Spark(十六)DataSet
Spark最吸引开发者的就是简单易用、跨语言(Scala, Java, Python, and R)的API。
本文主要讲解Apache Spark 2.0中RDD,DataFrame和Dataset三种API;它们各自适合的使用场景;它们的性能和优化;列举使用DataFrame和DataSet代替RDD的场景。本文聚焦DataFrame和Dataset,因为这是Apache Spark 2.0的API统一的重点。
Apache Spark 2.0统一API的主要动机是:简化Spark。通过减少用户学习的概念和提供结构化的数据进行处理。除了结构化,Spark也提供higher-level抽象和API作为特定领域语言(DSL)。
弹性数据集(RDD)
RDD是Spark建立之初的核心API。RDD是不可变分布式弹性数据集,在Spark集群中可跨节点分区,并提供分布式low-level API来操作RDD,包括transformation和action。
何时使用RDD?
使用RDD的一般场景:
你需要使用low-level的transformation和action来控制你的数据集;
你的数据集非结构化,比如:流媒体或者文本流;
你想使用函数式编程来操作你的数据,而不是用特定领域语言(DSL)表达;
你不想加入schema,比如,当通过名字或者列处理(或访问)数据属性不在意列式存储格式;
当你可以放弃使用DataFrame和Dataset来优化结构化和半结构化数据集的时候。
在Spark2.0中RDD发生了什么
你可能会问:RDD是不是成为“二等公民”了?或者是不是干脆以后不用了?
答案当然是NO!
通过后面的描述你会得知:Spark用户可以在RDD,DataFrame和Dataset三种数据集之间无缝转换,而且只需要使用超级简单的API方法。
DataFrames
DataFrame与RDD相同之处,都是不可变分布式弹性数据集。不同之处在于,DataFrame的数据集都是按指定列存储,即结构化数据。类似于传统数据库中的表。DataFrame的设计是为了让大数据处理起来更容易。DataFrame允许开发者把结构化数据集导入DataFrame,并做了higher-level的抽象;DataFrame提供特定领域的语言(DSL)API来操作你的数据集。
在Spark2.0中,DataFrame API将会和Dataset API合并,统一数据处理API。由于这个统一“有点急”,导致大部分Spark开发者对Dataset的high-level和type-safe API并没有什么概念。
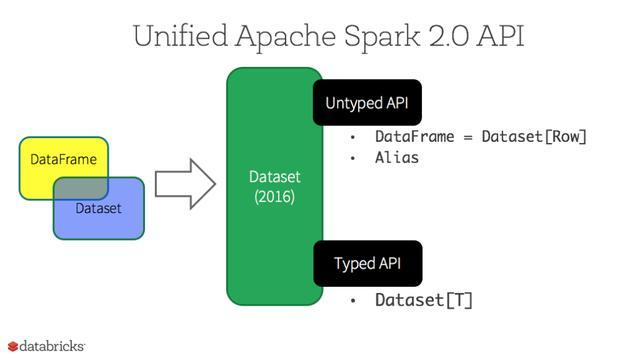
DataSets
从Spark2.0开始,DataSets扮演了两种不同的角色:强类型API和弱类型API,见下表。从概念上来讲,可以把DataFrame 当作一个泛型对象的集合DataSet[Row], Row是一个弱类型JVM 对象。相对应地,如果JVM对象是通过Scala的case class或者Java class来表示的,Dataset是强类型的。
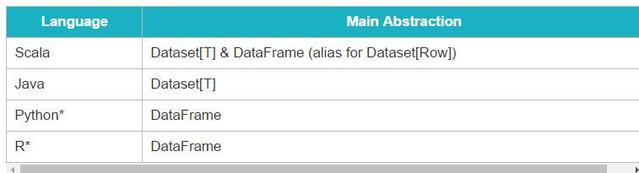
Dataset API的优势
对于Spark开发者而言,你将从Spark 2.0的DataFrame和Dataset统一的API获得以下好处:
1. 静态类型和运行时类型安全
考虑静态类型和运行时类型安全,SQL有很少的限制而Dataset限制很多。例如,Spark SQL查询语句,你直到运行时才能发现语法错误(syntax error),代价较大。然后DataFrame和Dataset在编译时就可捕捉到错误,节约开发时间和成本。
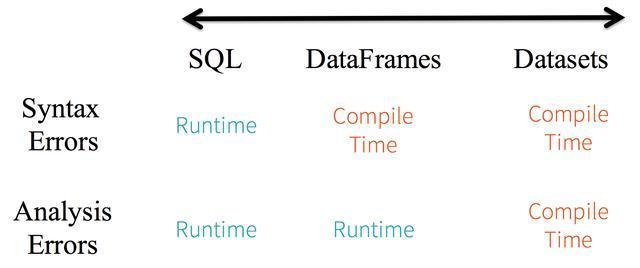
Dataset API都是lambda函数和JVM typed object,任何typed-parameters不匹配即会在编译阶段报错。因此使用Dataset节约开发时间。
2. High-level抽象以及结构化和半结构化数据集的自定义视图
DataFrame是Dataset[Row]的集合,把结构化数据集视图转换成半结构化数据集。例如,有个海量IoT设备事件数据集,用JSON格式表示。JSON是一个半结构化数据格式,很适合使用Dataset, 转成强类型的Dataset[DeviceIoTData]。
使用Scala为JSON数据DeviceIoTData定义case class。

紧接着,从JSON文件读取数据

上面代码运行时底层会发生下面3件事。
Spark读取JSON文件,推断出其schema,创建一个DataFrame;
Spark把数据集转换DataFrame -> Dataset[Row],泛型Row object,因为这时还不知道其确切类型;
Spark进行转换:Dataset[Row] -> Dataset[DeviceIoTData],DeviceIoTData类的Scala JVM object
我们的大多数人,在操作结构化数据时,都习惯于以列的方式查看和处理数据列,或者访问对象的指定列。Dataset 是Dataset[ElementType]类型对象的集合,既可以编译时类型安全,也可以为强类型的JVM对象定义视图。从上面代码获取到的数据可以很简单的展示出来,或者用高层方法处理。
3. 简单易用的API
虽然结构化数据会给Spark程序操作数据集带来挺多限制,但它却引进了丰富的语义和易用的特定领域语言。大部分计算可以被Dataset的high-level API所支持。例如,简单的操作agg,select,avg,map,filter或者groupBy即可访问DeviceIoTData类型的Dataset。
使用特定领域语言API进行计算是非常简单的。例如,使用filter()和map()创建另一个Dataset。
把计算过程翻译成领域API比RDD的关系代数式表达式要容易的多。例如:

4. 性能和优化
使用DataFrame和Dataset API获得空间效率和性能优化的两个原因:
首先:因为DataFrame和Dataset是在Spark SQL 引擎上构建的,它会使用Catalyst优化器来生成优化过的逻辑计划和物理查询计划。
R,Java,Scala或者Python的DataFrame/Dataset API,所有的关系型的查询都运行在相同的代码优化器下,代码优化器带来的的是空间和速度的提升。不同的是Dataset[T]强类型API优化数据引擎任务,而弱类型API DataFrame在交互式分析场景上更快,更合适。

其次,通过博客https://databricks.com/blog/2016/05/23/apache-spark-as-a-compiler-joining-a-billion-rows-per-second-on-a-laptop.html 可以知道:Dataset能使用Encoder映射特定类型的JVM 对象到Tungsten内部内存表示。Tungsten的Encoder可以有效的序列化/反序列化JVM object,生成字节码来提高执行速度。
什么时候使用DataFrame或者Dataset?
你想使用丰富的语义,high-level抽象,和特定领域语言API,那你可以使用DataFrame或者Dataset;
你处理的半结构化数据集需要high-level表达,filter,map,aggregation,average,sum,SQL查询,列式访问和使用lambda函数,那你可以使用DataFrame或者Dataset;
想利用编译时高度的type-safety,Catalyst优化和Tungsten的code生成,那你可以使用DataFrame或者Dataset;
你想统一和简化API使用跨Spark的Library,那你可以使用DataFrame或者Dataset;
如果你是一个R使用者,那你可以使用DataFrame或者Dataset;
如果你是一个Python使用者,那你可以使用DataFrame或者Dataset。
你可以无缝地把DataFrame或者Dataset转化成一个RDD,只需简单的调用.rdd:
总结
通过上面的分析,什么情况选择RDD,DataFrame还是Dataset已经很明显了。RDD适合需要low-level函数式编程和操作数据集的情况;DataFrame和Dataset适合结构化数据集,使用high-level和特定领域语言(DSL)编程,空间效率高和速度快。
Spark(十六)DataSet的更多相关文章
- Spark(十六)【SparkStreaming基本使用】
目录 一. SparkStreaming简介 1. 相关术语 2. SparkStreaming概念 3. SparkStreaming架构 4. 背压机制 二. Dstream入门 1. WordC ...
- 十六款值得关注的NoSQL与NewSQL数据库--转载
原文地址:http://tech.it168.com/a2014/0929/1670/000001670840_all.shtml [IT168 评论]传统关系型数据库在诞生之时并未考虑到如今如火如荼 ...
- ASP.NET Core 2.2 : 十六.扒一扒新的Endpoint路由方案 try.dot.net 的正确使用姿势 .Net NPOI 根据excel模板导出excel、直接生成excel .Net NPOI 上传excel文件、提交后台获取excel里的数据
ASP.NET Core 2.2 : 十六.扒一扒新的Endpoint路由方案 ASP.NET Core 从2.2版本开始,采用了一个新的名为Endpoint的路由方案,与原来的方案在使用上差别不 ...
- Alink漫谈(十六) :Word2Vec源码分析 之 建立霍夫曼树
Alink漫谈(十六) :Word2Vec源码分析 之 建立霍夫曼树 目录 Alink漫谈(十六) :Word2Vec源码分析 之 建立霍夫曼树 0x00 摘要 0x01 背景概念 1.1 词向量基础 ...
- 我的MYSQL学习心得(十六) 优化
我的MYSQL学习心得(十六) 优化 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据 ...
- Bootstrap <基础二十六>进度条
Bootstrap 进度条.在本教程中,你将看到如何使用 Bootstrap 创建加载.重定向或动作状态的进度条. Bootstrap 进度条使用 CSS3 过渡和动画来获得该效果.Internet ...
- Bootstrap<基础十六> 导航元素
Bootstrap 提供的用于定义导航元素的一些选项.它们使用相同的标记和基类 .nav.Bootstrap 也提供了一个用于共享标记和状态的帮助器类.改变修饰的 class,可以在不同的样式间进行切 ...
- 解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译)
解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译) http://improve.dk/orcamdf-rawdatabase-a-swiss-a ...
- Senparc.Weixin.MP SDK 微信公众平台开发教程(十六):AccessToken自动管理机制
在<Senparc.Weixin.MP SDK 微信公众平台开发教程(八):通用接口说明>中,我介绍了获取AccessToken(通用接口)的方法. 在实际的开发过程中,所有的高级接口都需 ...
随机推荐
- Python【pymysql】模块
import pymysql# 1.连上数据库 账号.密码 ip 端口号 数据库#2.建立游标#3.执行sql#4 .获取结果# 5.关闭游标#6.连接关闭coon = pymysql.connect ...
- NO.3day 网络基础
网络基础 1.互联网协议 概念:通过互联网传输数据的标准. 功能:定义计算机如何接入internet,以及接入internet的计算机通信的标准. 2.OSI五层模型 应用层--传输层--网络层--数 ...
- python安装pymssql
安装pymssql pip install pymssql 关于python安装pymssql报错export PYMSSQL_BUILD_WITH_BUNDLED_FREETDS=1 然后再 pip ...
- javascript精雕细琢(一):var let const function声明的区别
目录 引言 一.var 二.let 三.const 四.function 五.总结 引言 在学习javascript的过程中,变量是无时无刻不在使用的.那么相对应的,变量声明方法也如是. ...
- JAVA多线程提高十四: 面试题
前面针对多线程相关知识点进行了学习,那么我们来来看看常见的面试题: 1. 空中网面试题1 package com.kongzhongwang.interview; import java.util.c ...
- 51nod1312 最大异或和
题目来源: TopCoder 基准时间限制:1 秒 空间限制:131072 KB 分值: 320 有一个正整数数组S,S中有N个元素,这些元素分别是S[0],S[1],S[2]...,S[N-1]. ...
- 20155301 2016-2017-2 《Java程序设计》第5周学习总结
20155301 2016-2017-2 <Java程序设计>第5周学习总结 教材学习内容总结 1.1try.catch关键词,在用户不小心输入错误的时候,程序会出现错误信息,将代表错误的 ...
- java保存json格式数据,保存字符串和读取字符串
1.java保存json格式数据,保存字符串和读取字符串 import java.io.*; class RWJson { public void wiite(String s, String toS ...
- 爬虫笔记之JS检测浏览器开发者工具是否打开
在某些情况下我们需要检测当前用户是否打开了浏览器开发者工具,比如前端爬虫检测,如果检测到用户打开了控制台就认为是潜在的爬虫用户,再通过其它策略对其进行处理.本篇文章主要讲述几种前端JS检测开发者工具是 ...
- 50、多线程创建的三种方式之实现Runnable接口
实现Runnable接口创建线程 使用Runnable创建线程步骤: package com.sutaoyu.Thread; //1.自定义一个类实现java.lang包下的Runnable接口 cl ...