5G网络的深度强化学习:联合波束成形,功率控制和干扰协调
摘要:第五代无线通信(5G)支持大幅增加流量和数据速率,并提高语音呼叫的可靠性。在5G无线网络中共同优化波束成形,功率控制和干扰协调以增强最终用户的通信性能是一项重大挑战。在本文中,我们制定波束形成,功率控制和干扰协调的联合设计,以最大化信号干扰加噪声比(SINR),并使用深度强化学习解决非凸问题。通过利用深度Q学习的贪婪性质来估计行动的未来收益,我们提出了一种用于6 GHz以下频段的语音承载和毫米波(mmWave)频段的数据承载的算法。该算法利用来自连接用户的报告SINR,基站的发射功率以及所连接用户的坐标来改善通过覆盖和测量容量测量的性能。所提出的算法不需要信道状态信息并且不需要信道估计。仿真结果表明,我们的算法优于亚6 GHz语音承载的链路自适应行业标准,并且在真实的蜂窝环境中接近mmWave数据承载的最佳限制。
1 引言
随着第五代无线通信(5G)的推出,流量和数据速率的大幅增长继续发展。 同样发展的是增强的语音通话质量,更好的可靠性和改进的编解码器。 因此,预计未来的无线网络将满足对数据速率和增强的语音质量的巨大需求。 为了学习小区间干扰和波束间干扰的隐含特征,我们提出了一种基于强化学习(RL)框架的在线学习算法。 我们使用此框架来推导近似最优策略以最大化最终用户SINR。 强化学习在功率控制中的重要性已在[1] - [3]中得到证明。 语音承载中的功率控制使其对抗无线损伤(例如衰落)更具鲁棒性。 它还增强了网络的可用性并增加了蜂窝容量。
A.先前的工作
在[4] - [7]中研究了在上行链路和下行链路中执行功率控制和波束成形。 功率控制和波束形成在[7]中使用优化联合求解,但不考虑散射或阴影,这是毫米波(mmWave)传播中的关键现象。
工业标准采用几乎空白子帧(ABS)的方法来解决LTE中的同信道小区间干扰问题,其中两个基站相互干扰[8]。 虽然ABS在固定波束天线方向图中运行良好,但波束形成的动态特性降低了ABS的有用性[9]。
在[2]中研究了用于多输入多输出(MIMO)承载中的链路自适应的在线学习算法。 该算法的计算复杂度与现有的在线学习方法相当,但空间开销最小。 此外,该算法适应于快速改变信道分布。
在[3]中研究了异构网络中的干扰避免。 提出了用于宏和毫微微BS共存的Q学习框架。 建立了这些BS的分散式自组织的可行性,其中减少了毫微微小区对宏BS的干扰。 在[1]中也提出了Q学习的使用。 该框架侧重于多室内环境中的分组语音功率控制。 它利用半持久性调度来建立专用信道的虚拟感知。 该信道实现了下行链路的功率控制,以确保与行业标准相比增强的语音清晰度。
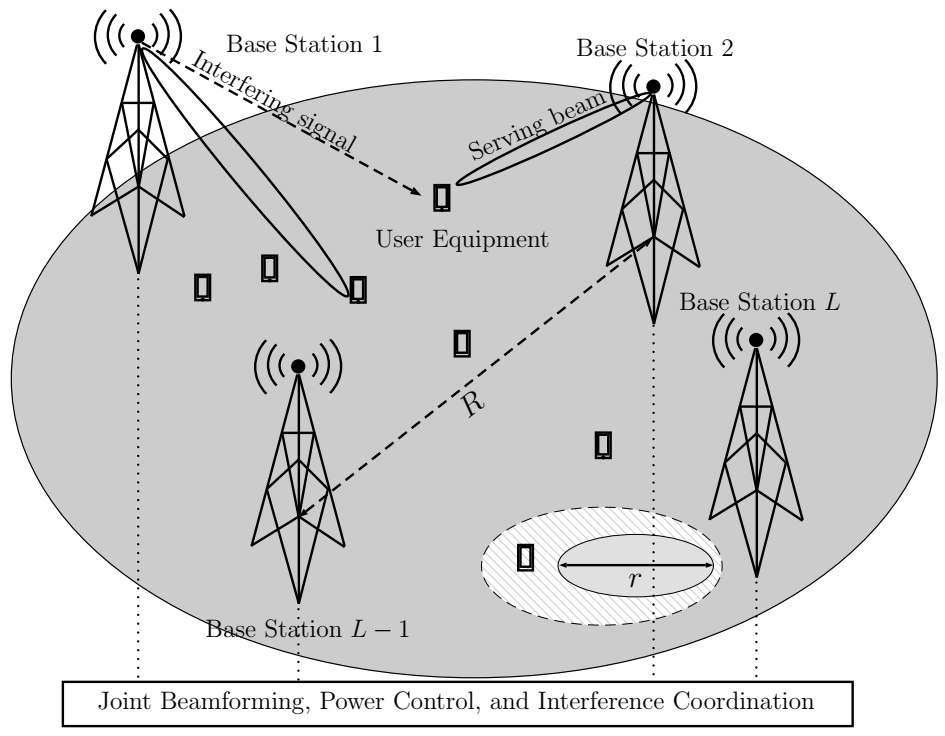
图1.对来自服务基站的信号执行联合波束成形和功率控制,同时协调来自其他BS的干扰。 有L个基站,其站点间距离为R,小区半径为r
在[4]中引入了大规模MIMO中的联合功率控制。 由于参与联合功率控制的BS之间的信道状态信息的有限交换,该方法导致开销减少。 联合功率控制方案导致SINR测量的性能增强。 在上行链路方向上,在[5]中研究了波束形成中的功率控制。 制定优化问题以最大化两个用户的可实现的总和速率,同时确保每个用户的最小速率约束。 使用强化学习来解决上行链路的问题在计算上是昂贵的并且可以导致用户设备(UE)电池的更快耗尽。 另一方面,我们专注于下行链路和干扰消除以及功率控制。
在过去的两年中,在[6],[10] - [12]中研究了无线通信中深度学习的使用。 [6]研究了深度强化学习对mmWave进行功率控制的具体用法。提出这种方法作为改进非视距(NLOS)传输性能的波束形成的替代方案。使用深度强化学习解决了在传输功率和质量目标的约束下最大化UE的总和速率的功率分配问题。在该解决方案中,使用卷积神经网络来估计深度强化学习问题的Q函数。在[10]中,使用深度Q学习获得了使动态相关多信道接入环境中的成功传输最大化的策略。在[11]中提出使用深度卷积神经网络来增强在低SINR下认知无线电中的调制的自动识别。在[12]中研究了能够通过功率控制可靠地阻塞传输的深度学习分类器。
B.动机
采用深度学习的目的:
1)提出的方案不需要信道知识就可以找到SINR最优波束成形矢量。(传统方法(SINR上限性能)通过在码本中搜索所有波束来找到最佳波束成形矢量,以使SINR最大化(这也需要对信道有全面的了解))
2)最小化UE向BS发送反馈中的参与。UE将接收到的SINR和坐标一起发回(使用UE坐标减少报告开销)
3)当涉及多个BS时,用于联合波束成形,功率控制和干扰协调命令的上限SINR性能消息传递的实现复杂性令人望而却步。
4)具有由UE发送给服务和干扰BS的显式PCIC命令需要对当前的行业标准进行修改。
5)为了执行联合波束成形和功率控制,对BS执行的相关动作进行二进制编码。
C.贡献
在本文中,介绍了一种不同的功率控制方法,不仅控制基站(BS)的发射功率,而且还协调干扰基站的发射功率。 这种方法允许我们通过控制干扰来控制SINR,而不是通常控制发射功率电平。 作为这种明显冲突的结果,出现竞争条件,其中给定用户的服务BS是另一用户的干扰BS。 因此,虽然功率控制请求给定BS和给定用户的功率增加,但是干扰协调可以同时请求相同BS的功率降低。 在我们之前的工作[1]中,我们通过改变服务BS发射功率来关注语音用户在下行链路上的功率控制。 然而,对于SINR目标计算,我们仅导出干扰的上限并在我们的计算中使用它。
我们提出了一种深度强化学习(DRL)方法来解决上述竞争条件。 我们进一步利用功率控制和干扰协调进行联合波束形成。 我们通过同时协调服务和干扰BS的发射功率来实现这一点。 这种联合活动可以在中心位置或在其中一个基站进行,如图1所示。我们采用波束形成波束形成方法并执行下行链路功率控制和干扰协调(PCIC),而无需连接手机发送 这些命令到服务或干扰BS。 而是,BS基于RL自主地计算其PCIC命令。 PCIC命令是在任何给定的离散时间步骤代表单个手机发出的。
D.论文组织
本文的其余部分安排如下。 在第二节中,我们详细描述了网络模型,系统模型和信道模型。 第三部分概述了问题的制定,并激发了在这些问题中使用强化学习的重要性。 在第四部分,我们讨论深度强化学习及其在解决问题中的用法。 在第五节中,我们提出了基于RL的深度算法,以便在6 GHz以下频段内为语音承载执行协调PCIC。 第VI节将这个想法扩展到联合波束成形和PCIC,但是用于mmWave数据承载。 在第七节中,我们展示了建议的性能测量数量,以便对我们的算法进 第VIII节显示了基于所选性能测量的我们提出的算法的结果以及对这些结果的讨论。 我们在第九节中总结了这篇论文。
2 网络,系统和信道模型
A.网络模型
采用OFDM多址下行蜂窝网络
B.系统模型
功率控制和干扰协调在半专用信道上进行。对于语音,可以通过半永久性调度来实现,如我们在第一节中所提到的,它可以创建专用信道的虚拟感觉。对于数据承载,使用波束成形为给定的UE提供专用波束,可以通过它进行功率控制和干扰协调。
C.信道模型
窄带几何模型(广泛用于分析和设计毫米波系统),信道模型需考虑两种情况(LOS和NLOS)
信道函数组成:路径增益和偏离角(AoD),信道路径数(在毫米波信道中比6GHz以下信道(可捕获角度域中的稀疏性)少),路径损耗,
3 问题制定
我们的目标是联合优化波束成形矢量和L BS处的发射功率,以最大化用户可实现的总和速率。 我们制定了联合波束形成,功率控制和干扰协调优化问题
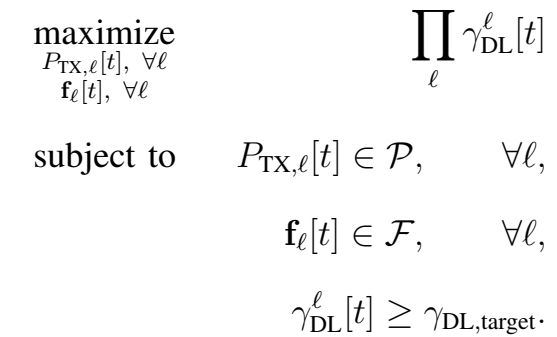
其中rDL,target表示下行链路传输的目标SNR。 由于约束的非凸性,该问题是非凸优化问题。 使用经典(非机器学习技术)解决这个问题通常需要在大空间上进行穷举搜索以找到候选解决方案。 在本文中,我们建议通过利用深度学习工具来解决这一挑战,这些工具可以在实现高SINR的同时避免穷举搜索。 特别是,采用深度学习(更具体地说是深度强化学习)的动机有以下几点:
1)我们不需要知道信道以便找到最佳波束形成向量。
2)我们最小化UE参与向BS发送反馈的参与。 特别地,UE发送回其接收的SINR及其坐标,而代理处理所涉及的BS的功率控制和干扰协调命令。
3)当涉及多个BS时,联合波束形成,功率控制和干扰协调的最佳协调是非常昂贵的。 RL的使用提供了L中线性时间内多个BS的控制开销的近似最优分布式协调。
4)UE发送给服务和干扰BS的显式PCIC命令需要修改当前的行业标准[13]。
接下来,在深入研究第V和VI节中提出的算法之前,我们将在第IV节中简要介绍深度强化学习。
4 关于深度加强学习的启动者
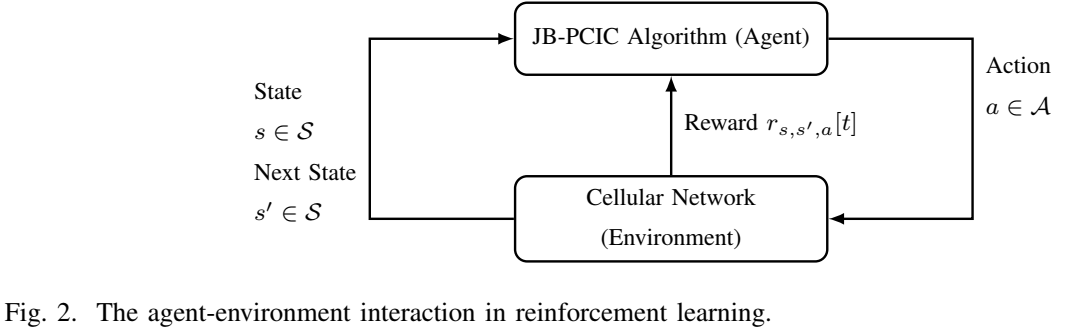
在本节中,我们描述了深度强化学习(DRL),它是[19]中引入的一种特殊类型的强化学习。 强化学习是一种机器学习技术,它使代理能够发现应该采取什么行动来最大化其在交互式环境中的预期未来奖励。 代理与环境之间的相互作用如图2所示。
由于我们在本文中采用强化学习算法,如第V和VI节所述,下一个描述侧重于强化学习。 特别是,DRL利用深度神经网络学习比手工制作的特征更好的表示的能力,并充当功能的通用逼近器。
强化学习要素:观察,状态,行动,策略,奖励,状态行动价值函数。
1)观察:观察是对环境特性的连续测量,写为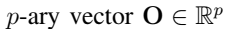 ,其中p为观察到的属性数。
,其中p为观察到的属性数。
2)状态:状态st是时间步长t处观测值的离散化。通常,状态也用于表示观察结果
3)行动:行动是代理可在时间步长t做出有有效选择之一,行动改变环境的状态(从当前状态转换为目标状态)
4)策略:策略π()操作是环境状态与代理要采取的动作之间的映射,随机策略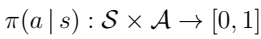
5)奖励:奖励信号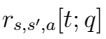 是代理处于时间步长t状态时采取行动并移动到下一个状态后获得的,参数
是代理处于时间步长t状态时采取行动并移动到下一个状态后获得的,参数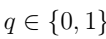 为承载选择器,它是一个二进制参数,用于区分话音承载者和数据承载者
为承载选择器,它是一个二进制参数,用于区分话音承载者和数据承载者
6)状态行动价值函数:策略下的状态行为价值函数,选择期望的折扣奖励

引入激活函数是为了增加神经网络模型的非线性,激活函数是用于计算隐藏层值的非线性函数。激活函数选择sigmoid函数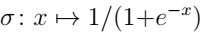
在线学习:与环境和DQN交互以获得预测并将其与真实答案进行比较并遭受损失的过程通常被称为“在线学习”。在在线学习中,UE将其数据反馈给服务BS,该服务BS轮流将其中继到用于DQN训练的中心位置,这个数据代表了网络环境的状态。
这些元素一起工作,它们之间的关系由目标决定,以便最大限度地提高代理选择的每个行动的未来折扣奖励,从而使环境转变为新的状态。 该政策规定了代理人与状态之间的关系。 通过训练阶段学习预期折扣奖励的价值。
收敛要求对状态-行为对进行无限次采样。
策略选择:通常情况下,Q学习是一种离线策略的一种强化学习算法,而非策略算法是即使根据任意搜索策略选择了动作也可以找到接近最优的策略。
本文选择了一种接近贪婪行为选择策略,该策略有两种模式:
1)探索:代理在每个时间步长t随机尝试不同的动作以发现最有效的动作。
2)利用:代理根据先前的经验在时间步骤t选择一个最大化状态行为价值函数。
5 深度强化学习语音功率控制和干扰协调
具有自适应调制和编码的固定的功率分配算法(FPA)为当今行业标准算法,并使用Q学习表格来实现该算法。
A.固定功率分配(Fixed Power Allocation,FPA)
将FPA功率控制作为基线算法,该算法可将发送信号功率设置为一个特定值。FPA中未实施干扰协调,总发射功率仅在所有PRB( physical resource blocks ,物理资源块)之间平均分配,恒定为:
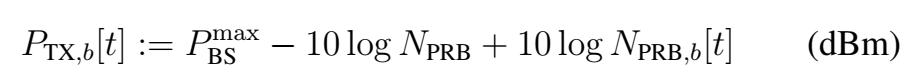
在标准算法中,BS固定其发射功率,仅更改发射的调制和编码方案,该改变被称为“链路自适应”,链路自适应是基于UE发送回BS的报告(即SINR和接收功率)进行的。由于BS的发射功率是固定的,因此链路自适应是基于从语音UE到服务BS的周期性或非周期性测量反馈而发生的,这也将导致改进的有效SINR和语音分组错误率的降低。另外,没有基于FPA的测量发送到干扰BS。
B.表格RL
使用Q学习的表格设置来实现语音通信,表格设置比DQN更适合小ULA尺寸M=1的问题
C.所提算法
一种基于DRL的算法,该算法无需UE发送明确的功率控制或干扰协调命令即可执行功率控制和干扰协调。相比于表格Q学习,使用DQN可以提供更低的计算开销,具体取决于状态数和DQN的深度。
该算法的主要步骤:

本文对语音使用自适应多速率编解码器(AMR)和正交相移键控。由于语音承载通常不需要高数据速率,所以本文选择固定调制。
6 深度强化学习mmWAVE波束形成功率控制和干扰协调
A.所提算法
所提算法共同控制波束成形矢量和发射功率以最大化目标函数,使用动作寄存器可同时执行多个动作。

B.上限
JB-PCIC算法在每个BS的欧几里德空间P*F中使用穷举搜索来优化SINR。虽然可以独立于ULA M中的天线数量选择P的大小,但F的大小与M直接相关。该算法对于较小的M和少量的BS L可能表现良好。
7 性能指标
A.收敛性
B. 覆盖范围
C.合率容量
8 仿真结果
在本节中,我们根据第VII节中的性能指标评估基于RL的建议解决方案的性能。 首先,我们在深入研究第VIII-B和VIII-C节中的模拟结果之前,描述了第VIII-A节中采用的设置。
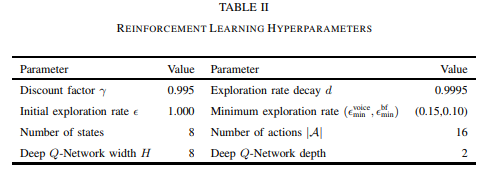
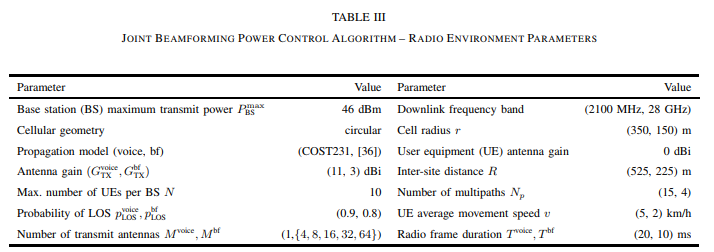
A.设置
目标SINR设置:
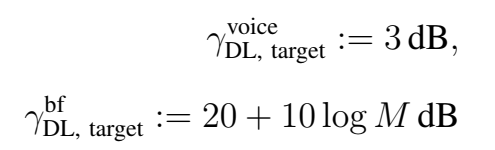
在我们提出的算法中,我们使用的奖励分为两层:1)根据所采取行动的时间,2)基于目标sinr是否满足或sinr是否低于最小值。

其中q=0用于语音承载,q=1用于数据承载。当对数据载体采取联合功率控制和波束成形动作时,对语音载体进行联合功率控制和干扰协调时,会在每个时间段对代理给予最大的奖励。显然,对于数据承载者,代理在波束成形码本中进行搜索比尝试增加或减少功率可获得更多奖励。但是,对于语音承载者,如果代理选择对服务的BS b进行功率控制,则与代理选择控制其他BSℓ的干扰相比,对代理的奖励更多。
B.结果
1)收敛性
ULA M的尺寸增加,所需的episodes 数量收敛增加,这是因为遍历波束形成码本的次数几乎随M的增加而线性增加。但是随着ULA M的大小减小,恒定阈值SNR的影响变得更加明显,这需要更多的episode克服在任何给定M时的影响。
2)覆盖范围
对于语音承载,可观察到SINR CCDF定义的覆盖范围在所有地方都有所提高。对于数据载体,覆盖范围在SINR BF随着M的增加而单调增加的地方得到改善,这是因为波束成形阵列增益随M的增加而增加。
3)求和速率
由于M的在增加,求和率的容量呈对数增长
C.图片
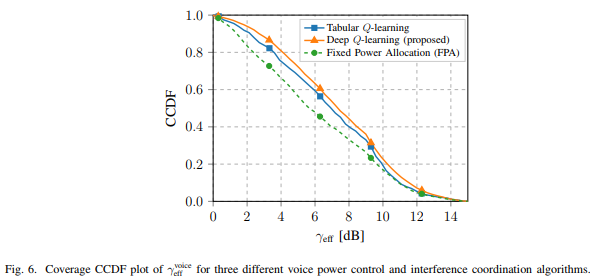
显示,FPA算法的性能最差,这是因为FPA没有功率控制或干扰协调(可预测)。表格式Q学习和深度Q学习PCIC实现的性能由于FPA。而深度Q学习优于表格式Q学习PCIC算法,这是因为选择状态动作值函数的初始化并没有妨碍深度Q学习收敛到更好的解决方案(这与表格式Q学习方法不同),当SINR的值为9dB时,两种方法开始出现差距,深度Q学习更接近于BS中心。
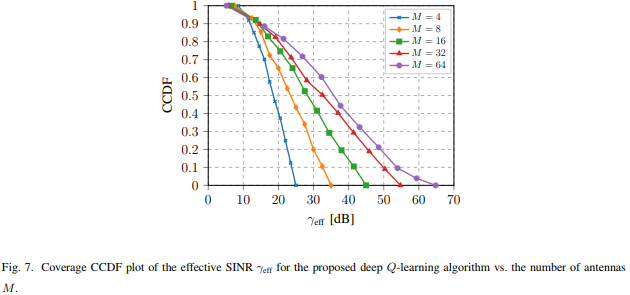
显示,随着M的增加,获得给定有效SINR的可能性也会随之增加,这是因为有效SINR取决于波束成形阵列增益(该增益为M的函数)。
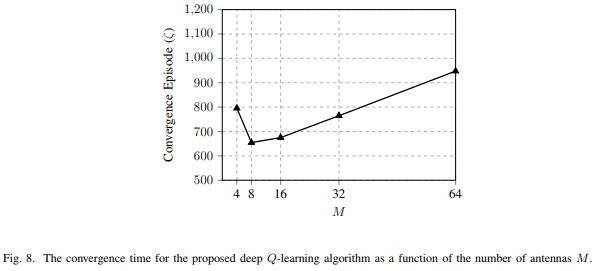
显示,当ULA M的大小较小时,恒定阈值SINR BF的影响变为主导地位,并且随着M 的增加,收敛的所需时间减小,这可能是因为波束网格中较宽度的波束能够覆盖以速度v移动的UE。如前面所提到的,随着ULA M尺寸的增加,所需的收敛次数会增加,SINR BF的影响最小,这是因为代理搜索码本的波束网格所需的时间较长,满足目标SINR需花费更长的时间。此时在尺寸大小为M时时间或时延是线性的,这是因为码本在M中是线性的。而此延迟可能分别对数据和语音承载的吞吐量和语音帧产生负面影响。
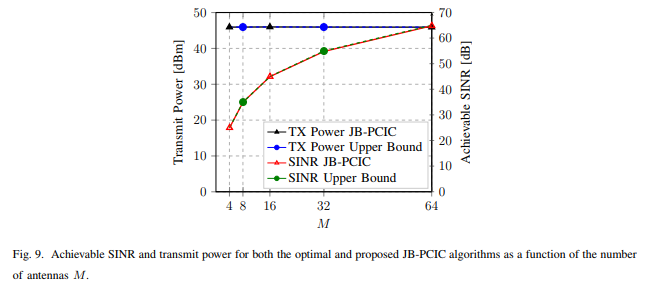
显示,所达到的SINR与ULA天线尺寸M成正比,这是因为波束成形阵列的增益小于等于M,发射功率几乎等于最大值。另外,还显示了与上限性能相比,JB-PCIC的相对性能。基站的发射功率和SINR的性能差距几乎在整个M范围内都减小了,这是因为DQN能够估算导致最佳性能的函数。
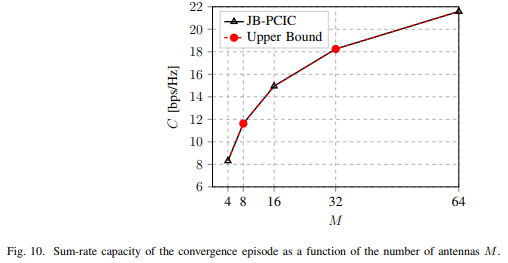
显示,与前面讨论的原因相同,所有M上的性能差距都在减小。
9 结论
在本文中,寻求在从多天线基站到单天线用户设备的OFDM多址蜂窝网络中最大化下行链路SINR。,其中用户设备受到来自其他多天线基站的干扰。 我们的系统使用低于6 GHz的频率用于语音和使用mmWave频率用于数据。 我们假设每个基站可以从有限集合中选择波束形成向量。 功率控制命令也来自有限集。 表明不存在封闭形式的解决方案,找到最佳答案需要进行详尽的搜索。 穷举搜索的运行时间是基站数量的指数。
为了避免穷举搜索,我们使用深度强化学习开发了联合波束形成,功率控制和干扰协调算法(JB-PCIC)。 实现的近似最佳SINR值高于通过工业标准算法实现的值。 对于语音通信,由于其更快的收敛,所提出的算法优于表格和固定功率分配算法。 所提出的算法的运行时复杂性是可能动作的数量,基站的数量和基站天线的数量的乘积。 也就是说,运行时复杂度在每个数量上都是线性的。
我们提出的用于联合波束形成,功率控制和干扰协调的算法要求UE每毫秒将其坐标及其接收的SINR发送到基站。 然而,所提出的算法不需要信道状态信息,这消除了对信道估计和相关训练序列的需要。 此外,降低了来自UE的总反馈量,因为UE不需要发送用于波束成形矢量改变,功率控制或干扰协调的显式命令。
5G网络的深度强化学习:联合波束成形,功率控制和干扰协调的更多相关文章
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- 论文:利用深度强化学习模型定位新物体(VISUAL SEMANTIC NAVIGATION USING SCENE PRIORS)
这是一篇被ICLR 2019 接收的论文.论文讨论了如何利用场景先验知识 (scene priors)来定位一个新场景(novel scene)中未曾见过的物体(unseen objects).举例来 ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 深度强化学习——连续动作控制DDPG、NAF
一.存在的问题 DQN是一个面向离散控制的算法,即输出的动作是离散的.对应到Atari 游戏中,只需要几个离散的键盘或手柄按键进行控制. 然而在实际中,控制问题则是连续的,高维的,比如一个具有6个关节 ...
- 深度强化学习资料(视频+PPT+PDF下载)
https://blog.csdn.net/Mbx8X9u/article/details/80780459 课程主页:http://rll.berkeley.edu/deeprlcourse/ 所有 ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- 用深度强化学习玩FlappyBird
摘要:学习玩游戏一直是当今AI研究的热门话题之一.使用博弈论/搜索算法来解决这些问题需要特别地进行周密的特性定义,使得其扩展性不强.使用深度学习算法训练的卷积神经网络模型(CNN)自提出以来在图像处理 ...
- 【资料总结】| Deep Reinforcement Learning 深度强化学习
在机器学习中,我们经常会分类为有监督学习和无监督学习,但是尝尝会忽略一个重要的分支,强化学习.有监督学习和无监督学习非常好去区分,学习的目标,有无标签等都是区分标准.如果说监督学习的目标是预测,那么强 ...
- 深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO) 2018-07-17 16:54:51 Reference: https://b ...
随机推荐
- Elasticsearch7.X 入门学习第八课笔记-----索引模板和动态模板
原文:Elasticsearch7.X 入门学习第八课笔记-----索引模板和动态模板 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接: ...
- java定时任务详解
首先,要创建你自己想要定时的实体类 @Service("smsService")@Transactionalpublic class SmsSendUtil { @Autowire ...
- 自定义、操作cookie
/** * 读取所有cookie * 注意二.从客户端读取Cookie时,包括maxAge在内的其他属性都是不可读的,也不会被提交.浏览器提交Cookie时只会提交name与value属性.maxAg ...
- 转载——CentOS---网络配置详解
看到一篇关于Centos网络配置很详细的文章,特此复制来.原文网址:http://blog.chinaunix.net/uid-26495963-id-3230810.html 一.配置文件详解在RH ...
- Android Studio使用阿里云Aliyun Maven仓库
如下所示,在build.gradle中添加Aliyun Maven仓库 // Top-level build file where you can add configuration options ...
- YOLOV3算法详解
YOLOV3 YOLO3主要的改进有:调整了网络结构:利用多尺度特征进行对象检测:对象分类用Logistic取代了softmax. 新的网络结构Darknet -53 darknet-53借用了re ...
- js中关键字 const , let , var 的用法区别
1.const定义的变量不可以修改,而且必须初始化. 2.var定义的变量可以修改,如果不初始化会输出undefined,不会报错. 3.let是块级作用域,函数内部使用let定义后,对函数外部无影响 ...
- Ubuntu 18.04 安装 CUDA 9.0
sudo dpkg -i cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64.deb sudo apt-key add /var/cuda-repo-< ...
- JDBC连接Hive数据库
一.依赖 pom <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncodi ...
- [POJ1934] Trip
问题描述 Alice and Bob want to go on holiday. Each of them has planned a route, which is a list of citie ...