Django模板层2
一.单表操作
1.1 开启test
from django.test import TestCase
import os
# Create your tests here. if __name__ == "__main__":
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "django_6.settings")
import django
django.setup()
from ap01 import models """
1.一对多的表操作 :即book和publish 首先我们先对书籍的数据进行增 删 改 查 x
2.手动加点和数据相关的数据 方便测试
"""
1.2 增
方法一:
# 1.一对多的表操作 >>>书籍:
# (1)增:添加书籍
# 因为书籍中有个publish字段 可以直接加id 也可以加出版社对象
# 方法一:
# res = models.Book.objects.create(title='聊斋志异',price=88.99,publisher_id=2)
# print(res)
方法二:
# 方法二:
# publish_obj = models.Publish.objects.filter(pk=3).first()
# print(publish_obj.name)
# res = models.Book.objects.create(title='西游记',price=666,publisher=publish_obj)
# print(res)
1.3 查
# 1.all()
book_obj = models.Book.objects.all()
print(book_obj)
# 2 filter()
book_obj = models.Book.objects.filter(id=7).first()
print(book_obj) # Book object
# 3.get()
# get()的方法一般不推荐使用 如果内容不存在则会报错
book_obj = models.Book.objects.get(title='红楼梦')
print(book_obj) # Book object # book_obj = models.Book.objects.get(pk=9)
# print(book_obj.title)
1.4 改
# 1.单表的update
# res = models.Book.objects.filter(id=7).update(price=77.66)
# print(res) # 返回值是1 我也不知道是啥
# 2.对象赋值的方式 all() 和filter() 都是Queryset()对象
# book_obj = models.Book.objects.filter(pk=7).first()
# print(book_obj)
# book_obj.title='花花'
# book_obj.save()
原生:
SELECT
`ap01_book`.`id`,
`ap01_book`.`title`,
`ap01_book`.`price`,
`ap01_book`.`publisher_id`
FROM
`ap01_book`
WHERE
`ap01_book`.`id` = 7
ORDER BY
`ap01_book`.`id` ASC
LIMIT 1;
args = ( 7, ) ( 0.000 ) UPDATE `ap01_book`
SET `title` = '花花',
`price` = '77.66',
`publisher_id` = 2
WHERE
`ap01_book`.`id` = 7;
args = ( '花花', '77.66', 2, 7 )
1.5 删
# 删除数据操作 一般不会用
# models.Book.objects.filter(id=6).delete() # 直接删除数据
二.其他查询方法
13条查询方法
all()
filter()
上面俩个查询到的都是 queryset() 对象
get() # 取值一般不推荐使用 查不到会报错
values() # 列表套字典 返回的是一个Queryset()的对象 内部是封装的字典的格式 value()内部支持传多个参数 key 就是我们自己查的字段 value 就是我们要的值
book_obj = models.Book.objects.values('title','price',)
print(book_obj)
# < QuerySet[
# {'title': '三国演义', 'price': Decimal('199.00')}, {'title': '花花', 'price': Decimal('77.66')},
# {'title': '西游记','666.00')}, {'title': '红楼梦', 'price': Decimal('66.44')}] >
values_list() # 列表套元组
# <QuerySet [('三国演义', Decimal('199.00')), ('花花', Decimal('77.66')),
# ('西游记', Decimal('666.00')), ('红楼梦', Decimal('66.44'))]>
# 返回的也是Query set()对象 里面是列表套元组的形式
first() 和last() 返回的是的我们的对象 first() 是取第一个 我们结合filter(pk).first() 其实内部走的是bject[0]
book_obj = models.Book.objects.first()
book3_obj = models.Book.objects.last()
book2_obj = models.Book.objects.filter(pk=8).first()
print(type(book_obj),book_obj)
print(type(book2_obj),book2_obj)
print(type(book3_obj),book3_obj) args = NONE ( 0.000 ) SELECT
`ap01_book`.`id`,
`ap01_book`.`title`,
`ap01_book`.`price`,
`ap01_book`.`publisher_id`
FROM
`ap01_book`
ORDER BY
`ap01_book`.`id` ASC
LIMIT 1;
args = ( ) SELECT
`ap01_book`.`id`,
`ap01_book`.`title`,
`ap01_book`.`price`,
`ap01_book`.`publisher_id`
FROM
`ap01_book`
WHERE
`ap01_book`.`id` = 8
ORDER BY
`ap01_book`.`id` ASC
LIMIT 1;
args = ( 8, )
(0.001)
<class 'ap01.models.Book'> Book object
<class 'ap01.models.Book'> Book object
<class 'ap01.models.Book'> Book object
count()
# count() 统计某个字段的个数
res = models.Book.objects.count() # 这里是不需要进行参传数的
print(res) # return getattr(self.get_queryset(), name)(*args, **kwargs) 颞部原理是反射
exclude()
res =models.Book.objects.filter(pk=7).exists()
print(res) # is_语句 判断是否包含pk=7的对象 True
distinct()
book_obj = models.Book.objects.values('title','publisher').distinct()
print(book_obj)
注意:这里是先获取vlues('字段1',‘字段2‘,’字段3‘) 。distinct()是根据我们要查的字段必须全部一致 如果里面价格’id‘ id 肯定不一样不能实现去除功能
order_by()
print(models.Book.objects.order_by('price')) # 默认是升序
exists() # 判断是否存在
reverse() #
print(models.Book.objects.order_by('price').reverse()) # 先进性排序再将结果进行反序
三。神奇的双下划线
1. 书籍名称中包含
# title__contains = 'p'
# title__icontains = 'p' # 这个忽略打大小写的 也即是P p 是查询只能其中一个匹配一个结果
book_list = models.Book.objects.filter(title__contains='西游')
print(book_list)
原生SQL 语句既是模糊匹配
SELECT `ap01_book`.`id`, `ap01_book`.`title`, `ap01_book`.`price`, `ap01_book`.`publisher_id` FROM `ap01_book` WHERE `ap01_book`.`title` LIKE '%西游%' LIMIT 21; args=('%西游%',)
补充:
关键字:like 是模糊匹配 %西游% 只要有就给你进行筛选出来
% 匹配任意一个 %三 》》》 以上三结尾的所有结果 三% 以三开头的任意字符 %三% 含有三的任意字符
— 只匹配一个字符
2.查询书籍价格大于199 或等于199 书籍对象
print(models.Book.objects.filter(price__gt=199)) # 大于 price 是我们当前的字段
print(models.Book.objects.filter(price__gte=199)) # 大于等于
print(models.Book.objects.filter(price__lt=199)) # 大于等于
print(models.Book.objects.filter(price__lte=199)) # 大于等于
# 原生SQL语句
SELECT
`ap01_book`.`id`,
`ap01_book`.`title`,
`ap01_book`.`price`,
`ap01_book`.`publisher_id`
FROM
`ap01_book`
WHERE
`ap01_book`.`price` <= 199
LIMIT 21;
args = ( DECIMAL ( '199' ), )
3.in 和range
print(models.Book.objects.filter(price__in=(666,199)))
# <QuerySet [<Book: 三国演义>, <Book: 西游记>, <Book: 西游记>]>
# price——in【】 () 容器范围内 SELECT
`ap01_book`.`id`,
`ap01_book`.`title`,
`ap01_book`.`price`,
`ap01_book`.`publisher_id`
FROM
`ap01_book`
WHERE
`ap01_book`.`price` IN ( 666, 199 )
LIMIT 21;
args = ( DECIMAL ( '' ), DECIMAL ( '' ) )
3.price__range() # between 100 and 400
print(models.Book.objects.filter(price__range=(66,199))) # <QuerySet [<Book: 三国演义>, <Book: 西游记>, <Book: 西游记>]>
SELECT
`ap01_book`.`id`,
`ap01_book`.`title`,
`ap01_book`.`price`,
`ap01_book`.`publisher_id`
FROM
`ap01_book`
WHERE
`ap01_book`.`price` BETWEEN 66
AND 199
LIMIT 21;
args = ( DECIMAL ( '' ), DECIMAL ( '' ) )
4.按年份查询
# # 按年查询
# filter(publish_date__year='2019')
user_obj = models.Publish.objects.filter(publish_date__year='2019').all()
user_obj = models.Publish.objects.filter(publish_date__year='2019').all() >>all() 是Queryset() 对象
print(book_obj )
<QuerySet [<Publish: Publish object>, <Publish: Publish object>, <Publish: Publish object>]>
原生SQL
SELECT
`ap01_publish`.`id`,
`ap01_publish`.`name`,
`ap01_publish`.`publish_date`
FROM
`ap01_publish`
WHERE
`ap01_publish`.`publish_date` BETWEEN '2019-01-01'
AND '2019-12-31'
LIMIT 21;
args = ( '2019-01-01', '2019-12-31' ) 按月份查询
user_obj = models.Publish.objects.filter(publish_date__month='8').first()
print(user_obj.publish_date)
四.多表操作
外键字段增删改查
1.一对多 》》》 书籍表和出版社表 外键建立在我们的书籍表中
添加2个作者到我们的书籍id=7 的数据表中

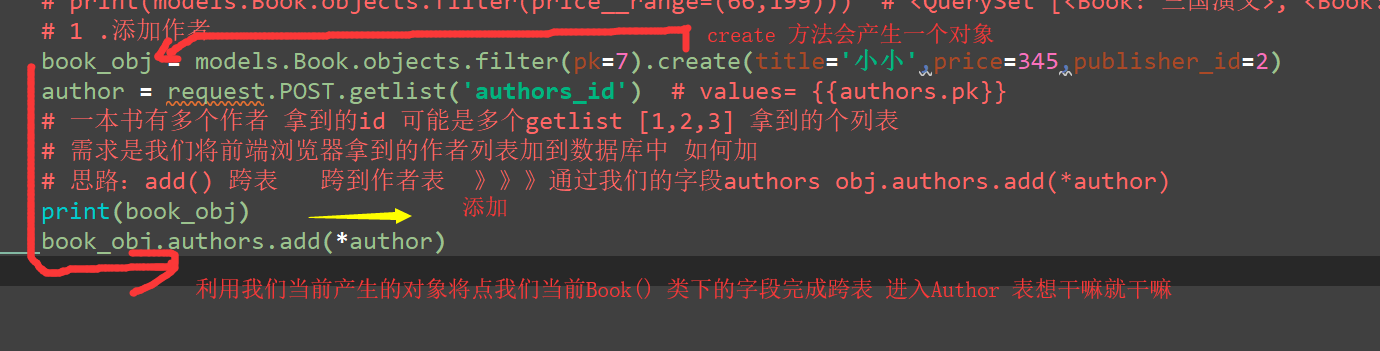
4.1 正向:判断是否查询的结果在我们当前第一条件是否有我们要查的条件 若有就是
# 7.查询书籍id为1 的作者的电话号码
# 思路:正向按字段 反向按表名小写 》》》1.反向规律:如果查询的结果是多 则需要book_set().all()
#
# 1/一看作者的电话号码咱们的这个字段没有啊 那么他和那张表直接关联
# 2/巧了正好我们Book下的author 在我们的表 book_obj.author__
# 反向表名(要查的收机号码在详情表中)小写
book_obj = models.Book.objects.filter(pk=7).first()
# print(book_obj)
author_list = book_obj.authors.all() # 一对多 拿到这本数的所有作者
for auth_obj in author_list:
print(auth_obj.author_detail.phone)
4.2 反向:
# 4.查询出版社 是 东方出版社出版的所有书籍
# 思路:1 出版社 书籍
# 方法一:反向 # publish_obj = models.Publish.objects.filter(name='东方出版社').first()
# print(publish_obj)
# print(publish_obj.book_set.all())
2.多对多:
增:
1.models.Book.objects.create(username='koko',password='123')
2.user_obj = modelsBook(usename='koko',password='123')
user_obj.save()
add() :添加多个:给某个字段添加多个值的时候
给闪过演义的书添加3个作者
book_obj = modles.Book.object.filter(title='三国演义').firest()
通过对象点方法实现 >>> 给那个表加 正向字段 反向 表名小写
book_obj.authors.add(1,2,3) >>> 注意:参数可以是单个数字或单个对象 也可以是多个数字pk 或作者对象
3.set():修改基于已经有得数据进行修改
将三国演义这本书的作者改为4,6
book_obj = modles.Book.objecet.filter(title='三国演义').first()
book_obj.authors.set([1,2]) >>>注意了:这里参数必须是迭代对象 可以单个或多个数字 单个对象或者多个对象
4.remove()
book_obj = modles.Book.objecet.filter(title='三国演义').first()
# 删除书籍是小小的作家
# 方法一:
book_obj = models.Book.objects.filter(title='小小').first()
book_obj.atuhors.remove(1,2) # 参数里面是单个数字和对象 多个数字一般是要删除pk 值不是迭代的容器 和add() 用法一样
#方法二:
author_obj = models.Author.objects.filter(pk=1).first()
book_obj.authors.remove(author_obj)
5.clear()
book_obj = models.Book.objects.filter(pk=14).first()
book_obj.authors.clear() >>> 不需要进行传参数
正向 和反向 多的book_set.all(_)
# 查询书籍id=7的有作者的姓名
book_obj = models.Book.objects.filter(pk=7).first()
print(book_obj.authors.all())
3.一对一
# # 一对一
# 查询作者是koko的家庭住址
# 方法一:正向
# 思路:1.判断是反向还是正向查询 我们条件当前类下 是否有 需要查的类的字段 有>>> 正向(字段) 没有>>>反向(表名小写)
# 2.获取对象
# 3.对象点要查结果的字段.name addr
au_obj = models.Author.objects.filter(name='koko').first() # 只要是Queryset 对象就可以无限的点
print(au_obj.author_detail.addr) # auth_obj = models.Author.objects.filter(name='koko').first()
# print(auth_obj)
# print(auth_obj.author_detail.addr)
五.跨表查询
总结: 总体来说就这两种
1 >>>>基于book_obj 跨表查询
2 >>>>基于authors__name >>> values(authors__name) 返回的是一个列表套字典的对象
一对一双下划线查询
正向:正向按字段 按字段,跨表可以在filter,也可以在values中
反向:按表名小写 >>>按表名小写,跨表可以在filter,也可以在values中 结果是多的话book_set 加上_set.all()
"""基于双下划綫的跨表查询(连表操作)
eft join
inner join
right join
union
"""
# 正向
# 1.查询j查询书籍id的 所有作者的手机号
book_obj = models.Book.objects.filter(pk=7).values('authors__name','authors__author_detail__phone')
print(book_obj)
"""只要表里面有外键字段 你就可以无限制跨多张表""" 最后————phone 普通字段取值
<QuerySet [{'authors__name': 'jason', 'authors__author_detail__phone': 132}, {'authors__name': 'tank', 'authors__author_detail__phone': 133}]>
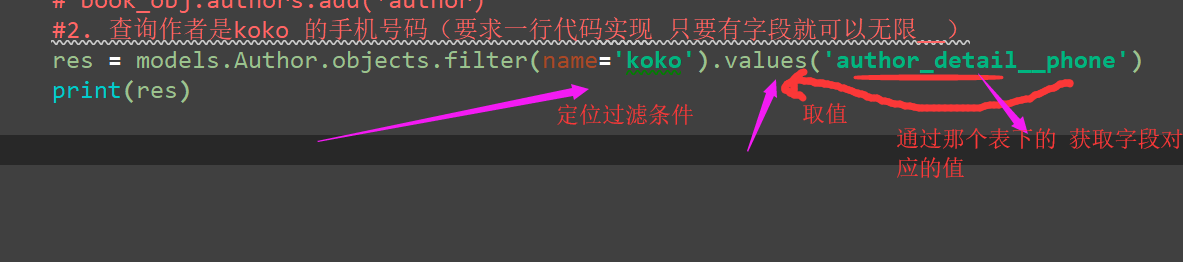
2。查看koko作者的收机号码
#2. 查询作者是koko 的手机号码(要求一行代码实现 只要有字段就可以无限__)
res = models.Author.objects.filter(name='koko').values('author_detail__phone')
print(res)
# 3 # 查询jason这个作者的年龄和手机号
# 需求:反向查大前提 》》》 正向按自段 反向按表名小写
print(models.Authordetail.objects.filter(author__name='koko').values('author__age','phone'))

# 1.查询书籍id是1 的作者的电话号码 一行代码解决
# 正向
print(models.Book.objects.filter(pk=6).values('authors__author_detail__phone'))

# 2.查询北方出版社出版的价格大于19的书 >>>正向

作业 ```python
"""
1 单表查询:
1 查询南方出版社出版社出版过的价格大于200的书籍
2 查询2017年8月出版的所有以py开头的书籍名称
3 查询价格为50,100或者150的所有书籍名称及其出版社名称
4 查询价格在100到200之间的所有书籍名称及其价格
5 查询所有人民出版社出版的书籍的价格(从高到低排序,去重)
"""
```
六.聚合查询
1.聚合(利用聚合函数)
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。
键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。
需要导模块:
from django.db.models import Sum,Max,Min,Avg,Count
# 1求出版社设南方出版社的书籍的的总价
res = models.Book.objects.filter(publisher__name='南方出版社').aggregate(Sum('price'))
print(res)
原生的SQL语句
SELECT
SUM( `ap01_book`.`price` ) AS `price__sum`
FROM
`ap01_book`
INNER JOIN `ap01_publish` ON ( `ap01_book`.`publisher_id` = `ap01_publish`.`id` )
WHERE
`ap01_publish`.`name` = '南方出版社';
args = ( '南方出版社', )
# 2.需求查询出本社是东方出本社的所有书籍的平均价格
res1 = models.Book.objects.filter(publisher__name='东方出版社').aggregate(Avg('price'))
print(res1) # {'price__avg': 110.626667}
# 2.需求查询出所有书籍的平均价格
res = models.Book.objects.filter().all().aggregate(Avg('price'))
print(res) # {'price__avg': 298.077143}
原生sql语句
SELECT
AVG( `ap01_book`.`price` ) AS `price__avg`
FROM
`ap01_book`
INNER JOIN `ap01_publish` ON ( `ap01_book`.`publisher_id` = `ap01_publish`.`id` )
WHERE
`ap01_publish`.`name` = '东方出版社';
args = ( '东方出版社', ) ( 0.000 ) SELECT
AVG( `ap01_book`.`price` ) AS `price__avg`
FROM
`ap01_book`;
args = ( )
七.分组查询
# 3.查询每个出版设的最高价的书名 最低价格的书名
# MAX
from django.db.models import Sum, Max, Min, Avg, Count
res1 = models.Publish.objects.annotate(max=Max('book__price')).values('name','book__title','book__price')
res2 = models.Publish.objects.annotate(min=Min('book__price')).values('name','book__title','book__price')
print(res1)
print(res2)
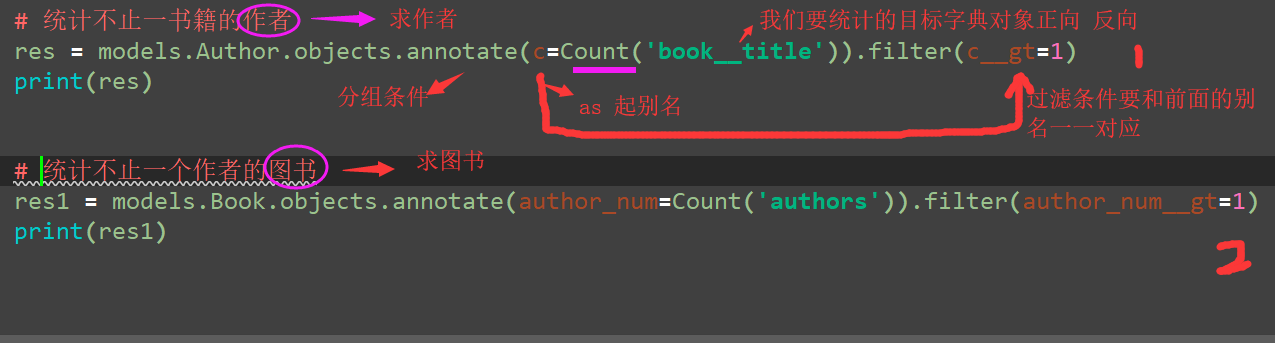
分组查询
# 统计不止一书籍的作者
res = models.Author.objects.annotate(c=Count('book__title')).filter(c__gt=1)
print(res)
# 统计不止一个作者的书籍
res1 = models.Book.objects.annotate(author_num=Count('authors')).filter(author_num__gt=1)
print(res1)
# 查询各个作者出的书的总价格
# 查询各个作者出的书的总价格
res = models.Author.objects.annotate(sp=Sum('book__price')).values('name','sp') print(res)
<QuerySet [{'name': 'koko', 'sp': Decimal('199.00')}, {'name': 'jason', 'sp': Decimal('276.66')}, {'name': 'tank', 'sp': Decimal('276.66')}]>
原生SQL:
SELECT
`ap01_author`.`name`,
SUM( `ap01_book`.`price` ) AS `sp`
FROM
`ap01_author`
LEFT OUTER JOIN `ap01_book_authors` ON ( `ap01_author`.`id` = `ap01_book_authors`.`author_id` )
LEFT OUTER JOIN `ap01_book` ON ( `ap01_book_authors`.`book_id` = `ap01_book`.`id` )
GROUP BY
`ap01_author`.`id`
ORDER BY
NULL
LIMIT 21;
args = ( )
八.F与Q查询
F查询是在们我们获取字段下面的值进行比较时用
# F(查询条件两端都是数据库数据)
# 给书籍表增加卖出和库存字段
# 1.查询出卖出数大于库存数的商品
# F查询的本质就是从数据库中获取某个字段的对应的值
# 查询库存数 大于 卖出数的书籍
"""之前查询等号后面的条件都是我们认为输入的
现在变成了需要从数据库中获取数据放在等号后面
"""
from django.db.models import F
res = models.Book.objects.filter(stock__gt=F('sale'))
print(res)
#将 库存数 加1000
# 将书籍库存数全部增加1000 新增就是update 更新
models.Book.objects.update(stock=F('stock')+1000)

# 把所有书名后面加上'新款'
# from django.db.models.functions import Concat
# from django.db.models import Value
# ret3 = models.Book.objects.update(title=Concat(F('title'), Value('新款')))
# Q(filter里面条件都是与,Q支持与或非)
# 查询书籍名称是三国演义或者价格是69 得结果
from django.db.models import Q
"""
class Q(tree.Node):
"""
"""
Encapsulates filters as objects that can then be combined logically (using
`&` and `|`).
"""
"""
# Connection types
AND = 'AND'
OR = 'OR'
default = AND 默认是and 同时满足得并列关系
"""
# 因为数据的filter 等条件是,and 关系 但是想要或| 是必须得通过Q类方法进行操作得>>>
# 查询书籍名称是三国演义或者价格是444.44
res = models.Book.objects.filter(Q(title='三国演义')|Q(price=69))
print(res)
# 1.查询 卖出数大于100 或者 价格小于100块的
# 2.查询 库存数是100 并且 卖出数不是0 的产品
# 3.查询 产品名包含新款, 并且库存数大于60的
```
九.Q的高级用用法
# Q的高级用法
# 先产生一个校q
q = Q() # 类对像
# 默认还是and 可以通过connection = 'or' 改为或 # q.children.append(('title__contains','三国演义')) # TypeError: append() takes exactly one argument (2 given) q.children.append(('price__gt',200)) # 往列表中添加筛选条件 res = models.Book.objects.filter(q) # filter支持你直接传q对象 但是默认还是and关系 print(res)

Django模板层2的更多相关文章
- Django模板层学习笔记
一. 前言 Django模板层的知识包括标签.过滤器.自定义标签.自定义过滤器以及inclusion_tag,最重要的是模板的继承和导入. 首先模板层最重要的是模板语法,之前我们提过涉及到变量用模板语 ...
- django——模板层
每一个Web框架都需要一种很便利的方法用于动态生成HTML页面. 最常见的做法是使用模板. 模板包含所需HTML页面的静态部分,以及一些特殊的模版语法,用于将动态内容插入静态部分. 说白了,模板层就是 ...
- Django模板层
一:模板简介 二:模板语法值变量 三: 模板之过滤器 四: 模板之标签 五:自定义标签和过滤器 一:模板简介 def current_datetime(request): now=datetime ...
- Django——模板层(template)(模板语法、自定义模板过滤器及标签、模板继承)
前言:当我们想在页面上给客户端返回一个当前时间,一些初学者可能会很自然的想到用占位符,字符串拼接来达到我们想要的效果,但是这样做会有一个问题,HTML被直接硬编码在 Python代码之中. 1 2 3 ...
- Django模板层之templates
一 模版简介 你可能已经注意到我们在例子视图中返回文本的方式有点特别. 也就是说,HTML被直接硬编码在 Python代码之中. def current_datetime(request): now ...
- $Django 模板层(模板导入,继承)、 单表*详(增删改查,基于双下划线的查询)、static之静态文件配置
0在python脚本中使用django环境 import osif __name__ == '__main__': os.environ.setdefault("DJANGO_SETT ...
- $Django 模板层(变量、过滤器 、标签)、自定义(模板过滤器,标签)
1 模版语法之变量:详见源码 -{{ 变量 }}:******重要******{#相当于print了该变量#} {#只写函数名 相当于()执行了#}<p>函数:{{ test }}< ...
- django模板层(templates)
1.基础部分 通过使用模板,就可以在URL中直接调用HTML,它还是松耦合的,灵活性强,而且更容易维护 而且可以将变量通过一定的方式嵌入到HTML中,最终渲染到页面,总的来说基于模板完成了数据与用户之 ...
- django模板层之静态文件引入优化
1.新手使用 我们一般在初学django的情况下,引入django的静态文件一般有如下两种方式: 通过路径引用: <script type="text/javascript" ...
随机推荐
- HTTP深入浅出http请求(转)-----http请求的过程和实现机制
摘要:此文章大概讲明了http请求的过程和实现机制,可以作为了解,至于请求头和响应头的具体信息需要查看下一篇随笔:Http请求详解(转)----请求+响应各字段详解 HTTP(HyperText ...
- [BZOJ4010]:[HNOI2015]菜肴制作(拓扑排序)
题目传送门 题目描述 知名美食家小A被邀请至ATM大酒店,为其品评菜肴. ATM酒店为小A准备了N道菜肴,酒店按照为菜肴预估的质量从高到低给予1到N的顺序编号,预估质量最高的菜肴编号为1.由于菜肴之间 ...
- c++11多线程---线程操作
1.等待线程执行完成 join() 方法数会阻塞主线程直到目标线程调用完毕,即join会直接执行该子线程的函数体部分. 2.暂停线程(线程休眠) 使用std::this_thread::sleep_f ...
- iOS应用将强制使用HTTPS安全加密-afn配置https(190926更新)
WWDC 2016苹果开发者大会上,苹果在讲解全新的iOS10中提到了数据安全这一方面,并且苹果宣布iOS应用将从2017年1月起启用名为App Transport Security的安全传输功能. ...
- 如何将EDM数据分类工作做的更加真善美
众所周知,数据是互联网时代营销的决定性因素,数据的好坏关乎到营销能力的强弱,而细化到EDM行业中,数据细分变得极为重要,根据数据形态的不同,将会涉及到多种不同的细分方法,有效的利用这些方法,将会大大的 ...
- Eureka服务注册与发现-提供消费服务模型
1.工具及软件版本 JDK1.8 Spring Boot 1.4.3.RELEASE <parent> <groupId>org.springframework.boot< ...
- 安装ssh
1.win10 安装ssh sudo apt-get remove --purge openssh-server ## 先删ssh sudo apt-get install openssh-serve ...
- vue路由高级用法
五.路由设置高级用法alias 别名 {path:'/list',component:MyList,alias:'/lists'}redirect 重定向 {path:'/productList',r ...
- vue 格式化时间的插件库
格式化时间的插件库 点击进入 moment.js网址 ,在这里可以找到需要引入的script标签 点击进入 moment.js的文档 在文档中可以找到对应的格式和例子 此文来源于: https://w ...
- Java数据结构之栈(Stack)
1.栈(Stack)的介绍 栈是一个先入后出(FILO:First In Last Out)的有序列表. 栈(Stack)是限制线性表中元素的插入和删除只能在同一端进行的一种特殊线性表. 允许插入和删 ...