hashlib加密 logging日志 subprocess
Day23 hashlib加密 logging日志
- hahlib加密模块
- logging日志模块
- subprocess模块
1.hahlib加密模块
1.什么是加密?
将明文数据处理成密文数据的过程 让人无法看懂
2.为什么加密?
为保护隐私安全
3.任何判断数据是加密的?
由字母数字以及符号随机组合的一串字符串
4.密文的长短如何讲究?
密文越长说明安全系数越高使用的技术就越难越消耗资源
当然了密文的长度由项目的各项指标决定
密文不是越长越好适合最重要
5.常见的加密算法有那些?
MD5 sha系列 hmac base64
6.加密基本操作
import hashlib
# 1.选择加密算法
md5 = hashlib.md5()
# 2.传入明文数据
md5.update(b'hello')
# 3.获取加密密文
res = md5.hexdigest()
print(res) # 5d41402abc4b2a76b9719d911017c592
加密补充说明
1.加密算法不变内容就不变
内容如果相同,那么无论是一次性传还是分步传结果肯定也有
# md5.update(b'hello~world~python~666') # 一次性传可以
md5.update(b'hello') # 分多次传也可以
md5.update(b'~world') # 分多次传也可以
md5.update(b'~python~666') # 分多次传也可以
2.加密之后的结果不可能反解密的,
所谓的解密是后台工作人员一个一个的猜测结果
如果密码设置的难一点就解密不了,需要再次猜测
3.加盐处理
在明文里面添加一些额外的干扰项
# 1.选择加密算法
md5 = hashlib.md5()
# 2.传入明文数据
md5.update('公司设置的干扰项'.encode('utf8'))
md5.update(b'hello python') # 一次性传可以
# 3.获取加密密文
res = md5.hexdigest()
print(res) # e53024684c9be1dd3f6114ecc8bbdddc
4.动态加盐
干扰项是随机变化的
eg:当前时间、用户名部分...
5.加密实践操作
1.用户密码操作
2.文件安全性校验
3.文件内容一致性校验
4.大文件加密
2.subprocess模块
模拟操作系统终端 执行命令并获取结果
import subprocess
res = subprocess.Popen(
'asdas', # 操作系统要执行的命令
shell=True, # 固定配置
stdin=subprocess.PIPE, # 输入命令
stdout=subprocess.PIPE, # 输出结果
)
print('正确结果', res.stdout.read().decode('gbk')) # 获取操作系统执行命令之后的正确结果
print('错误结果', res.stderr) # 获取操作系统执行命令之后的错误结果
3.logging日志模块
1.如何理解日志
简单的理解为记录行为举止操作
2.日志的级别(5个级别)
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
3.日志模块的要求
代码无需会写,但是必须会CV
import logging
# logging.debug('debug message')
# logging.info('info message')
# logging.warning('warning message')
# logging.error('error message')
# logging.critical('critical message')
file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf8',)
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
handlers=[file_handler,],
level=logging.ERROR
)
logging.error('你好')
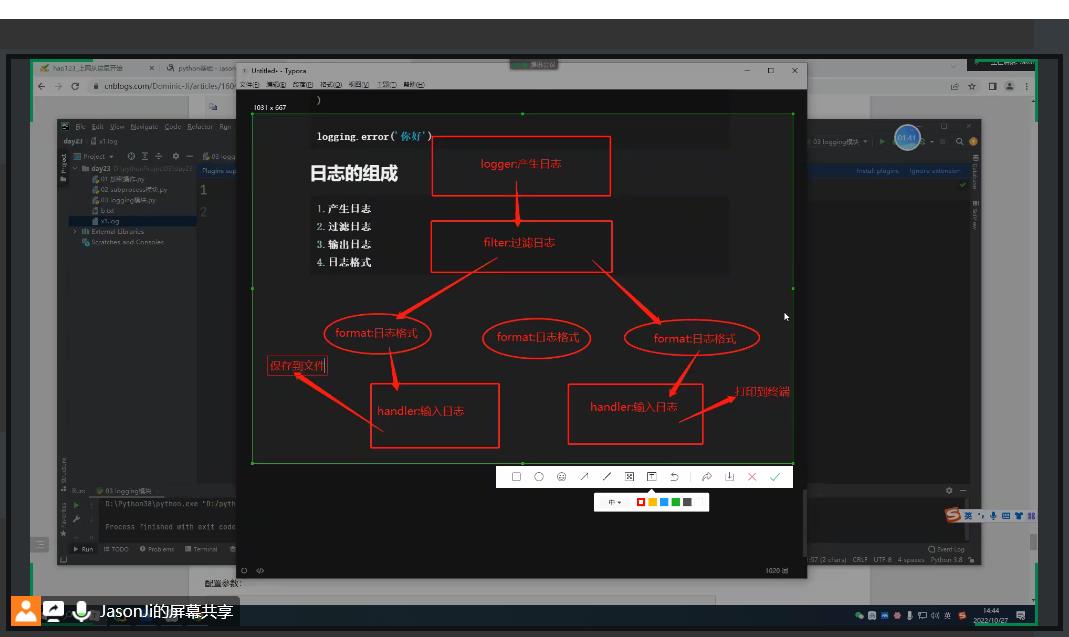
日志的组成
1.产生日志
2.过滤日志
(基本不用因为产生阶段就可以操作掉)
3.输出日志
4.日志格式
import logging
# 1.日志的产生(准备原材料) logger对象
logger = logging.getLogger('购物车记录')
# 2.日志的过滤(剔除不良品) filter对象>>>:可以忽略 不用使用
# 3.日志的产出(成品) handler对象
hd1 = logging.FileHandler('a1.log', encoding='utf-8') # 输出到文件中
hd2 = logging.FileHandler('a2.log', encoding='utf-8') # 输出到文件中
hd3 = logging.StreamHandler() # 输出到终端
# 4.日志的格式(包装) format对象
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
fm2 = logging.Formatter(
fmt='%(asctime)s - %(name)s: %(message)s',
datefmt='%Y-%m-%d',
)
# 5.给logger对象绑定handler对象
logger.addHandler(hd1)
logger.addHandler(hd2)
logger.addHandler(hd3)
# 6.给handler绑定formmate对象
hd1.setFormatter(fm1)
hd2.setFormatter(fm2)
hd3.setFormatter(fm1)
# 7.设置日志等级
logger.setLevel(10) # debug
# 8.记录日志
logger.debug('写了半天 好累啊 好热啊')
图片形式详解
日志配置字典
import logging
import logging.config
# 定义日志输出格式 开始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' # 其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
# 自定义文件路径
logfile_path = 'a3.log'
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
# 打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
# 打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
# logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
# '购物车记录': {
# 'handlers': ['default','console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
# 'level': 'WARNING',
# 'propagate': True, # 向上(更高level的logger)传递
# }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
},
}
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
# logger1 = logging.getLogger('购物车记录')
# logger1.warning('尊敬的VIP客户 晚上好 您又来啦')
# logger1 = logging.getLogger('注册记录')
# logger1.debug('jason注册成功')
logger1 = logging.getLogger('红浪漫顾客消费记录')
logger1.debug('慢男 猛男 骚男')
hashlib加密 logging日志 subprocess的更多相关文章
- python常用模块补充hashlib configparser logging,subprocess模块
一.hashlib模板 Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等. 什么是摘要算法呢?摘要算法又称哈希算法.散列算法.它通过一个函数,把任意长度的数据转换为一个长度固定 ...
- python hashlib模块 logging模块 subprocess模块
一 hashlib模块 import hashlib md5=hashlib.md5() #可以传参,加盐处理 print(md5) md5.update(b'alex') #update参数必须是b ...
- s14 第5天 时间模块 随机模块 String模块 shutil模块(文件操作) 文件压缩(zipfile和tarfile)shelve模块 XML模块 ConfigParser配置文件操作模块 hashlib散列模块 Subprocess模块(调用shell) logging模块 正则表达式模块 r字符串和转译
时间模块 time datatime time.clock(2.7) time.process_time(3.3) 测量处理器运算时间,不包括sleep时间 time.altzone 返回与UTC时间 ...
- logging日志模块,hashlib hash算法相关的库,
logging: 功能完善的日志模块 import logging #日志的级别 logging.debug("这是个调试信息")#级别10 #常规信息 logging.info( ...
- 约束、自定义异常、hashlib模块、logging日志模块
一.约束(重要***) 1.首先我们来说一下java和c#中的一些知识,学过java的人应该知道,java中除了有类和对象之外,还有接口类型,java规定,接口中不允许在方法内部写代码,只能约束继承它 ...
- hashlib加密模块、logging日志模块
hashlib模块 加密:将明文数据通过一系列算法变成密文数据 目的: 就是为了数据的安全 基本使用 基本使用 import hashlib # 1.先确定算法类型(md5普遍使用) md5 = ha ...
- 【转】python模块分析之logging日志(四)
[转]python模块分析之logging日志(四) python的logging模块是用来写日志的,是python的标准模块. 系列文章 python模块分析之random(一) python模块分 ...
- python模块分析之logging日志(四)
前言 python的logging模块是用来设置日志的,是python的标准模块. 系列文章 python模块分析之random(一) python模块分析之hashlib加密(二) python模块 ...
- 常用模块(hashlib,configparser,logging)
常用模块(hashlib,configparser,logging) hashlib hashlib 摘要算法的模块md5 sha1 sha256 sha512摘要的过程 不可逆能做的事:文件的一致性 ...
- 包,logging日志模块,copy深浅拷贝
一 包 package 包就是一个包含了 __init__.py文件的文件夹 包是模块的一种表现形式,包即模块 首次导入包: 先创建一个执行文件的名称空间 1.创建包下面的__init__.py文件的 ...
随机推荐
- 【项目实战】CNN手写识别
由于只需要修改之前基于ANN模型代码的模型设计部分所以篇幅较短,简单的加点注释给自己查看即可 视频链接:https://www.bilibili.com/video/BV1Y7411d7Ys?p=10 ...
- 15. 第十四篇 安装CoreDNS
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247483850&idx=1&sn=4bfdb26f ...
- X-Pack:创建阈值检查警报
简单的事情应该简单(Simple things should be simple),这是Elastic {ON} '17的主题之一,Elastics收到了许多关于使用简单易用的UI创建警报的请求.事实 ...
- PyCharm安装PyQt5及其工具(Qt Designer、PyUIC、PyRcc)详细教程
摘要:Qt是常用的用户界面设计工具,而在Python中则使用PyQt这一工具包,它是Python编程语言和Qt库的成功融合.这篇博文通过图文详细介绍在PyCharm中如何完整优雅地安装配置PyQt5的 ...
- 使用SqlDataReader对象从数据库中检索只读的数据。
SqlDataReader对象每次从查询结果中读取一行到内存中,对于sql数据库,如果只需要顺序读取,可以优先选择SqlDataReader,其对数据库的读取速度非常快. 调用SqlDataReade ...
- SpringBoot 自定义注解 实现多数据源
SpringBoot自定义注解实现多数据源 前置学习 需要了解 注解.Aop.SpringBoot整合Mybatis的使用. 数据准备 基础项目代码:https://gitee.com/J_look/ ...
- LeetCode------两数之和(3)【数组】
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/two-sum 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 ...
- 知识图谱顶刊综述 - (2021年4月) A Survey on Knowledge Graphs: Representation, Acquisition, and Applications
知识图谱综述(2021.4) 论文地址:A Survey on Knowledge Graphs: Representation, Acquisition, and Applications 目录 知 ...
- SpringCloud怎么迈向云原生?
很多公司由于历史原因,都会有自研的RPC框架. 尤其是在2015-2017期间,Spring Cloud刚刚面世,Dubbo停止维护多年,很多公司在设计自己的RPC框架时,都会基于Spring Clo ...
- 图文详解丨iOS App上架全流程及审核避坑指南
App Store作为苹果官方的应用商店,审核严格周期长一直让用户头疼不已,很多app都"死"在了审核这一关,那我们就要放弃iOS用户了吗?当然不是!本期我们从iOS app上架流 ...