学习sklearn聚类使用
学习利用sklearn的几个聚类方法:
一.几种聚类方法
1.高斯混合聚类(mixture of gaussians)
2.k均值聚类(kmeans)
3.密度聚类,均值漂移(mean shift)
4.层次聚类或连接聚类(ward最小离差平方和)
二.评估方法
1.完整性:值:0-1,同一个类别所有数据样本是否划分到同一个簇中
2.同质性:值:0-1,每个簇是否只包含同一个类别的样本
3.上面两个的调和均值
4.以上三种在评分时需要用到数据样本的真正标签,但实际很难做到。轮廓系数(1,-1):只使用聚类的数据,它计算的是每个数据样本与同簇数据样本和其它簇数据样本之间的相似度,因为从平均来看,与同簇比较起来,比其它簇更相似。
三.说明
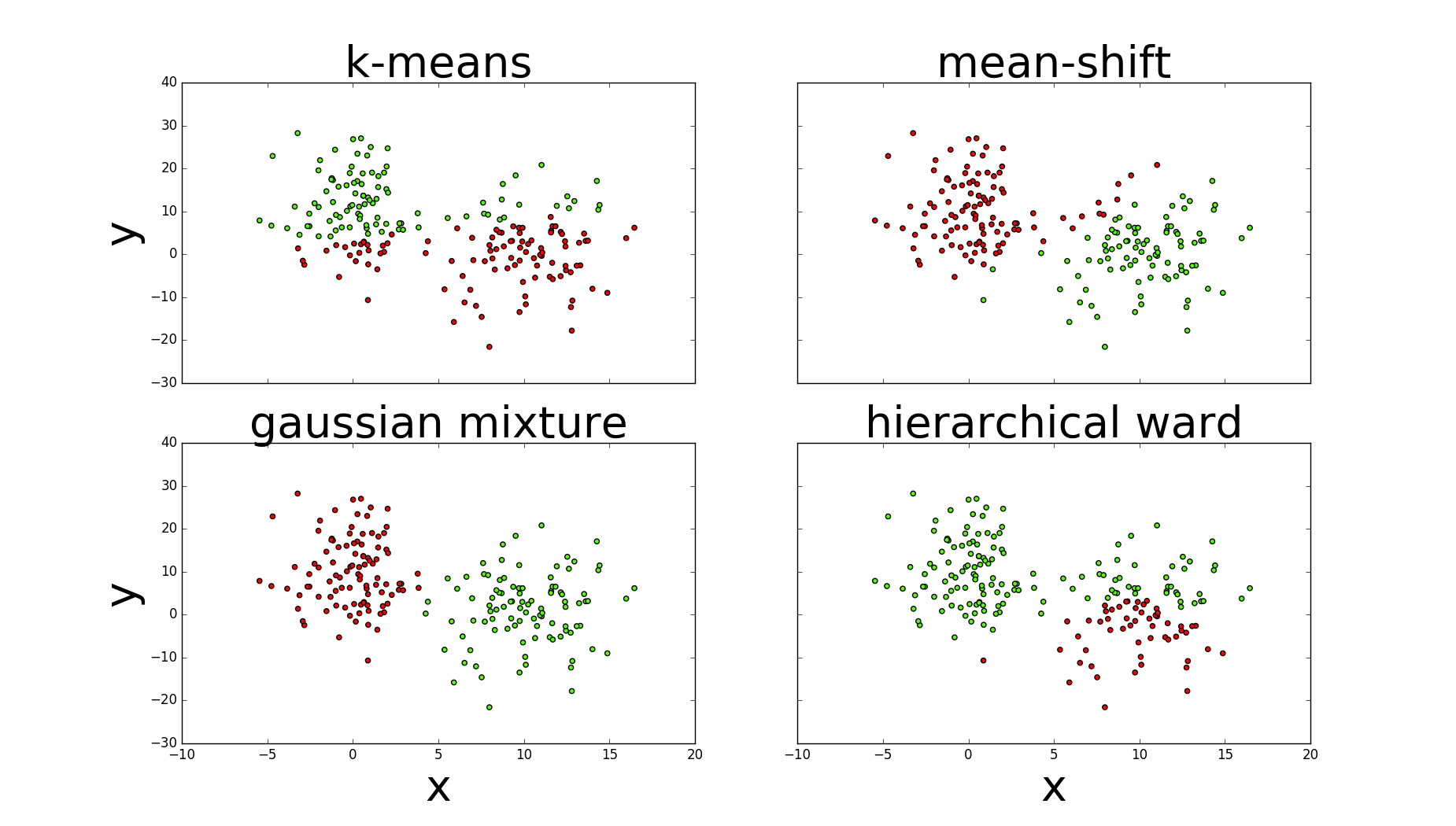
1.kmeans与高斯需要指定簇的数量(n_clusters=2,n_components=2);均值漂移指定带宽(bandwidth=7);层次使用ward链接定义合并代价(距离),终止最大距离max_d。
2.图中可以看出高斯的评估指标最好,其次是均值漂移,k均值与层次较差
四.sklearn聚类
#!/usr/bin/python
# -*- coding: utf-8 -*- import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.cluster import MeanShift
from sklearn.metrics import homogeneity_completeness_v_measure
from sklearn import mixture
from scipy.cluster.hierarchy import linkage
from scipy.cluster.hierarchy import fcluster class ClusterMethod: def __init__(self):
l1=np.zeros(100)
l2=np.ones(100)
self.labels=np.concatenate((l1,l2),) #随机创建两个二维正太分布,形成数据集
def dataProduction(self):
# 随机创建两个二维正太分布,形成数据集
np.random.seed(4711)
c1 = np.random.multivariate_normal([10, 0], [[3, 1], [1, 4]], size=[100, ])
l1 = np.zeros(100)
l2 = np.ones(100)
# 一个100行的服从正态分布的二维数组
c2 = np.random.multivariate_normal([0, 10], [[3, 1], [1, 4]], size=[100, ])
# 加上一些噪音
np.random.seed(1)
noise1x = np.random.normal(0, 2, 100)
noise1y = np.random.normal(0, 8, 100)
noise2 = np.random.normal(0, 8, 100)
c1[:, 0] += noise1x # 第0列加入噪音数据
c1[:, 1] += noise1y
c2[:, 1] += noise2 # 定义绘图
self.fig = plt.figure(figsize=(20, 15))
# 添加子图,返回Axes实例,参数:子图总行数,子图总列数,子图位置
ax = self.fig.add_subplot(111)
# x轴
ax.set_xlabel('x', fontsize=30)
# y轴
ax.set_ylabel('y', fontsize=30)
# 标题
self.fig.suptitle('classes', fontsize=30)
# 连接
labels = np.concatenate((l1, l2), )
X = np.concatenate((c1, c2), )
# 散点图
pp1 = ax.scatter(c1[:, 0], c1[:, 1], cmap='prism', s=50, color='r')
pp2 = ax.scatter(c2[:, 0], c2[:, 1], cmap='prism', s=50, color='g')
ax.legend((pp1, pp2), ('class 1', 'class 2'), fontsize=35)
self.fig.savefig('scatter.png')
return X def clusterMethods(self):
X=self.dataProduction()
self.fig.clf()#reset plt
self.fig,((axis1,axis2),(axis3,axis4))=plt.subplots(2,2,sharex='col',sharey='row')#函数返回一个figure图像和一个子图ax的array列表 #k-means
self.kMeans(X,axis1)
#mean-shift
self.meanShift(X,axis2)
#gaussianMix
self.gaussianMix(X,axis3)
#hierarchicalWard
self.hierarchicalWard(X,axis4) def kMeans(self,X,axis1):
kmeans=KMeans(n_clusters=2)#聚类个数
kmeans.fit(X)#训练
pred_kmeans=kmeans.labels_#每个样本所属的类
print('kmeans:',np.unique(kmeans.labels_))
print('kmeans:',homogeneity_completeness_v_measure(self.labels,pred_kmeans))#评估方法,同质性,完整性,两者的调和平均
#plt.scatter(X[:,0],X[:,1],c=kmeans.labels_,cmap='prism')
axis1.scatter(X[:,0],X[:,1],c=kmeans.labels_,cmap='prism')
axis1.set_ylabel('y',fontsize=40)
axis1.set_title('k-means',fontsize=40)
#plt.show() def meanShift(self,X,axis2):
ms=MeanShift(bandwidth=7)#带宽
ms.fit(X)
pred_ms=ms.labels_
axis2.scatter(X[:,0],X[:,1],c=pred_ms,cmap='prism')
axis2.set_title('mean-shift',fontsize=40)
print('mean-shift:',np.unique(ms.labels_))
print('mean-shift:',homogeneity_completeness_v_measure(self.labels,pred_ms)) def gaussianMix(self,X,axis3):
gmm=mixture.GMM(n_components=2)
gmm.fit(X)
pred_gmm=gmm.predict(X)
axis3.scatter(X[:, 0], X[:, 1], c=pred_gmm, cmap='prism')
axis3.set_xlabel('x', fontsize=40)
axis3.set_ylabel('y', fontsize=40)
axis3.set_title('gaussian mixture', fontsize=40)
print('gmm:',np.unique(pred_gmm))
print('gmm:',homogeneity_completeness_v_measure(self.labels,pred_gmm)) def hierarchicalWard(self,X,axis4):
ward=linkage(X,'ward')#训练
max_d=110#终止层次算法最大的连接距离
pred_h=fcluster(ward,max_d,criterion='distance')#预测属于哪个类
axis4.scatter(X[:,0], X[:,1], c=pred_h, cmap='prism')
axis4.set_xlabel('x',fontsize=40)
axis4.set_title('hierarchical ward',fontsize=40)
print('ward:',np.unique(pred_h))
print('ward:',homogeneity_completeness_v_measure(self.labels,pred_h)) self.fig.set_size_inches(18.5,10.5)
self.fig.savefig('comp_clustering.png',dpi=100)#保存图 if __name__=='__main__':
cluster=ClusterMethod()
cluster.clusterMethods()
五.评估图
参考:1.Machine.Learning.An.Algorithmic.Perspective.2nd.Edition.
2.Machine Learning for the Web
学习sklearn聚类使用的更多相关文章
- 用scikit-learn学习DBSCAN聚类
在DBSCAN密度聚类算法中,我们对DBSCAN聚类算法的原理做了总结,本文就对如何用scikit-learn来学习DBSCAN聚类做一个总结,重点讲述参数的意义和需要调参的参数. 1. scikit ...
- 用scikit-learn学习K-Means聚类
在K-Means聚类算法原理中,我们对K-Means的原理做了总结,本文我们就来讨论用scikit-learn来学习K-Means聚类.重点讲述如何选择合适的k值. 1. K-Means类概述 在sc ...
- sklearn聚类模型:基于密度的DBSCAN;基于混合高斯模型的GMM
1 sklearn聚类方法详解 2 对比不同聚类算法在不同数据集上的表现 3 用scikit-learn学习K-Means聚类 4 用scikit-learn学习DBSCAN聚类 (基于密度的聚类) ...
- ArcGIS案例学习笔记-聚类点的空间统计特征
ArcGIS案例学习笔记-聚类点的空间统计特征 联系方式:谢老师,135-4855-4328,xiexiaokui@qq.com 目的:对于聚集点,根据分组字段case field,计算空间统计特征 ...
- 用scikit-learn学习BIRCH聚类
在BIRCH聚类算法原理中,我们对BIRCH聚类算法的原理做了总结,本文就对scikit-learn中BIRCH算法的使用做一个总结. 1. scikit-learn之BIRCH类 在scikit-l ...
- 用scikit-learn学习谱聚类
在谱聚类(spectral clustering)原理总结中,我们对谱聚类的原理做了总结.这里我们就对scikit-learn中谱聚类的使用做一个总结. 1. scikit-learn谱聚类概述 在s ...
- 机器学习之sklearn——聚类
生成数据集方法:sklearn.datasets.make_blobs(n_samples,n_featurs,centers)可以生成数据集,n_samples表示个数,n_features表示特征 ...
- sklearn聚类评价指标
sklearn中的指标都在sklearn.metric包下,与聚类相关的指标都在sklearn.metric.cluster包下,聚类相关的指标分为两类:有监督指标和无监督指标,这两类指标分别在skl ...
- 零基础学习Kmeans聚类算法的原理与实现过程
内容导入: 聚类是无监督学习的典型例子,聚类也能为企业运营中也发挥者巨大的作用,比如我们可以利用聚类对目标用户进行群体分类,把目标群体划分成几个具有明显特征区别的细分群体,从而可以在运营活动中为这些细 ...
随机推荐
- ABC136E Max GCD
Thinking about different ways of thinking. --- LzyRapx 题目 思路比较容易想到. Observations: 每次操作过后和不变. 枚举和的因子 ...
- 实现一台Linux电脑连接另一台Linux(SSH实现linux之间的免密码登陆)
怎么实现一台Linux电脑连接另一台Linux电脑? 首先查看是否安装ssh服务:systemctl status sshd.service 启动服务:systemctl start sshd.ser ...
- 怎么快速写好看的手机menu菜单
要达到这样的效果: <div class="menu"> <div class="menu-1"> <img alt=" ...
- cf 1163D Mysterious Code (字符串, dp)
大意: 给定字符串$C$, 只含小写字母和'*', '*'表示可以替换为任意小写字母, 再给定字符串$S,T$, 求$S$在$C$中出现次数-$T$在$C$中出现次数最大值. 设$dp[i][j][k ...
- centos配置mutt和msmtp发送邮件
一.安装mutt yum install mutt -y 二.配置mutt vim /etc/Muttrc 在里面找到下面几行,并将内容修改为你自己的内容(下面几行分布在不同位置,请耐心查找,记得去掉 ...
- O003、准备 KVM 实验环境
参考https://www.cnblogs.com/CloudMan6/p/5240770.html KVM 是 OpenStack 使用的最广泛的Hypervisor,本节介绍如何搭建 KVM ...
- Vue中,过滤器的使用方法!
Vue.js允许自定义过滤器,可被用于一些常见的文本格式化.过滤器可以用在两个地方:双花括号插值和v-bind表达式.过滤器应该被添加在JavaScript表达式的尾部,由“管道”符号指示:(借官方的 ...
- 本地存储cookie,localStorage,sessionStorage
常见的前端存储有老朋友 cookie,短暂的 sessionStorage,和简单强大的localStorage 他们之间的区别有以下几点 1.. cookie在浏览器和服务器间来回传递.而sessi ...
- 记一次启动Tomcat 控制台以及log4j 乱码问题
Tomcat启动乱码 问题描述:当你发现你的Tomcat启动时乱码了,而你只是换了个Tomcat版本而已. 在找到真正的问题之前,我在网上百度了N多的资料,都试过了,但是都不行.1.修改了 windo ...
- python动态添加属性
class A: def __init__(self, info ={}): self.info = info def __getattr__(self, item): return self.inf ...