mysql的两阶段提交协议
http://www.cnblogs.com/hustcat/p/3577584.html
前两天和百度的一个同学聊MySQL两阶段提交,当时自信满满的说了一堆,后来发现还是有些问题的理解还是比较模糊,可能是因为时间太久了,忘记了吧。这里再补一下:)
5.3.1事务提交流程
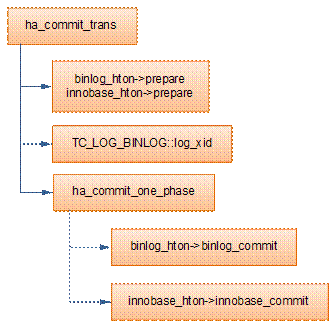
MySQL的事务提交逻辑主要在函数ha_commit_trans中完成。事务的提交涉及到binlog及具体的存储的引擎的事务提交。所以MySQL用2PC来保证的事务的完整性。MySQL的2PC过程如下:
T@ : | | | | >trans_commit
T@ : | | | | | enter: stmt.ha_list: <NONE>, all.ha_list: <NONE>
T@ : | | | | | debug: stmt.unsafe_rollback_flags:
T@ : | | | | | debug: all.unsafe_rollback_flags:
T@ : | | | | | >trans_check
T@ : | | | | | <trans_check
T@ : | | | | | info: clearing SERVER_STATUS_IN_TRANS
T@4 : | | | | | >ha_commit_trans
T@ : | | | | | | info: all= thd->in_sub_stmt= ha_info=0x0 is_real_trans=
T@ : | | | | | | >MYSQL_BIN_LOG::commit
T@ : | | | | | | | enter: thd: 0x2b9f4c07beb0, all: yes, xid: , cache_mngr: 0x0
T@ : | | | | | | | >ha_commit_low
T@ : | | | | | | | | >THD::st_transaction::cleanup
T@ : | | | | | | | | | >free_root
T@ : | | | | | | | | | | enter: root: 0x2b9f4c07d660 flags:
T@ : | | | | | | | | | <free_root
T@ : | | | | | | | | <THD::st_transaction::cleanup
T@ : | | | | | | | <ha_commit_low
T@ : | | | | | | <MYSQL_BIN_LOG::commit
T@ : | | | | | | >THD::st_transaction::cleanup
T@ : | | | | | | | >free_root
T@ : | | | | | | | | enter: root: 0x2b9f4c07d660 flags:
T@ : | | | | | | | <free_root
T@ : | | | | | | <THD::st_transaction::cleanup
T@ : | | | | | <ha_commit_trans
T@ : | | | | | debug: reset_unsafe_rollback_flags
T@ : | | | | <trans_commit
T@ : | | | | >MDL_context::release_transactional_locks
T@ : | | | | | >MDL_context::release_locks_stored_before
T@ : | | | | | <MDL_context::release_locks_stored_before
T@ : | | | | | >MDL_context::release_locks_stored_before
T@ : | | | | | <MDL_context::release_locks_stored_before
T@ : | | | | <MDL_context::release_transactional_locks
T@ : | | | | >set_ok_status
T@ : | | | | <set_ok_status
T@ : | | | | THD::enter_stage: /usr/src/mysql-5.6./sql/sql_parse.cc:
T@ : | | | | >PROFILING::status_change
T@ : | | | | <PROFILING::status_change
T@ : | | | | >trans_commit_stmt
T@ : | | | | | enter: stmt.ha_list: <NONE>, all.ha_list: <NONE>
T@ : | | | | | enter: stmt.ha_list: <NONE>, all.ha_list: <NONE>
T@ : | | | | | debug: stmt.unsafe_rollback_flags:
T@ : | | | | | debug: all.unsafe_rollback_flags:
T@ : | | | | | debug: add_unsafe_rollback_flags:
T@ : | | | | | >MYSQL_BIN_LOG::commit
(1)先调用binglog_hton和innobase_hton的prepare方法完成第一阶段,binlog_hton的papare方法实际上什么也没做,innodb的prepare将事务状态设为TRX_PREPARED,并将redo log刷磁盘 (innobase_xa_prepare à trx_prepare_for_mysql à trx_prepare_off_kernel)。
(2)如果事务涉及的所有存储引擎的prepare都执行成功,则调用TC_LOG_BINLOG::log_xid将SQL语句写到binlog,此时,事务已经铁定要提交了。否则,调用ha_rollback_trans回滚事务,而SQL语句实际上也不会写到binlog。
(3)最后,调用引擎的commit完成事务的提交。实际上binlog_hton->commit什么也不会做(因为(2)已经将binlog写入磁盘),innobase_hton->commit则清除undo信息,刷redo日志,将事务设为TRX_NOT_STARTED状态(innobase_commit à innobase_commit_low à trx_commit_for_mysql à trx_commit_off_kernel)。
|
//ha_innodb.cc static int innobase_commit( /*============*/ /* out: 0 */ THD* thd, /* in: MySQL thread handle of the user for whom the transaction should be committed */ bool all) /* in: TRUE - commit transaction FALSE - the current SQL statement ended */ { ... trx->mysql_log_file_name = mysql_bin_log.get_log_fname(); trx->mysql_log_offset = (ib_longlong)mysql_bin_log.get_log_file()->pos_in_file; ... } |
函数innobase_commit提交事务,先得到当前的binlog的位置,然后再写入事务系统PAGE(trx_commit_off_kernel à trx_sys_update_mysql_binlog_offset)。
InnoDB将MySQL binlog的位置记录到trx system header中:
|
//trx0sys.h /* The offset of the MySQL binlog offset info in the trx system header */ #define TRX_SYS_MYSQL_LOG_INFO (UNIV_PAGE_SIZE - 1000) #define TRX_SYS_MYSQL_LOG_MAGIC_N_FLD 0 /* magic number which shows if we have valid data in the MySQL binlog info; the value is ..._MAGIC_N if yes */ #define TRX_SYS_MYSQL_LOG_OFFSET_HIGH 4 /* high 4 bytes of the offset within that file */ #define TRX_SYS_MYSQL_LOG_OFFSET_LOW 8 /* low 4 bytes of the offset within that file */ #define TRX_SYS_MYSQL_LOG_NAME 12 /* MySQL log file name */ |
5.3.2 事务恢复流程
Innodb在恢复的时候,不同状态的事务,会进行不同的处理(见trx_rollback_or_clean_all_without_sess函数):
<1>对于TRX_COMMITTED_IN_MEMORY的事务,清除回滚段,然后将事务设为TRX_NOT_STARTED;
<2>对于TRX_NOT_STARTED的事务,表示事务已经提交,跳过;
<3>对于TRX_PREPARED的事务,要根据binlog来决定事务的命运,暂时跳过;
<4>对于TRX_ACTIVE的事务,回滚。
MySQL在打开binlog时,会检查binlog的状态(TC_LOG_BINLOG::open)。如果binlog没有正常关闭(LOG_EVENT_BINLOG_IN_USE_F为1),则进行恢复操作,基本流程如下:
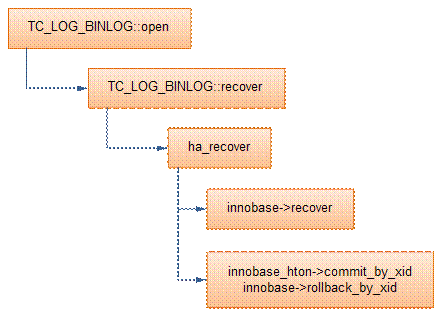
<1>扫描binlog,读取XID_EVENT事务,得到所有已经提交的XA事务列表(实际上事务在innodb可能处于prepare或者commit);
<2>对每个XA事务,调用handlerton::recover,检查存储引擎是否存在处于prepare状态的该事务(见innobase_xa_recover),也就是检查该XA事务在存储引擎中的状态;
<3>如果存在处于prepare状态的该XA事务,则调用handlerton::commit_by_xid提交事务;
<4>否则,调用handlerton::rollback_by_xid回滚XA事务。
5.3.3 几个参数讨论
(1)sync_binlog
Mysql在提交事务时调用MYSQL_LOG::write完成写binlog,并根据sync_binlog决定是否进行刷盘。默认值是0,即不刷盘,从而把控制权让给OS。如果设为1,则每次提交事务,就会进行一次刷盘;这对性能有影响(5.6已经支持binlog group),所以很多人将其设置为100。
bool MYSQL_LOG::flush_and_sync()
{
int err=0, fd=log_file.file;
safe_mutex_assert_owner(&LOCK_log);
if (flush_io_cache(&log_file))
return 1;
if (++sync_binlog_counter >= sync_binlog_period && sync_binlog_period)
{
sync_binlog_counter= 0;
err=my_sync(fd, MYF(MY_WME));
}
return err;
}
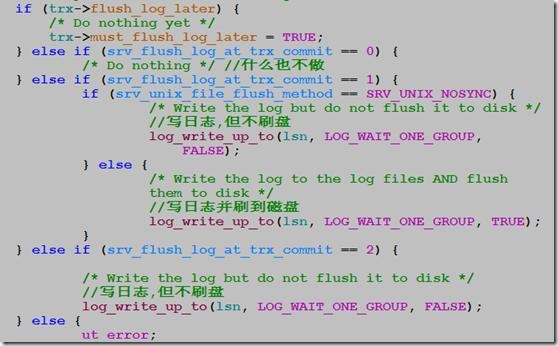
(2) innodb_flush_log_at_trx_commit
该参数控制innodb在提交事务时刷redo log的行为。默认值为1,即每次提交事务,都进行刷盘操作。为了降低对性能的影响,在很多生产环境设置为2,甚至0。
trx_flush_log_if_needed_low(
/*========================*/
lsn_t lsn) /*!< in: lsn up to which logs are to be
flushed. */
{
switch (srv_flush_log_at_trx_commit) {
case :
/* Do nothing */
break;
case :
/* Write the log and optionally flush it to disk */
log_write_up_to(lsn, LOG_WAIT_ONE_GROUP,
srv_unix_file_flush_method != SRV_UNIX_NOSYNC);
break;
case :
/* Write the log but do not flush it to disk */
log_write_up_to(lsn, LOG_WAIT_ONE_GROUP, FALSE); break;
default:
ut_error;
}
}
If the value of innodb_flush_log_at_trx_commit is 0, the log buffer is written out to the log file once per second and the flush to disk operation is performed on the log file, but nothing is done at a transaction commit. When the value is 1 (the default), the log buffer is written out to the log file at each transaction commit and the flush to disk operation is performed on the log file. When the value is 2, the log buffer is written out to the file at each commit, but the flush to disk operation is not performed on it. However, the flushing on the log file takes place once per second also when the value is 2. Note that the once-per-second flushing is not 100% guaranteed to happen every second, due to process scheduling issues.
The default value of 1 is required for full ACID compliance. You can achieve better performance by setting the value different from 1, but then you can lose up to one second worth of transactions in a crash. With a value of 0, any mysqld process crash can erase the last second of transactions. With a value of 2, only an operating system crash or a power outage can erase the last second of transactions.
(3) innodb_support_xa
用于控制innodb是否支持XA事务的2PC,默认是TRUE。如果关闭,则innodb在prepare阶段就什么也不做;这可能会导致binlog的顺序与innodb提交的顺序不一致(比如A事务比B事务先写binlog,但是在innodb内部却可能A事务比B事务后提交),这会导致在恢复或者slave产生不同的数据。
int
innobase_xa_prepare(
/*================*/
/* out: 0 or error number */
THD* thd, /* in: handle to the MySQL thread of the user
whose XA transaction should be prepared */
bool all) /* in: TRUE - commit transaction
FALSE - the current SQL statement ended */
{
…
if (!thd->variables.innodb_support_xa) {
return(0);
}
ver mysql 5.7 bool trans_xa_commit(THD *thd)
{
bool res= TRUE;
enum xa_states xa_state= thd->transaction.xid_state.xa_state;
DBUG_ENTER("trans_xa_commit"); if (!thd->transaction.xid_state.xid.eq(thd->lex->xid))
{
/*
xid_state.in_thd is always true beside of xa recovery procedure.
Note, that there is no race condition here between xid_cache_search
and xid_cache_delete, since we always delete our own XID
(thd->lex->xid == thd->transaction.xid_state.xid).
The only case when thd->lex->xid != thd->transaction.xid_state.xid
and xid_state->in_thd == 0 is in the function
xa_cache_insert(XID, xa_states), which is called before starting
client connections, and thus is always single-threaded.
*/
XID_STATE *xs= xid_cache_search(thd->lex->xid);
res= !xs || xs->in_thd;
if (res)
my_error(ER_XAER_NOTA, MYF());
else
{
res= xa_trans_rolled_back(xs);
ha_commit_or_rollback_by_xid(thd, thd->lex->xid, !res);
xid_cache_delete(xs);
}
DBUG_RETURN(res);
} if (xa_trans_rolled_back(&thd->transaction.xid_state))
{
xa_trans_force_rollback(thd);
res= thd->is_error();
}
else if (xa_state == XA_IDLE && thd->lex->xa_opt == XA_ONE_PHASE)
{
int r= ha_commit_trans(thd, TRUE);
if ((res= MY_TEST(r)))
my_error(r == ? ER_XA_RBROLLBACK : ER_XAER_RMERR, MYF());
}
else if (xa_state == XA_PREPARED && thd->lex->xa_opt == XA_NONE)
{
MDL_request mdl_request; /*
Acquire metadata lock which will ensure that COMMIT is blocked
by active FLUSH TABLES WITH READ LOCK (and vice versa COMMIT in
progress blocks FTWRL). We allow FLUSHer to COMMIT; we assume FLUSHer knows what it does.
*/
mdl_request.init(MDL_key::COMMIT, "", "", MDL_INTENTION_EXCLUSIVE,
MDL_TRANSACTION); if (thd->mdl_context.acquire_lock(&mdl_request,
thd->variables.lock_wait_timeout))
{
ha_rollback_trans(thd, TRUE);
my_error(ER_XAER_RMERR, MYF());
}
else
{
DEBUG_SYNC(thd, "trans_xa_commit_after_acquire_commit_lock"); if (tc_log)
res= MY_TEST(tc_log->commit(thd, /* all */ true));
else
res= MY_TEST(ha_commit_low(thd, /* all */ true)); if (res)
my_error(ER_XAER_RMERR, MYF());
}
}
else
{
my_error(ER_XAER_RMFAIL, MYF(), xa_state_names[xa_state]);
DBUG_RETURN(TRUE);
} thd->variables.option_bits&= ~OPTION_BEGIN;
thd->transaction.all.reset_unsafe_rollback_flags();
thd->server_status&=
~(SERVER_STATUS_IN_TRANS | SERVER_STATUS_IN_TRANS_READONLY);
DBUG_PRINT("info", ("clearing SERVER_STATUS_IN_TRANS"));
xid_cache_delete(&thd->transaction.xid_state);
thd->transaction.xid_state.xa_state= XA_NOTR; DBUG_RETURN(res);
}
5.3.4 安全性/性能讨论
上面3个参数不同的值会带来不同的效果。三者都设置为1(TRUE),数据才能真正安全。sync_binlog非1,可能导致binlog丢失(OS挂掉),从而与innodb层面的数据不一致。innodb_flush_log_at_trx_commit非1,可能会导致innodb层面的数据丢失(OS挂掉),从而与binlog不一致。
关于性能分析,可以参考
http://www.mysqlperformanceblog.com/2011/03/02/what-is-innodb_support_xa/
在事务提交时innobase会调用ha_innodb.cc 中的innobase_commit,而innobase_commit通过调用trx_commit_complete_for_mysql(trx0trx.c)来调用log_write_up_to(log0log.c),也就是当innobase提交事务的时候就会调用log_write_up_to来写redo log
innobase_commit中
if (all # 如果是事务提交
|| (!thd_test_options(thd, OPTION_NOT_AUTOCOMMIT | OPTION_BEGIN))) {
通过下面的代码实现事务的commit串行化
if (innobase_commit_concurrency > ) {
pthread_mutex_lock(&commit_cond_m);
commit_threads++; if (commit_threads > innobase_commit_concurrency) {
commit_threads--;
pthread_cond_wait(&commit_cond,
&commit_cond_m);
pthread_mutex_unlock(&commit_cond_m);
goto retry;
}
else {
pthread_mutex_unlock(&commit_cond_m);
}
} trx->flush_log_later = TRUE; # 在做提交操作时禁止flush binlog 到磁盘
innobase_commit_low(trx);
trx->flush_log_later = FALSE;
先略过innobase_commit_low调用 ,下面开始调用trx_commit_complete_for_mysql做write日志操作
trx_commit_complete_for_mysql(trx); #开始flush log
trx->active_trans = ;
在trx_commit_complete_for_mysql中,主要做的是对系统参数srv_flush_log_at_trx_commit值做判断来调用
log_write_up_to,或者write redo log file或者write&&flush to disk
if (!trx->must_flush_log_later) {
/* Do nothing */
} else if (srv_flush_log_at_trx_commit == ) { #flush_log_at_trx_commit=,事务提交不写redo log
/* Do nothing */
} else if (srv_flush_log_at_trx_commit == ) { #flush_log_at_trx_commit=,事务提交写log并flush磁盘,如果flush方式不是SRV_UNIX_NOSYNC (这个不是很熟悉)
if (srv_unix_file_flush_method == SRV_UNIX_NOSYNC) {
/* Write the log but do not flush it to disk */ log_write_up_to(lsn, LOG_WAIT_ONE_GROUP, FALSE);
} else {
/* Write the log to the log files AND flush them to
disk */ log_write_up_to(lsn, LOG_WAIT_ONE_GROUP, TRUE);
}
} else if (srv_flush_log_at_trx_commit == ) { #如果是2,则只write到redo log /* Write the log but do not flush it to disk */ log_write_up_to(lsn, LOG_WAIT_ONE_GROUP, FALSE);
} else {
ut_error;
}
那么下面看log_write_up_to
if (flush_to_disk #如果flush到磁盘,则比较当前commit的lsn是否大于已经flush到磁盘的lsn
&& ut_dulint_cmp(log_sys->flushed_to_disk_lsn, lsn) >= ) { mutex_exit(&(log_sys->mutex)); return;
} if (!flush_to_disk #如果不flush磁盘则比较当前commit的lsn是否大于已经写到所有redo log file的lsn,或者在只等一个group完成条件下是否大于已经写到某个redo file的lsn
&& (ut_dulint_cmp(log_sys->written_to_all_lsn, lsn) >=
|| (ut_dulint_cmp(log_sys->written_to_some_lsn, lsn)
>=
&& wait != LOG_WAIT_ALL_GROUPS))) { mutex_exit(&(log_sys->mutex)); return;
}
#下面的代码判断是否log在write,有的话等待其完成
if (log_sys->n_pending_writes > ) {
if (flush_to_disk # 如果需要刷新到磁盘,如果正在flush的lsn包括了commit的lsn,只要等待操作完成就可以了
&& ut_dulint_cmp(log_sys->current_flush_lsn, lsn)
>= ) {
goto do_waits;
} if (!flush_to_disk # 如果是刷到redo log file的那么如果在write的lsn包括了commit的lsn,也只要等待就可以了
&& ut_dulint_cmp(log_sys->write_lsn, lsn) >= ) {
goto do_waits;
}
......
if (!flush_to_disk # 如果在当前IO空闲情况下 ,而且不需要flush到磁盘,那么 如果下次写的位置已经到达buf_free位置说明wirte操作都已经完成了,直接返回
&& log_sys->buf_free == log_sys->buf_next_to_write) {
mutex_exit(&(log_sys->mutex));
return;
}
下面取到group,设置相关write or flush相关字段,并且得到起始和结束位置的block号
log_sys->n_pending_writes++; group = UT_LIST_GET_FIRST(log_sys->log_groups);
group->n_pending_writes++; /* We assume here that we have only
one log group! */ os_event_reset(log_sys->no_flush_event);
os_event_reset(log_sys->one_flushed_event); start_offset = log_sys->buf_next_to_write;
end_offset = log_sys->buf_free; area_start = ut_calc_align_down(start_offset, OS_FILE_LOG_BLOCK_SIZE);
area_end = ut_calc_align(end_offset, OS_FILE_LOG_BLOCK_SIZE); ut_ad(area_end - area_start > ); log_sys->write_lsn = log_sys->lsn; if (flush_to_disk) {
log_sys->current_flush_lsn = log_sys->lsn;
}
log_block_set_checkpoint_no调用设置end_offset所在block的LOG_BLOCK_CHECKPOINT_NO为log_sys中下个检查点号
log_block_set_flush_bit(log_sys->buf + area_start, TRUE); # 这个没看明白
log_block_set_checkpoint_no(
log_sys->buf + area_end - OS_FILE_LOG_BLOCK_SIZE,
log_sys->next_checkpoint_no);
保存不属于end_offset但在其所在的block中的数据到下一个空闲的block
ut_memcpy(log_sys->buf + area_end,
log_sys->buf + area_end - OS_FILE_LOG_BLOCK_SIZE,
OS_FILE_LOG_BLOCK_SIZE);
对于每个group调用log_group_write_buf写redo log buffer
while (group) {
log_group_write_buf(
group, log_sys->buf + area_start,
area_end - area_start,
ut_dulint_align_down(log_sys->written_to_all_lsn,
OS_FILE_LOG_BLOCK_SIZE),
start_offset - area_start); log_group_set_fields(group, log_sys->write_lsn); # 计算这次写的lsn和offset来设置group->lsn和group->lsn_offset group = UT_LIST_GET_NEXT(log_groups, group);
}
......
if (srv_unix_file_flush_method == SRV_UNIX_O_DSYNC) { # 这个是什么东西
/* O_DSYNC means the OS did not buffer the log file at all:
so we have also flushed to disk what we have written */ log_sys->flushed_to_disk_lsn = log_sys->write_lsn; } else if (flush_to_disk) { group = UT_LIST_GET_FIRST(log_sys->log_groups); fil_flush(group->space_id); # 最后调用fil_flush执行flush到磁盘
log_sys->flushed_to_disk_lsn = log_sys->write_lsn;
} 接下来看log_group_write_buf做了点什么 在log_group_calc_size_offset中,从group中取到上次记录的lsn位置(注意是log files组成的1个环状buffer),并计算这次的lsn相对于上次的差值
# 调用log_group_calc_size_offset计算group->lsn_offset除去多个LOG_FILE头部长度后的大小,比如lsn_offset落在第3个log file上,那么需要减掉3*LOG_FILE_HDR_SIZE的大小
gr_lsn_size_offset = (ib_longlong)
log_group_calc_size_offset(group->lsn_offset, group);
group_size = (ib_longlong) log_group_get_capacity(group); # 计算group除去所有LOG_FILE_HDR_SIZE长度后的DATA部分大小 # 下面是典型的环状结构差值计算
if (ut_dulint_cmp(lsn, gr_lsn) >= ) { difference = (ib_longlong) ut_dulint_minus(lsn, gr_lsn);
} else {
difference = (ib_longlong) ut_dulint_minus(gr_lsn, lsn); difference = difference % group_size; difference = group_size - difference;
} offset = (gr_lsn_size_offset + difference) % group_size;
# 最后算上每个log file 头部大小,返回真实的offset
return(log_group_calc_real_offset((ulint)offset, group));
接着看 # 如果需要写的内容超过一个文件大小
if ((next_offset % group->file_size) + len > group->file_size) { write_len = group->file_size # 写到file末尾
- (next_offset % group->file_size);
} else {
write_len = len; # 否者写len个block
} # 最后真正的内容就是写buffer了,如果跨越file的话另外需要写file log file head部分 if ((next_offset % group->file_size == LOG_FILE_HDR_SIZE)
&& write_header) {
/* We start to write a new log file instance in the group */ log_group_file_header_flush(group,
next_offset / group->file_size,
start_lsn);
srv_os_log_written+= OS_FILE_LOG_BLOCK_SIZE;
srv_log_writes++;
} # 调用fil_io来执行buffer写
if (log_do_write) {
log_sys->n_log_ios++; srv_os_log_pending_writes++; fil_io(OS_FILE_WRITE | OS_FILE_LOG, TRUE, group->space_id,
next_offset / UNIV_PAGE_SIZE,
next_offset % UNIV_PAGE_SIZE, write_len, buf, group); srv_os_log_pending_writes--; srv_os_log_written+= write_len;
srv_log_writes++;
mysql的两阶段提交协议的更多相关文章
- 浅谈mysql的两阶段提交协议
前两天和百度的一个同学聊MySQL两阶段提交,当时自信满满的说了一堆,后来发现还是有些问题的理解还是比较模糊,可能是因为时间太久了,忘记了吧.这里再补一下:) 5.3.1事务提交流程 MySQL的事务 ...
- 浅析SQL Server实现分布式事务的两阶段提交协议2PC
不久之前团队有个新人问我一个很重要的web服务接口如何保证事务的问题.因为涉及到跨库事务,当时我只是回答目前我们的SOA框架都不支持跨库事务.然后就问到了数据库跨库事务是如何实现的,我只能凭印象含糊回 ...
- 分布式协议之两阶段提交协议(2PC)和改进三阶段提交协议(3PC)
一. 事务的ACID 事务是保证数据库从一个一致性的状态永久地变成另外一个一致性状态的根本,当中,ACID是事务的基本特性. A是Atomicity,原子性.一个事务往往涉及到很多的子操作,原子性则保 ...
- mysql 有两种数据库引擎发音
mysql 有两种数据库引擎 一种是 MyISAM,一种是 InnoDB MyISAM 发音为 "my-z[ei]m"; InnoDB 发音为 "in-no-db&quo ...
- flask 操作mysql的两种方式-sqlalchemy操作
flask 操作mysql的两种方式-sqlalchemy操作 二.ORM sqlalchemy操作 #coding=utf-8 # model.py from app import db class ...
- flask 操作mysql的两种方式-sql操作
flask 操作mysql的两种方式-sql操作 一.用常规的sql语句操作 # coding=utf-8 # model.py import MySQLdb def get_conn(): conn ...
- MySql获取两个日期间的时间差
[1]MySql 语言获取两个日期间的时间差 DATEDIFF 函数可以获得两个日期之间的时间差.但是,这个函数得出的结果是天数. 需要直接获取秒数可使用TIMESTAMPDIFF函数.应用示例如下: ...
- MySql计算两个日期的时间差函数
MySql计算两个日期时间的差函数: 第一种:TIMESTAMPDIFF函数,需要传入三个参数,第一个是比较的类型,可以比较FRAC_SECOND.SECOND. MINUTE. HOUR. DAY. ...
- mysql合并 两个count语句一次性输出结果的方法
mysql合并 两个count语句一次性输出结果的方法 需求场景:经常要查看有两个表统计数,用SELECT COUNT(*) FROM hotcontents,SELECT COUNT(*) FROM ...
随机推荐
- 动画 -- ListView列表item逐个出来(从无到有)
import android.app.ListActivity; import android.os.Bundle; import android.widget.ArrayAdapter; publi ...
- 在asp.net mvc中使用PartialView返回部分HTML段
问题链接: MVC如何实现异步调用输出HTML页面 该问题是个常见的 case, 故写篇文章用于提示新人. 在asp.net mvc中返回View时使用的是ViewResult,它继承自ViewRes ...
- 最长公共子序列LCS
LCS:给出两个序列S1和S2,求出的这两个序列的最大公共部分S3就是就是S1和S2的最长公共子序列了.公共部分 必须是以相同的顺序出现,但是不必要是连续的. LCS具有最优子结构,且满足重叠子问题的 ...
- 举例详细说明javascript作用域、闭包原理以及性能问题(转)
转自:http://www.cnblogs.com/mrsunny/archive/2011/11/03/2233978.html 这可能是每一个jser都曾经为之头疼的却又非常经典的问题,关系到内存 ...
- Crontab设置定时任务
Crontab文件格式 文件格式: minute hour day month weekday username command 格式解析 字段 描述 minute 分,值为0-59 hour 小 ...
- Junit3.8
使用Junit的最佳实践:新建一个名为test的source folder,用于存放测试类源代码目标类与测试类应该位于同一个包下面,这样测试类中就不必导入源代码所在的包,因为他们位于同一个包下面 测试 ...
- [JS代码]如何判断ipad或者iphone是否为横屏或者竖屏 - portrait或者landscape
//判断横屏或者竖屏 function orient() { //alert('gete'); if (window.orientation == 0 || window.orientation == ...
- 如何学习java ee
来看看Sun给出的J2EE 相关技术主要分为几大块. 1. Web Service技术 - Java API for XML Processing (JAXP) - Java API for XM ...
- 使用CocoaPods管理依赖库
本篇内容将介绍Mac和iOS开发中必备的一个依赖库管理工具CocoaPods. CocoaPods是什么 在iOS开发中势必会用到一些第三方依赖库,比如大家都熟悉的ASIHttpRequest.AFN ...
- How to include cascading style sheets (CSS) in JSF
In JSF 2.0, you can use <h:outputStylesheet /> output a css file. For example, <h:outputSty ...