RabbitMQ上手记录–part 5-节点集群高可用(多服务器)
上一part《RabbitMQ上手记录–part 4-节点集群(单机多节点)》中介绍了RabbitMQ集群的一些概念以及实现了在单机上运行多个节点,并且将多个节点组成一个集群。
通常情况下的集群节点是不会都放在一个服务器上的,实际情况是分布在不同的服务器上,所以这里我们将会把集群节点部署在多个服务器上。同时基于集群节点我们会接着实现负载均衡,并且通过代码来演示在某个节点宕机之后,能自动连接到集群里的另外一个节点。
这部分演练将会用到负载均衡技术,具体就不详细说了,这个技术是分布式系统中非常基础的一项技术。这里我使用的软件负载均衡,使用的是HAProxy(同样不详细介绍,很容易找到资料)。
以下演练基于CentOS7操作系统
第一步搭建多服务器的节点集群
a.准备好三个CentOS服务器
这里准备三个虚拟机,分别安装好了RabbitMQ,IP地址如下
加点 主机名 IP
节点1(主节点) bogon 192.168.115.136
节点2 worker1 192.168.115.138
节点3 worker2 192.168.115.139
为了便于使用主机名通讯,需要在各个节点设置host文件的对应的IP地址
sudo vim /etc/hosts
加入如下内容
192.168.115.136 bogon
192.168.115.138 worker1
192.168.115.139 worker2
b.构建集群
步骤类似于《RabbitMQ上手记录–part 4-节点集群(单机多节点)》的方法,但是是在不同的服务器上执行,最重要的是确保各个RabbitMQ服务使用的相同的.erlang.cookie。
同步.erlang.cookie
.erlang.cookie
该文件位于/var/lib/rabbitmq/.erlang.cookie
这个文件的作用类似于一种身份验证信息,可以称为token,不同的RabbitMQ服务之间需要使用相同的token才能正常通讯。如果都在单机上实现多节点,用的是本机同一个文件,所以不需要设置。
好了,简单介绍.erlang.cookie文件之后,那么我们需要将节点1的.erlang.cookie的内容复制到节点2、节点3的.erlang.cookie中。
输出文件内容,然后手动拷贝到其他服务器上
sudo cat /var/lib/rabbitmq/.erlang.cookie
在主节点打开防火墙端口
sudo firewall-cmd --add-port=25672/tcp --permanent
sudo firewall-cmd --add-port=5672/tcp --permanent
sudo firewall-cmd --add-port=4369/tcp --permanent
将从节点加入集群
在节点2执行如下命令
sudo rabbitmqctl stop_app
sudo rabbitmqctl reset
sudo rabbitmqctl join_cluster rabbit@bogon
启动节点并查看集群状态
sudo rabbitmqctl start_app
sudo rabbitmqctl cluster_status
应该能看到类似如下输出
[{nodes,[{disc,[rabbit@bogon,rabbit@worker1]}]},
{running_nodes,[rabbit@bogon,rabbit@worker1]},
然后依次在节点3执行重复执行上述命令,完成集群节点添加
注意:这里执行命令的时候都不需要指定哪个节点,因为我们这里默认是一个服务器一个节点
第二步使用HAProxy
接下来利用刚配好的集群,我们来设置HAProxy的配置。
安装HAProxy
话说HAProxy的网站已经打不开了,估计需要用科学上网才行,但是找个安装包还是很容易的。
在主节点下载并安装HAProxy
http://www.rpmfind.net/linux/centos/7.4.1708/os/x86_64/Packages/haproxy-1.5.18-6.el7.x86_64.rpm
然后
yum -y install haproxy-1.5.18-6.el7.x86_64.rpm
HAProxy配置
新建文件haproxy_rabbitmq.cfg,内容如下
global
log 127.0.0.1 local0 info
maxconn 4096
stats socket /tmp/haproxy.socket uid haproxy mode 770 level admin
daemon defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
option redispatch
maxconn 2000
timeout connect 5s
timeout client 120s
timeout server 120s listen rabbitmq_local_cluster 192.168.115.136:5670
mode tcp
balance roundrobin
server rabbit_1 192.168.115.136:5672 check inter 5000 rise 2 fall 3
server rabbit_2 192.168.115.138:5672 check inter 5000 rise 2 fall 3
server rabbit_3 192.168.115.139:5672 check inter 5000 rise 2 fall 3 listen private_monitoring :8100
mode http
option httplog
stats enable
stats uri /stats
stats refresh 5s
大概描述一下上述配置
1.配置了站点集群配置rabbitmq_local_cluster,监听的端口号是5670
2.这个集群后面有三个服务器,分别对应的是我们集群的三个RabbitMQ服务节点
3.check inter 5000 rise 2 fall 3
check inter 5000 检查后端服务是否可用的时间间隔为5秒
rise 2 一个失败节点如果有2次检查到是可用的,则重新标记为可用
fall 3 如果节点有3次不可用,那么会被标记为失败节点
4.listen private_monitoring :8100
通过浏览器访问8100端口可以查看HAProxy的状态信息
具体去查看HAProxy的文档。
然后开启8100端口
sudo firewall-cmd --add-port=8100/tcp –permanent
启动HAProxy
sudo haproxy -f haproxy_rabbitmq.cfg
打开浏览器访问http://192.168.115.136:8100/stats
能看到如下节点统计信息,可以看到目前三个节点都是在运行状态的
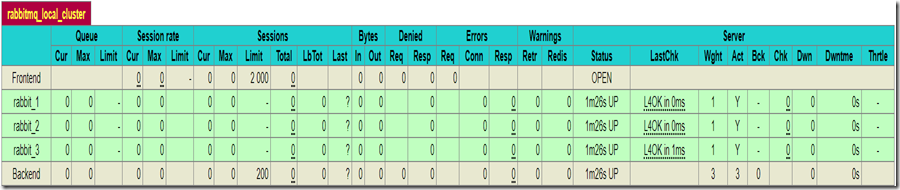
第三步使用节点集群
前面两步分别搭建了RabbitMQ的节点集群和利用HAproxy实现负载均衡,现在来看看如何在代码中使用节点集群。
在介绍程序之前,先明确节点失效重连的问题。节点集群主要的功能就是要实现高可用,在某个节点失效的情况下,还能继续提供服务。当客户端正在使用的节点失效时,对应的连接会失效,然后重新连接集群后会连接到另外一个可用的节点。所以之前定义的exchange,queue都不能确保还能重用,因此在失效转移之后,我们可以认为是重新连接到了一个全新的节点,涉及的exchange,queue和bindings都需要重新定义。
a.创建RabbitMQ用户
创建一个用于在客户端连接RabbitMQ集群的用户,之前默认的guest用户只能在服务器本机使用。
在主节点执行如下命令,创建用户admin,密码为123456,设置为管理员并且设置对默认的vhost有所有访问权(这里只是演示,通常情况下不会给这么广的权限)
sudo rabbitmqctl add_user admin 123456
sudo rabbitmqctl set_user_tags admin administrator
sudo rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"
b.消费者代码
这里还是使用Python的实现,新建cluster_node_consumer.py,代码如下
import sys, json, pika, time, traceback def msg_rcvd(channel, method, header, body):
message = json.loads(body)
print "Received: %(content)s/%(time)d" % message
channel.basic_ack(delivery_tag=method.delivery_tag) if __name__ == "__main__":
AMQP_SERVER = sys.argv[1]
AMQP_PORT = int(sys.argv[2])
AMQP_USER = sys.argv[3]
AMQP_PWD = sys.argv[4] creds_broker = pika.PlainCredentials(AMQP_USER, AMQP_PWD)
conn_params = pika.ConnectionParameters(
AMQP_SERVER,
port=AMQP_PORT,
virtual_host="/",
credentials=creds_broker) while True:
try:
conn_broker = pika.BlockingConnection(conn_params)
channel = conn_broker.channel()
channel.exchange_declare(
exchange="cluster_test", exchange_type="direct", auto_delete=False)
channel.queue_declare(queue="cluster_test", auto_delete=False)
channel.queue_bind(
queue="cluster_test",
exchange="cluster_test",
routing_key="cluster_test") print "Ready for testing!"
channel.basic_consume(msg_rcvd, queue="cluster_test", no_ack=False, consumer_tag="cluster_test")
channel.start_consuming()
except Exception, e:
traceback.print_exc()
上述代码从命令行读取服务器的地址,端口,用户名和密码,然后创建连接。
最关键的是while True部分,这里使用了try catch捕获所有异常,确保在出现异常之后能重新创建连接。
重新连接之后,会重新执行创建queue,exchange和binding。
执行如下命令运行消费者程序
python cluster_node_consumer.py 192.168.115.136 5670 admin 123456
192.168.115.136 是HAproxy配置的对外地址
5670 是HAproxy配置的访问端口
admin 123456 分别是在主节点创建的RabbitMQ用户名和密码
输出
Ready for testing!
看到这输出并且没有其他异常信息时,说明已经连接上了集群。
这时候我们可以在HAproxy的状态统计站点http://192.168.115.136:8100/stats查看当前连接的是哪个节点。
查看Cur这一列,这里显示的节点当前的连接数,可以看到rabbit_3有一个连接,那么就是刚刚消费者程序创建的,并且目前正在使用。
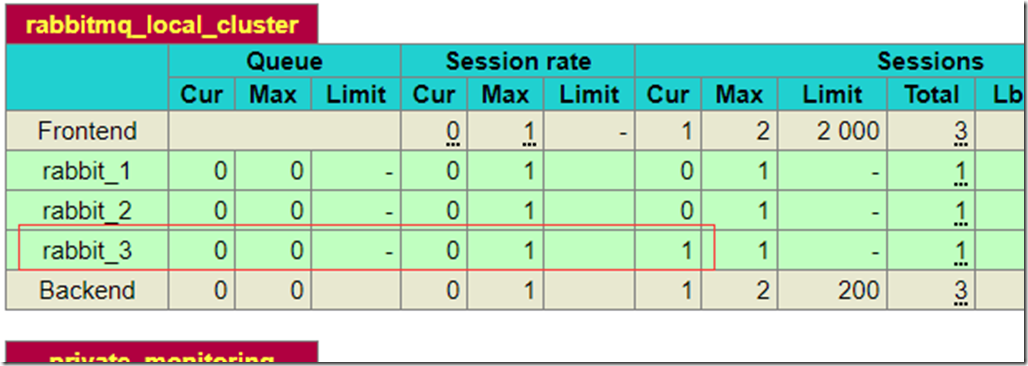
这时候将rabbit_3停止,登录节点3,执行如下命令
sudo rabbitmqctl stop_app
那么在运行消费者程序的控制台就会看到如下输出
Traceback (most recent call last):
File "cluster_node_consumer.py", line 37, in <module>
channel.start_consuming()
File "/home/junwen/anaconda2/lib/python2.7/site-packages/pika/adapters/blocking_connection.py", line 1780, in start_consuming
self.connection.process_data_events(time_limit=None)
File "/home/junwen/anaconda2/lib/python2.7/site-packages/pika/adapters/blocking_connection.py", line 707, in process_data_events
self._flush_output(common_terminator)
File "/home/junwen/anaconda2/lib/python2.7/site-packages/pika/adapters/blocking_connection.py", line 474, in _flush_output
result.reason_text)
ConnectionClosed: (320, "CONNECTION_FORCED - broker forced connection closure with reason 'shutdown'")
Ready for testing!
可以看到一连串的异常信息输出,最后是Ready for testing!说明客户端连接被断开了,抛出了异常信息,然后又重新连接了。
我们再看看目前HAProxy的状态信息
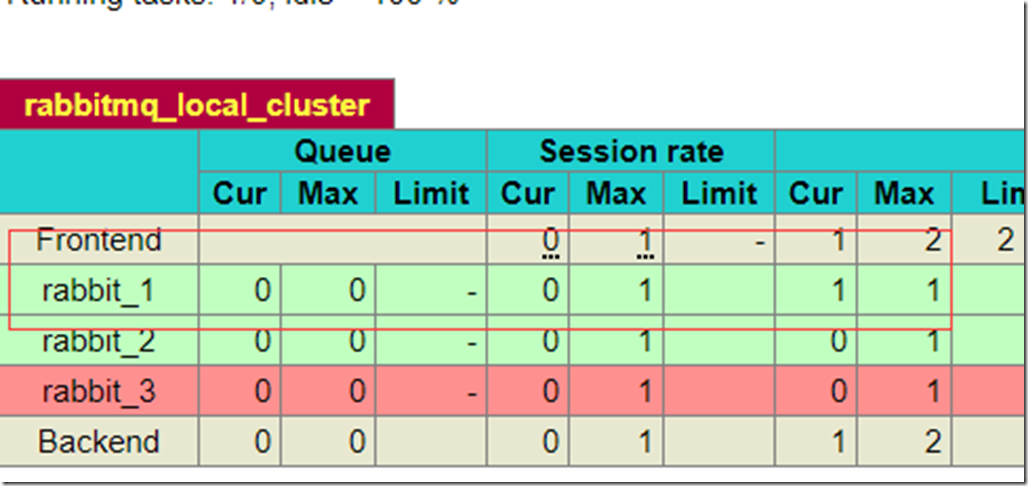
可以看到rabbit_3目前是不可用状态。rabbit_1有一个连接,就是刚才程序连接失效之后重新创建的连接。
c.生产者代码
生产者的这端的代码比较简单,跟普通的调用没有区别,只是链接的地址是HAProxy的服务地址。
新建cluster_node_producer.py,代码如下
import sys, time, json, pika AMQP_SERVER = sys.argv[1]
AMQP_PORT = int(sys.argv[2])
AMQP_USER = sys.argv[3]
AMQP_PWD = sys.argv[4] creds_broker = pika.PlainCredentials(AMQP_USER, AMQP_PWD)
conn_params = pika.ConnectionParameters(
AMQP_SERVER, port=AMQP_PORT, virtual_host="/", credentials=creds_broker) conn_broker = pika.BlockingConnection(conn_params) channel = conn_broker.channel() msg = json.dumps({"content": "Cluster Test!", "time": time.time()}) msg_props = pika.BasicProperties(content_type="application/json") channel.basic_publish(
body=msg,
exchange="cluster_test",
properties=msg_props,
routing_key="cluster_test") print "Sent cluster test message."
上述代码中链接服务器部分跟消费者的代码一致,都是从命令行读取参数,然后创建连接。
创建连接之后,立即发布一个消息,消息内容也是写死的。
新开一个终端,运行生产者代码
python cluster_node_producer.py 192.168.115.136 5670 admin 123456
在消费者代码运行的那个终端可以看到如下输出
Received: Cluster Test!/1524405533
这里生产者的代码实际上只是演示可以连接到HAProxy服务,所以消息发送之后就会关闭连接。
完整的代码文件请参考https://github.com/shenba2014/RabbitMQ/tree/master/cluster
OK,到此跨服务器的节点集群演示完毕,后续研究一下如何解决多数据中心高可用的问题。
RabbitMQ上手记录–part 5-节点集群高可用(多服务器)的更多相关文章
- linux RHCS集群 高可用web服务器
RHCS集群,高可用服务器 高可用 红帽集群套件,提供高可用性,高可靠性,负载均衡,快速的从一个节点切换到另一个节点(最多16个节点)负载均衡 通过lvs提供负载均衡,lvs将负载通过负载分配策略,将 ...
- RabbitMQ从零到集群高可用(.NetCore5.0) -高可用集群构建落地
系列文章: RabbitMQ从零到集群高可用(.NetCore5.0) - RabbitMQ简介和六种工作模式详解 RabbitMQ从零到集群高可用(.NetCore5.0) - 死信队列,延时队列 ...
- Rabbitmq集群高可用测试
Rabbitmq集群高可用 RabbitMQ是用erlang开发的,集群非常方便,因为erlang天生就是一门分布式语言,但其本身并不支持负载均衡. Rabbit模式大概分为以下三种:单一模式.普通模 ...
- RabbitMQ从零到集群高可用(.NetCore5.0) - 死信队列,延时队列
系列文章: RabbitMQ从零到集群高可用(.NetCore5.0) - RabbitMQ简介和六种工作模式详解 RabbitMQ从零到集群高可用(.NetCore5.0) - 死信队列,延时队列 ...
- openstack pike 集群高可用 安装 部署 目录汇总
# openstack pike 集群高可用 安装部署#安装环境 centos 7 史上最详细的openstack pike版 部署文档欢迎经验分享,欢迎笔记分享欢迎留言,或加QQ群663105353 ...
- bitmq集群高可用测试
Rabbitmq集群高可用 RabbitMQ是用erlang开发的,集群非常方便,因为erlang天生就是一门分布式语言,但其本身并不支持负载均衡. Rabbit模式大概分为以下三种:单一模式.普通模 ...
- 浅谈MySQL集群高可用架构
前言 高可用架构对于互联网服务基本是标配,无论是应用服务还是数据库服务都需要做到高可用.对于一个系统而言,可能包含很多模块,比如前端应用,缓存,数据库,搜索,消息队列等,每个模块都需要做到高可用,才能 ...
- Eureka 集群高可用配置.
SERVER:1 server: port: 1111 eureka: instance: hostname: ${spring.cloud.client.ip-address} instance-i ...
- mysql集群高可用架构
前言 高可用架构对于互联网服务基本是标配,无论是应用服务还是数据库服务都需要做到高可用.对于一个系统而言,可能包含很多模块,比如前端应用,缓存,数据库,搜索,消息队列等,每个模块都需要做到高可用,才能 ...
- hadoop+zookeeper集群高可用搭建
hadoop+zookeeper集群高可用搭建 Senerity 发布于 2 ...
随机推荐
- 一起学习MVC(4)Controllers的学习
控制器Controllers Controllers为控制器文档,AccountControllers内的方法对应View→Account下的cshtml文件. 我们看到Aco ...
- Tasks遇到的一些坑,关于在子线程中对线程权限认证。
一般情况下,不应该在执行多线程认证的时候对其子线程进行身份认证,如:A线程的子线程B和子线程C. 当使用 Parallel.ForEach方法时,只有自身线程能够拥有相对应的权限,其子线程权限则为NU ...
- C#中获取用户登录IP地址
using System.Net; //导入命名空间 public string getLocalIP() { string strHostName = Dns.GetHostName(); //得到 ...
- 浏览器对HTTP请求的编码行为
浏览器对请求的URL编码行为 浏览器会对请求的URL中非ASCII码字符进行编码.这里不是指对整个URL进行编码,而是仅仅对非ASCII码字符部分进行编码,详情请看下面的实验记录. 实验一:在URL参 ...
- Day 19 re 模块 random模块,正则表达式
https://www.cnblogs.com/Eva-J/p/7228075.html#_label10 findall search match方法 和 search相比 match自带 ^ se ...
- openvswitch BFD 简介
为了保护关键应用,网络中会设计有一定的冗余备份链路,网络发生故障时就要求网络设备能够快速检测出故障并将流量切换至备份链路以加快网络收敛速度.目前有些链路(如POS)通过硬件检测机制来实现快速故障检测. ...
- Retrofit源码解析(上)
简介Retrofit是Square公司开发的一款针对Android网络请求的框架,官网地址http://square.github.io/retrofit/ ,在官网上有这样的一句话介绍retrofi ...
- Unity色子的投掷与点数的获得(详解)
前几天需要一个色子的投掷并且获得朝上点数的Unity脚本,在网上找了很多,都是一个模子刻出来的. 对于2018版的我来说,网上找的都是很早就弃用了的老版本. 好不容易能运行了,结果并不理想,于是又突发 ...
- javascript中创建对象的几种不同方法
javascript中创建对象的几种不同方法 方法一:最直白的方式:字面量模式创建 <script> var person={ name:"小明", age:20, s ...
- ubuntu sudo: pip:找不到命令
编辑文件 /etc/sudoers sudo vi /etc/sudoers 将Defaults env_reset ,改为 Defaults !env_reset 编辑文件-/.bashers ...