MyBatis使用Collection查询多对多或一对多结果集bug
情况描述:当使用JOIN查询,如果SQL查询出来的记录不是按id列排序的,则生成的List结果会有问题
案例:
1) 数据库模型
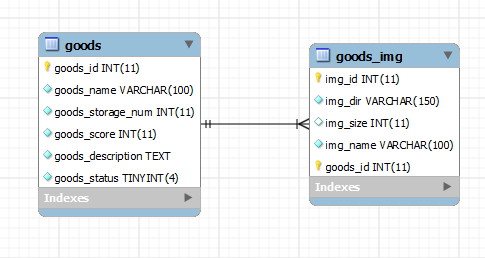
简而言之一个Goods包含多个Goods_Img
2) Java Bean
Goods.java
public class Goods {
private Integer goodsId;
private String goodsName;
private Integer goodsStorageNum;
private Integer goodsScore;
private GoodsStatus goodsStatus;
private String goodsDescription;
private List<GoodsImg> goodsImgList;
... getter and setter ...
}
GoodImg.java
public class GoodsImg {
private Integer imgId;
private Integer goodsId;
private String imgDir;
private Integer imgSize;
private String imgName;
... getter and setter ...
}
3) Mapper
<!-- Result Map -->
<!-- goods resultmap -->
<resultMap id="goodsResultMap" type="com.qunar.scoresystem.bean.Goods">
<id property="goodsId" column="goods_id" />
<result property="goodsName" column="goods_name" />
<result property="goodsStorageNum" column="goods_storage_num" />
<result property="goodsScore" column="goods_score" />
<result property="goodsDescription" column="goods_description" />
<result property="goodsStatus" column="goods_status" />
<collection property="goodsImgList" resultMap="goodsImgResult" />
</resultMap> <!-- goodsimage resultmap -->
<resultMap id="goodsImgResult" type="com.qunar.scoresystem.bean.GoodsImg">
<id property="imgId" column="img_id" />
<result property="goodsId" column="goods_id" />
<result property="imgDir" column="img_dir" />
<result property="imgSize" column="img_size" />
<result property="imgName" column="img_name" />
</resultMap>
4) 执行的 SQL
select
goods.goods_id as goods_id,
goods.goods_name as goods_name,
goods.goods_storage_num as goods_storage_num,
goods.goods_score as goods_score,
goods.goods_description as goods_description,
goods.goods_status as goods_status ,
goods_img.img_name as img_name ,
goods_img.img_dir as img_dir ,
goods_img.img_size as img_size
from goods
join goods_img
on goods.goods_id=goods_img.goods_id
5) 结果集
a. 当SQL查询的结果为

注意上图中的goods_id顺序为乱序
则MyBatis返回的List结果为
Goods{goodsId=1, goodsName='good1', goodsStorageNum=1, goodsScore=1, goodsStatus=[1 | 下架], goodsDescription='1', goodsImgList=[GoodsImg{imgId=null, goodsId=1, imgDir='d1', imgSize=1, imgName='img1'}, GoodsImg{imgId=null, goodsId=1, imgDir='d2', imgSize=2, imgName='img2'}, GoodsImg{imgId=null, goodsId=1, imgDir='d4', imgSize=4, imgName='img4'}, GoodsImg{imgId=null, goodsId=1, imgDir='d6', imgSize=6, imgName='img6'}]}
Goods{goodsId=1, goodsName='good1', goodsStorageNum=1, goodsScore=1, goodsStatus=[1 | 下架], goodsDescription='1', goodsImgList=[GoodsImg{imgId=null, goodsId=1, imgDir='d1', imgSize=1, imgName='img1'}, GoodsImg{imgId=null, goodsId=1, imgDir='d2', imgSize=2, imgName='img2'}, GoodsImg{imgId=null, goodsId=1, imgDir='d4', imgSize=4, imgName='img4'}, GoodsImg{imgId=null, goodsId=1, imgDir='d6', imgSize=6, imgName='img6'}]}
Goods{goodsId=1, goodsName='good1', goodsStorageNum=1, goodsScore=1, goodsStatus=[1 | 下架], goodsDescription='1', goodsImgList=[GoodsImg{imgId=null, goodsId=1, imgDir='d1', imgSize=1, imgName='img1'}, GoodsImg{imgId=null, goodsId=1, imgDir='d2', imgSize=2, imgName='img2'}, GoodsImg{imgId=null, goodsId=1, imgDir='d4', imgSize=4, imgName='img4'}, GoodsImg{imgId=null, goodsId=1, imgDir='d6', imgSize=6, imgName='img6'}]}
可见返回的结果中有 三个 一模一样的 Goods(id=1,且包含5个GoodsImg), 而我们期待的结果应该是 List{ Goods(id=1), Goods(id=2), Goods(id=3) }
b. 当使用的SQL查询结果如下

上面的查询结果为id有序结果,正则MyBatis返回的Java结果集为:
Goods{goodsId=1, goodsName='good1', goodsStorageNum=1, goodsScore=1, goodsStatus=[1 | 下架], goodsDescription='1', goodsImgList=[GoodsImg{imgId=null, goodsId=1, imgDir='d1', imgSize=1, imgName='img1'}, GoodsImg{imgId=null, goodsId=1, imgDir='d2', imgSize=2, imgName='img2'}, GoodsImg{imgId=null, goodsId=1, imgDir='d3', imgSize=3, imgName='img3'}, GoodsImg{imgId=null, goodsId=1, imgDir='d4', imgSize=4, imgName='img4'}]}
Goods{goodsId=2, goodsName='good2', goodsStorageNum=2, goodsScore=2, goodsStatus=[1 | 下架], goodsDescription='2', goodsImgList=[GoodsImg{imgId=null, goodsId=2, imgDir='d5', imgSize=5, imgName='img5'}]}
Goods{goodsId=3, goodsName='good3', goodsStorageNum=3, goodsScore=3, goodsStatus=[1 | 下架], goodsDescription='3', goodsImgList=[GoodsImg{imgId=null, goodsId=3, imgDir='d6', imgSize=6, imgName='img6'}]}
观察goodsId,我们取得了期待的结果
答案:
根据作者本人的解释, MyBatis为了降低内存开销,采用ResultHandler逐行读取的JDBC ResultSet结果集的,这就会造成MyBatis在结果行返回的时候无法判断以后的是否还会有这个id的行返回,所以它采用了一个方法来判断当前id的结果行是否已经读取完成,从而将其加入结果集List,这个方法是:
1. 读取当前行记录A,将A加入自定义Cache类,同时读取下一行记录B
2. 使用下一行记录B的id列和值为key(这个key由resultMap的<id>标签列定义)去Cache类里获取记录
3. 假如使用B的key不能够获取到记录,则说明B的id与A不同,那么A将被加入到List
4. 假如使用B的key可以获取到记录,说明A与B的id相同,则会将A与B合并(相当于将两个goodsImg合并到一个List中,而goods本身并不会增加)
5. 将B定为当前行,同时读取下一行C,重复1-5,直到没有下一行记录
6. 当没有下一行记录的时候,将最后一个合并的resultMap对应的java对象加入到List(最后一个被合并goodsImg的Goods)
所以
a. 当结果行是乱序的,例如BBAB这样的顺序,在记录行A遇到一个id不同的曾经出现过的记录行B时, A将不会被加入到List里(因为Cache里已经存在B的id为key的cahce了)
b. 当结果是顺序时,则结果集不会有任何问题,因为 记录行 A 不可能 遇到一个曾经出现过的 记录行B, 所以记录行A不会被忽略,每次遇到新行B时,都不可能使用B的key去Cache里取到值,所以A必然可以被加入到List
在MyBatis中,实现这个逻辑的代码如下
@Override
protected void handleRowValues(ResultSet rs, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultColumnCache resultColumnCache) throws SQLException {
final DefaultResultContext resultContext = new DefaultResultContext();
skipRows(rs, rowBounds);
Object rowValue = null;
while (shouldProcessMoreRows(rs, resultContext, rowBounds)) {
final ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(rs, resultMap, null);
// 下一记录行的id构成的cache key
final CacheKey rowKey = createRowKey(discriminatedResultMap, rs, null, resultColumnCache);
Object partialObject = objectCache.get(rowKey);
// 判断下一记录行是否被记录与cache中,如果不在cache中则将该记录行的对象插入List
if (partialObject == null && rowValue != null) { // issue #542 delay calling ResultHandler until object
if (mappedStatement.isResultOrdered()) objectCache.clear(); // issue #577 clear memory if ordered
callResultHandler(resultHandler, resultContext, rowValue);
}
// 当前记录行的值
rowValue = getRowValue(rs, discriminatedResultMap, rowKey, rowKey, null, resultColumnCache, partialObject);
}
// 插入最后一记录行的对象到List
if (rowValue != null) callResultHandler(resultHandler, resultContext, rowValue);
}
举例:
以

这个结果集为例,MyBatis会逐行读取记录行,我们将1~6行编号为A,B,C,D,E,F
1. 读取A行(id=1),将A行加入Cache,查看B行(id=1)的id,B行在Cache中已存在,不操作
2. 读取B行(id=1),查看C(id=2)行id,C行在Cache中不存在,将B行对应的Java对象插入List
3. 读取C(id=2)行,查看D(id=1)行ID,D行在Cache中已存在,不操作(此处漏掉一个id=2的Goods)
4. 读取D行(id=1),查看E行(id=3)ID,E行在Cache中不存在,将D行对应的java对象插入List(此处插入第一个重复的id=1的Goods)
5. 读取E行(id=3),查看F行(id=1)的ID,F行在Cache中已存在,不操作(此处漏掉一个id=3的Goods)
6. 读取F行(id=1),没有下一行,跳出循环,并插入最后一个Goods(此处插入第二个重复id=1的Goods)
所以,最后我们得到了3个一样的Goods,至于有序结果集,大家也可以按顺序去推一下,得到的结果集就是正确的
此外,源码中我们也可以看到作者原先给的注释: issue #542,讨论的就是这个问题,参见如下链接
https://github.com/mybatis/mybatis-3/pull/22
https://code.google.com/p/mybatis/issues/detail?id=542
所以,如果我们要用这种方式去查询一对多关系,恐怕只能手动排序好结果集才不会出错.
另外,我还发现一个有趣的现象,就是当MySQL在主表数据量<=3条时,Join的结果集是无序的,而当结果集的数据量>3条时,Join的结果集就变成有序了
a. 主表数据<=3条
主表:

Join结果

b. 主表数据>3行
主表

Join结果

MyBatis使用Collection查询多对多或一对多结果集bug的更多相关文章
- mybatis的collection查询问题以及使用原生解决方案的结果
之前在springboot+mybatis环境的坑和sql语句简化技巧的第2点提到,数据库的一对多查询可以一次查询多级数据,并且把拿到的数据按id聚合,使父级表和子级表都有数据. 但是这种查询,必然要 ...
- Mybatis中的多表查询 多对一,一对多
示例:用户和账户 一个用户可以有多个账户 一个账户只能属于一个用户(多个账户也可以属于同一个用户) 步骤: 1.建立两张表:用户表,账户表 让用户表和账户表之间具备一对多的关系:需要使用外键在账户表中 ...
- mybatis使用collection查询集合属性规则
接上篇mybatis使用associaton进行分步查询 相关的类还是上篇中的类. 查询部门的时候将部门对应的所有员工信息也查询出来 DepartmentMapper.xml <!--嵌套结果集 ...
- Mybatis多表查询(一对一、一对多、多对多)
Mybatis的多表级联查询 . 一对一可以通过<association>实现,一对多和多对多通过<collection>实现. <discriminator> 元 ...
- mybatis学习记录六——一对一、一对多和多对多查询
9 订单商品数据模型 9.1 数据模型分析思路 1.每张表记录的数据内容 分模块对每张表记录的内容进行熟悉,相当 于你学习系统 需求(功能)的过程. 2.每张表重要的字段设置 非空 ...
- 六 mybatis高级映射(一对一,一对多,多对多)
1 订单商品数据模型 以订单商品数据为模型,来对mybaits高级关系映射进行学习.
- MyBatis学习05(多对一和一对多)
8.多对一的处理 多对一的理解: 多个学生对应一个老师 如果对于学生这边,就是一个多对一的现象,即从学生这边关联一个老师! 数据库设计 CREATE TABLE `teacher` ( `id` IN ...
- mybatis ----数据级联查询(多对一)
工程的目录结构: 有两个表,一个文章表article ,一个用户表user. create table article (id int(11) not null auto_increment, use ...
- MyBatis --- 映射关系【一对一、一对多、多对多】,懒加载机制
映射(多.一)对一的关联关系 1)若只想得到关联对象的id属性,不用关联数据表 2)若希望得到关联对象的其他属性,要关联其数据表 举例: 员工与部门的映射关系为:多对一 1.创建表 员工表 确定其外键 ...
随机推荐
- 【LOJ】#2024. 「JLOI / SHOI2016」侦查守卫
题解 童年的回忆! 想当初,这是我考的第一次省选,我当时初二,我什么都不会,然后看着这个东西,是不是能用我一个月前才会的求lca,光这个lca我就调了一个多小时= =,然后整场五个小时,我觉得其他题不 ...
- 8-10 Coping Books uva714
题意:把一个包含m个正整数的序列划分为k个 1<=k<=m<=500的非空连续子序列 使得每个正整数恰好属于一个序列 设第i个序列的各个数之和为 Si 你的任务是让所有的 ...
- Ubuntu16.04下HBase的安装与配置
一.环境 os : Ubuntu 16.04 LTS 64bit jdk : 1.8.0_161 hadoop : mysql : hive : hbase: -hadoop2 安装HBase前,系统 ...
- C#中 EF(EntityFramework) 性能优化
现在工作中很少使用原生的sql了,大多数的时候都在使用EF.刚开始的时候,只是在注重功能的实现,最近一段时间在做服务端接口开发.开发的时候也是像之前一样,键盘噼里啪啦的一顿敲,接口秒秒钟上线,但是到联 ...
- Ionic实战九:ionic视频播放
本模板和以前的方式不同,采用的是 iframe方式引入的视频,如下代码:       
- 美团外卖Android平台化的复用实践
美团外卖平台化复用主要是指多端代码复用,正如美团外卖iOS多端复用的推动.支撑与思考文章所述,多端包含有两层意思:其一是相同业务的多入口,指美团外卖业务需要在美团外卖App(下文简称外卖App)和美团 ...
- Sockets CF732E set map
题目:http://codeforces.com/problemset/problem/732/E 题目大意: 有n台电脑(computer)和m个插座(socket),两者均有一个power值,分别 ...
- python2和python3同时安装
现在很多项目用python2完成的,很多情况下2和3是同时存在的 大多人都是先安装了python2 安装python3: 下一步: 然后安装完成以后,去cmd控制台输入python看看安装成功了吗(用 ...
- BZOJ.3991.[SDOI2015]寻宝游戏(思路 set)
题目链接 从哪个点出发最短路径都是一样的(最后都要回来). 脑补一下,最短路应该是按照DFS的顺序,依次访问.回溯遍历所有点,然后再回到起点. 即按DFS序排序后,Ans=dis(p1,p2)+dis ...
- bzoj 3275 最小割
给你一堆东西,叫你选一些东西出来,使得价值最大,要求选出的东西集合中的任意a,b满足性质p. 可以考虑: 1.拟阵? 2.二分图? 这道题由于数学硬伤,不知道不存在两条直角边是奇数,斜边是整数的直角三 ...