动驱逐,当磁盘空间大于百分之80 他会判定这个pod是有问题的。
解释:
本地磁盘是一个 BestEffort 资源,kubelet 会在 DiskPressure 的情况下,kubelet 会按照 QoS 进行评估。如果 Kubelet 判定缺乏 inode 资源,就会通过驱逐最低 QoS 的 Pod 的方式来回收 inodes。如果 kubelet 判定缺乏磁盘空间,就会通过在相同 QoS 的 Pods 中,选择消耗最多磁盘空间的 Pod 进行驱逐。
四、kubernetes之生产环境etcd高可用、备份、监控等
4.1 要说到kubernetes,就一定要聊聊etcd ,他存储了于整个kubernetes的信息
etcd是一个高可用的键值存储系统,主要用于共享配置和服务发现。etcd是由CoreOS开发并维护的,灵感来自于 ZooKeeper 和 Doozer,它使用Go语言编写,并通过Raft一致性算法处理日志复制以保证强一致性。
etcd可以用于配置共享和服务发现。
 

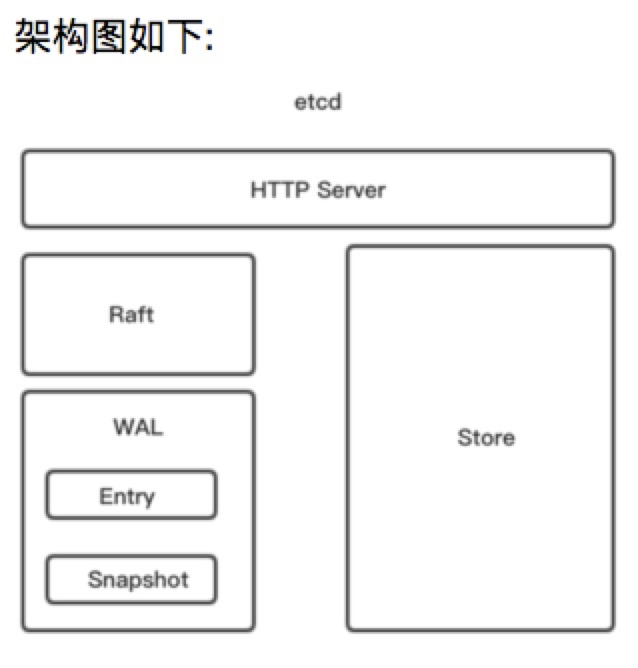
4.2 etcd主要分为四个部分:
HTTP Server:用于处理用户发送的API请求以及其他etcd节点的同步与心跳信息请求
Store:存储,用于处理etcd支持的各类功能的事务,包括数据索引,节点状态变更,事件处理与执行等。它是etcd对用于提供的大多数API功能的具体实现
Raft: Raft强一致算法的具体实现,是etcd的核心
WAL: Write Ahead Log(日志先行),WAL是一种实现事务日志的标准方法。etcd通过WAL进行持久化存储,所有的数据在提交之前都会事先记录日志 a. Snapshot: 防止数据过多而进行的状态快照 b. Entry: 存储的具体的日志内容
 

4.3 etcd中的术语:
- Raft: etcd所采用的保证分布式系统强一致的算法
- Node: 一个Raft状态机实例
- Member: 一个etcd实例,管理一个Node,可以为客户端请求提供服务
- Cluster: 多个Member构成的可以协同工作的etcd集群
- Peer: 同一个集群中,其他Member的称呼
- Client: 向etcd集群发送HTTP请求的客户端
- WAL: 预写日志,是etcd用于持久化存储的日志格式
- Snapshot: etcd防止WAL文件过多而设置的快照,存储etcd数据状态
- Proxy: etcd的一种模式,可以为etcd提供反向代理服务
- Leader: Raft算法中通过竞选而产生的处理所有数据提交的节点
- Follower: Raft算法中竞选失败的节点,作为从属节点,为算法提供强一致性保证
- Candidate: Follower超过一定时间接收不到Leader节点的心跳的时候,会转变为Candidate(候选者)开始Leader竞选
- Term: 某个节点称为Leader到下一次竞选开始的时间周期,称为Term(任界,任期)
- Index: 数据项编号, Raft中通过Term和Index来定位数据
4.4 Raft 状态机
Raft集群中的每个节点都处于一种基于角色的状态机中。具体来说,Raft定义了节点的三种角色: Follower、Candidate和Leader。
- Leader(领导者): Leader节点在集群中有且仅能有一个,它负责向所有的Follower节点同步日志数据
- Follower(跟随者): Follower节点从Leader节点获取日志,提供数据查询功能,并将所有修改请求转发给Leader节点
- Candidate(候选者): 当集群中的Leader节点不存在或者失联之后,其他Follower节点转换为Candidate,然后开始新的Leader节点选举
这三种角色状态之间的转换,如下图:
 
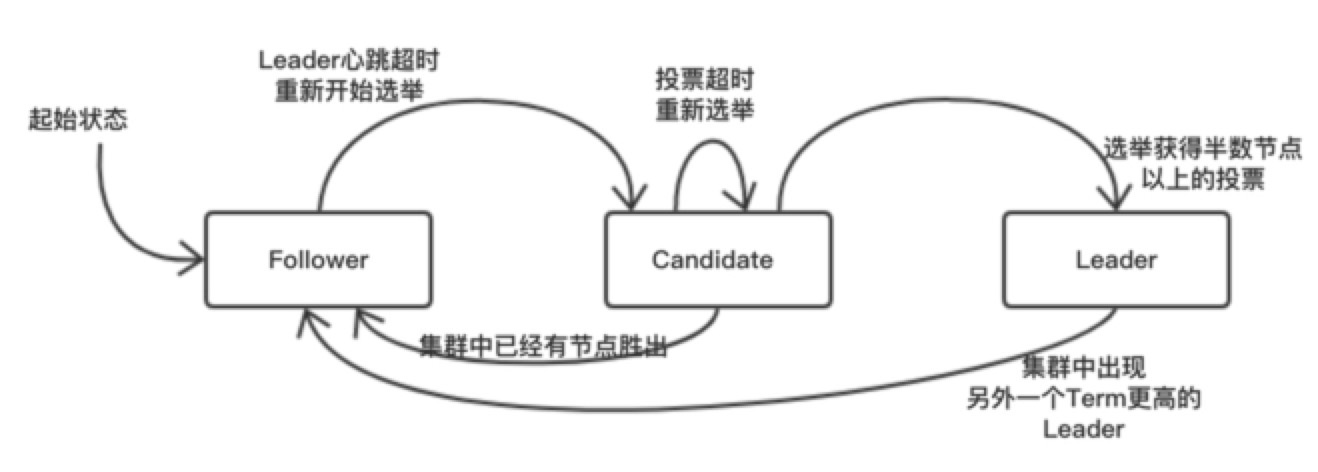
一个 Raft 集群包含若干个服务器节点;通常是 5 个,这允许整个系统容忍 2 个节点的失效。在任何时刻,每一个服务器节点都处于这三个状态之一:领导人、跟随者或者候选人。在通常情况下,系统中只有一个领导人并且其他的节点全部都是跟随者。跟随者都是被动的:他们不会发送任何请求,只是简单的响应来自领导者或者候选人的请求。领导人处理所有的客户端请求(如果一个客户端和跟随者联系,那么跟随者会把请求重定向给领导人)
每次成功选举,新的Leader的Term(任届)值都会比之前的Leader增加1。当集群中由于网络或者其他原因出现分裂后又重新合并的时候,集群中可能会出现多于一个的Leader节点。此时,Term值更高的节点才会成为真正的Leader。
4.5 etcd client
主要包含以下几个功能:
- Cluster:向集群里增加etcd服务端节点之类,属于管理员操作。
- KV:我们主要使用的功能,即操作K-V。
- Lease:租约相关操作,比如申请一个TTL=10秒的租约。
- Watcher:观察订阅,从而监听最新的数据变化。
- Auth:管理etcd的用户和权限,属于管理员操作。
- Maintenance:维护etcd,比如主动迁移etcd的leader节点,属于管理员操作
4.6.etcd 运维、与备份

- 安装就不在这里详细介绍了。简单介绍下日常运维以及备份
一、查看集群中的节点
ETCDCTL_API=3 etcdctl --endpoints=https://xxx.xx.xx.xx --cacert=ca.pem --cert=etcd-client.pem --key=etcd-client-key.pem --write-out=table member list
二、添加节点
使用etcdctl member add node-name --peer-urls="https://xxx:2380"添加节点,生成变量。
1.准备新机器, 将上一步生成的配置文件变量,写到新节点,尤其是集群状态为existing。(目标节点的数据目录要清空)
2.生成用于集群节点通信的SSL证书
3.生成用于客户端和节点通信的证书
4.启动并检查
三、生产环境建议
建议采取多台etcd集群至5台,保证多个节点挂掉不会影响使用
四、etcd 备份
 

配合 cronjob nfs 或 云共享储存 建议分钟级别保留
4.7. etcd 监控
推荐promtheus + grafana 可自定义promtheus etcd 报警规则,或grafana alert 插件报警 等等
 
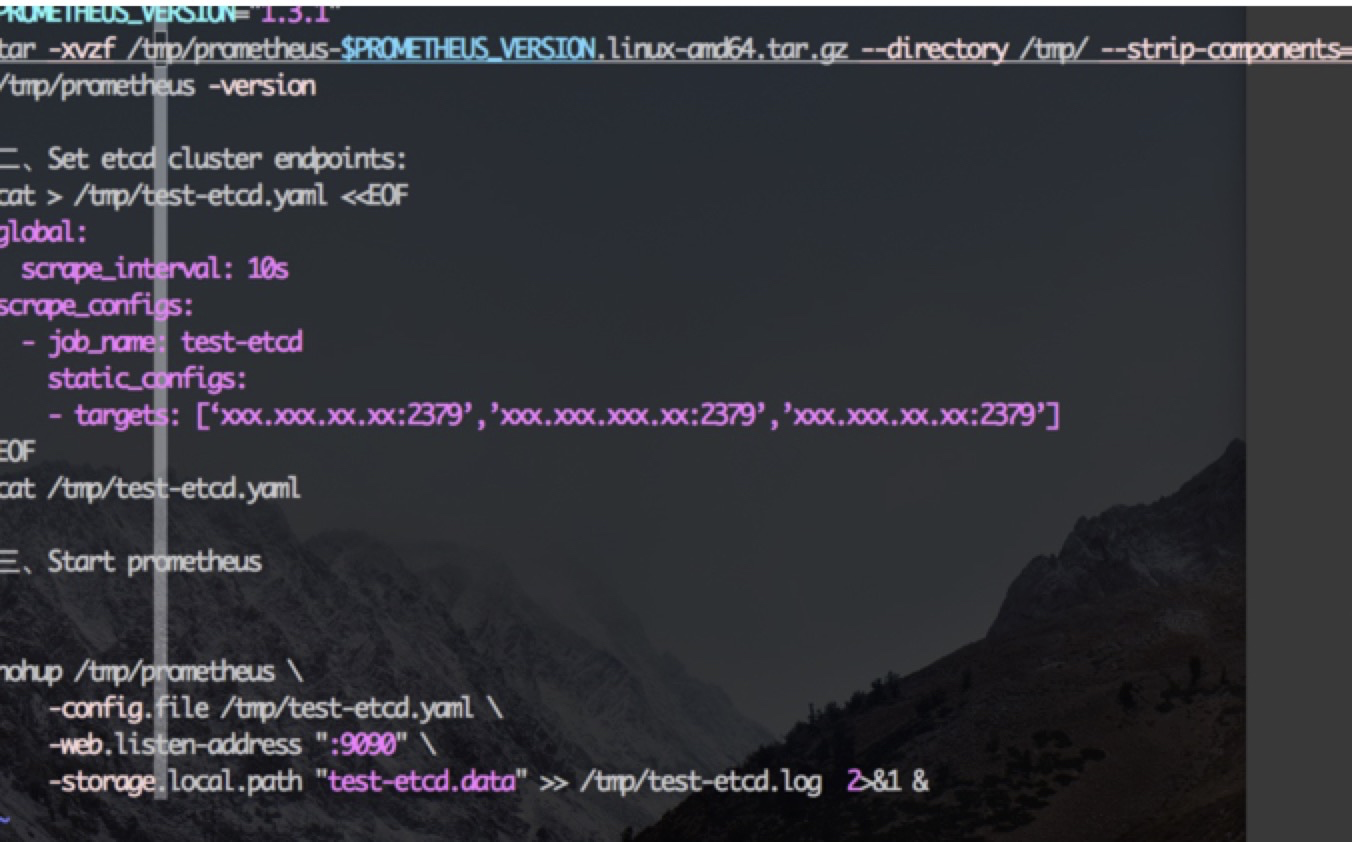
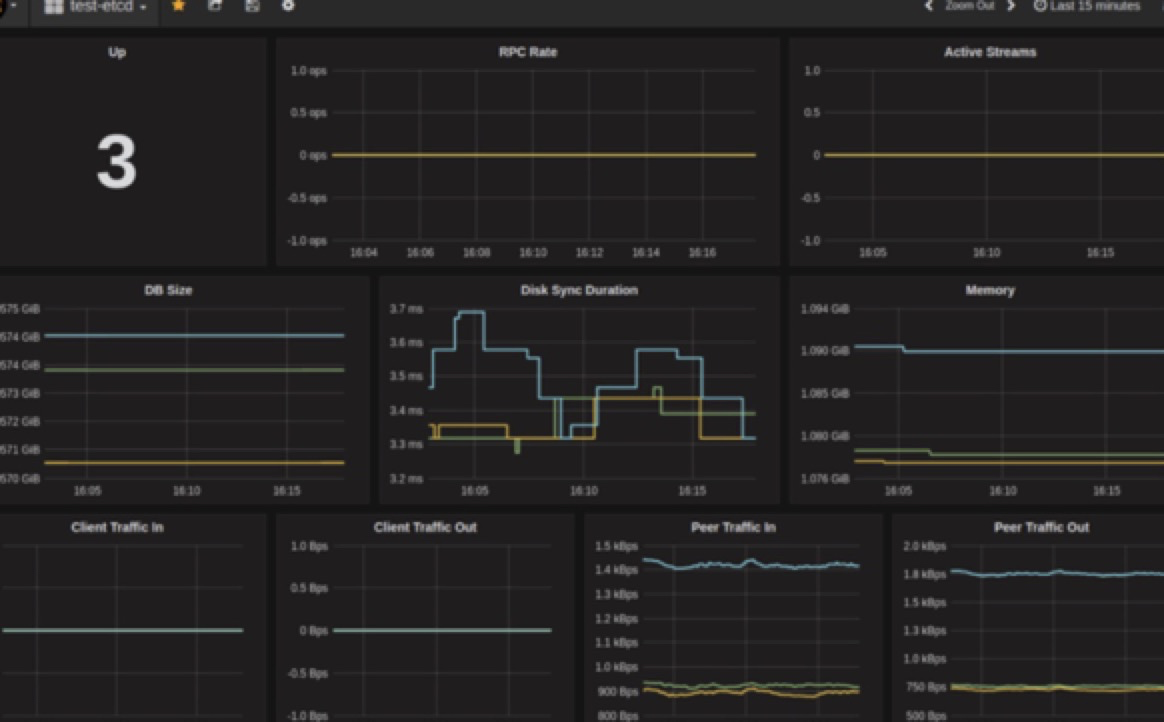
 

参考 https://coreos.com/etcd/docs/latest/op-guide/monitoring.html
五、容器基础监控、业务监控
监控是整个运维环节,乃⾄至整个产品⽣生命周期中最重要的⼀环、事前及时预警发现故障、事后提供数据追查定位问题,分析业务指标等等坚持业务指标采集是代码的⼀部分原则不不动摇,提⾼高指标覆盖率监控⽅方式和指标要标准化。
5.1. 定制容器基础监控规则、规范。比如cpu阀值、内存阀值、磁盘阀值等等、高峰期 robot自动巡检 报告
5.2. 监控选型:promtheus 、zabbix 等等
- Promtheus 负责监控整个集群 配合grafana
- 业务监控:监控pod cpu mem 使用率 等等
- zabbix:负责文本类监控,如message 监控 kubernetes pod list 是否 running状态、以及pod扩缩容监控
5.3.报警规则,怎么才能让避免垃圾报警。避免狼来了的故事
所有报警规则promtheus 或 zabbix 需根据kubernetes Kubelet 监控资源消耗规则匹配,特别注意要和kubernetes一些自动恢复规则最好匹配,尽量低于kubernetes规则,要比kubernetes早发现,自研告警信息管理平台,
在一个平台中接收所有监控系统的告警,让运维人员集中处理系统异常事件,避免多平台切换,提升运维效率。 promtheus、Zabbix等主流监控平台的告警自动整合进来 ,使用时间序列规则,将大量重复的告警事件压缩为一条有真正意义的告警。而后通过属性关联、 机器学习等算法把相关的告警合并起来,安排一线运维负责7x24小时应急值守, 快速接收告警进行初步预判,二线研发团队负责告警升级的分析和根源定位,建议使用钉钉,短信报警
一个kubernetes 集群的 dashborad 基本信息
 
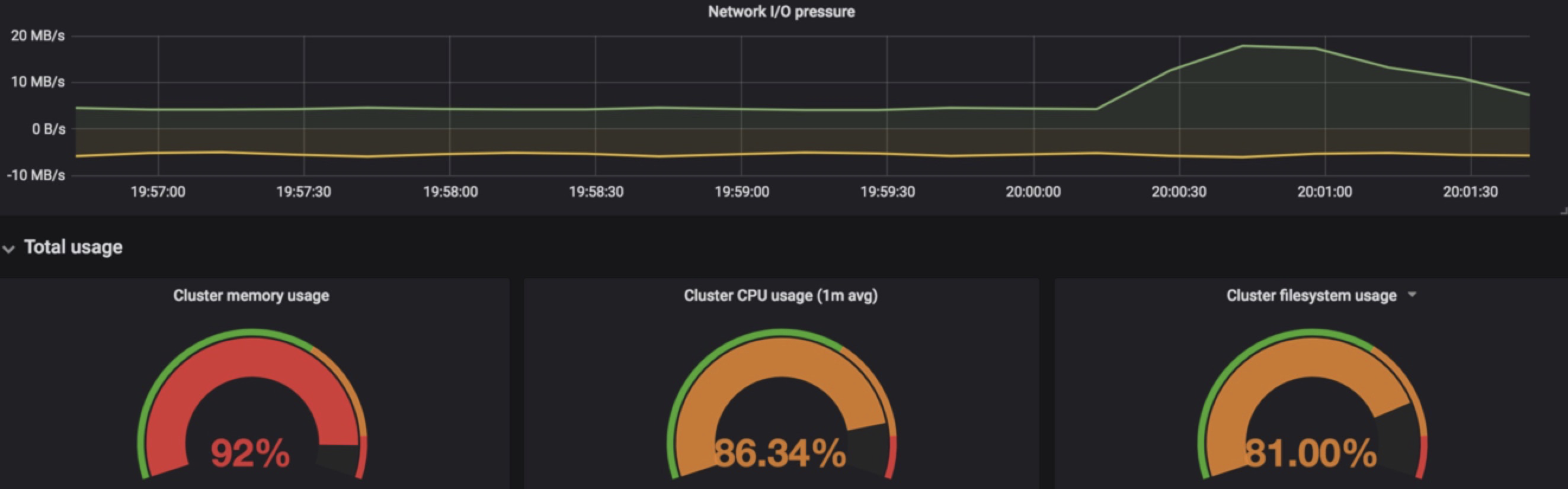
指定pod cpu mem 监控
 
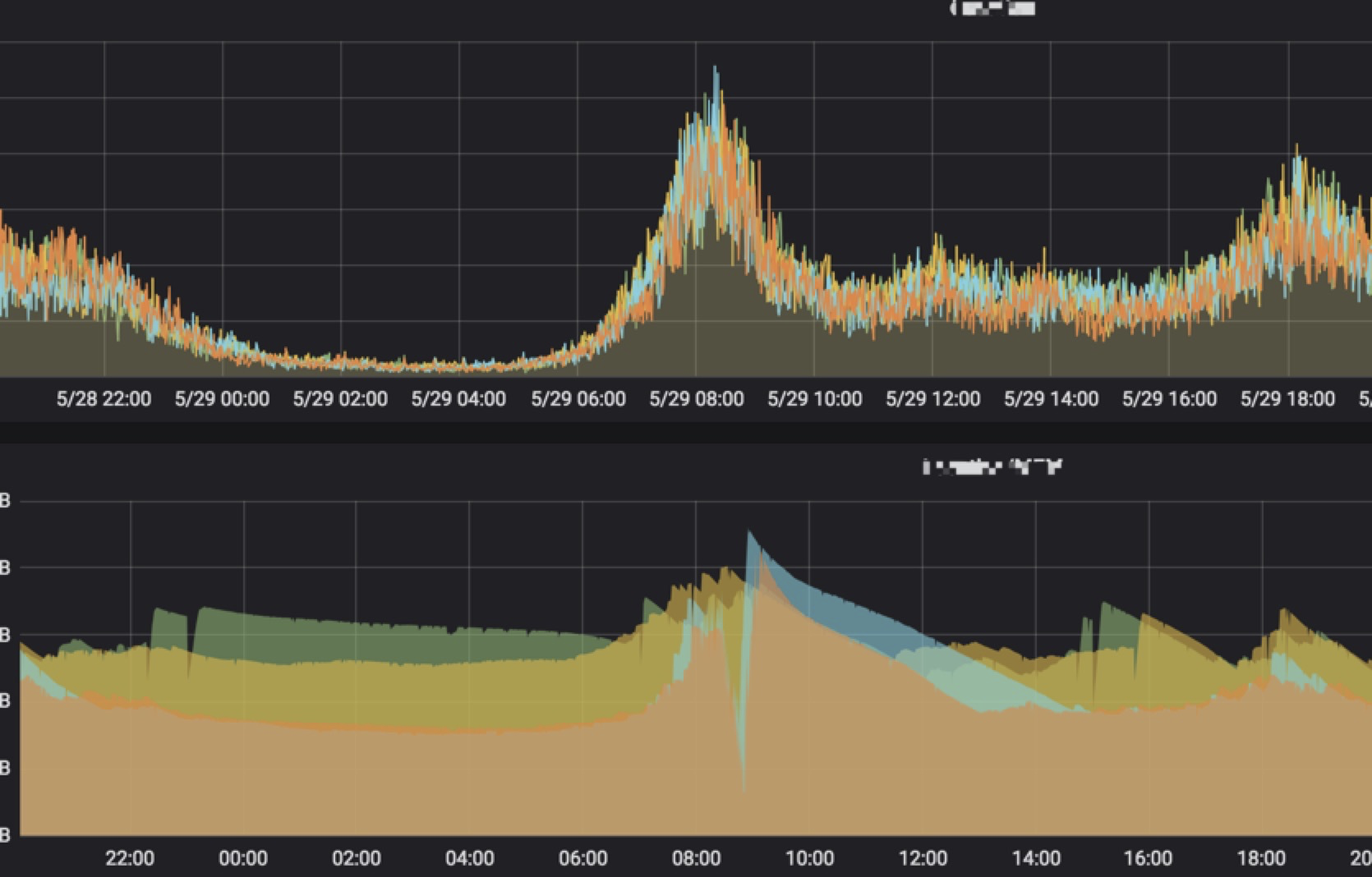
5.4 pod自动扩容提醒 和异常pod(crashloopbackoff)报警(钉钉报警)
 

5.5 业务监控 、pod cpu 内存 监控 高峰期自动钉钉发送 无人值守
 
六、kubernetes趟过的坑
6.1 案例一
异常:
authentication.k8s.io:0xc820374f50] is already registered
kubectl throwing group is already registered error
原因:
kubectl版本与Kubernetes版本不一致导致的
解决:
选择相应的kubectl版本重新安装
6.2 案例二
异常:
kubelet: E0529 17:40:11.741095 14358 fs.go:418] Stat fs failed. Error: no such file or directory
原因:由于安装docker时宿主目录被软链 overlayfs清理container不完整导致的
解决:
安装kubernetes集群时 docker需要配置好宿主目录 不要软链
6.3案例三
异常:svc ip 变化 导致无法访问,1.9.4之前的惊天大BUG
原因:一个或者多个 Kubernetes service 对应的 Kubernetes endpoints 消失几分钟或者更长时间,kubectl get ep --all-namespaces” 不断查询,可以观察到一些 AGE 在分钟级别的 endpoints 总是忽然消失,endpoints不稳定,导致service无法变化
解决:升级kubernetes至1.9.3或更高 1.9.2的bug
6.4 案例四
异常:做线上cordon节点的时候 服务不可以用,导致某云slb 无法转发到节点的容器业务服务
原因:一般设置cordon的之后就会drain做排水调度,在ServiceController里面确实会将unschedulable的节点从service上移除,这个是目前kubernetes的机制
解决:做cordon操作时选择在业务低峰期,比如凌晨操作,分批操作不要一下子全部cordon
七、trouble shooting for linux
常用技巧
• 通过系统级别的方法先查看整体系统负载情况,再快速定位具体模块问题
• top / iotop / iftop等查看CPU负载,io负载,网卡负载总体情况
• ps / lsof查看(连接句柄)进程当前关联的句柄(进程)
• strace抓一段时间可疑进程的系统调用情况
lsof
• 枚举进程打开的句柄(文件、sockets)
• 查看某一文件或连接(TCP/UDP端口)所关联的进程
• 查看flock文件锁&线程锁交叉导致的死锁(W)
• lsof
• lsof -nPp
• lsof -nPI@192.168.xx.x:22
• lsof /var/lib/mysql/mysql.sock
ss
• 查看TCP/UDP sockets状态
• ss -an | grep LISTEN
• netstat -s
• EST, CLOSE-WAIT, TIME-WAIT, SYN_RECV
• 发送TCP RST可以避免进入TIME-WAIT状态
Tcpdump
• 网络抓包,网络故障分析
• tcpdump -vv -i eth0 port xx -X -s 0
• tcpdump -vv -s 0 -i eth0 port xx -w /tmp/xx.pcap
ofo容器pass架构分享的更多相关文章
- 【原创译文】基于Docker和Rancher的超融合容器云架构
基于Docker和Rancher的超融合容器云架构 ---来自Rancher和Redapt 超融合架构在现代数据中心是一项巨大的变革.Nutanix公司发明了超融合架构理论,自从我听说他们的“iPho ...
- Mvc项目架构分享之项目扩展
Mvc项目架构分享之项目扩展 Contents 系列一[架构概览] 0.项目简介 1.项目解决方案分层方案 2.所用到的技术 3.项目引用关系 系列二[架构搭建初步] 4.项目架构各部分解析 5.项目 ...
- mvc项目架构分享系列之架构搭建初步
mvc项目架构分享系列之架构搭建初步 Contents 系列一[架构概览] 0.项目简介 1.项目解决方案分层方案 2.所用到的技术 3.项目引用关系 系列二[架构搭建初步] 4.项目架构各部分解析 ...
- Asp.net mvc项目架构分享系列之架构概览
Asp.net mvc项目架构分享系列之架构概览 Contents 系列一[架构概览] 0.项目简介 1.项目解决方案分层方案 2.所用到的技术 3.项目引用关系 系列二[架构搭建初步] 4.项目架构 ...
- Asp.net mvc项目架构分享系列之架构搭建初步
copy to:http://www.cnblogs.com/ben121011/p/5014795.html 项目架构各部分解析 Core Models IDAL MSSQLDAL IBLL BLL ...
- Docker容器学习与分享07
Docker容器网络 在分享06中学完了bridge网络,接着学习none网络和host网络. Docker在安装时会在host上默认创建三个网络,分别是bridge.host.null. [root ...
- 【转帖】一文看懂docker容器技术架构及其中的各个模块
一文看懂docker容器技术架构及其中的各个模块 原创 波波说运维 2019-09-29 00:01:00 https://www.toutiao.com/a6740234030798602763/ ...
- 容器云架构中使用gorouter+haproxy作为流量入口
小贴士 Gorouter 项目地址:https://github.com/cloudfoundry/gorouter/Gorouter来源于CloudFoundry.是一个高性能.轻量级的路由器及 ...
- UWP开发之Mvvmlight实践九:基于MVVM的项目架构分享
在前几章介绍了不少MVVM以及Mvvmlight实例,那实际企业开发中将以那种架构开发比较好?怎样分层开发才能节省成本? 本文特别分享实际企业项目开发中使用过的项目架构,欢迎参照使用!有不好的地方欢迎 ...
随机推荐
- BZOJ4522:[CQOI2016]密钥破解(Pollard-Rho,exgcd)
Description 一种非对称加密算法的密钥生成过程如下: 1. 任选两个不同的质数 p ,q 2. 计算 N=pq , r=(p-1)(q-1) 3. 选取小于r ,且与 r 互质的整数 e ...
- openssl生成证书
数字证书: 第三方机构使用一种安全的方式把公钥分发出去 证书格式:x509,pkcs家族 x509格式: 公钥和有效期限: 持有者的个人合法身份信息:(主机名,域名) 证书的使用方式 CA的信息 CA ...
- virtualbox+vagrant学习-2(command cli)-16-vagrant snapshot命令
Snapshot快照 这是用于管理客户机器快照的命令.快照记录客户计算机的时间点状态.然后可以快速恢复到此环境.这可以让你进行试验和尝试,并迅速恢复到以前的状态. 快照并不是每个provider都支持 ...
- Spring整合MyBatis(四)MapperFactoryBean 的创建
摘要: 本文结合<Spring源码深度解析>来分析Spring 5.0.6版本的源代码.若有描述错误之处,欢迎指正. 目录 一.MapperFactoryBean的初始化 二.获取 Map ...
- C语言程序设计I—第十一周教学
第十一周教学总结(12/11-17/11) 教学内容 第4章 循环结构-break continue嵌套循环 4.3 判断素数,4.4求1! + 2! + -. + 100! 课前准备 在蓝墨云班课发 ...
- python3爬虫-下载网易云音乐,评论
# -*- coding: utf-8 -*- ''' 16位随机字符的字符串 参数一 获取歌曲下载地址 "{"ids":"[1361348080]" ...
- go Context的使用
控制并发有两种经典的方式,一种是WaitGroup,另外一种就是Context WaitGroup的使用 WaitGroup可以用来控制多个goroutine同时完成 func main() { va ...
- 课下测试补交(ch03 ch08)
课下测试补交(ch03 ch08) 课下测试 ch03 1.有关gdb调试汇编,下面说法正确的是(ABCE) A . 可以用disas反汇编当前函数 B . 以16进制形式打印%rax中内容的命令是 ...
- git push 每次都要输入用户名密码
添加远程库的时候使用了https的方式..所以每次都要用https的方式push到远程库,速度还慢.. 查看使用的传输协议: git remote -v 重新设置成ssh的方式: git remote ...
- PostgreSQL的PITR中,对 unfilled wal log 如何处理为好
磨砺技术珠矶,践行数据之道,追求卓越价值 回到上一级页面: PostgreSQL基础知识与基本操作索引页 回到顶级页面:PostgreSQL索引页 通过实验,可以发现,PostgreSQL中使 ...