spark 三种数据集的关系(一)
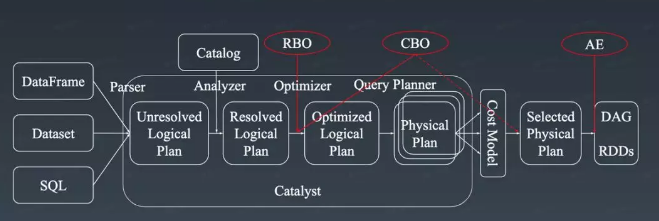
Catalyst Optimizer:
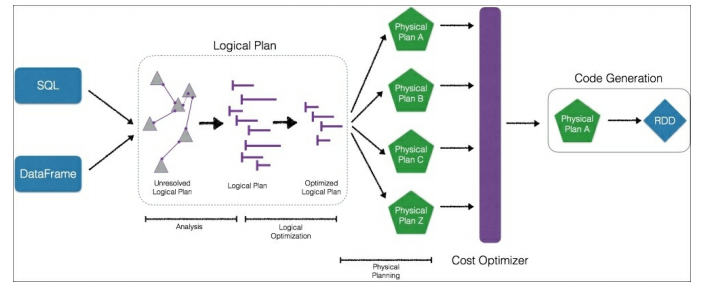
Dataset
数据集仅可用Scala或Java。但是,我们提供了以下上下文来更好地理解Spark 2.0的方向数据集是在2015年作为Apache Spark 1.6版本的一部分引入的。datasets的目标是提供一个类型安全的编程接口。
这允许开发人员使用具有编译时类型安全性的半结构化数据(如JSON或键值对)进行工作(也就是说,生产应用程序在运行之前可以检查错误)。
Python不实现Dataset API的部分原因是Python不是一种类型安全的语言。同样重要的是,数据集API包含高级领域特定的语言操作,如sum()、avg()、join()和group()。
后一个特性意味着您具有传统Spark RDDs的灵活性,但是代码也更容易表达、读取和编写。
从下图中可以看出,DataFrame和Dataset都属于作为Apache Spark的一部分引入的新Dataset API2.0:
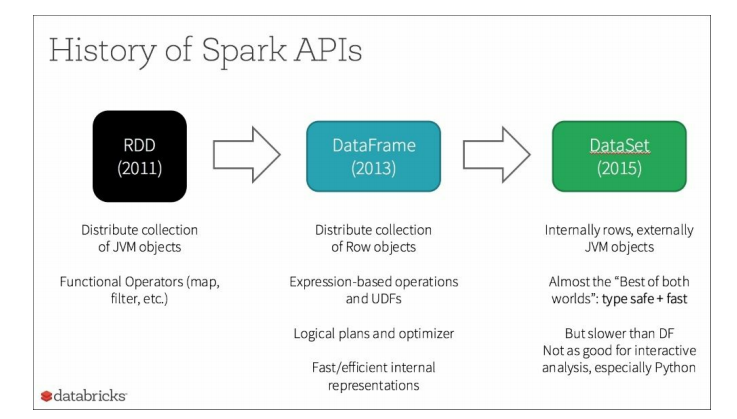
DataFrame和Dataset api的统一有可能创建打破向后兼容性的更改。
从下图中可以看出,DataFrame和Dataset都属于作为Apache Spark的一部分引入的新Dataset API2.0:DataFrame和Dataset api的统一有可能创建打破向后兼容性的更改。
这是Apache Spark 2.0成为主要版本的主要原因之一(最小化任何中断的更改)。从下图中可以看出,DataFrame和Dataset都属于作为Apache Spark的一部分引入的新Dataset API2.0:
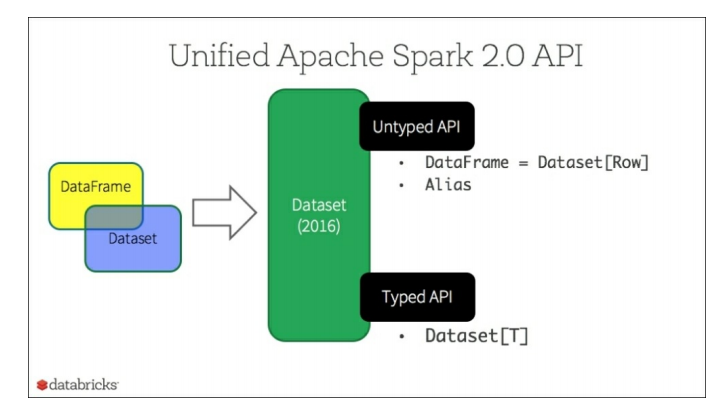
如前所述,Dataset API提供了一个类型安全的、面向对象的编程接口。数据集可以通过将表达式和数据字段公开给查询接口和
的快速内存编码来利用 。但是,随着DataFrame和Dataset现在作为Apache Spark 2.0的一部分统一起来,DataFrame现在是Dataset非类型化API的别名。
。但是,随着DataFrame和Dataset现在作为Apache Spark 2.0的一部分统一起来,DataFrame现在是Dataset非类型化API的别名。
更具体地说:
DataFrame = Dataset[T]
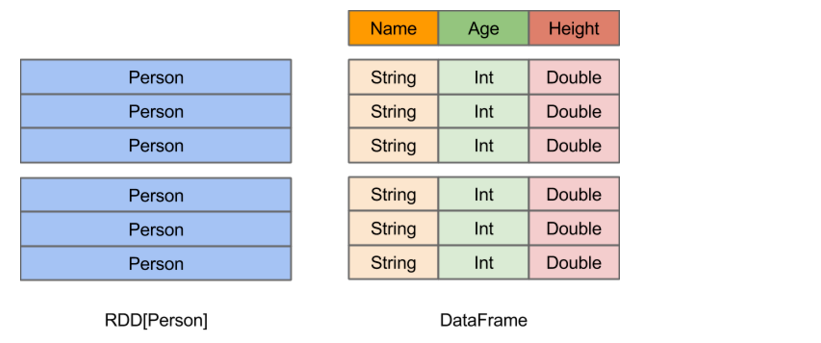
DataFrame是什么?
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
创建DataFrame
在Spark SQL中,开发者可以非常便捷地将各种内、外部的单机、分布式数据转换为DataFrame。以下Python示例代码充分体现了Spark SQL 1.3.0中DataFrame数据源的丰富多样和简单易用:
# 从Hive中的users表构造DataFrame
users = sqlContext.table("users") # 加载S3上的JSON文件
logs = sqlContext.load("s3n://path/to/data.json", "json") # 加载HDFS上的Parquet文件
clicks = sqlContext.load("hdfs://path/to/data.parquet", "parquet") # 通过JDBC访问MySQL
comments = sqlContext.jdbc("jdbc:mysql://localhost/comments", "user") # 将普通RDD转变为DataFrame
rdd = sparkContext.textFile("article.txt") \
.flatMap(lambda line: line.split()) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b) \
wordCounts = sqlContext.createDataFrame(rdd, ["word", "count"]) # 将本地数据容器转变为DataFrame
data = [("Alice", 21), ("Bob", 24)]
people = sqlContext.createDataFrame(data, ["name", "age"]) # 将Pandas DataFrame转变为Spark DataFrame(Python API特有功能)
sparkDF = sqlContext.createDataFrame(pandasDF)
使用DataFrame
和Pandas类似,Spark DataFrame也提供了一整套用于操纵数据的DSL。
这些DSL在语义上与SQL关系查询非常相近(这也是Spark SQL能够为DataFrame提供无缝支持的重要原因之一)。以下是一组用户数据分析示例:
# 创建一个只包含"年轻"用户的DataFrame
young = users.filter(users.age < 21) # 也可以使用Pandas风格的语法
young = users[users.age < 21] # 将所有人的年龄加1
young.select(young.name, young.age + 1) # 统计年轻用户中各性别人数
young.groupBy("gender").count() # 将所有年轻用户与另一个名为logs的DataFrame联接起来
young.join(logs, logs.userId == users.userId, "left_outer")
除DSL以外,我们当然也可以像以往一样,用SQL来处理DataFrame:
young.registerTempTable("young")
sqlContext.sql("SELECT count(*) FROM young")
最后,当数据分析逻辑编写完毕后,我们便可以将最终结果保存下来或展现出来:
# 追加至HDFS上的Parquet文件
young.save(path="hdfs://path/to/data.parquet",
source="parquet",
mode="append") # 覆写S3上的JSON文件
young.save(path="s3n://path/to/data.json",
source="json",
mode="append") # 保存为SQL表
young.saveAsTable(tableName="young", source="parquet" mode="overwrite") # 转换为Pandas DataFrame(Python API特有功能)
pandasDF = young.toPandas() # 以表格形式打印输出
young.show()</span>
1.幕后英雄:Spark SQL查询优化器与代码生成
正如RDD的各种变换实际上只是在构造RDD DAG,DataFrame的各种变换同样也是lazy的。它们并不直接求出计算结果,而是将各种变换组装成与RDD DAG类似的逻辑查询计划。如前所述,由于DataFrame带有schema元信息,Spark SQL的查询优化器得以洞察数据和计算的精细结构,从而施行具有很强针对性的优化。随后,经过优化的逻辑执行计划被翻译为物理执行计划,并最终落实为RDD DAG。
这样做的好处体现在几个方面:
1. 用户可以用更少的申明式代码阐明计算逻辑,物理执行路径则交由Spark SQL自行挑选。一方面降低了开发成本,一方面也降低了使用门槛——很多情况下,即便新手写出了较为低效的查询,Spark SQL也可以通过过滤条件下推、列剪枝等策略予以有效优化。这是RDD API所不具备的。
2. Spark SQL可以动态地为物理执行计划中的表达式生成JVM字节码,进一步实现归避虚函数调用开销、削减对象分配次数等底层优化,使得最终的查询执行性能可以与手写代码的性能相媲美。
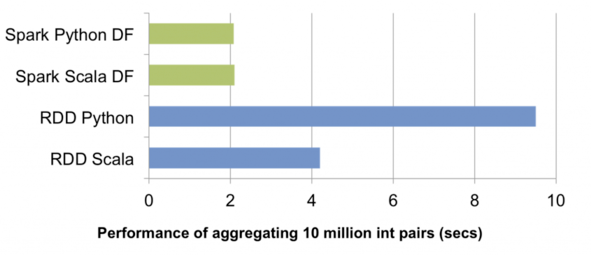
3. 对于PySpark而言,采用DataFrame编程时只需要构造体积小巧的逻辑执行计划,物理执行全部由JVM端负责,Python解释器和JVM间大量不必要的跨进程通讯得以免除。如上图所示,一组简单的对一千万整数对做聚合的测试中,PySpark中DataFrame API的性能轻松胜出RDD API近五倍。此外,今后Spark SQL在Scala端对查询优化器的所有性能改进,PySpark都可以免费获益。
2.外部数据源API增强

数据写入支持
在Spark 1.2.0中,外部数据源API只能将外部数据源中的数据读入Spark,而无法将计算结果写回数据源;同时,通过数据源引入并注册的表只能是临时表,相关元信息无法持久化。在1.3.0中,我们提供了完整的数据写入支持,从而补全了多数据源互操作的最后一块重要拼图。前文示例中Hive、Parquet、JSON、Pandas等多种数据源间的任意转换,正是这一增强的直接成果。
站在Spark SQL外部数据源开发者的角度,数据写入支持的API主要包括:
2.1. 数据源表元数据持久化
CREATE [TEMPORARY] TABLE [IF NOT EXISTS]
<table-name> [(col-name data-type [, ...)]
USING <source> [OPTIONS ...]
[AS <select-query>]
由此,注册自外部数据的SQL表既可以是临时表,也可以被持久化至Hive metastore。需要持久化支持的外部数据源,除了需要继承原有的RelationProvider以外,还需继承CreatableRelationProvider。
2.2. InsertableRelation
支持数据写入的外部数据源的relation类,还需继承trait InsertableRelation,并在insert方法中实现数据插入逻辑。
Spark 1.3.0中内置的JSON和Parquet数据源都已实现上述API,可以作为开发外部数据源的参考示例。
3.统一的load/save API
在Spark 1.2.0中,要想将SchemaRDD中的结果保存下来,便捷的选择并不多。常用的一些包括:
rdd.saveAsParquetFile(...)
rdd.saveAsTextFile(...)
rdd.toJSON.saveAsTextFile(...)
rdd.saveAsTable(...)
....
可见,不同的数据输出方式,采用的API也不尽相同。更令人头疼的是,我们缺乏一个灵活扩展新的数据写入格式的方式。
针对这一问题,1.3.0统一了load/save API,让用户按需自由选择外部数据源。这套API包括:
1.SQLContext.table
#从SQL表中加载DataFrame。 2.SQLContext.load
#从指定的外部数据源加载DataFrame。 3.SQLContext.createExternalTable
#将指定位置的数据保存为外部SQL表,元信息存入Hive metastore,并返回包含相应数据的DataFrame。 4.DataFrame.save
#将DataFrame写入指定的外部数据源。 5.DataFrame.saveAsTable
#将DataFrame保存为SQL表,元信息存入Hive metastore,同时将数据写入指定位置。
4.Parquet数据源增强
Spark SQL从一开始便内置支持Parquet这一高效的列式存储格式。在开放外部数据源API之后,原有的Parquet支持也正在逐渐转向外部数据源。1.3.0中,Parquet外部数据源的能力得到了显著增强。主要包括schema合并和自动分区处理。
1.Schema合并
与ProtocolBuffer和Thrift类似,Parquet也允许用户在定义好schema之后随时间推移逐渐添加新的列,只要不修改原有列的元信息,新旧schema仍然可以兼容。这一特性使得用户可以随时按需添加新的数据列,而无需操心数据迁移。
2.分区信息发现
按目录对同一张表中的数据分区存储,是Hive等系统采用的一种常见的数据存储方式。新的Parquet数据源可以自动根据目录结构发现和推演分区信息。
3.分区剪枝
分区实际上提供了一种粗粒度的索引。当查询条件中仅涉及部分分区时,通过分区剪枝跳过不必要扫描的分区目录,可以大幅提升查询性能。
以下Scala代码示例统一展示了1.3.0中Parquet数据源的这几个能力(Scala代码片段):
// 创建两个简单的DataFrame,将之存入两个独立的分区目录
val df1 = (1 to 5).map(i => (i, i * 2)).toDF("single", "double")
df1.save("data/test_table/key=1", "parquet", SaveMode.Append)
val df2 = (6 to 10).map(i => (i, i * 2)).toDF("single", "double")
df2.save("data/test_table/key=2", "parquet", SaveMode.Append)
// 在另一个DataFrame中引入一个新的列,并存入另一个分区目录
val df3 = (11 to 15).map(i => (i, i * 3)).toDF("single", "triple")
df3.save("data/test_table/key=3", "parquet", SaveMode.Append)
// 一次性读入整个分区表的数据
val df4 = sqlContext.load("data/test_table", "parquet")
// 按分区进行查询,并展示结果
val df5 = df4.filter($"key" >= 2)
df5.show()
这段代码的执行结果为:
6 12 null 2
7 14 null 2
8 16 null 2
9 18 null 2
10 20 null 2
11 null 33 3
12 null 36 3
13 null 39 3
14 null 42 3
15 null 45 3
可见,Parquet数据源自动从文件路径中发现了key这个分区列,并且正确合并了两个不相同但相容的schema。值得注意的是,在最后的查询中查询条件跳过了key=1这个分区。Spark SQL的查询优化器会根据这个查询条件将该分区目录剪掉,完全不扫描该目录中的数据,从而提升查询性能。
总体来说
- schema : RDD每一行的数据, 结构都是一样的. 这个结构就存储在schema中. Spark通过schame就能够读懂数据, 因此在通信和IO时就只需要序列化和反序列化数据, 而结构的部分就可以省略了.
off-heap : 意味着JVM堆以外的内存, 这些内存直接受操作系统管理(而不是JVM)。Spark能够以二进制的形式序列化数据(不包括结构)到off-heap中, 当要操作数据时, 就直接操作off-heap内存. 由于Spark理解schema, 所以知道该如何操作.
off-heap就像地盘, schema就像地图, Spark有地图又有自己地盘了, 就可以自己说了算了, 不再受JVM的限制, 也就不再收GC的困扰了.
通过schema和off-heap, DataFrame解决了RDD的缺点, 但是却丢了RDD的优点. DataFrame不是类型安全的, API也不是面向对象风格的.所以我们后来在spark2.0引入的dataset。
spark 三种数据集的关系(一)的更多相关文章
- spark 三种数据集的关系(二)
一个Dataset是一个分布式的数据集,而且它是一个新的接口,这个新的接口是在Spark1.6版本里面才被添加进来的,所以要注意DataFrame是先出来的,然后在1.6版本才出现的Dataset,提 ...
- spark三种连接Join
本文主要介绍spark join相关操作. 讲述spark连接相关的三个方法join,left-outer-join,right-outer-join,在这之前,我们用hiveSQL先跑出了结果以方便 ...
- Spark:三种任务提交流程standalone、yarn-cluster、yarn-client
spark的runtime参考:Spark:Yarn-cluster和Yarn-client区别与联系浪尖分享资料 standalone Spark可以通过部署与Yarn的架构类似的框架来提供自己的集 ...
- Spark三种部署方式
- Apache Spark 2.0三种API的传说:RDD、DataFrame和Dataset
Apache Spark吸引广大社区开发者的一个重要原因是:Apache Spark提供极其简单.易用的APIs,支持跨多种语言(比如:Scala.Java.Python和R)来操作大数据. 本文主要 ...
- Spark学习笔记-三种属性配置详细说明【转】
相关资料:Spark属性配置 http://www.cnblogs.com/chengxin1982/p/4023111.html 本文出处:转载自过往记忆(http://www.iteblog.c ...
- EF Core 快速上手——EF Core的三种主要关系类型
系列文章 EF Core 快速上手--EF Core 入门 本节导航 三种数据库关系类型建模 Migration方式创建和习修改数据库 定义和创建应用DbContext 将复杂查询拆分为子查询 本 ...
- Django-多对多关系的三种创建方式-forms组件使用-cookie与session-08
目录 表模型类多对多关系的三种创建方式 django forms 组件 登录功能手写推理过程 整段代码可以放过来 forms 组件使用 forms 后端定义规则并校验结果 forms 前端渲染标签组件 ...
- Django多对多表的三种创建方式,MTV与MVC概念
MTV与MVC MTV模型(django): M:模型层(models.py) T:templates V:views MVC模型: M:模型层(models.py) V:视图层(views.py) ...
随机推荐
- C#作业系统中的安全系统
比赛条件 编写多线程代码时,总是存在竞争条件的风险.当一个操作的输出取决于其控制之外的另一个过程的定时时,发生竞争条件. 竞争条件并不总是一个错误,但它是不确定行为的来源.当竞争条件确实导致错误时,可 ...
- PJzhang:URL重定向漏洞的72般变化
猫宁!!! 反射型xss的利用可以给对方发送钓鱼链接,窃取对方cookie,进入对方账户. 利用url重定向漏洞,发送给对方一个钓鱼链接,重定向到一个恶意网页,比如一个假的银行网站,被盗取账号密码 ...
- login 模块,re 模块
标准三流 标准输入流:sys. stdin # input的底层 标准输出流:sys. stdout # print的底层 标准错误流:sys. stderr # 异常及loggin ...
- DARTS代码分析(Pytorch)
最近在看DARTS的代码,有一个operations.py的文件,里面是对各类点与点之间操作的方法. OPS = { 'none': lambda C, stride, affine: Zero(st ...
- 关联规则(Apriori算法)
关联分析直观理解 关联分析中最有名的例子是“尿布与啤酒”.据报道,美国中西部的一家连锁店发现,男人们会在周四购买尿布和啤酒.这样商店实际上可以将尿布与啤酒放在一块,并确保在周四全价销售从而获利.当然, ...
- 【Python开发】Python之re模块 —— 正则表达式操作
Python之re模块 -- 正则表达式操作 这个模块提供了与 Perl 相似l的正则表达式匹配操作.Unicode字符串也同样适用. 正则表达式使用反斜杠" \ "来代表特殊形式 ...
- 通道的分离与合并,ROI,
通道的分离与合并 class Program { static void Main(String[] args) { Mat img = CvInvoke.Imread(@"C:\Users ...
- stm32 F40x CCM数据区的使用
1. CCM需要打开总线时钟 2. CCM可以作为堆和栈使用 使用分散加载文件直接操作即可 RW_CCMRAM1 0x10000000 { .ANY (HEAP) .ANY (STACK) } 3. ...
- select poll epoll之间的区别
1.select poll每次循环调用时都需要将文件描述符和事件拷贝到内核空间,epoll只需要拷贝一次: (这种情况在对于描述符数量不大的情况下还可以,但是当描述符的数量达到十几万甚至上百万的时候, ...
- Centos 7 下Gitlab 自启动设置
禁止 Gitlab 开机自启动: systemctl disable gitlab-runsvdir.service 启用 Gitlab 开机自启动: systemctl enable gitlab- ...