Hibernate5笔记7--Hibernate缓存机制
Hibernate缓存机制:
缓存范围:
应用程序中根据缓存的范围,可以将缓存分为三类:
(1)事务范围缓存(单Session,即一级缓存)
事务范围的缓存只能被当前事务访问,每个事务都有各自的缓存。缓存的生命周期依赖于事务的生命周期:当事务结束时,缓存的生命周期也会结束。事务范围的缓存使用内存作为存储介质。Hibernate中的一级缓存就属于事务范围。
(2)应用范围缓存(单SessionFactory,即二级缓存)
应用范围的缓存可以被应用程序内的所有事务共享访问。缓存的生命周期依赖于应用的生命周期,当应用结束时,缓存的生命周期同时结束。应用范围的缓存可以使用内存或硬盘作为存储介质。Hibernate的二级缓存就属于应用范围。
(3)集群范围缓存(多SessionFactory)
在集群环境中,缓存被一个机器或多个机器的进程共享,缓存中的数据被复制到集群环境中的每个进程节点,进程间通过远程通信来保证缓存中的数据的一致性,缓存中的数据通常采用对象的松散数据形式。有些Hibernate的二级缓存第三方插件支持集群范围缓存。
(1) 一级缓存:
一级缓存,就是Session缓存,其实就是内存中的一块空间,在这个内存空间存放了相互关联的Java对象。Session缓存是事务级缓存。伴随着事务的开启而开启,伴随着事务的关闭而关闭。Session缓存由Hibernate进行管理。Session缓存,是Hibernate内置的。是不能被程序员取消的。即,只要使用Hibernate,就一定要使用,更确切地说,就一定在使用Session缓存。
当程序调用Session的load()方法、get()方法、save()方法、saveOrUpdate()方法、update()方法或查询接口方法时,Hibernate会对实体对象进行缓存。当通过load()或get()方法查询实体对象时,Hibernate会首先到缓存中查询,在找不到实体对象的情况下,Hibernate才会发出SQL语句到DB中查询。从而提高了Hibernate的使用效率。
一级缓存相关的方法:
evict(Object o):从Session中删除指定对象
clear():无参数,将Session缓存清空
contains(Object o):判断指定对象是否在Session中存在
flush():无参数,将Session中对象状态同步到DB中
快照(引用自北京动力节点):

代码说明:
@Test
public void test01_SQL() {
//1. 获取Session
Session session = HbnUtils.getSession();
try {
//2. 开启事务
session.beginTransaction();
//3. 操作
//session.get的时候,hibernate就将数据库中的数据加载到session缓存中,同时也会备份到快照中
Student student = session.get(Student.class, 2);
student.setName("n_2");
session.update(student);
//4. 事务提交
//commit是唯一的同步时间点,当程序运行到同步时间点时,
//hibernate先判断session缓存中的数据和快照中的数据是否相同,
//如果不相同,则更新数据库,如果相同,则不更新数据库,
//以上,两种情况,无论是否写了update,都成立
session.getTransaction().commit();
} catch (Exception e) {
e.printStackTrace();
//5. 事务回滚
session.getTransaction().rollback();
}
}
Session的刷新与同步:
Session的刷新是指,Session缓存中的数据的更新。Session的同步是指,将Session缓存中的数据同步更新到DB中。执行同步的时间点只有一个:事务的提交。
当代码中执行了对Session中现有数据的修改操作,即update()与delete()语句后,Session缓存并不会马上刷新,即并不会马上执行update与delete的SQL语句,而是在某个时间点到来时,才会刷新缓存,更新缓存中的数据。刷新的时间点主要有三个:
(1)执行Query查询
(2)执行session.flush()
(3)执行事务的提交
通过Session的setFlushMode()方法,可以设置缓存刷新模式:
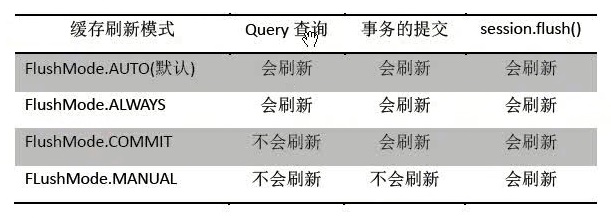
注意:增删改操作,当刷新时间点到来时是否马上进行缓存更新,各自情况还是不同的。
删除操作,一到达刷新时间点,马上执行delete语句,更新Session中数据;
更新操作,到达刷新时间点后,是否马上执行update语句,更新Session中数据,还要看该修改内容是否与快照一致若一致,则执行,否则,则不执行;
插入操作,无需等到刷新时间点的到达,见到save()后马上执行insert语句。因为插入操作不是修改Session中已经的存在数据,而是给Session中添加数据。
(2) 二级缓存:
二级缓存是SessionFactory级的缓存,其生命周期与SessionFactory一致。SessionFactory缓存可以依据功能和目的的不同而划分为内置缓存和外置缓存。
SessionFactory的内置缓存中存放了映射元数据和预定义SQL语句,映射元数据是映射文件中数据的副本,而预定义SQL语句是在Hibernate初始化阶段根据映射元数据推导出来的SQL。SessionFactory的内置缓存是只读的,应用程序不能修改缓存中的映射元数据和预定义SQL语句,因此SessionFactory不需要进行内置缓存与映射文件的同步。
SessionFactory的外置缓存是一个可配置的插件。在默认情况下,SessionFactory不会启用这个插件。外置缓存的数据是数据库数据的副本,外置缓存的介质可以是内存或者硬盘。SessionFactory的外置缓存也被称为Hibernate的二级缓存。
Hibernate本身只提供了二级缓存的规范,但并未实现,故需要第三方缓存产品的支持。常用的二级缓存第三方插件有:
EHCache、Memcached、OSCache、SwarmCache、JBossCache等。这些插件的功能各有侧重,各有特点。

二级缓存的执行:当Hibernate根据ID访问数据对象时,首先会从一级缓存Session中查找。若查不到且配置了二级缓存,则会从二级缓存中查找;若还查不到,就会查询数据库,把结果按照ID放入到缓存中。执行增、删、改操作时,会同步更新缓存。
二级缓存内容分类,根据缓存内容的不同,可以将Hibernate二级缓存分为四类:
(1)类缓存:缓存对象为实体类对象
(2)集合缓存:缓存对象为集合类对象
(3)更新时间戳缓存:
(4)查询缓存:缓存对象为查询结果
二级缓存的并发访问策略:
事务型(transactional):隔离级别最高,对于经常被读但很少被改的数据,可以采用此策略。因为它可以防止脏读与不可重复读的并发问题。发生异常的时候,缓存也能够回滚(系统开销大)。
读写型(read-write):对于经常被读但很少被改的数据,可以采用此策略。因为它可以防止脏读的并发问题。更新缓存的时候会锁定缓存中的数据。
非严格读写型(nonstrict-read-write):不保证缓存与数据库中数据的一致性。对于极少被改,并且允许偶尔脏读的数据,可采用此策略。不锁定缓存中的数据。
只读型(read-only):对于从来不会被修改的数据,可使用此策略。
二级缓存管理相关的方法:
与二级缓存管理相关的方法,一般都定义在Cache接口中。而Cache对象的获取,需要通过SessionFactory的getCache()方法:
Cache cache = sessionFactory.getCache();
二级缓存的配置(应用EHCache插件):
(1)导入ehcache的jar包,略
(2)在hibernate.cfg.xml中的<session-factory>元素中加入如下内容,开启二级缓存和注册二级缓存区域工厂:
<!-- 开启二级缓存 -->
<property name="hibernate.cache.use_second_level_cache">
true
</property>
<!-- 注册二级缓存区域工厂 -->
<property name="hibernate.cache.region.factory_class">
org.hibernate.cache.ehcache.EhCacheRegionFactory
</property>
(3)解压EHCache的核心Jar包ehcache-core-2.4.3.jar,将其中的一个配置文件ehcache-failsafe.xml直接放到项目的src目录下,并更名为ehcache.xml,注意其中的配置可以修改:
<defaultCache
maxElementsInMemory="10000"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
maxElementsOnDisk="10000000"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU">
<persistence strategy="localTempSwap"/>
</defaultCache>
(4)指定缓存内容:
指定缓存内容,即指定哪个类或哪个集合要进行二级缓存。指定的位置有两处:映射文件、主配置文件。这两种任选其一即可。它们的效果是相同的,但各有利弊:
在映射文件中指定缓存内容,查看其类的映射文件时,一眼就可看到类为缓存类,集合为缓存集合。但,弊端是,缓存的指定位置分散,缺乏项目的整体性。
在主配置文件中指定缓存内容,可一眼看到整个项目中所有缓存类与缓存集合。但,弊端是,缓存内容的指定与类映射分离。
映射文件中指定缓存内容:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping package="com.tongji.beans">
<class name="Country">
<!-- 指定当前类为类缓存对象 -->
<!-- <cache usage="read-only"/> -->
<id name="cid">
<generator class="native"/>
</id>
<property name="cname"/>
<set name="ministers" cascade="save-update">
<!-- 指定当前集合为集合缓存对象 -->
<!-- <cache usage="read-only"/> -->
<key column="countryId"/>
<one-to-many class="Minister"/>
</set>
</class>
</hibernate-mapping>
在主配置文件中指定缓存内容:在<mapping/>标签的后面指定类缓存与集合缓存
<!-- 指定类缓存 -->
<class-cache usage="read-only" class="com.tongji.beans.Minister" />
<class-cache usage="read-only" class="com.tongji.beans.Country" />
<!-- 指定集合缓存 -->
<collection-cache usage="read-only"
collection="com.tongji.beans.Country.ministers" />
补充:
(1)类缓存,缓存的是类的详情;集合缓存,在没有对集合中元素对应的类进行类缓存的时候,缓存的是所有元素的id。
(2)Query查询缓存,即session.createQuery(hql)时进行缓存。说明以下三点:
(1)Query查询的结果也会存放到一、二级缓存中
(2)Query查询默认不会从一、二级缓存中读取数据,但可以改变:
先在主配置文件中,开启Query查询总开关:<property name="hibernate.cache.use_query_cache">true</property>
查询时的代码:
@Test
public void test02() {
//1. 获取Session
Session session = HbnUtils.getSession();
try {
//2. 开启事务
session.beginTransaction();
//3. 操作
//第一次查询
String hql = "from Country where cid=1";
Country country1 = (Country) session.createQuery(hql).setCacheable(true).uniqueResult();
System.out.println("第一次查询:Country = " + country1);
//第二次查询
Country country2 = (Country) session.createQuery(hql).setCacheable(true).uniqueResult();
System.out.println("第二次查询:Country = " + country2); //将一级缓存数据清空
session.clear(); //第三次查询,从二级缓存中读取
Country country3 = (Country) session.createQuery(hql).setCacheable(true).uniqueResult();
System.out.println("第三次查询:Country = " + country3);
//4. 事务提交
session.getTransaction().commit();
} catch (Exception e) {
e.printStackTrace();
//5. 事务回滚
session.getTransaction().rollback();
}
}
(3)Query查询要从缓存中读取数据,必须保证Query所执行的HQL语句完全相同。因为Query查询,不仅将数据存放到了缓存中,还将HQL语句存放到了缓存中。
(4)修改时间戳:在二级缓存存放的对象中,比一级缓存中多出一个属性,updateTimeStamp,修改时间戳。只要这个属性发生改变,就说明有操作修改了DB中的数据,二级缓存中的该缓存对象已经不是最新数据,需要从DB中再次查询更新。
而Query接口的executeUpdate()方法所进行的更新,可以绕过一级缓存,但会修改二级缓存中缓存对象的updateTimeStamp值,由于该值的改变,二级缓存就会通过新的查询来更新缓存中的数据(一、二级缓存都更新了)。
Hibernate5笔记7--Hibernate缓存机制的更多相关文章
- 10.hibernate缓存机制详细分析(转自xiaoluo501395377)
hibernate缓存机制详细分析 在本篇随笔里将会分析一下hibernate的缓存机制,包括一级缓存(session级别).二级缓存(sessionFactory级别)以及查询缓存,当然还要讨论 ...
- 【转 :Hibernate 缓存机制】
转自:http://www.cnblogs.com/wean/archive/2012/05/16/2502724.html Hibernate 缓存机制 一.why(为什么要用Hibernate缓存 ...
- hibernate缓存机制详解
hiberante面试题—hibernate缓存机制详解 这是面试中经常问到的一个问题,可以按照我的思路回答,准你回答得很完美.首先说下Hibernate缓存的作用(即为什么要用缓存机制),然后再 ...
- hibernate缓存机制与N+1问题
在项目中遇到的趣事 本文基于hibernate缓存机制与N+1问题展开思考, 先介绍何为N+1问题 再hibernate中用list()获得对象: /** * 此时会发出一条sql,将30个学生全部查 ...
- HIbernate学习笔记(八) hibernate缓存机制
hibernate缓存 一. Session级缓存(一级缓存) 一级缓存很短和session的生命周期一致,因此也叫session级缓存或事务级缓存 hibernate一级缓存 那些方法支持一级缓存: ...
- hibernate缓存机制(转)
原文出处:http://www.cnblogs.com/wean/archive/2012/05/16/2502724.html 一.why(为什么要用Hibernate缓存?) Hibernate是 ...
- hibernate缓存机制详细分析 复制代码 内部资料 请勿转载 谢谢合作
您可以通过点击 右下角 的按钮 来对文章内容作出评价, 也可以通过左下方的 关注按钮 来关注我的博客的最新动态. 如果文章内容对您有帮助, 不要忘记点击右下角的 推荐按钮 来支持一下哦 如果您对文章内 ...
- Hibernate 缓存机制
一.why(为什么要用Hibernate缓存?) Hibernate是一个持久层框架,经常访问物理数据库. 为了降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能. 缓存内的数据是对物理数 ...
- hibernate缓存机制详细分析
转自:http://www.cnblogs.com/xiaoluo501395377/p/3377604.html 在本篇随笔里将会分析一下hibernate的缓存机制,包括一级缓存(session级 ...
- Hibernate 缓存机制二(转)
感谢:http://www.cnblogs.com/wean/archive/2012/05/16/2502724.html 一.why(为什么要用Hibernate缓存?) Hibernate是一个 ...
随机推荐
- UVAlive6439_Pasti Pas!
题目是说给你一个字符串,现在要你用一些特殊的符号代替这个字符串中某一些子串,使得被替换后的串是一个回文串. 现在要你求替换后的字符串的最大的可能的长度. 其实这个题目没有什么固定的算法哦,我直接暴力就 ...
- Nginx在Linux上的安装和配置
链接:http://www.cnblogs.com/wbyp/p/7737224.html
- 整理:python的二维数组操作
Python中初始化一个5 x 3每项为0的数组,最好方法是: multilist = [[0 for col in range(5)] for row in range(3)] 如果初始化一个二维数 ...
- ajax请求提交到controller后总是不成功
最近在做实习时,点击查询时在js中发送ajax请求到controller后台,但是无论怎么样都不成功,请求地址是正确的,因为在后台用system.out.println输出有值,并且也确实return ...
- idea中Hibernate错误:无法解析表
idea中Hibernate错误:无法解析表 这种情况主要是在idea中使用hibernate自定义注解,idea无法检查数据源 this inspecton controls whether the ...
- bzoj 2428: [HAOI2006]均分数据 && bzoj 3680 : 吊打XXX 模拟退火
每次把元素随便扔随机一个初始解,退火时每次随机拿一个元素扔到随机一个集合里,当温度高时因为状态不稳定扔到那个元素和最小的里边. 如果新解优,更新ans. 把原式拆一下,就可以用int存了. bzoj ...
- poi导出word表格详解 超详细了
转:非常感谢原作者 poi导出word表格详解 2018年07月20日 10:41:33 Z丶royAl 阅读数:36138 一.效果如下 二.js代码 function export_word( ...
- Redis 创建多个端口 链接redis端口
默认的是6379 可以用6380,6381开启多个 1.开启 ./redis-server ../etc/redis.6380.conf & 2.链接 redis-cli -p 6380 查看 ...
- C# 在程序中控制IIS服务或应用程序池关闭重启
//停止IIS服务 ServiceController sc = new ServiceController("iisadmin"); if(sc.Status=ServiceCo ...
- linux下yum错误:[Errno 14] problem making ssl connection Trying other mirror.
今天是要yum命令安装EPEL仓库后 yum install epel-release 突然发现yum安装其他的软件出错. 错误:[Errno 14] problem making ssl conne ...