【CDN+】 Spark入门---Handoop 中的MapReduce计算模型
前言
项目中运用了Spark进行Kafka集群下面的数据消费,本文作为一个Spark入门文章/笔记,介绍下Spark基本概念以及MapReduce模型
Spark的基本概念:
官网: http://spark.apache.org/ 给出了如下概念
Apache Spark™ is a unified analytics engine for large-scale data processing.
Apache Spark™是用于大规模数据处理的统一分析引擎。当然,它也适用于AI人工智能。
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark有如下优势:
- Spark提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理的需求
- 官方资料介绍Spark可以将Hadoop集群中的应用在内存中的运行速度提升100倍,甚至能够将应用在磁盘上的运行速度提升10倍
思考:
1. Spark 是一个开源的大数据处理框架,它比MapReduce 更高效。
2. Spark 是基于内存进行计算的,那势必会遇到OOM问题,以及超大数据无法处理的情况,所有一般项目应该会Spark+MapReduce混合使用。
3. 那么核心来了,要了解Spark 势必要认识Handoop 中的MapReduce计算模型,并进行比较。
Handoop 与MapReduce
首先让我们来重温一下 hadoop 的四大组件:
HDFS: Hadoop Distributed File System 分布式存储系统
MapReduce:分布式计算系统 (MapReduce2.X版本会基于YARN框架进行优化)
YARN: hadoop 的资源调度系统
Common: 以上三大组件的底层支撑组件,主要提供基础工具包和 RPC 框架等
Mapreduce 是一个分布式运算程序的编程框架,是用户开发“基于 hadoop 的数据分析 应用”的核心框架
Mapreduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的 分布式运算程序,并发运行在一个 hadoop 集群上
下图可以说明mapreduce的详细计算过程:
input(默认是HDFS,Hadoop Distributed File System) ---splitting(数据分裂) ---mapping(数据按规则映射)---shuffling(数据混洗)---reducing(数据归纳) ---final result (数据合并结果)
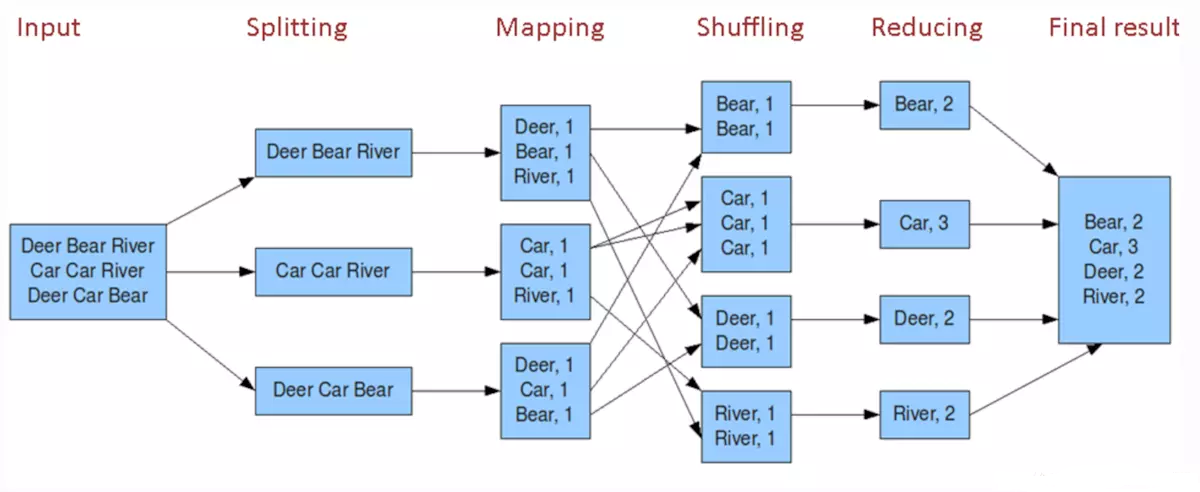
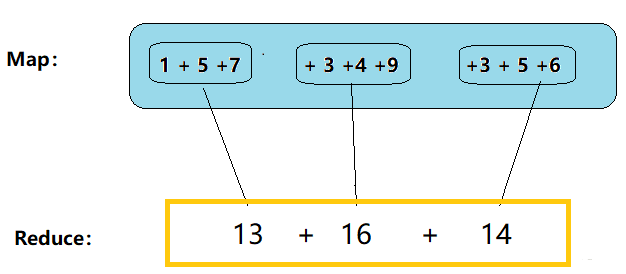
其实可以简单的理解MapReduce ,它只有两步: map + reduce
代码实现Map 与Reduce
1. Map
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* Description: Mapper<br/>
* Copyright (c) , 2018, xlj <br/>
* This program is protected by copyright laws. <br/>
* @version : 1.0
*
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* 4个泛型,前两个是指定mapper端输入数据的类型,为什么呢,mapper和reducer都一样
* 拿数据,输出数据都是以<key,value>的形式进行的--那么key,value都分别有一个数据类型
* KEYIN:输入的key的类型
* VALUEIN:输入的value的类型
* KEYOUT:输出的key的数据类型
* VALUEOUT:输出的value的数据累心
* map reduce的数据输入输出都是以key,value对封装的
* 至于输入的key,value形式我们是不能控制的,是框架传给我们的,
* 框架传给我们是什么类型,我们这里就写什么数据类型
*
* 默认情况下框架传给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,
* 因为我们的框架是读一行就调用一次我们的偏移量
* 那么就把一行的起始偏移量作为key,这一行的内容作为value
*
* 那么输出端的数据类型是什么,由于我们输出的数<hello,1>
* 那么它们的数据类型就显而易见了
* 初步定义为:
* Mapper<Long, String, String, int>
* 但是不管是Long还是String,在MapReduce里面运行的时候,这个数据读到网络里面进行传递
* 即各个节点之间会进行传递,那么要在网络里面传输,那么就意味着这个数据得序列化
* Long、String对象,内存对象走网络都得序列化,Long、String,int序列化
* 如果自己实现Serializable接口,那么附加的信息太多了
* hadoop实现了自己的一套序列化机制
* 所以就不要用Java里面的数据类型了,而是用它自己的封装一套数据类型
* 这样就有助于提高效率,实现了自己的序列化接口
* 在序列化传输的 时候走的就是自己的序列化方法来传递,少了很多负载信息,传递数据精简,
* Long---LongWritable
* String也有自己的封装-Text
* int--IntWritable
*/
public class DemoMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// MapReduce框架每读一次数据,就会调用一次该方法
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法参数中
//key--这一行数据的其实偏移量 value--这一行数据的文本内容
//1.先把单词拿出来,拿到一行
String line = value.toString();
//2.切分单词,这个是按照特定的分隔符 进行切分
String [] words = line.split(" ");
//3.把里面的单词发送出去
/*
* 怎么发出去呢?我都不知道reduce在哪里运行
* 其实呢,这个不用我们关心
* 你只要把你的东西给那个工具就可以了
* 剩下的就给那个框架去做
* 那个工具在哪-----context
* 它把那个工具放到那个context里面去了,即输出的工具
* 所以你只要输出到context里面就行了
* 剩下的具体往哪里走,是context的事情
*/
//遍历单词数组,输出为<K,V>形式 key是单词,value是1
for (String word : words) {
//记得把key和value继续封装起来,即下面
context.write(new Text(word), new IntWritable(1));
}
/*
* map方法的执行频率:每读一行就调一次
* 最后到reduce 的时候,应该是把某个单词里面所有的1都到,才能处理
* 而且中间有一个缓存的过程,因为每个map的处理速度都不会完全一致
* 等那个单词所有的1都到齐了才传给reduce
*/
//每一组key,value都全了,才会去调用一次reduce,reduce直接去处理valuelist
//接着就是写Reduce逻辑了 }
}
2. Reduce
import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; /**
* Description: Reducer<br/>
* Copyright (c) , 2018, xlj <br/>
* This program is protected by copyright laws. <br/>
* @version : 1.0
*/
/*
* 四个泛型的类型记得要对应
*/
public class DemoReducer extends Reducer<Text, IntWritable, Text, Text> {
//map处理之后,value传过来的是一个value的集合
//框架在map处理完成之后,将所有的KV对保存起来,进行分组,然后传递一个组,调用一次reduce
//相同的key在一个组
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
//遍历valuelist,进行了累加
int count = 0;
for (IntWritable value : values) {
//get()方法就能拿到里面的值
count += value.get();
}
//输出一组(一个单词)的统计结果
//默认输出到HDFS的一个文件上面去,放在HDFS的某个目录下
context.write(key, new Text(count+""));
//但是还差一个描述类:用来描述整个逻辑 /*
* Map,Reducce都是个分散的,那集群运行的时候不知道运行哪些MapReduce
*
* 处理业务逻辑的一个整体,叫做job
* 我们就可以把那个job告诉那个集群,我们此次运行的是哪个job,
* job里面用的哪个作为Mapper,哪个业务作为Reducer,我们得指定
*
* 所以还得写一个类用来描述处理业务逻辑
* 把一个特定的业务处理逻辑叫做一个job(作业),我们就可以把这个job告诉那个集群,
*
*/
}
}
3. 运行Map 与 Reduce
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* Description: 用来描述一个特定的作业<br/>
* Copyright (c) , 2018, xlj <br/>
* This program is protected by copyright laws. <br/>
* 该作业使用哪个类作为逻辑处理的map
* 哪个作为reduce
* 还可以指定该作业要处理的数据所在的路径
* 还可以指定该作业输出的结果放到哪个路径
*
* @version : 1.0
*/ public class DemoRunner {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//首先要描述一个作业,这些信息是挺多的,哪个是map,哪个是reduce,输入输出路径在哪
//一般来说这么多信息,就可以把它封装在一个对象里面,那么这个对象呢就是 ----Job对象
Job job = Job.getInstance(new Configuration()); //job用哪个类作为Mapper 指定输入输出数据类型是什么
job.setMapperClass(DemoMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //job用哪个类作为Reducer 指定数据输入输出类型是什么
job.setReducerClass(DemoReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); //指定原始数据存放在哪里//参数:文件在哪个路径下,这个路径下的所有文件都会去读的
FileInputFormat.setInputPaths(job, new Path("input/data1")); //指定处理结果的数据存放路径
FileOutputFormat.setOutputPath(job, new Path("output1")); //提交
int isok = job.waitForCompletion(true)?0:-1;
System.exit(isok);
}
}
后记:
本文主要是介绍了MapReduce的计算原理,它可以为后续的Spark 理解打下基础。
【CDN+】 Spark入门---Handoop 中的MapReduce计算模型的更多相关文章
- MapReduce计算模型
MapReduce计算模型 MapReduce两个重要角色:JobTracker和TaskTracker. MapReduce Job 每个任务初始化一个Job,没个Job划分为两个阶段:Map和 ...
- MapReduce计算模型的优化
MapReduce 计算模型的优化涉及了方方面面的内容,但是主要集中在两个方面:一是计算性能方面的优化:二是I/O操作方面的优化.这其中,又包含六个方面的内容. 1.任务调度 任务调度是Hadoop中 ...
- MapReduce计算模型二
之前写过关于Hadoop方面的MapReduce框架的文章MapReduce框架Hadoop应用(一) 介绍了MapReduce的模型和Hadoop下的MapReduce框架,此文章将进一步介绍map ...
- MapReduce 计算模型
前言 本文讲解Hadoop中的编程及计算模型MapReduce,并将给出在MapReduce模型下编程的基本套路. 模型架构 在Hadoop中,用于执行计算任务(MapReduce任务)的机器有两个角 ...
- 第四篇:MapReduce计算模型
前言 本文讲解Hadoop中的编程及计算模型MapReduce,并将给出在MapReduce模型下编程的基本套路. 模型架构 在Hadoop中,用于执行计算任务(MapReduce任务)的机器有两个角 ...
- Hadoop/Spark入门学习笔记(完结)
Hadoop基础及演练 ---第1章 初识大数据 大数据是一个概念也是一门技术,是在以Hadoop为代表的大数据平台框架上进行各种数据分析的技术. ---第2章 Hadoop核心HDFS Hadoop ...
- 管道设计CAD系统中重量重心计算
管道设计CAD系统中重量重心计算 eryar@163.com Abstract. 管道设计CAD系统中都有涉及到重量重心计算的功能,这个功能得到的重心数据主要用于托盘式造船时方便根据重心设置吊装配件. ...
- 【MapReduce】二、MapReduce编程模型
通过前面的实例,可以基本了解MapReduce对于少量输入数据是如何工作的,但是MapReduce主要用于面向大规模数据集的并行计算.所以,还需要重点了解MapReduce的并行编程模型和运行机制 ...
- Spark入门实战系列--2.Spark编译与部署(中)--Hadoop编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Hadooop 1.1 搭建环境 1.1.1 安装并设置maven 1. 下载mave ...
随机推荐
- Web前端开发 --》 如何实现页面同时在移动端和pc端的兼容问题
很简单,只需要在html文件中对你引入的css进行一个类似于媒体查询的操作 <!DOCTYPE html> <html lang="en"> <hea ...
- python列表-使用
一.列表用于循环 1.for循环 2. in 和 not in 3.多重赋值
- CentOS7 修复MBR引导
为了达到实验目的,首先破坏MBR引导bootloader 重启系统发现系统进不去了,这正是我们想要的 重启进入系统救援模式,输入以下命令重建MBR引导bootloader 重启,可以正常引导进入系统
- Java中的容器(集合)
1.Java常用容器:List,Set,Map List: 继承了Collection接口(public interface List<E> extends Collection<E ...
- java 多态 (知识点不完整)
1.多态的条件 1.要有继承 2.方法重写 3.父类引用指向子类对象 多态中成员访问 1. 访问成员变量: 编译看左边,运行也看左边 f.num = 10 因为这里是父类的,看是父类Father ...
- 搜索(DFS)---查找最大连通面积
查找最大的连通面积 695. Max Area of Island (Medium) [[0,0,1,0,0,0,0,1,0,0,0,0,0], [0,0,0,0,0,0,0,1,1,1,0,0,0] ...
- 微信jssdk配置的问题,使用MVC制作的demo
一,view代码 <script src="~/Scripts/jquery-3.3.1.js"></script> <script src=&quo ...
- 放弃等待,故障到来:少一个 await 引发的 tcp 连接泄漏故障
更新:后来升级至 .NET Core 2.2 Preview 3 ,并将 System.Net.Http 升级至 4.3.4 之后没出现这个问题,问题与 https://github.com/dotn ...
- Storm简介——实时流式计算介绍
概念 实时流式计算: 大数据环境下,流式数据将作为一种新型的数据类型,这种数据具有连续性.无限性和瞬时性.是实时数据处理所面向的数据类型,对这种流式数据的实时计算就是实时流式计算. 特征 实时流式计算 ...
- python 安装opencv及问题解决
正常安装模式 pip install opencv-python==3.4.5.20 pip install opencv-contrib-python==3.4.5.20 -i http://pyp ...