Python爬虫之selenium爬虫,模拟浏览器爬取天猫信息
由于工作需要,需要提取到天猫400个指定商品页面中指定的信息,于是有了这个爬虫。这是一个使用 selenium 爬取天猫商品信息的爬虫,虽然功能单一,但是也算是 selenium 爬虫的基本用法了。
源码展示
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import csv
import time class TM_itemdetail(object):
def __init__(self,readname='ids.txt',savename='info.csv'):
'''传入2个参数,分别是读取ID的文本名称和保存信息的表格名称,给予默认值'''
self.readname = readname
self.savename = savename
self.driver = webdriver.Chrome()
self.driver.maximize_window()
# 设置一个智能等待
self.waiter = WebDriverWait(self.driver,5)
self.get_csv() def get_csv(self):
'''创建一个表格,并且给表格添加标题行'''
with open(self.savename,'w',newline='') as f:
fieldnames = ['id','info']
writer = csv.DictWriter(f,fieldnames=fieldnames)
writer.writeheader() def write_info(self,info_dic):
'''写入单个信息,传入的参数是一个字典,字典的key跟表格的标题对应'''
with open(self.savename,'a',newline='') as f:
fieldnames = ['id', 'info']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writerow(info_dic) def get_ids(self):
'''读取文本的ID,形成一个列表'''
with open(self.readname,'r') as f:
lines = f.readlines()
ids = [k.replace('\n','').strip() for k in lines]
return ids def get_info(self,id):
'''爬虫的主要操作,模拟打开浏览器,找到信息的标签,提取后写入表格'''
dic = {}
url = 'https://detail.tmall.com/item.htm?id={}'.format(id)
self.driver.get(url)
# html = self.driver.page_source
# print(html)
try:
location = self.waiter.until(
EC.presence_of_element_located((By.XPATH,'//li[@class="J_step4Time"]'))
)
info = location.text.strip()
dic['id'] = id
dic['info'] = info if info else '信息为空白'
self.write_info(dic)
except TimeoutException as e:
print(e)
dic['id'] = id
dic['info'] = '{}超时,未找到信息'.format(e).strip()
self.write_info(dic) def main(self):
'''主函数,循环爬取,并打印相应的操作过程'''
ids = self.get_ids()
counter = len(ids)
i = 1
for id in ids:
self.get_info(id)
print('总计{}个,已经爬取{}个'.format(counter,i))
i += 1 if __name__ == '__main__':
start = time.time()
tm = TM_itemdetail()
tm.main()
tm.driver.close()
end = time.time()
print('运行结束,总耗时:{:.2f}秒'.format(end-start))
源码解析
这个爬虫主要由三个步骤构成:
- 读取文本中商品ID
- 循环爬取每个商品的信息
- 将信息保存到csv表格中
读取文本中的信息
由于是爬取给定的商品ID的宝贝的信息,所以需要一份包含商品ID的文本,文本中每行放入一个商品ID即可。
然后使用 Python 内置的方法,读取所有的商品ID并形成一个列表返回即可,这个过程可以封装到一个函数中,也即是下面这个:
def get_ids(self):
'''读取文本的ID,形成一个列表'''
with open(self.readname,'r') as f:
lines = f.readlines()
ids = [k.replace('\n','').strip() for k in lines]
return ids
这个函数看似没有传入参数,实际上因为是类的函数,所以有个参数是使用的类的属性,也就是文本的名称 self.readname。文件的读写可以使用 with...as... 语句,这种操作比较简洁方便。
爬取页面信息
下面截图中红色部分即使要提取的信息部分:
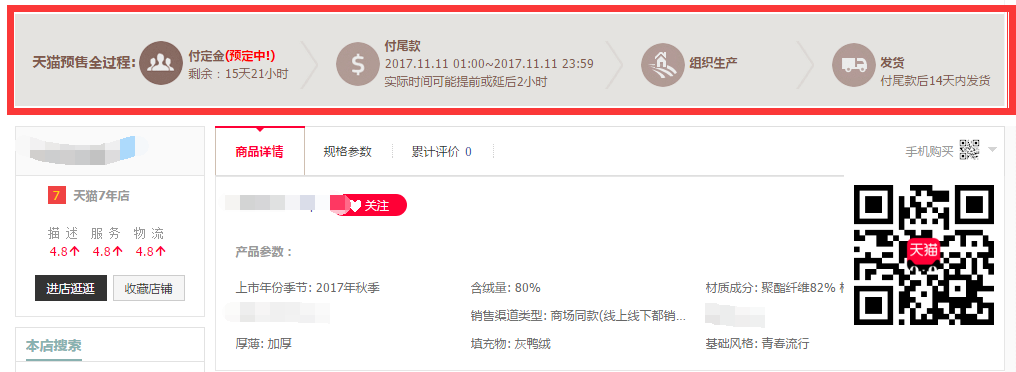
本来想着可以直接找到 URL 构造的规律去使用 requests 来爬的,但是最终还是遇到了难度,于是没有办法,只好祭出 selenium 这个大杀器!
selenium 爬虫的本质就是模拟浏览器的操作,所以这个爬虫很简单,只需要模拟浏览器打开以下网页,然后找到自己要的信息,提取就行了。
具体代码也封装到了一个函数中,这个函数需要传递一个参数,也就是一个商品ID,用来构成 URL 以便爬虫使用。
def get_info(self,id):
'''爬虫的主要操作,模拟打开浏览器,找到信息的标签,提取后写入表格'''
dic = {}
url = 'https://detail.tmall.com/item.htm?id={}'.format(id)
self.driver.get(url)
# html = self.driver.page_source
# print(html)
try:
location = self.waiter.until(
EC.presence_of_element_located((By.XPATH,'//li[@class="J_step4Time"]'))
)
info = location.text.strip()
dic['id'] = id
dic['info'] = info if info else '信息为空白'
self.write_info(dic)
except TimeoutException as e:
print(e)
dic['id'] = id
dic['info'] = '{}超时,未找到信息'.format(e).strip()
self.write_info(dic)
这个函数主要进行的操作流程为:
- 打开浏览器
- 输入一个 URL
- 等待页面刷新之后查找信息标签
- 提取指定信息,然后使用封装好的函数写入表格
其中最重要的步骤是提取信息的过程,这个使用了智能等待,也就是设定一个超时,然后浏览器会在这个超时的时间内智能的多次查找指定的信息,直到找到信息就进行下一步,否则继续刷新页面查找,直到超时时间到达报错。
保存信息到表格
信息已经提取,就需要保存起来,因为这个爬虫是工作需要,而且量也比较小,所以最佳的保存信息的方式就是 CSV 的表格形式了,直接使用 Python 自带的 csv 模块就可以。
信息保存分为2个部分:
- 在程序运行的最初,创建一个表格,并且给表格写入标题
- 在每次爬完一个页面,就在表格中写入一条信息
所以,写入表格的代码其实就是分成2个部分来的。
第一部分:
def get_csv(self):
'''创建一个表格,并且给表格添加标题行'''
with open(self.savename,'w',newline='') as f:
fieldnames = ['id','info']
writer = csv.DictWriter(f,fieldnames=fieldnames)
writer.writeheader()
这个部分创建了一个表格,并且可以看到,在爬虫类的的初始化中,已经运行了这个函数,也就是说,在爬虫创建的时候,就创建了一个表格。
self.get_csv()
第二部分:
def write_info(self,info_dic):
'''写入单个信息,传入的参数是一个字典,字典的key跟表格的标题对应'''
with open(self.savename,'a',newline='') as f:
fieldnames = ['id', 'info']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writerow(info_dic)
这个函数就是封装的写入信息,需要传入一个参数,也就是已经提取到的信息,这个信息需要写成字典的格式,因为在表格中已经创建了标题,所以可以直接使用标题的值来作为字典的 key。
循环爬取
最后,将整个爬虫的逻辑封装到一个主函数 main() 中即可,并且,为了可以及时看到爬虫的运行进度,可以在控制台中打印爬虫的进度信息。
def main(self):
'''主函数,循环爬取,并打印相应的操作过程'''
ids = self.get_ids()
counter = len(ids)
i = 1
for id in ids:
self.get_info(id)
print('总计{}个,已经爬取{}个'.format(counter,i))
i += 1
后记:不得不说,Python真的是个神器,很多需要花大量的时间去重复操作的一个事情,只需要花一点点时间写一个爬虫代码就能做到。
所以,那句话怎么说来着,人生苦短,快用 Python !
原创文章,装载请注明出处,文章内容来自 http://www.stopfollow.com/article/selenium-crawler-get-tmall-information/
Python爬虫之selenium爬虫,模拟浏览器爬取天猫信息的更多相关文章
- Python Requests库入门——应用实例-京东商品页面爬取+模拟浏览器爬取信息
京东商品页面爬取 选择了一款荣耀手机的页面(给华为打广告了,荣耀play真心不错) import requests url = "https://item.jd.com/7479912.ht ...
- Selenium+Chrome/phantomJS模拟浏览器爬取淘宝商品信息
#使用selenium+Carome/phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏 ...
- 爬虫之Selenium 动态渲染页面爬取
Selenim 是一个自动化测试工具,可以利用它驱动浏览器执行特定的动作,如点击.下拉等操作,同时可以获取浏览器当前呈现的页面的源代码,做到可见及可爬 1.使用流程 1)声明浏览器对象 Seleniu ...
- python模拟浏览器爬取数据
爬虫新手大坑:爬取数据的时候一定要设置header伪装成浏览器!!!! 在爬取某财经网站数据时由于没有设置Header信息,直接被封掉了ip 后来设置了Accept.Connection.User-A ...
- selenium+谷歌无头浏览器爬取网易新闻国内板块
网页分析 首先来看下要爬取的网站的页面 查看网页源代码:你会发现它是由js动态加载显示的 所以采用selenium+谷歌无头浏览器来爬取它 1 加载网站,并拖动到底,发现其还有个加载更多 2 模拟点击 ...
- scrapy模拟浏览器爬取验证码页面
使用selenium模块爬取验证码页面,selenium模块需要另外安装这里不讲环境的配置,我有一篇博客有专门讲ubuntn下安装和配置模拟浏览器的开发 spider的代码 # -*- coding: ...
- 关于爬虫的日常复习(10)—— 实战:使用selenium模拟浏览器爬取淘宝美食
- 使用PHP curl模拟浏览器抓取网站信息
curl是一个利用URL语法在命令行方式下工作的文件传输工具.curl是一个利用URL语法在命令行方式下工作的文件传输工具.它支持很多协议:FTP, FTPS, HTTP, HTTPS, GOPHER ...
- 3.使用Selenium模拟浏览器抓取淘宝商品美食信息
# 使用selenium+phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏览器翻页,并 ...
随机推荐
- 模拟界面请求到web服务器
客户端 package com.lsw.client; import java.io.*; import java.net.*; import java.util.*; public class HT ...
- 远程连接mysql root账号报错:2003-can't connect to MYSQL serve(转)
远程连接mysql root账号报错:2003-can't connect to MYSQL serve 1.远程连接Linux系统,登录数据库:mysql -uroot -p(密码) 2.修改roo ...
- python 全排列
itertools模块现成的全排列: for i in itertools.permutations('abcd',4): print ''.join(i) 相关全排列算法: def perm(l): ...
- Linux内核中断处理机制
<什么是中断> 计算停下当前处理任务,并保存现场,转而去处理其他是任务,当完成任务后再回到原来的任务中去. <中断的分类> a:软中断 软中断时执行中断指令产生的,软中 ...
- Codeforces Round #350 (Div. 2) E. Correct Bracket Sequence Editor 栈 链表
E. Correct Bracket Sequence Editor 题目连接: http://www.codeforces.com/contest/670/problem/E Description ...
- UVALive 5968
假如出现SS 那么表示Spring,如果出现SX的话,就表示WINTER,末尾出现S不管 #include <map> #include <set> #include < ...
- URAL 1880 Psych Up's Eigenvalues
1880. Psych Up's Eigenvalues Time limit: 0.5 secondMemory limit: 64 MB At one of the contests at the ...
- hdu 4277 USACO ORZ DFS
USACO ORZ Time Limit: 5000/1500 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total S ...
- Bootstrap 3之美05-排版、Button、Icon、Nav和NavBar、List、Table、Form
本篇主要包括: ■ 排版■ Button■ Icon■ Nav和NavBar■ List■ Table■ Form 排版 ● 斜体:<em>● 加粗体:<strong& ...
- Class.forName(String name)方法,到底会触发那个类加载器进行类加载行为?
4.2 在代码中直接调用Class.forName(String name)方法,到底会触发那个类加载器进行类加载行为? Class.forName(String name)默认会使用调用类的类加载器 ...