MySQL--索引条件下推优化
http://blog.163.com/li_hx/blog/static/1839914132015782821512/
一 什么是“索引条件下推”
“索引条件下推”,称为 Index Condition Pushdown (ICP),这是MySQL提供的用某一个索引对一个特定的表从表中获取元组”,注意我们这里特意强调了“一个”,这是因为这样的索引优化不是用于多表连接而是用于单表扫描,确切地说,是单表利用索引进行扫描以获取数据的一种方式。
二 “索引条件下推”的目的
用ySQL官方手册描述:
The goal of ICP is to reduce the number of full-record reads and thereby reduce IO operations. For InnoDB clustered indexes, the complete record is already read into the InnoDB buffer. Using ICP in this case does not reduce IO.
这句官方描述,一是说明减少完整记录(一条完整元组)读取的个数;二是说明对于InnoDB聚集索引无效,只能是对SECOND INDEX这样的非聚集索引有效。
三 原理
先看实例:
mysql> set optimizer_switch='index_condition_pushdown=off'; //关闭ICP
Query OK, 0 rows affected (0.00 sec)
mysql> EXPLAIN SELECT * FROM t4 WHERE 1=t4.a4 AND t4.name like 'char%';
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t4 | NULL | range | a4_i | a4_i | 28 | NULL | 1 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> set optimizer_switch='index_condition_pushdown=on'; //打开ICP,则Extra列中显示“Using index condition”
Query OK, 0 rows affected (0.00 sec)
mysql> EXPLAIN SELECT * FROM t4 WHERE 1=t4.a4 AND t4.name like 'char%';
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | t4 | NULL | range | a4_i | a4_i | 28 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
如果打开ICP,则执行计划的Extra列会显示“Using index condition”,这表明在。
借用网上的2张图加以改造,并配以解释,来说明原理,更清晰地说明问题。
图一:不使用ICP技术(过程使用数字符号标示,如①②③等)
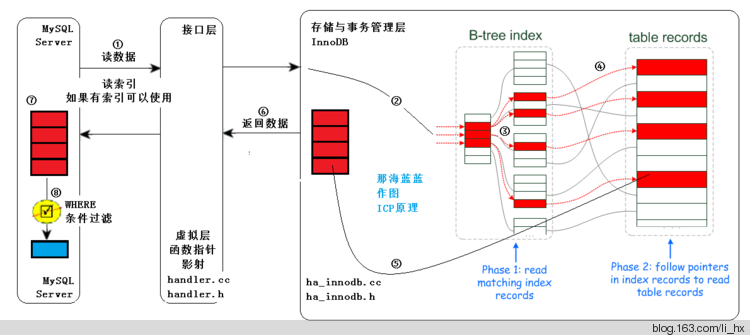
过程解释:
①:MySQL Server发出读取数据的命令,这是在执行器中执行如下代码段,通过函数指针和handle接口调用存储引擎的索引读或全表表读。此处进行的是索引读。
if (in_first_read)
{
in_first_read= false;
error= (*qep_tab->read_first_record)(qep_tab); //设定合适的读取函数,如设定索引读函数/全表扫描函数
}
else
error= info->read_record(info);
②、③:进入存储引擎,读取索引树,在索引树上查找,把满足条件的(经过查找,红色的满足)从表记录中读出(步骤④,通常有IO),从存储引擎返回⑤标识的结果。此处,不仅要在索引行进行索引读取(通常是内存中,速度快。步骤③),还要进行进行步骤④,通常有IO。
⑥:从存储引擎返回查找到的多条元组给MySQL Server,MySQL Server在⑦得到较多的元组。
⑦--⑧:⑦到⑧依据WHERE子句条件进行过滤,得到满足条件的元组。注意在MySQL Server层得到较多元组,然后才过滤,最终得到的是少量的、符合条件的元组。
图二:使用ICP技术(过程使用数字符号标示,如①②③等)
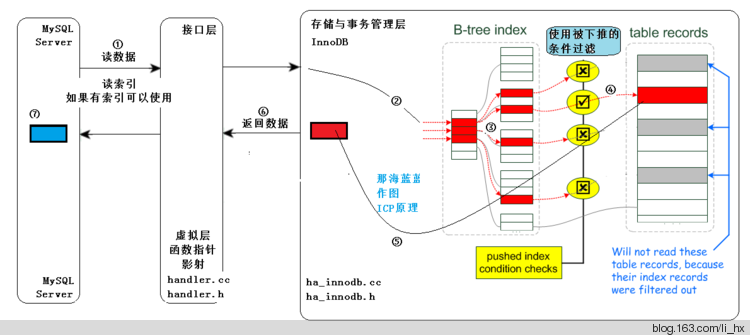
过程解释:
⑥:从存储引擎返回查找到的少量元组给MySQL Server,MySQL Server在⑦得到少量的元组。因此比较图一无ICP的方式,返回给MySQL Server层的即是少量的、符合条件的元组。
另外,图中的部件层次关系,不再进行解释。
四 实现细节
1 ICP只能用于辅助索引,不能用于聚集索引。
2 ICP只用于单表,不是多表连接是的连接条件部分(如开篇强调)
如果表访问的类型为:
3 EQ_REF/REF_OR_NULL/REF/SYSTEM/CONST: 可以使用ICP
4 range:如果不是“index tree only(只读索引)”,则有机会使用ICP
5 ALL/FT/INDEX_MERGE/INDEX_SCAN: 不可以使用ICP
五 上楼
1 条件下推,一直是SQL优化的基本规则。所以,条件下推技术是常规技术。数据库的优化器几乎不会不实现条件下推优化。
2 技术层面,MySQL存在MySQL Server层和储存层,使得条件下推显得“有些割裂”。
3 非技术层面,MySQL之所以引入ICP,猜一猜或拍拍脑袋,原因你懂得。
六 从代码的角度看
对于图一的解释,给出了读数据的代码片段,无论是关闭还是打开ICP, 从下面给出的函数调用关系可以看出,2幅图对应的情况下,代码路径是一致的.
首条元组读取调用关系(蓝色标识和非首条元组不同之处):
JOIN::exec()->do_select()->sub_select()->join_init_read_record()->rr_quick()->
QUICK_RANGE_SELECT::get_next()->ha_innobase::multi_range_read_next()->
DsMrr_impl::dsmrr_next()->handler::multi_range_read_next()->
handler::read_range_first()->handler::ha_index_read_map()->
handler::index_read_map()->ha_innobase::index_read()
除首条元组读取调用关系(蓝色标识和首条元组不同之处)
JOIN::exec()->do_select()->sub_select()->join_init_read_record()->rr_quick()->
QUICK_RANGE_SELECT::get_next()->ha_innobase::multi_range_read_next()->
DsMrr_impl::dsmrr_next()->handler::multi_range_read_next()->
handler::read_range_next()->handler::ha_index_next()->
ha_innobase::index_next()->ha_innobase::general_fetch()
MySQL--索引条件下推优化的更多相关文章
- 【mysql优化 2】索引条件下推优化
原文地址:Index Condition Pushdown Optimization 索引条件下推(ICP:index condition pushdown)是mysql中一个常用的优化,尤其是当my ...
- 浅析MySQL中的Index Condition Pushdown (ICP 索引条件下推)和Multi-Range Read(MRR 索引多范围查找)查询优化
本文出处:http://www.cnblogs.com/wy123/p/7374078.html(保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错误 ...
- MySQL 中Index Condition Pushdown (ICP 索引条件下推)和Multi-Range Read(MRR 索引多范围查找)查询优化
一.ICP优化原理 Index Condition Pushdown (ICP),也称为索引条件下推,体现在执行计划的上是会出现Using index condition(Extra列,当然Extra ...
- 8.2.1.5 Engine Condition Pushdown Optimization 引擎条件下推优化
8.2.1.5 Engine Condition Pushdown Optimization 引擎条件下推优化 这种优化改善了直接比较在一个非索引列和一个常量比较的效率. 在这种情况下, 条件是 下推 ...
- MySQL索引原理及优化
一.各种数据结构介绍 这一小节结合哈希表.完全平衡二叉树.B树以及B+树的优缺点来介绍为什么选择B+树. 假如有这么一张表(表名:sanguo): (1)Hash索引 对name字段建立哈希索引: 根 ...
- MySQL5.6之Index Condition Pushdown(ICP,索引条件下推)-Using index condition
http://blog.itpub.net/22664653/viewspace-1210844/ -- 这篇博客写的更细,以后看 ICP(index condition pushdown)是mysq ...
- mysql5.6新功能索引条件下推(转载)
原文地址:http://www.cnblogs.com/zengkefu/p/5684101.html 一什么是"索引条件下推" "索引条件下推",称为 Ind ...
- MySQL索引分析与优化
1.MySQL能够在name的索引中查找“Mike”值,然后直接转到数据文件中相应的行,准确地返回该行的 peopleid(999).在这个过程中,MySQL只需处理一个行就可以返回结果.如果没有“n ...
- Mysql 索引原理及优化
本文内容主要来源于互联网上主流文章,只是按照个人理解稍作整合,后面附有参考链接. 一.摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引 ...
随机推荐
- Linux下gdb使用整理记录
1.创建cpp文件:vim sourcefile.cpp 2.生成可执行文件:g++ -g sourcefile.cpp -o exename ------据说是要必须加上-g参数,否则不可调试 3. ...
- 使用RSA非对称密钥算法实现硬件设备授权
一.硬件设备授权 即用户在硬件设备输入一个序列号(或一个包含授权信息的文件),然后硬件设备便可正常使用. 二.授权方案 构思授权方案时,参考了下面网址的思路: http://bbs.csdn.n ...
- NServiceBus-性能测试
NServiceBus: 有效地处理一个消息 处理大量并发 尺度大小不同的服务器 尺度低规格的设备 的最终平衡速度和安全. 基准 许多参数会影响测量性能.最明显的是硬件服务器和CPU核的数量,大小的内 ...
- T-SQL 批处理
批处理简介 批处理是作为一个逻辑单元的T-SQL语句.如果一条语句不能通过语法分析,那么不会运行任何语句.如果一条语句在运行时失败,那么产生错误的语句之前的语句都已经运行了. 为了将一个脚本分为多个批 ...
- REST四种请求(get,delete,put,post) 收集整理 之一
转自:http://blog.csdn.net/cloudcraft/article/details/10087033 资源是REST中最关键的抽象概念,它们是能够被远程访问的应用程序对象.一个资源就 ...
- 如何让Java和C++接口互相调用:JNI使用指南
如何让Java和C++接口互相调用:JNI使用指南 转自:http://cn.cocos2d-x.org/article/index?type=cocos2d-x&url=/doc/cocos ...
- oracle学习 九 游标的使用(持续更)
为什么要使用? 笔者查阅了一些资料之后得到的结论是, 关系型数据库是面向集合的,而游标是面向行的,游标可对取出来的集合(结果集)中每一行进行相同或不同的操作,还提供对基于游标位置而对表中数据进行删除或 ...
- StringBuffer与StringBuilder的异同
一. 相同之处 1.均是可变字符序列,可以随机的改变字符串,如追加操作或插入操作 2. 均使用了内部缓冲区,并且当内部缓冲区溢出后均会自动增大 二. 不同之处 1. Stri ...
- [置顶] 小强的HTML5移动开发之路(9)——坦克大战游戏3
上一篇我们创建了敌人的坦克和自己的坦克,接下来就应该让坦克发子弹了,我们下面来看一下如何让我们的坦克发出子弹. 前面我们用面向对象的思想对Tank进行了封装,又利用对象冒充实现了我们的坦克和敌人的坦克 ...
- HDU 3696 Farm Game(dp+拓扑排序)
Farm Game Problem Description “Farm Game” is one of the most popular games in online community. In t ...