Hadoop学习之路(十三)MapReduce的初识
MapReduce是什么
首先让我们来重温一下 hadoop 的四大组件:
HDFS:分布式存储系统
MapReduce:分布式计算系统
YARN:hadoop 的资源调度系统
Common:以上三大组件的底层支撑组件,主要提供基础工具包和 RPC 框架等
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 Hadoop 的数据分析应用” 的核心框架
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布 式运算程序,并发运行在一个 Hadoop 集群上
为什么需要 MapReduce
1、海量数据在单机上处理因为硬件资源限制,无法胜任
2、而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度
3、引入 MapReduce 框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将 分布式计算中的复杂性交由框架来处理
设想一个海量数据场景下的数据计算需求:
| 单机版:磁盘受限,内存受限,计算能力受限 |
|
分布式版: 1、 数据存储的问题,hadoop 提供了 hdfs 解决了数据存储这个问题 2、 运算逻辑至少要分为两个阶段,先并发计算(map),然后汇总(reduce)结果 3、 这两个阶段的计算如何启动?如何协调? 4、 运算程序到底怎么执行?数据找程序还是程序找数据? 5、 如何分配两个阶段的多个运算任务? 6、 如何管理任务的执行过程中间状态,如何容错? 7、 如何监控? 8、 出错如何处理?抛异常?重试? |
可见在程序由单机版扩成分布式版时,会引入大量的复杂工作。为了提高开发效率,可以将 分布式程序中的公共功能封装成框架,让开发人员可以将精力集中于业务逻辑。
Hadoop 当中的 MapReduce 就是这样的一个分布式程序运算框架,它把大量分布式程序都会 涉及的到的内容都封装进了,让用户只用专注自己的业务逻辑代码的开发。它对应以上问题 的整体结构如下:
MRAppMaster:MapReduce Application Master,分配任务,协调任务的运行
MapTask:阶段并发任,负责 mapper 阶段的任务处理 YARNChild
ReduceTask:阶段汇总任务,负责 reducer 阶段的任务处理 YARNChild
MapReduce做什么

简单地讲,MapReduce可以做大数据处理。所谓大数据处理,即以价值为导向,对大数据加工、挖掘和优化等各种处理。
MapReduce擅长处理大数据,它为什么具有这种能力呢?这可由MapReduce的设计思想发觉。MapReduce的思想就是“分而治之”。
(1)Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:一是数据或计算的规模相对原任务要大大缩小;二是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;三是这些小任务可以并行计算,彼此间几乎没有依赖关系。
(2)Reducer负责对map阶段的结果进行汇总。至于需要多少个Reducer,用户可以根据具体问题,通过在mapred-site.xml配置文件里设置参数mapred.reduce.tasks的值,缺省值为1。
MapReduce 程序运行演示
在 MapReduce 组件里,官方给我们提供了一些样例程序,其中非常有名的就是 wordcount 和 pi 程序。这些 MapReduce 程序的代码都在 hadoop-mapreduce-examples-2.7.5.jar 包里,这 个 jar 包在 hadoop 安装目录下的/share/hadoop/mapreduce/目录里 下面我们使用 hadoop 命令来试跑例子程序,看看运行效果
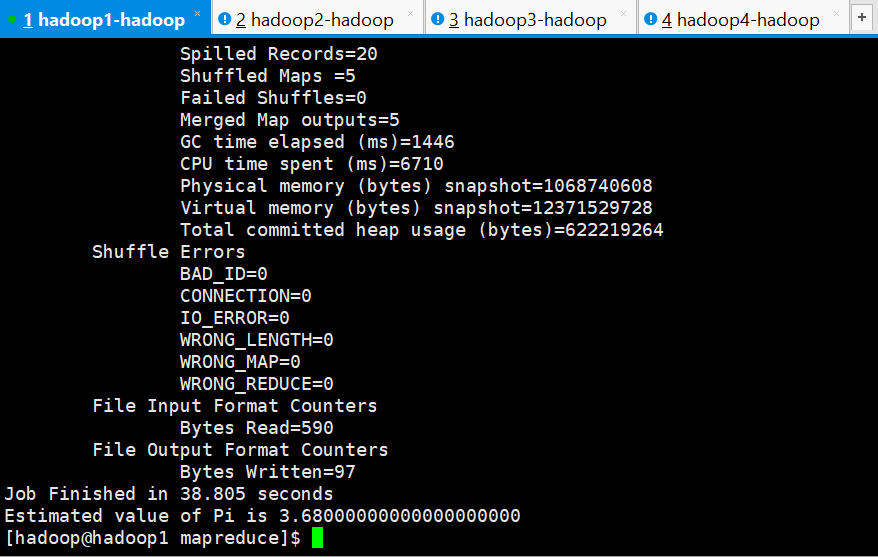
MapReduce 示例 pi 的程序
[hadoop@hadoop1 ~]$ cd apps/hadoop-2.7./share/hadoop/mapreduce/
[hadoop@hadoop1 mapreduce]$ pwd
/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce
[hadoop@hadoop1 mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.5.jar pi 5 5
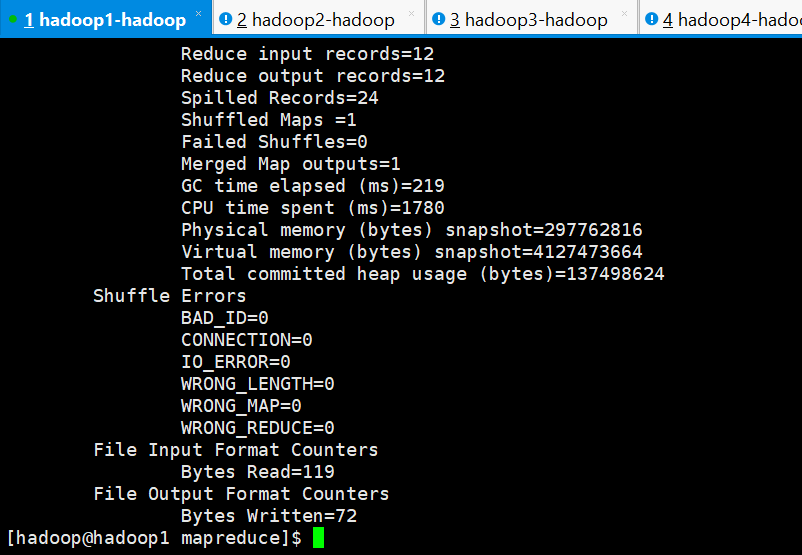
MapReduce 示例 wordcount 的程序
[hadoop@hadoop1 mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.5.jar wordcount /wc/input1/ /wc/output1/
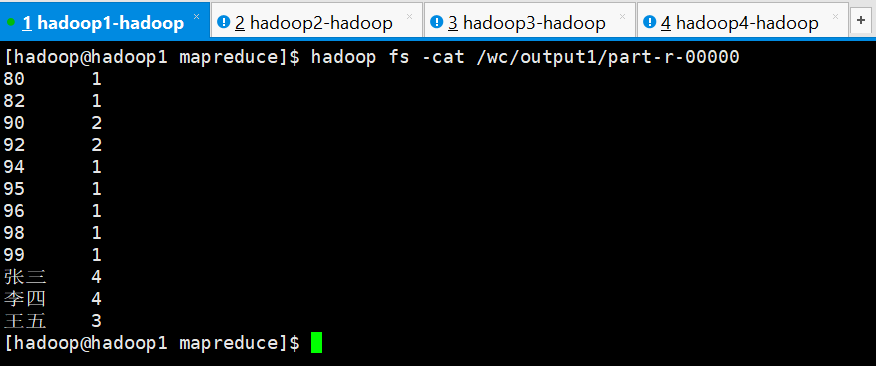
查看结果
[hadoop@hadoop1 mapreduce]$ hadoop fs -cat /wc/output1/part-r-00000
其他程序
那除了这两个程序以外,还有没有官方提供的其他程序呢,还有就是它们的源码在哪里呢?
我们打开 mapreduce 的源码工程,里面有一个 hadoop-mapreduce-project 项目:
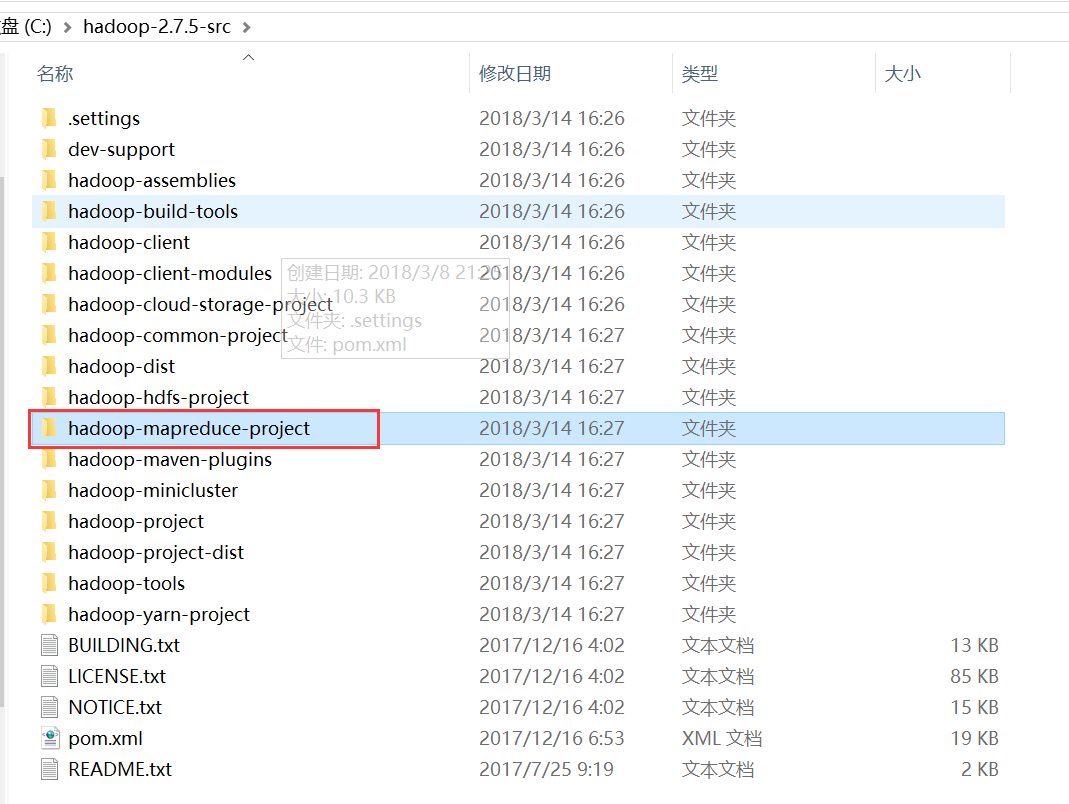
里面有一个例子程序的子项目:hadoop-mapreduce-examples
其中 src 是例子程序源码目录,pom.xml 是该项目的 maven 管理配置文件,我们打开该文件, 找到第 127 行,它告诉了我们例子程序的主程序入口:

找到src\main\java\org\apache\hadoop\examples目录
打开主入口程序,看源代码:
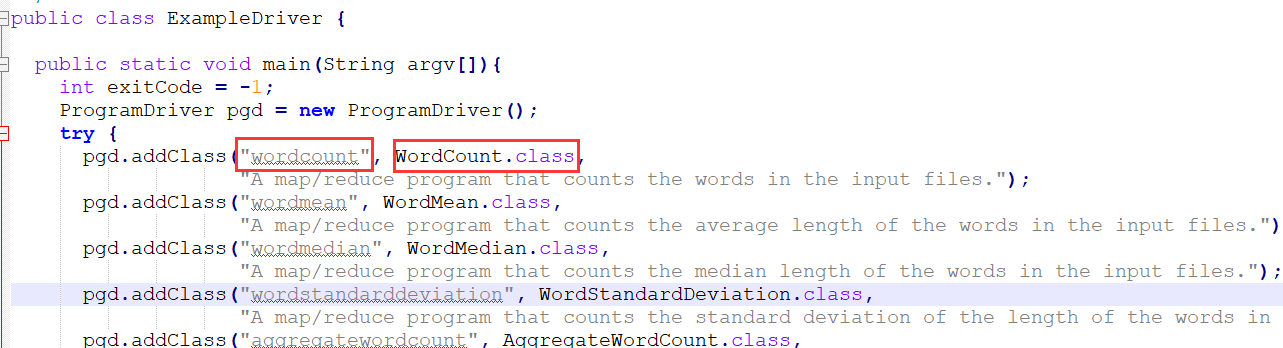
找到这一步,我们就能知道其实 wordcount 程序的实际程序就是 WordCount.class,这就是我 们想要找的例子程序的源码。
WordCount.java源码
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.examples; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
MapReduce 示例程序编写及编码规范
上一步,我们查看了 WordCount 这个 MapReduce 程序的源码编写,可以得出几点结论:
1、 该程序有一个 main 方法,来启动任务的运行,其中 job 对象就存储了该程序运行的必要 信息,比如指定 Mapper 类和 Reducer 类 job.setMapperClass(TokenizerMapper.class); job.setReducerClass(IntSumReducer.class);
2、 该程序中的 TokenizerMapper 类继承了 Mapper 类
3、 该程序中的 IntSumReducer 类继承了 Reducer 类
总结:MapReduce 程序的业务编码分为两个大部分,一部分配置程序的运行信息,一部分 编写该 MapReduce 程序的业务逻辑,并且业务逻辑的 map 阶段和 reduce 阶段的代码分别继 承 Mapper 类和 Reducer 类
编写自己的 Wordcount 程序
package com.ghgj.mapreduce.wc.demo; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
*
* 描述: MapReduce出入门:WordCount例子程序
*/
public class WordCountMR { /**
* 该main方法是该mapreduce程序运行的入口,其中用一个Job类对象来管理程序运行时所需要的很多参数:
* 比如,指定用哪个组件作为数据读取器、数据结果输出器 指定用哪个类作为map阶段的业务逻辑类,哪个类作为reduce阶段的业务逻辑类
* 指定wordcount job程序的jar包所在路径 .... 以及其他各种需要的参数
*/
public static void main(String[] args) throws Exception {
// 指定hdfs相关的参数
Configuration conf = new Configuration();
// conf.set("fs.defaultFS", "hdfs://hadoop02:9000");
System.setProperty("HADOOP_USER_NAME", "hadoop"); // 这是高可用的集群的配置文件。如果不是高可用集群,请自行替换配置文件
// conf.addResource("hdfs_config/core-site.xml");
// conf.addResource("hdfs_config/hdfs-site.xml"); // conf.set("mapreduce.framework.name", "yarn");
// conf.set("yarn.resourcemanager.hostname", "hadoop04"); // 通过Configuration对象获取Job对象,该job对象会组织所有的该MapReduce程序所有的各种组件
Job job = Job.getInstance(conf); // 设置jar包所在路径
job.setJarByClass(WordCountMR.class); // 指定mapper类和reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class); // Mapper的输入key-value类型,由MapReduce框架决定
// 指定maptask的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 假如 mapTask的输出key-value类型,跟reduceTask的输出key-value类型一致,那么,以上两句代码可以不用设置 // reduceTask的输入key-value类型 就是 mapTask的输出key-value类型。所以不需要指定
// 指定reducetask的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); // 为job指定输入数据的组件和输出数据的组件,以下两个参数是默认的,所以不指定也是OK的
// job.setInputFormatClass(TextInputFormat.class);
// job.setOutputFormatClass(TextOutputFormat.class); // 为该mapreduce程序制定默认的数据分区组件。默认是 HashPartitioner.class
// job.setPartitionerClass(HashPartitioner.class); // 如果MapReduce程序在Eclipse中,运行,也可以读取Windows系统本地的文件系统中的数据
Path inputPath = new Path("D:\\bigdata\\wordcount\\input");
Path outputPath = new Path("D:\\bigdata\\wordcount\\output33"); // 设置该MapReduce程序的ReduceTask的个数
// job.setNumReduceTasks(3); // 指定该mapreduce程序数据的输入和输出路径
// Path inputPath = new Path("/wordcount/input");
// Path outputPath = new Path("/wordcount/output");
// 该段代码是用来判断输出路径存在不存在,存在就删除,虽然方便操作,但请谨慎
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
} // 设置wordcount程序的输入路径
FileInputFormat.setInputPaths(job, inputPath);
// 设置wordcount程序的输出路径
FileOutputFormat.setOutputPath(job, outputPath); // job.submit();
// 最后提交任务(verbose布尔值 决定要不要将运行进度信息输出给用户)
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion ? 0 : 1);
} /**
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*
* KEYIN 是指框架读取到的数据的key的类型,在默认的InputFormat下,读到的key是一行文本的起始偏移量,所以key的类型是Long
* VALUEIN 是指框架读取到的数据的value的类型,在默认的InputFormat下,读到的value是一行文本的内容,所以value的类型是String
* KEYOUT 是指用户自定义逻辑方法返回的数据中key的类型,由用户业务逻辑决定,在此wordcount程序中,我们输出的key是单词,所以是String
* VALUEOUT 是指用户自定义逻辑方法返回的数据中value的类型,由用户业务逻辑决定,在此wordcount程序中,我们输出的value是单词的数量,所以是Integer
*
* 但是,String ,Long等jdk中自带的数据类型,在序列化时,效率比较低,hadoop为了提高序列化效率,自定义了一套序列化框架
* 所以,在hadoop的程序中,如果该数据需要进行序列化(写磁盘,或者网络传输),就一定要用实现了hadoop序列化框架的数据类型
*
* Long ----> LongWritable
* String ----> Text
* Integer ----> IntWritable
* Null ----> NullWritable
*/
static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { /**
* LongWritable key : 该key就是value该行文本的在文件当中的起始偏移量
* Text value : 就是MapReduce框架默认的数据读取组件TextInputFormat读取文件当中的一行文本
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 切分单词
String[] words = value.toString().split(" ");
for (String word : words) {
// 每个单词计数一次,也就是把单词组织成<hello,1>这样的key-value对往外写出
context.write(new Text(word), new IntWritable(1));
}
}
} /**
* 首先,和前面一样,Reducer类也有输入和输出,输入就是Map阶段的处理结果,输出就是Reduce最后的输出
* reducetask在调我们写的reduce方法,reducetask应该收到了前一阶段(map阶段)中所有maptask输出的数据中的一部分
* (数据的key.hashcode%reducetask数==本reductask号),所以reducetaks的输入类型必须和maptask的输出类型一样
*
* reducetask将这些收到kv数据拿来处理时,是这样调用我们的reduce方法的: 先将自己收到的所有的kv对按照k分组(根据k是否相同)
* 将某一组kv中的第一个kv中的k传给reduce方法的key变量,把这一组kv中所有的v用一个迭代器传给reduce方法的变量values
*/
static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { /**
* Text key : mapTask输出的key值
* Iterable<IntWritable> values : key对应的value的集合(该key只是相同的一个key)
*
* reduce方法接收key值相同的一组key-value进行汇总计算
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // 结果汇总
int sum = 0;
for (IntWritable v : values) {
sum += v.get();
}
// 汇总的结果往外输出
context.write(key, new IntWritable(sum));
}
}
}
MapReduce 程序编写规范
1、用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行 MR 程序的客户端)
2、Mapper 的输入数据是 KV 对的形式(KV 的类型可自定义)
3、Mapper 的输出数据是 KV 对的形式(KV 的类型可自定义)
4、Mapper 中的业务逻辑写在 map()方法中
5、map()方法(maptask 进程)对每一个<k,v>调用一次
6、Reducer 的输入数据类型对应 Mapper 的输出数据类型,也是 KV 对的形式
7、Reducer 的业务逻辑写在 reduce()方法中
8、Reducetask 进程对每一组相同 k 的<k,v>组调用一次 reduce()方法
9、用户自定义的 Mapper 和 Reducer 都要继承各自的父类
10、整个程序需要一个 Drvier 来进行提交,提交的是一个描述了各种必要信息的 job 对象
WordCount 的业务逻辑
1、 maptask 阶段处理每个数据分块的单词统计分析,思路是每遇到一个单词则把其转换成 一个 key-value 对,比如单词 hello,就转换成<’hello’,1>发送给 reducetask 去汇总
2、 reducetask 阶段将接受 maptask 的结果,来做汇总计数
MapReduce 运行方式及 Debug
集群运行模式
打 jar 包,提交任务到集群运行,适用:生产环境,不适用:测试,调试,开发
要点一:首先要把代码打成 jar 上传到 linux 服务器
要点二:用 hadoop jar 的命令去提交代码到 yarn 集群运行
要点三:处理的数据和输出结果应该位于 hdfs 文件系统
要点四:如果需要在 windows 中的 eclipse 当中直接提交 job 到集群,则需要修改 YarnRunner 类,这个比较复杂,不建议使用
本地运行模式
Eclipse 开发环境下本地运行,好处是方便调试和测试
直接在IDE环境中进行环境 : eclipse
1、直接运行在本地,读取本地数据
2、直接运行在本地,读取远程的文件系统的数据
3、直接在IDE中提交任务给YARN集群运行
Hadoop学习之路(十三)MapReduce的初识的更多相关文章
- Hadoop学习之路(7)MapReduce自定义排序
本文测试文本: tom 20 8000 nancy 22 8000 ketty 22 9000 stone 19 10000 green 19 11000 white 39 29000 socrate ...
- Hadoop学习之路(6)MapReduce自定义分区实现
MapReduce自带的分区器是HashPartitioner 原理:先对map输出的key求hash值,再模上reduce task个数,根据结果,决定此输出kv对,被匹配的reduce任务取走. ...
- Hadoop学习之路(5)Mapreduce程序完成wordcount
程序使用的测试文本数据: Dear River Dear River Bear Spark Car Dear Car Bear Car Dear Car River Car Spark Spark D ...
- 阿里封神谈hadoop学习之路
阿里封神谈hadoop学习之路 封神 2016-04-14 16:03:51 浏览3283 评论3 发表于: 阿里云E-MapReduce >> 开源大数据周刊 hadoop 学生 s ...
- 《Hadoop学习之路》学习实践
(实践机器:blog-bench) 本文用作博文<Hadoop学习之路>实践过程中遇到的问题记录. 本文所学习的博文为博主“扎心了,老铁” 博文记录.参考链接https://www.cnb ...
- Hadoop学习之路(二十)MapReduce求TopN
前言 在Hadoop中,排序是MapReduce的灵魂,MapTask和ReduceTask均会对数据按Key排序,这个操作是MR框架的默认行为,不管你的业务逻辑上是否需要这一操作. 技术点 MapR ...
- 小强的Hadoop学习之路
本人一直在做NET开发,接触这行有6年了吧.毕业也快四年了(6年是因为大学就开始在一家小公司做门户网站,哈哈哈),之前一直秉承着学要精,就一直一门心思的在做NET(也是懒吧).最近的工作一直都和大数据 ...
- 我的hadoop学习之路
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上. Ha ...
- Hadoop学习基础之三:MapReduce
现在是讨论这个问题的不错的时机,因为最近媒体上到处充斥着新的革命所谓“云计算”的信息.这种模式需要利用大量的(低端)处理器并行工作来解决计算问题.实际上,这建议利用大量的低端处理器来构建数据中心,而不 ...
- Hadoop学习之第一个MapReduce程序
期望 通过这个mapreduce程序了解mapreduce程序执行的流程,着重从程序解执行的打印信息中提炼出有用信息. 执行前 程序代码 程序代码基本上是<hadoop权威指南>上原封不动 ...
随机推荐
- 《码出高效 Java开发手册》第四章 走进JVM(未整理)
码云地址: https://gitee.com/forxiaoming/JavaBaseCode/tree/master/EasyCoding
- 撩课-Web大前端每天5道面试题-Day25
1.web前端开发,如何提高页面性能优化? 内容方面: .减少 HTTP 请求 (Make Fewer HTTP Requests) .减少 DOM 元素数量 (Reduce the Number o ...
- js/jq动态创建表格的行与列
之前做了一个项目,需求是能动态创建表格行,动态创建表格的列,度了很多资料,都没有动态创建列的插件,所以自己动手写了一个 需求大概是(下图) 1.动态添加一行.2.动态添加一列,3.删除行.4.删除列, ...
- 2016最新Java学习计划
一.Java学习路线图 二.Java学习路线图--视频篇 六大阶段 学完后目标 知识点 配套免费资源(视频+笔 记+源码+模板) 密码 第一阶段 Java基础 入门 学习周期: 35天 ...
- CentOS7系列--1.4CentOS7服务
CentOS7服务管理 1. 查看服务 1.1. 查看所有运行的服务 [root@centos7 ~]# systemctl -t service UNIT LOAD ACTIVE SUB DESCR ...
- 激活函数(relu,prelu,elu,+BN)对比on cifar10
激活函数(relu,prelu,elu,+BN)对比on cifar10 可参考上一篇: 激活函数 ReLU.LReLU.PReLU.CReLU.ELU.SELU 的定义和区别 一.理论基础 ...
- arcgis 加载高德地图 es6的方式
目前很多arcgis 加载高德地图是dojo的方式 外部引入文件,现在改成这种方式 /** * Created by Administrator on 2018/5/14 0014. */ impor ...
- linux erlang环境安装
1.安装环境:yum -y install make gcc gcc-c++ kernel-devel m4 glibc-devel autoconfyum -y install ncurses-de ...
- 前端构建工具 Gulp.js 上手实例
在软件开发中使用自动化构建工具的好处是显而易见的.通过工具自动化运行大量单调乏味.重复性的任务,比如图像压缩.文件合并.代码压缩.单元测试等等,可以为开发者节约大量的时间,使我们能够专注于真正重要的. ...
- alter system register的用法
转自 http://blog.csdn.net/njyxfw/article/details/7516143 今天一个同事问到我,有没动态注册监听的命令,查了下,找到了alter system reg ...