统计学习方法c++实现之八 EM算法与高斯混合模型
EM算法与高斯混合模型
前言
EM算法是一种用于含有隐变量的概率模型参数的极大似然估计的迭代算法。如果给定的概率模型的变量都是可观测变量,那么给定观测数据后,就可以根据极大似然估计来求出模型的参数,比如我们假设抛硬币的正面朝上的概率为p(相当于我们假设了概率模型),然后根据n次抛硬币的结果就可以估计出p的值,这种概率模型没有隐变量,而书中的三个硬币的问题(先抛A然后根据A的结果决定继续抛B还是C),这种问题中A的结果就是隐变量,我们只有最后一个硬币的结果,其中的隐变量无法观测,所以这种无法直接根据观测数据估计概率模型的参数,这时就需要对隐变量进行估计,进而得到概率模型的参数,这里要注意,概率模型是已知的(已经假定好了),包括隐变量的模型也是假设好的,只是具体的参数未知,这时候就需要用EM算法求解未知参数,这里我用EM算法估计了高斯混合模型的参数,并用高斯混合模型实现了聚类,代码地址。
EM算法
EM算法中文名称是期望极大算法,EM是expectation maximization的缩写,从名字就可以窥视算法的核心,求期望,求极大。求谁的期望?求似然函数对隐变量的期望,所以,首先必须确定隐变量是什么。其次,对谁求极大?当然是求出概率模型的参数使得上一步的期望最大。算法如下:
输入:观测变量数据Y,隐变量数据Z(这里也是知道的?其实这里我的理解是,这里不是已知的,但是却是可以根据假设的隐变量的参数得到的),联合分布\(P(Y,Z|\theta)\), 条件分布\(P(Z|Y,\theta)\)
输出:模型参数\(\theta\)
E步:记\(\theta^{(i)}\)为第i次迭代参数\(\theta\)的估计值,i+1次迭代的E步, 计算
\(Q(\theta, \theta^{(i)})=E_Z[logP(Y,Z|\theta)|Y, \theta^{(i)}]=\sum_{Z}logP(Y,Z|\theta)P(Z|Y,\theta^{(i)})\)
M步,求使\(Q(\theta, \theta^{(i)})\)极大的\(\theta\),作为下一次迭代的\(\theta^{(i+1)}\)
重复2,3直到收敛
可以看出最重要的在于求\(Q(\theta, \theta^{(i)})\),那么为什么每一次迭代最大化\(\sum_{Z}logP(Y,Z|\theta)P(Z|Y,\theta^{(i)})\)就能使观测数据的似然函数最大(这是我们的最终目的)?这里书上有证明,很详细,就不赘述了。先看一下我们要最大化的极大似然函数,然后这里主要引用西瓜书中的解释来从理解EM算法:
\(L(\theta)=logP(Y|\theta)=log(\sum_ZP(Y,Z|\theta))=log(\sum_ZP(Y|Z,\theta)P(Z|\theta))\)
在迭代过程中,若参数\(\theta\)已知,则可以根据训练数据推断出最优隐变量Z的值(E步);反之,若Z的值已知,则可以方便的对参数\(\theta\)做极大似然估计(M步)。
可以看出就是一种互相计算,一起提升的过程。
这部分如果推导看不懂了,可以结合下面的二维高斯混合模型的EM算法来理解。
c++实现
这里我使用EM算法来估计高斯混合模型的参数来进行聚类,高斯混合模型还有一个很大的作用是进行前景提取,这里仅仅用二维混合高斯模型进行聚类。
代码结构
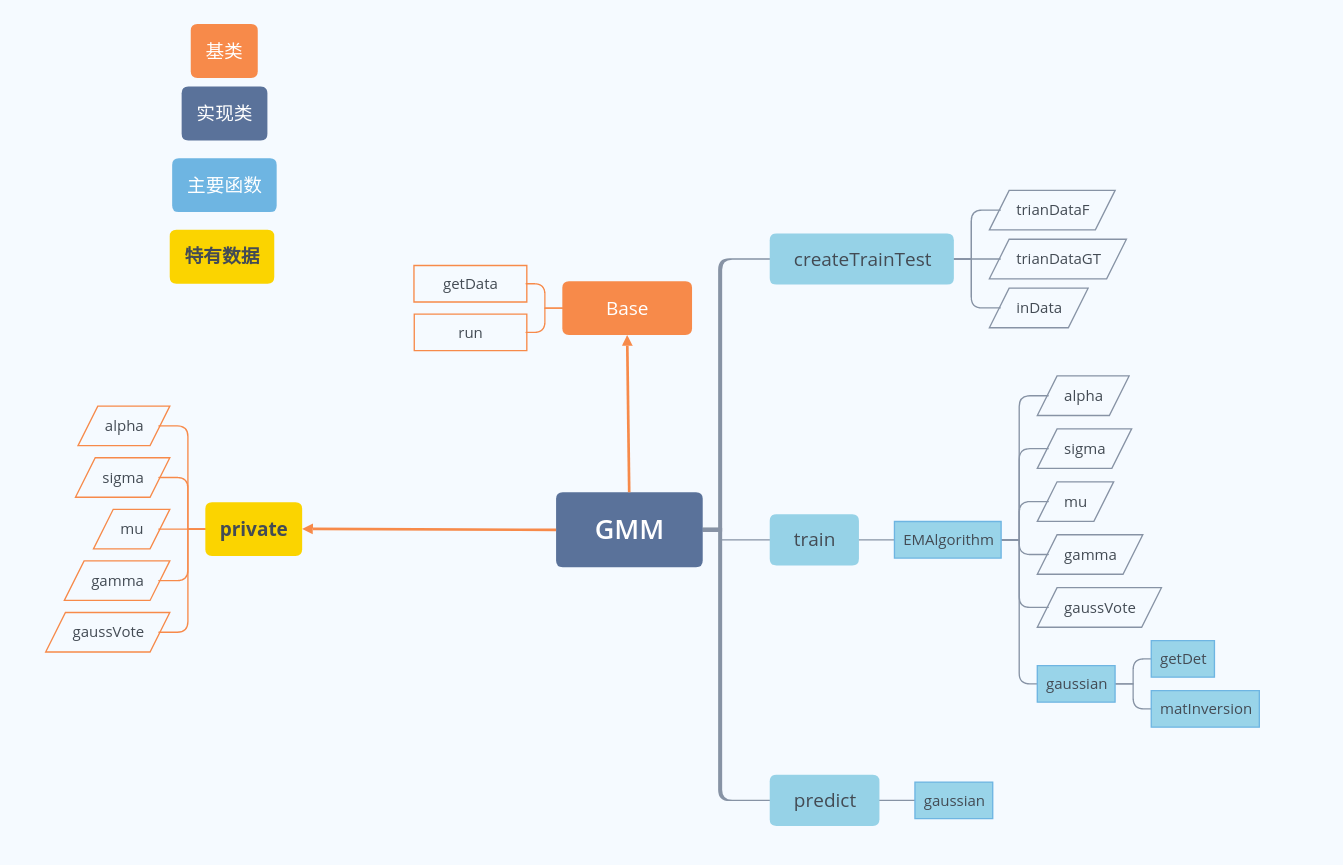
关键代码
这里实现起来其实没什么难点,难点在于推导参数的更新公式,详情参考西瓜书p206。
void GMM::EMAlgorithm(vector<double> &alphaOld, vector<vector<vector<double>>> &sigmaOld,
vector<vector<double>> &muOld) {
// compute gamma
for (int i = 0; i < trainDataF.size(); ++i) {
double probSum = 0;
for (int l = 0; l < alpha.size(); ++l) {
double gas = gaussian(muOld[l], sigmaOld[l], trainDataF[i]);
probSum += alphaOld[l] * gas;
}
for (int k = 0; k < alpha.size(); ++k) {
double gas = gaussian(muOld[k], sigmaOld[k], trainDataF[i]);
gamma[i][k] = alphaOld[k] * gas / probSum;
}
}
// update mu, sigma, alpha
for (int k = 0; k < alpha.size(); ++k) {
vector<double> muNew;
vector<vector<double>> sigmaNew;
double alphaNew;
vector<double> muNumerator;
double sumGamma = 0.0;
for (int i = 0; i < trainDataF.size(); ++i) {
sumGamma += gamma[i][k];
if (i==0) {
muNumerator = gamma[i][k] * trainDataF[i];
}
else {
muNumerator = muNumerator + gamma[i][k] * trainDataF[i];
}
}
muNew = muNumerator / sumGamma;
for (int i = 0; i < trainDataF.size(); ++i) {
if (i==0) {
auto temp1 = gamma[i][k]/ sumGamma * (trainDataF[i] - muNew);
auto temp2 = trainDataF[i] - muNew;
sigmaNew = vecMulVecToMat(temp1, temp2);
}
else {
auto temp1 = gamma[i][k] / sumGamma * (trainDataF[i] - muNew);
auto temp2 = trainDataF[i] - muNew;
sigmaNew = sigmaNew + vecMulVecToMat(temp1, temp2);
}
}
alphaNew = sumGamma / trainDataF.size();
mu[k] = muNew;
sigma[k] = sigmaNew;
alpha[k] = alphaNew;
}
}
总结
前面的代码一直用vector来实现向量,但是这里用到了矩阵,矩阵的相关计算都添加的计算函数。最正规的应该是写个类,实现矩阵运算,但是这里偷懒了,以后写代码一定要考虑周到,这样添添补补的太低效了。
统计学习方法c++实现之八 EM算法与高斯混合模型的更多相关文章
- 《统计学习方法》笔记九 EM算法及其推广
本系列笔记内容参考来源为李航<统计学习方法> EM算法是一种迭代算法,用于含有隐变量的概率模型参数的极大似然估计或极大后验概率估计.迭代由 (1)E步:求期望 (2)M步:求极大 组成,称 ...
- EM 算法求解高斯混合模型python实现
注:本文是对<统计学习方法>EM算法的一个简单总结. 1. 什么是EM算法? 引用书上的话: 概率模型有时既含有观测变量,又含有隐变量或者潜在变量.如果概率模型的变量都是观测变量,可以直接 ...
- 斯坦福大学机器学习,EM算法求解高斯混合模型
斯坦福大学机器学习,EM算法求解高斯混合模型.一种高斯混合模型算法的改进方法---将聚类算法与传统高斯混合模型结合起来的建模方法, 并同时提出的运用距离加权的矢量量化方法获取初始值,并采用衡量相似度的 ...
- 机器学习第三课(EM算法和高斯混合模型)
极大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一.说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值. ...
- 机器学习算法总结(六)——EM算法与高斯混合模型
极大似然估计是利用已知的样本结果,去反推最有可能(最大概率)导致这样结果的参数值,也就是在给定的观测变量下去估计参数值.然而现实中可能存在这样的问题,除了观测变量之外,还存在着未知的隐变量,因为变量未 ...
- EM算法求高斯混合模型參数预计——Python实现
EM算法一般表述: 当有部分数据缺失或者无法观察到时,EM算法提供了一个高效的迭代程序用来计算这些数据的最大似然预计.在每一步迭代分为两个步骤:期望(Expectation)步骤和最大化( ...
- EM算法和高斯混合模型GMM介绍
EM算法 EM算法主要用于求概率密度函数参数的最大似然估计,将问题$\arg \max _{\theta_{1}} \sum_{i=1}^{n} \ln p\left(x_{i} | \theta_{ ...
- 统计学习方法笔记--EM算法--三硬币例子补充
本文,意在说明<统计学习方法>第九章EM算法的三硬币例子,公式(9.5-9.6如何而来) 下面是(公式9.5-9.8)的说明, 本人水平有限,怀着分享学习的态度发表此文,欢迎大家批评,交流 ...
- 学习笔记——EM算法
EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计.EM算法的每次迭代由两步组成:E步,求期望(expectation):M步,求 ...
随机推荐
- memset struct含有string的崩溃
2019/4/2 补充一下 这里如果填充为0,则不会崩溃,填充为非0时,再次调用赋值就会崩溃 推测非0拷贝破坏了string内部的数据结构,不要对任何类使用memset https://blog.cs ...
- python3+OpenGL环境配置
注:示例系统环境:Windows10 64位 + Anaconda3: 1.首先登录https://www.opengl.org/resources/libraries/glut/,下载下图箭头所指的 ...
- ios的图片解压
YYKit SDWebImage FLAnimatedImage YYKit YYCGImageCreateDecodedCopy YYImageCoder 1 2 3 4 5 6 7 8 9 10 ...
- performSelector 多参调用的实现方案
1.nsinvocation封装: 2.msg_send封装: 第二种方案是系统的原生封装.
- UVa 1363 - Joseph's Problem(数论)
链接: https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem& ...
- AE-----合成
AE-----合成 大纲:
- openstack排除查找错误的两种方法
1.openstack日志一般放在什么什么位置?2.如何调试openstack命令执行过程? 我们会经常错误,但是我们碰到错误该怎么做,该如何找到原因.对于openstack有两种办法:在上一篇文章h ...
- leetcode 217. Contains Duplicate 287. Find the Duplicate Number 442. Find All Duplicates in an Array 448. Find All Numbers Disappeared in an Array
后面3个题都是限制在1-n的,所有可以不先排序,可以利用巧方法做.最后两个题几乎一模一样. 217. Contains Duplicate class Solution { public: bool ...
- linux shell基本知识 sleep命令
在有的shell(比如linux中的bash)中sleep还支持睡眠(分,小时) sleep 睡眠1秒 sleep 1s 睡眠1秒 sleep 1m 睡眠1分 sleep 1h 睡眠1小时
- KMP算法之从懵逼到入门
写本文的目的: 1.加深自己的理解,以便自己日后复习 2.给看到此文的人一点启发 KMP算法看懂了就觉得特别简单,思路也好理解,但是看不懂之前,查各种资料看大佬的博客,都很懵逼...... 1. 算 ...