Java synchronized那点事
前言
请看上篇:Java 对象头那点事
文章中的源码都有不同程度缩减,来源于openjdk8的开源代码(tag:jdk8-b120)。
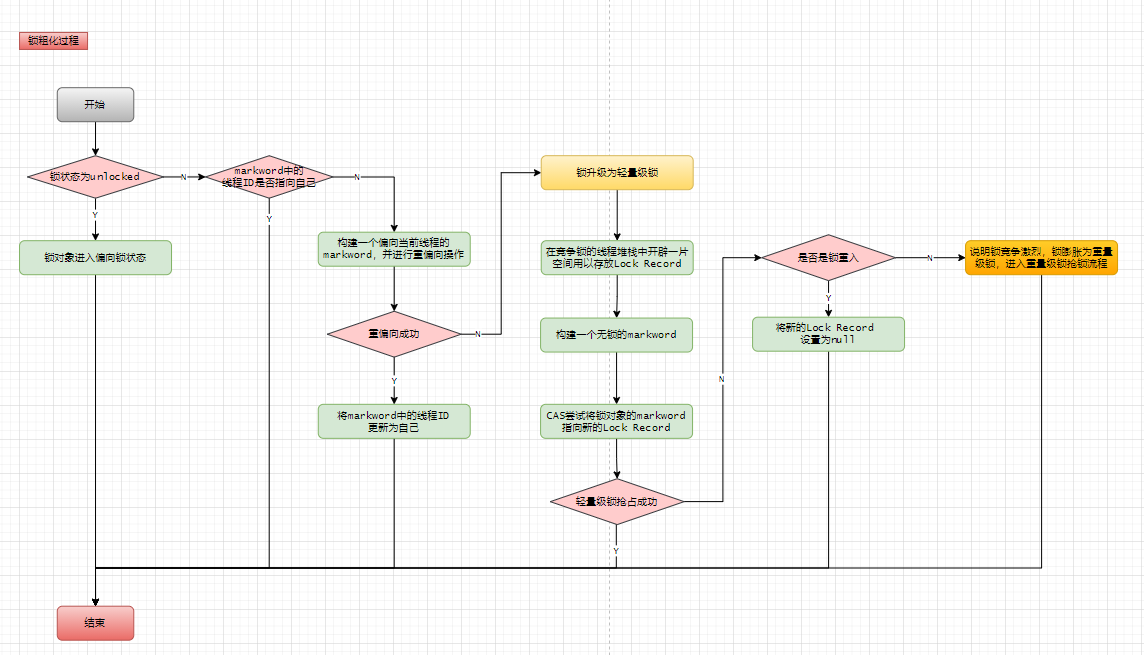
锁粗化过程
偏向锁
①:markword中保存的线程ID是自己且epoch等于class的epoch,则说明是偏向锁重入。
②:偏向锁若已禁用,进行撤销偏向锁。
③:偏向锁开启,都进行进行重偏向操作。
④:若进行了锁撤销操作或重偏向操作失败,则需要升级为轻量级锁或者进一步升级为重量级锁。
匿名偏向
锁对象在发送锁竞争后会升级为偏向锁,不过当不发生锁竞争时,锁对象依然会升级为偏向锁,这种情况叫匿名偏向。
当jvm启动4s后,会默认给新建的对象加上偏向锁。
上代码:
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.8</version>
</dependency>
这个包下的工具类的功能有:
// 查看对象内部结构
System.out.println(ClassLayout.parseInstance(bingo).toPrintable());
// 查看对象外部信息
System.out.println(GraphLayout.parseInstance(bingo).toPrintable());
// 查看对象总大小
System.out.println(GraphLayout.parseInstance(bingo).totalSize());
默认JVM是开启指针压缩,可以通过vm参数开启关闭指针压缩:-XX:-UseCompressedOops。
当创建锁对象前不进行休眠4s的操作:
@Test
public void mark() throws InterruptedException {
Bingo bingo = new Bingo();
bingo.setP(1);
bingo.setB(false);
// 查看对象内部结构
System.out.println(ClassLayout.parseInstance(bingo).toPrintable());
System.out.println("\n++++++++++++++++++++++++++\n");
synchronized (bingo) {
// 查看对象内部结构
System.out.println(ClassLayout.parseInstance(bingo).toPrintable());
}
}
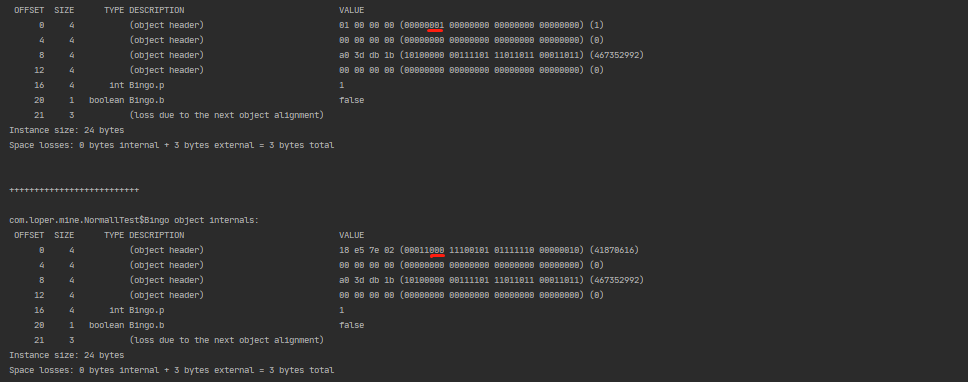
看我标红线的后三位的值,由于启动过快,锁直接从无锁升级成了轻量级锁。
当创建锁对象前进行休眠4s的操作:
@Test
public void mark() throws InterruptedException {
TimeUnit.SECONDS.sleep(4);
Bingo bingo = new Bingo();
bingo.setP(1);
bingo.setB(false);
// 查看对象内部结构
System.out.println(ClassLayout.parseInstance(bingo).toPrintable());
System.out.println("\n++++++++++++++++++++++++++\n");
synchronized (bingo) {
// 查看对象内部结构
System.out.println(ClassLayout.parseInstance(bingo).toPrintable());
}
}
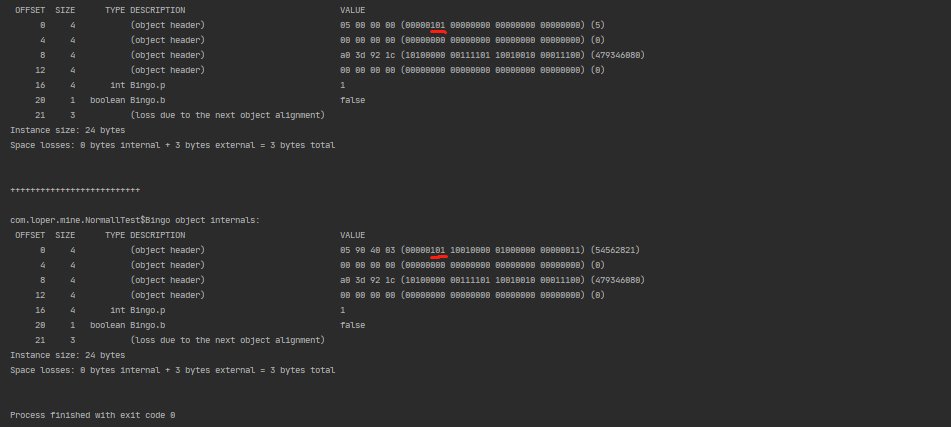
当在程序启动4s后创建锁对象,就会默认偏向。
重偏向
因为偏向锁不会自动释放,因此当锁对象处于偏向锁时,另一个线程进来只能依托VM判断上一个获取偏向锁的线程是否存活、是否退出持有锁来决定是锁升级还是进行重偏向。
锁撤销
①:偏向锁的撤销必须等待VM全局安全点(安全点指所有java线程都停在安全点,只有vm线程运行)。
②:撤销偏向锁恢复到无锁(标志位为 01)或轻量级锁(标志位为 00)的状态。
③:只要发生锁竞争,就会进行锁撤销。
备注:
当开启偏向锁时,若持有偏向锁的线程仍然存活且未退出同步代码块,锁升级为轻量级锁/重量级锁之前会进行偏向锁撤销操作。
如果是升级为轻量级锁,撤销之后需要创建Lock Record 来保存之前的markword信息。
批量偏向/撤销概念:
参考1:https://www.cnblogs.com/LemonFive/p/11248248.html
- 批量重偏向
当一个线程同时持有同一个类的多个对象的偏向锁时(这些对象的锁竞争不激烈),执行完同步代码块后,如果另一个线程也要持有这些对象的锁,当对象数量达到一定程度时,会触发批量重偏向机制(进行过批量重偏向的对象不可再进行批量重偏向)。 - 批量锁撤销
当触发批量重偏向后,会触发批量撤销机制。
阈值定义在globals.hpp中:
// 批量重偏向阈值
product(intx, BiasedLockingBulkRebiasThreshold, 20)
// 批量锁撤销阈值
product(intx, BiasedLockingBulkRevokeThreshold, 40)
可以在VM启动参数中通过-XX:BiasedLockingBulkRebiasThreshold 和 -XX:BiasedLockingBulkRevokeThreshold 来手动设置阈值。
偏向锁的撤销和重偏向的代码(过于复杂)在biasedLocking.cpp中:
void BiasedLocking::revoke_at_safepoint(Handle h_obj) {
assert(SafepointSynchronize::is_at_safepoint(), "must only be called while at safepoint");
oop obj = h_obj();
HeuristicsResult heuristics = update_heuristics(obj, false);
if (heuristics == HR_SINGLE_REVOKE) {
// 重偏向
revoke_bias(obj, false, false, NULL);
} else if ((heuristics == HR_BULK_REBIAS) ||
(heuristics == HR_BULK_REVOKE)) {
// 批量撤销或重偏向
bulk_revoke_or_rebias_at_safepoint(obj, (heuristics == HR_BULK_REBIAS), false, NULL);
}
clean_up_cached_monitor_info();
}
参考2:
对于存在明显多线程竞争的场景下使用偏向锁是不合适的,比如生产者-消费者队列。生产者线程获得了偏向锁,消费者线程再去获得锁的时候,就涉及到这个偏向锁的撤销(revoke)操作,而这个撤销是比较昂贵的。那么怎么判断这些对象是否适合偏向锁呢?jvm采用以类为单位的做法,其内部为每个类维护一个偏向锁计数器,对其对象进行偏向锁的撤销操作进行计数。当这个值达到指定阈值的时候,jvm就认为这个类的偏向锁有问题,需要进行重偏向(rebias)。对所有属于这个类的对象进行重偏向的操作叫批量重偏向(bulk rebias),之前的做法是对heap进行遍历,后来引入epoch。当需要bulk rebias时,对这个类的epoch值加1,以后分配这个类的对象的时候mark字段里就是这个epoch值了,同时还要对当前已经获得偏向锁的对象的epoch值加1,这些锁数据记录在方法栈里。这样判断这个对象是否获得偏向锁的条件就是:mark字段后3位是101,thread字段跟当前线程相同,epoch字段跟所属类的epoch值相同。如果epoch值不一样,即使thread字段指向当前线程,也是无效的,相当于进行过了rebias,只是没有对对象的mark字段进行更新。如果这个类的revoke计数器继续增加到一个阈值,那个jvm就认为这个类不适合偏向锁了,就要进行bulk revoke。于是多了一个判断条件,要查看所属类的字段,看看是否允许对这个类使用偏向锁。
轻量级锁
轻量级体现在线程会尝试在自己的堆栈中创建Lock Record存储锁对象的相关信息,不需要在内核态和用户态之间进行切换,不需要操作系统进行调度。
加锁
拿到轻量级锁线程堆栈:
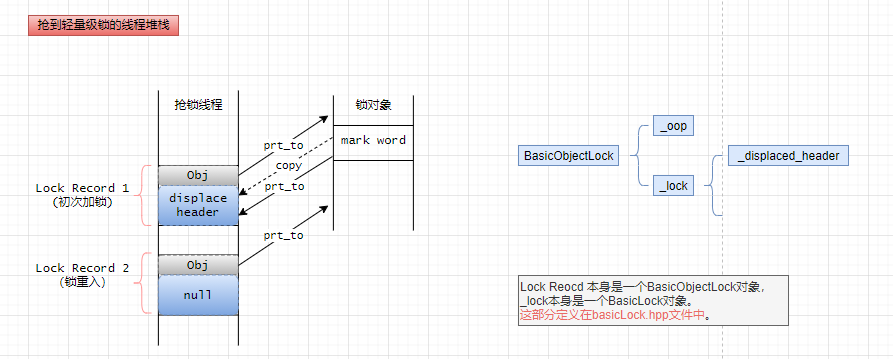
Lock Record主要分为两部分:
- obj
指向锁对象本身。重入时也如此。 - displaced header(缩写为hdr)
第一次拿到锁时hdr存放的是encode加密后的markword,重入时存放null。
思考:为什么锁重入时hdr存放的是null,而不是用计数器来实现呢?
假设一个场景,当一个线程同时拿到A、B、C...N 多个锁的时候,那么线程的堆栈中,肯定有多个锁对象的Lock Record,
如:
synchronized(a){
synchronized(b){
synchronized(c){
// do something
synchronized(a){
// do something
}
}
}
}
当锁a重入时,如果用计数器,还得遍历当前线程堆栈拿到第一次的Lock Record,解锁时也要遍历,效率必然低下。作为jdk底层代码必然讲究效率。
以上纯属个人看法(欢迎交流)。
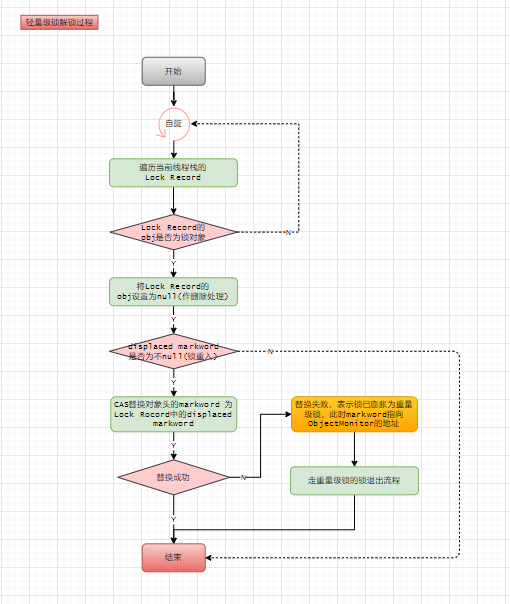
解锁
①:使用遍历方式将当前线程堆栈中属于该锁对象的Lock Record 指向Null。
②:CAS还原markword为无锁状态。
③:第②步失败需要升级为重量级锁。
优缺点
优点
在线程接替/交替执行的情况下,锁竞争比较小,可以避免成为重量级锁而引起的性能问题。缺点
当锁竞争比较激烈、多线程同事竞争锁的时候,需要从轻量级升级为重量级,产生了额外的开销。
源码分析
加锁
加锁、解锁流程的代码在InterpreterRuntime.cpp中。
这是我从github拉下来的源码:
/**
* (轻量级锁)加锁流程
* */
CASE(_monitorenter): {
// (锁对象本身)
oop lockee = STACK_OBJECT(-1);
// derefing's lockee ought to provoke implicit null check
CHECK_NULL(lockee);
// find a free monitor or one already allocated for this object
// if we find a matching object then we need a new monitor
// since this is recursive enter
BasicObjectLock* limit = istate->monitor_base();
BasicObjectLock* most_recent = (BasicObjectLock*) istate->stack_base();
// (这个entry就是大家常说的Lock Record吧)
BasicObjectLock* entry = NULL;
while (most_recent != limit ) {
if (most_recent->obj() == NULL) entry = most_recent;
else if (most_recent->obj() == lockee) break;
most_recent++;
}
if (entry != NULL) {
entry->set_obj(lockee);
// (构建一个无锁状态的mark word)
markOop displaced = lockee->mark()->set_unlocked();
// (放到lock record 中)
entry->lock()->set_displaced_header(displaced);
// 锁对象的markword是否为这个无锁的displaced markword
// (CAS替换失败说明锁对象的markword 不是无所状态)
if (Atomic::cmpxchg_ptr(entry, lockee->mark_addr(), displaced) != displaced) {
// Is it simple recursive case?
// (判断是否是锁重入)
if (THREAD->is_lock_owned((address) displaced->clear_lock_bits())) {
// (如果是重入场景,那么新的Lock Record 设置为Null)
entry->lock()->set_displaced_header(NULL);
} else {
// (不是锁重入,且抢锁失败,说明锁竞争激烈,升级为重量级。进入重量级锁抢锁流程)
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
}
UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);
} else {
istate->set_msg(more_monitors);
UPDATE_PC_AND_RETURN(0); // Re-execute
}
}
可以看得出来,这部分代码并没有体现出偏向锁的逻辑,有大佬给出原因,可以参考这篇博客:https://www.jianshu.com/p/4758852cbff4
其他大佬解析后的代码:
点击查看代码
CASE(_monitorenter): {
// lockee 就是锁对象
oop lockee = STACK_OBJECT(-1);
// derefing's lockee ought to provoke implicit null check
CHECK_NULL(lockee);
// code 1:找到一个空闲的Lock Record
BasicObjectLock* limit = istate->monitor_base();
BasicObjectLock* most_recent = (BasicObjectLock*) istate->stack_base();
BasicObjectLock* entry = NULL;
while (most_recent != limit ) {
if (most_recent->obj() == NULL) entry = most_recent;
else if (most_recent->obj() == lockee) break;
most_recent++;
}
//entry不为null,代表还有空闲的Lock Record
if (entry != NULL) {
// code 2:将Lock Record的obj指针指向锁对象
entry->set_obj(lockee);
int success = false;
uintptr_t epoch_mask_in_place = (uintptr_t)markOopDesc::epoch_mask_in_place;
// markoop即对象头的mark word
markOop mark = lockee->mark();
intptr_t hash = (intptr_t) markOopDesc::no_hash;
// code 3:如果锁对象的mark word的状态是偏向模式
if (mark->has_bias_pattern()) {
uintptr_t thread_ident;
uintptr_t anticipated_bias_locking_value;
thread_ident = (uintptr_t)istate->thread();
// code 4:这里有几步操作,下文分析
anticipated_bias_locking_value =
(((uintptr_t)lockee->klass()->prototype_header() | thread_ident) ^ (uintptr_t)mark) &
~((uintptr_t) markOopDesc::age_mask_in_place);
// code 5:如果偏向的线程是自己且epoch等于class的epoch
if (anticipated_bias_locking_value == 0) {
// already biased towards this thread, nothing to do
if (PrintBiasedLockingStatistics) {
(* BiasedLocking::biased_lock_entry_count_addr())++;
}
success = true;
}
// code 6:如果偏向模式关闭,则尝试撤销偏向锁
else if ((anticipated_bias_locking_value & markOopDesc::biased_lock_mask_in_place) != 0) {
markOop header = lockee->klass()->prototype_header();
if (hash != markOopDesc::no_hash) {
header = header->copy_set_hash(hash);
}
// 利用CAS操作将mark word替换为class中的mark word
if (Atomic::cmpxchg_ptr(header, lockee->mark_addr(), mark) == mark) {
if (PrintBiasedLockingStatistics)
(*BiasedLocking::revoked_lock_entry_count_addr())++;
}
}
// code 7:如果epoch不等于class中的epoch,则尝试重偏向
else if ((anticipated_bias_locking_value & epoch_mask_in_place) !=0) {
// 构造一个偏向当前线程的mark word
markOop new_header = (markOop) ( (intptr_t) lockee->klass()->prototype_header() | thread_ident);
if (hash != markOopDesc::no_hash) {
new_header = new_header->copy_set_hash(hash);
}
// CAS替换对象头的mark word
if (Atomic::cmpxchg_ptr((void*)new_header, lockee->mark_addr(), mark) == mark) {
if (PrintBiasedLockingStatistics)
(* BiasedLocking::rebiased_lock_entry_count_addr())++;
}
else {
// 重偏向失败,代表存在多线程竞争,则调用monitorenter方法进行锁升级
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
success = true;
}
else {
// 走到这里说明当前要么偏向别的线程,要么是匿名偏向(即没有偏向任何线程)
// code 8:下面构建一个匿名偏向的mark word,尝试用CAS指令替换掉锁对象的mark word
markOop header = (markOop) ((uintptr_t) mark & ((uintptr_t)markOopDesc::biased_lock_mask_in_place |(uintptr_t)markOopDesc::age_mask_in_place |epoch_mask_in_place));
if (hash != markOopDesc::no_hash) {
header = header->copy_set_hash(hash);
}
markOop new_header = (markOop) ((uintptr_t) header | thread_ident);
// debugging hint
DEBUG_ONLY(entry->lock()->set_displaced_header((markOop) (uintptr_t) 0xdeaddead);)
if (Atomic::cmpxchg_ptr((void*)new_header, lockee->mark_addr(), header) == header) {
// CAS修改成功
if (PrintBiasedLockingStatistics)
(* BiasedLocking::anonymously_biased_lock_entry_count_addr())++;
}
else {
// 如果修改失败说明存在多线程竞争,所以进入monitorenter方法
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
success = true;
}
}
// 如果偏向线程不是当前线程或没有开启偏向模式等原因都会导致success==false
if (!success) {
// 轻量级锁的逻辑
//code 9: 构造一个无锁状态的Displaced Mark Word,并将Lock Record的lock指向它
markOop displaced = lockee->mark()->set_unlocked();
entry->lock()->set_displaced_header(displaced);
//如果指定了-XX:+UseHeavyMonitors,则call_vm=true,代表禁用偏向锁和轻量级锁
bool call_vm = UseHeavyMonitors;
// 利用CAS将对象头的mark word替换为指向Lock Record的指针
if (call_vm || Atomic::cmpxchg_ptr(entry, lockee->mark_addr(), displaced) != displaced) {
// 判断是不是锁重入
if (!call_vm && THREAD->is_lock_owned((address) displaced->clear_lock_bits())) {
//code 10: 如果是锁重入,则直接将Displaced Mark Word设置为null
entry->lock()->set_displaced_header(NULL);
} else {
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
}
}
UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);
} else {
// lock record不够,重新执行
istate->set_msg(more_monitors);
UPDATE_PC_AND_RETURN(0); // Re-execute
}
}
解锁
/**
* (轻量级锁)解锁流程
* */
CASE(_monitorexit): {
oop lockee = STACK_OBJECT(-1);
CHECK_NULL(lockee);
BasicObjectLock* limit = istate->monitor_base();
BasicObjectLock* most_recent = (BasicObjectLock*) istate->stack_base();
// (挨个遍历当前线程栈中的Lock Record)
while (most_recent != limit ) {
// (Lock Record 的obj是否是需解锁的锁对象)
if ((most_recent)->obj() == lockee) {
BasicLock* lock = most_recent->lock();
markOop header = lock->displaced_header();
// (将obj设置为null(作删除处理))
most_recent->set_obj(NULL);
// If it isn't recursive we either must swap old header or call the runtime
if (header != NULL) {
// (非重入,CAS替换对象头的markword 为Lock Rocord中的displaced markword)
if (Atomic::cmpxchg_ptr(header, lockee->mark_addr(), lock) != lock) {
// restore object for the slow case
// (替换失败,表示锁已膨胀为重量级锁,此时markword指向ObjectMonitor的地址)
most_recent->set_obj(lockee);
// (走重量级锁的锁退出流程)
CALL_VM(InterpreterRuntime::monitorexit(THREAD, most_recent), handle_exception);
}
}
UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);
}
most_recent++;
}
// Need to throw illegal monitor state exception
CALL_VM(InterpreterRuntime::throw_illegal_monitor_state_exception(THREAD), handle_exception);
ShouldNotReachHere();
}
重量级锁
重量级锁是基于monitor模型进行实现的。
重量级锁是如何体现重量级的?
①:需要创建monitor,包含阻塞队列、竞争队列、继承者、锁拥有者等大量数据,会占用大量内存。
②:需要调用操作系统对线程进行park、unpark操作,会涉及到cpu在用户态和内核态之间切换,开销大。
③:monitor所运行的VM线程(内核线程)需要操作系统将那些调度,耗费时间。
monitor的初始化
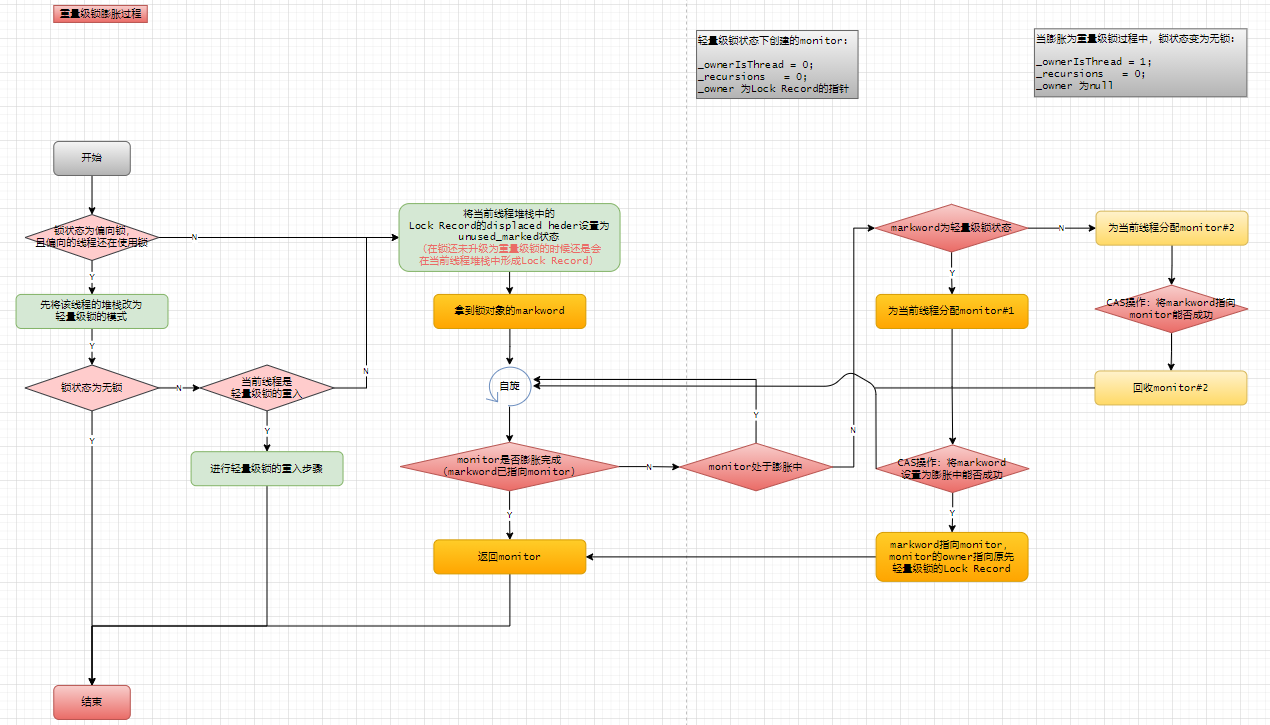
①:monitor并不是一下子初始化完成的。
②:monitor在初始化的过程中,如果有线程进来获取锁,则会进行自旋。
③:线程进入monitor后会被封装成一个ObjectWaiter(双向链表结构),然后park住当前线程。当有线程退出锁后会进行unpark操作(唤醒操作涉及到操作系统,会产生额外的开销)。
ObjectWaiter的结构:
class ObjectWaiter : public StackObj {
// ...
ObjectWaiter * volatile _next;
ObjectWaiter * volatile _prev;
Thread* _thread;
// ...
};
monitor的组成
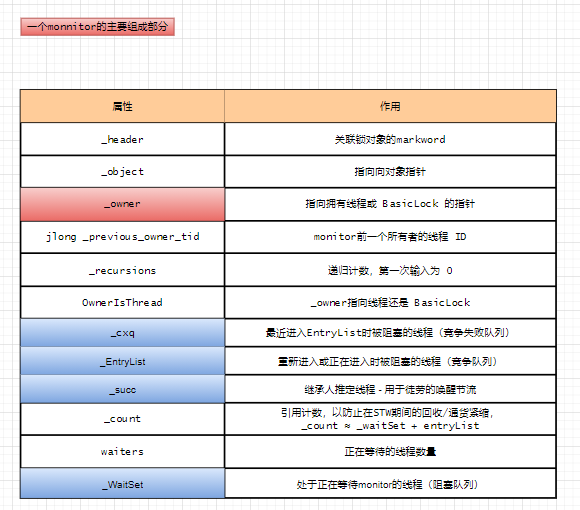
volatile markOop _header; // displaced object header word - mark
void* volatile _object; // backward object pointer - strong root
void * volatile _owner; // pointer to owning thread OR BasicLock
volatile jlong _previous_owner_tid; // thread id of the previous owner of the monitor
volatile intptr_t _recursions; // recursion count, 0 for first entry
int OwnerIsThread ; // _owner is (Thread *) vs SP/BasicLock
ObjectWaiter * volatile _cxq ; // LL of recently-arrived threads blocked on entry.
ObjectWaiter * volatile _EntryList ; // Threads blocked on entry or reentry.
Thread * volatile _succ ; // Heir presumptive thread - used for futile wakeup throttling
volatile intptr_t _count;
volatile intptr_t _waiters; // number of waiting threads
ObjectWaiter * volatile _WaitSet; // LL of threads wait()ing on the monitor
monitor的工作流程
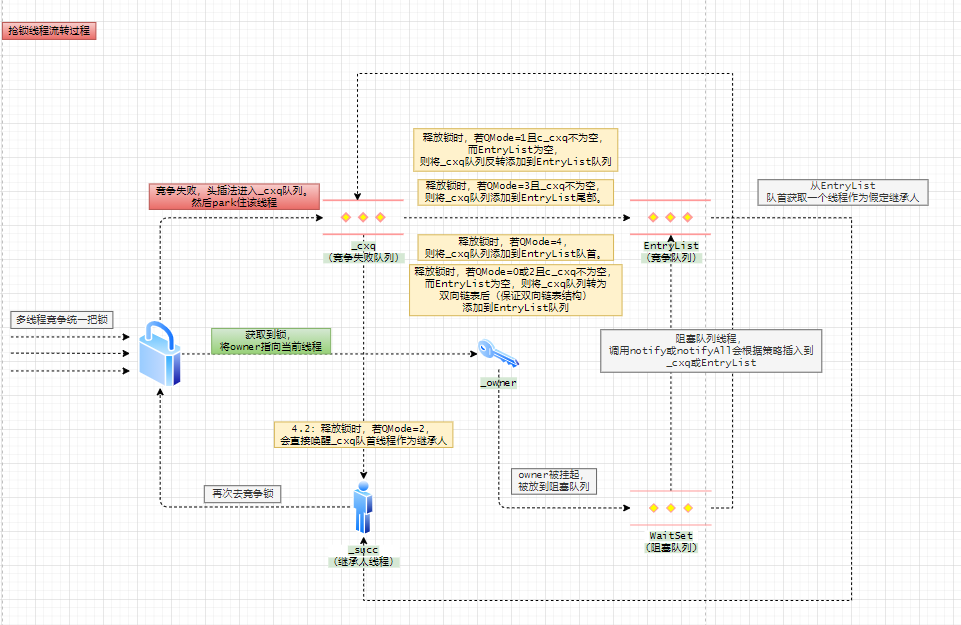
阻塞队列中的线程进入_cxq、_EntryList队列的过程有着不同的策略:
- policy == 0,头插_EntryList
- policy == 1,尾插_EntryList
- policy == 2,头插_cxq
- policy == 3,尾插_cxq
源码分析
加锁第一阶段
这部分代码并没有创建monitor。
大部分工作是对锁状态做判断、安全点的检查,考虑无锁、轻量级锁的重入情况,因为锁升级为重量级锁就直接进内核态了,消耗资源太多。
InterpreterRuntime.cpp#monitorenter源码:
IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem))
#ifdef ASSERT
thread->last_frame().interpreter_frame_verify_monitor(elem);
#endif
if (PrintBiasedLockingStatistics) {
Atomic::inc(BiasedLocking::slow_path_entry_count_addr());
}
Handle h_obj(thread, elem->obj());
assert(Universe::heap()->is_in_reserved_or_null(h_obj()),
"must be NULL or an object");
// 开启偏向锁
if (UseBiasedLocking) {
// Retry fast entry if bias is revoked to avoid unnecessary inflation
ObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK);
} else {
ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK);
}
assert(Universe::heap()->is_in_reserved_or_null(elem->obj()),
"must be NULL or an object");
#ifdef ASSERT
thread->last_frame().interpreter_frame_verify_monitor(elem);
#endif
IRT_END
主要还是看ObjectSynchronizer::fast_enter、ObjectSynchronizer::slow_enter,这部分源码在synchronizer.cpp中。
void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock, bool attempt_rebias, TRAPS) {
// 开启偏向锁
if (UseBiasedLocking) {
if (!SafepointSynchronize::is_at_safepoint()) {
// 不在安全点(安全点指所有java线程都停在安全点,只有vm线程运行),需要撤销并重偏向
BiasedLocking::Condition cond = BiasedLocking::revoke_and_rebias(obj, attempt_rebias, THREAD);
if (cond == BiasedLocking::BIAS_REVOKED_AND_REBIASED) {
return;
}
} else {
assert(!attempt_rebias, "can not rebias toward VM thread");
// 在安全点进行偏向锁的撤销
BiasedLocking::revoke_at_safepoint(obj);
}
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
}
// 上述操作是要保证在进入重量级锁之前锁状态应该处于轻量级锁
slow_enter (obj, lock, THREAD) ;
}
/**
* slow enter
* 主要对锁状态做判断,考虑无锁、轻量级锁的重入情况,因为锁升级为重量级锁就直接进内核态了,消耗资源太多。
* */
void ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) {
markOop mark = obj->mark();
assert(!mark->has_bias_pattern(), "should not see bias pattern here");
// (mark word是无锁状态)
if (mark->is_neutral()) {
lock->set_displaced_header(mark);
if (mark == (markOop) Atomic::cmpxchg_ptr(lock, obj()->mark_addr(), mark)) {
TEVENT (slow_enter: release stacklock) ;
return ;
}
} else
// (如果是锁重入)
if (mark->has_locker() && THREAD->is_lock_owned((address)mark->locker())) {
assert(lock != mark->locker(), "must not re-lock the same lock");
assert(lock != (BasicLock*)obj->mark(), "don't relock with same BasicLock");
lock->set_displaced_header(NULL);
return;
}
// markword的值设置为值为marked_value的markword(不能看起来无锁,也不能看起来像持有偏向锁、轻量级锁的情况)
lock->set_displaced_header(markOopDesc::unused_mark());
// 膨胀为重量级锁,enter方法后面进入重量级锁的抢占流程
ObjectSynchronizer::inflate(THREAD, obj())->enter(THREAD);
}
如果是进入fast_enter(),那么就会再进行一次偏向锁开启的判断,再进入slow_enter()的逻辑中去,那么为什么不开始就直接进行slow_enter呢?就为了判断下锁偏向和撤销吗?这部分逻辑也完全可以写到slow_enter中去。这么写的原因未知。
加锁第二阶段
形成monitor,用来调度竞争锁的线程。
先看锁的膨胀过程:
ObjectMonitor * ATTR ObjectSynchronizer::inflate (Thread * Self, oop object) {
// 自旋
for (;;) {
const markOop mark = object->mark() ;
assert (!mark->has_bias_pattern(), "invariant") ;
// The mark can be in one of the following states:
// * Inflated - just return(膨胀完成,直接返回)
// * Stack-locked - coerce it to inflated(轻量级加锁状态)
// * INFLATING - busy wait for conversion to complete(膨胀中)
// * Neutral - aggressively inflate the object.(无锁状态)
// * BIASED - Illegal. We should never see this()(偏向锁,非法,这里不能出现)
// CASE: inflated
if (mark->has_monitor()) {
ObjectMonitor * inf = mark->monitor() ;
assert (inf->header()->is_neutral(), "invariant");
assert (inf->object() == object, "invariant") ;
assert (ObjectSynchronizer::verify_objmon_isinpool(inf), "monitor is invalid");
return inf ;
}
// 膨胀中,进行下一轮自旋
if (mark == markOopDesc::INFLATING()) {
TEVENT (Inflate: spin while INFLATING) ;
ReadStableMark(object) ;
continue ;
}
// 轻量级锁状态
if (mark->has_locker()) {
// 为当前线程分配一个monitor
ObjectMonitor * m = omAlloc (Self) ;
m->Recycle();
m->_Responsible = NULL ;
m->OwnerIsThread = 0 ;
m->_recursions = 0 ;
m->_SpinDuration = ObjectMonitor::Knob_SpinLimit ; // Consider: maintain by type/class
// CAS操作:尝试将markword设置为INFLATING状态,失败进行下一轮自旋
markOop cmp = (markOop) Atomic::cmpxchg_ptr (markOopDesc::INFLATING(), object->mark_addr(), mark) ;
if (cmp != mark) {
omRelease (Self, m, true) ;
continue ; // Interference -- just retry
}
markOop dmw = mark->displaced_mark_helper() ;
assert (dmw->is_neutral(), "invariant") ;
m->set_header(dmw) ;
m->set_owner(mark->locker());
m->set_object(object);
guarantee (object->mark() == markOopDesc::INFLATING(), "invariant") ;
object->release_set_mark(markOopDesc::encode(m));
if (ObjectMonitor::_sync_Inflations != NULL) ObjectMonitor::_sync_Inflations->inc() ;
TEVENT(Inflate: overwrite stacklock) ;
if (TraceMonitorInflation) {
if (object->is_instance()) {
ResourceMark rm;
tty->print_cr("Inflating object " INTPTR_FORMAT " , mark " INTPTR_FORMAT " , type %s",
(void *) object, (intptr_t) object->mark(),
object->klass()->external_name());
}
}
return m ;
}
/**
* 走到这里说明1:monitor 未膨胀完成 2:monitor不在膨胀过程中 3:锁状态也不是轻量级状态
* 能走到这里说明锁状态已经变为无锁状态了
*/
assert (mark->is_neutral(), "invariant");
ObjectMonitor * m = omAlloc (Self) ;
m->Recycle();
m->set_header(mark);
m->set_owner(NULL);
m->set_object(object);
m->OwnerIsThread = 1 ;
m->_recursions = 0 ;
m->_Responsible = NULL ;
m->_SpinDuration = ObjectMonitor::Knob_SpinLimit ; // consider: keep metastats by type/class
// (省略部分代码)
return m ;
}
}
ObjectSynchronizer::omAlloc的作用:
尝试从线程的本地omFreeList 分配。线程将首先尝试从其本地列表中分配,然后从全局列表中,只有在那些尝试失败后,线程才会尝试实例化新的监视器。线程本地空闲列表占用 加热 ListLock 并改善分配延迟,并减少共享全局列表上的一致性流量。
总之我也没看懂,大概就是分配一个monitor给该线程用...
加锁第三阶段
当monitor形成之后,线程是阻塞还是拿到锁执行同步块代码,就看线程自己的运气了。
线程进入monitor:
void ATTR ObjectMonitor::EnterI (TRAPS) {
// 省略部分代码...
// 尝试获取锁
if (TryLock (Self) > 0) {
return ;
}
DeferredInitialize () ;
// 不死心,再来一次
if (TrySpin (Self) > 0) {
return ;
}
ObjectWaiter node(Self) ;
Self->_ParkEvent->reset() ;
node._prev = (ObjectWaiter *) 0xBAD ;
node.TState = ObjectWaiter::TS_CXQ ;
ObjectWaiter * nxt ;
for (;;) {
// 头插_cxq
node._next = nxt = _cxq ;
if (Atomic::cmpxchg_ptr (&node, &_cxq, nxt) == nxt) break ;
// 还来?
if (TryLock (Self) > 0) {
return ;
}
}
// 省略部分代码...
for (;;) {
if (TryLock (Self) > 0) break ;
assert (_owner != Self, "invariant") ;
if ((SyncFlags & 2) && _Responsible == NULL) {
Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;
}
// park self
if (_Responsible == Self || (SyncFlags & 1)) {
TEVENT (Inflated enter - park TIMED) ;
Self->_ParkEvent->park ((jlong) RecheckInterval) ;
// Increase the RecheckInterval, but clamp the value.
RecheckInterval *= 8 ;
if (RecheckInterval > 1000) RecheckInterval = 1000 ;
} else {
TEVENT (Inflated enter - park UNTIMED) ;
Self->_ParkEvent->park() ;
}
// 唤醒后又可以进行抢锁啦~
if (TryLock(Self) > 0) break ;
// 省略部分代码...
}
return ;
}
果然synchronized不是公平锁,不过这也太不公平了。
解锁第一阶段
owner在退出持有锁的时候,会根据monitor的QMode策略,决定继承者的选取方式,选定继承者之前owner仍然会持有锁,以保证并行性。
void ATTR ObjectMonitor::exit(bool not_suspended, TRAPS) {
// 省略部分代码...
// 重入次数递减至0
if (_recursions != 0) {
_recursions--; // this is simple recursive enter
TEVENT (Inflated exit - recursive) ;
return ;
}
if ((SyncFlags & 4) == 0) {
_Responsible = NULL ;
}
// 自旋
for (;;) {
// (...) 省略部分代码
ObjectWaiter * w = NULL ;
int QMode = Knob_QMode ;
// 绕过EntryList,直接从_cxq中唤醒线程作为下一个继承者用于竞争锁
if (QMode == 2 && _cxq != NULL) {
w = _cxq ;
assert (w != NULL, "invariant") ;
assert (w->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
ExitEpilog (Self, w) ;
return ;
}
// 将_cxq队列中的线程移到_EntryList尾部
if (QMode == 3 && _cxq != NULL) {
w = _cxq ;
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
assert (w != NULL , "invariant") ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
ObjectWaiter * Tail ;
for (Tail = _EntryList ; Tail != NULL && Tail->_next != NULL ; Tail = Tail->_next) ;
if (Tail == NULL) {
_EntryList = w ;
} else {
// _EntryList 的tail的next执行_cxq的头部
Tail->_next = w ;
w->_prev = Tail ;
}
}
// 将_cxq队列中的线程移到_EntryList头部
if (QMode == 4 && _cxq != NULL) {
// 如此可以保证最近竞争锁线程处于_EntryList的头部
w = _cxq ;
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
assert (w != NULL , "invariant") ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
// 此时q为_cxq对了的tail线程
if (_EntryList != NULL) {
q->_next = _EntryList ;
_EntryList->_prev = q ;
}
_EntryList = w ;
}
// 若_EntryList不为空,QMode = 3 || QMode = 4 会唤醒_EntryList头部线程作为下一位继承者,并进行unpark操作
w = _EntryList ;
if (w != NULL) {
assert (w->TState == ObjectWaiter::TS_ENTER, "invariant") ;
ExitEpilog (Self, w) ;
return ;
}
w = _cxq ;
if (w == NULL) continue ;
/*
* 能走到这里说明在这步采用线程进入_cxq队列,前面的操作中_cxq和_EntryList都是空队列
*/
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
TEVENT (Inflated exit - drain cxq into EntryList) ;
assert (w != NULL , "invariant") ;
assert (_EntryList == NULL , "invariant") ;
if (QMode == 1) {
ObjectWaiter * s = NULL ;
ObjectWaiter * t = w ;
ObjectWaiter * u = NULL ;
// 将_cxq队列反转,s为反转之后的_cxq
while (t != NULL) {
guarantee (t->TState == ObjectWaiter::TS_CXQ, "invariant") ;
t->TState = ObjectWaiter::TS_ENTER ;
u = t->_next ;
t->_prev = u ;
t->_next = s ;
s = t;
t = u ;
}
// 将反转倒序之后的_cxq放进_EntryList中
_EntryList = s ;
assert (s != NULL, "invariant") ;
} else {
// QMode == 0 or QMode == 2
_EntryList = w ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
// 将_cxq由单向链表转为双向链表
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
}
if (_succ != NULL) continue;
w = _EntryList ;
if (w != NULL) {
guarantee (w->TState == ObjectWaiter::TS_ENTER, "invariant") ;
ExitEpilog (Self, w) ;
return ;
}
}
}
解锁第二阶段
唤醒继承者,让它去尝试获取锁。
// 选取继承者、唤醒继承者队列的头部线程(代码就不看了):
void ObjectMonitor::ExitEpilog (Thread * Self, ObjectWaiter * Wakee) {
// Exit protocol:
// 1. ST _succ = wakee
// 2. membar #loadstore|#storestore;
// 2. ST _owner = NULL
// 3. unpark(wakee)
}
总结
1:无论偏向锁、轻量级锁、重量级锁,都是可重入的。所以熟悉JAVA并发包的ReentrantLock重入锁机制是有必要的。
2:只有重量级锁需要操作系统去进行调度竞争锁的线程。
3:偏向锁的撤销不是为了使锁降级为无锁状态,而是需要先降级再转变为轻量级锁状态。
4:偏向锁的撤销需要等待全局安全点,且锁撤销有一定的开销。所以在多线程竞争激烈的情况下,可以实现关闭偏向锁来进行性能调优。
想看源码的看这些文件。

其他优化
JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
①:适应性自旋
升级为重量级锁之前,会尝试自旋一定次数(默认10次,可通过参数-XX : PreBlockSpin来更改)来延缓进入重量级锁的过程。
优点:若真的成功则可以避免锁升级,减少线程进入monitor从而带来的一系列开销。同时当前线程不会经历挂起-唤醒的过程,可以更快响应。
缺点:会一直占用cpu,若自旋失败则是额外的浪费。
②:锁粗化
将连在一起的加锁、解锁操作扩大范围,只进行一次性加锁、解锁操作。
如:
Object lock = new Object();
List<String> list = new ArrayList();
synchronized(lock){
list.add("a");
}
synchronized(lock){
list.add("b");
}
synchronized(lock){
list.add("c");
}
优化为:
Object lock = new Object();
List<String> list = new ArrayList();
synchronized(lock){
list.add("a");
list.add("b");
list.add("c");
}
③:锁消除
若当前线程创建的对象分配在堆,但不会被其他线程使用,那么这段代码就可以不加锁。
或者根据逃逸分析,当前线程new的对象不会被其他线程使用,那么也不需要加锁。
其他问题
①:当所状态为偏向锁时,如何存储hashcode信息?
若hashCode方法的调用是在对象已经处于偏向锁状态时调用,它的偏向状态会被立即撤销,并且锁会升级为重量级锁。
②:什么线程复用?
两个线程间隔5s启动,markword中thread信息一摸一样这个现象实际上就是JVM线程复用。
本文参考文章:
①:小米信息部技术团队-synchronized 实现原理
②:synchronized的jvm源码加锁流程分析聊锁的意义
③:Java对象的内存布局
④:盘一盘 synchronized (二)—— 偏向锁批量重偏向与批量撤销
⑤:https://www.bbsmax.com/A/xl56qY9rJr/
⑥:Java并发编程:Synchronized底层优化(偏向锁、轻量级锁)
感触:上网搜很难看到自己想要的内容,甚至有的文章还会起误导性作用。果然还是要好好学习,厉害的大佬比比皆是。在性能调优上哪有什么最优解,只有合适与不合适,重在选择与取舍。
Java synchronized那点事的更多相关文章
- Java日志性能那些事(转)
在任何系统中,日志都是非常重要的组成部分,它是反映系统运行情况的重要依据,也是排查问题时的必要线索.绝大多数人都认可日志的重要性,但是又有多少人仔细想过该怎么打日志,日志对性能的影响究竟有多大呢?今天 ...
- Java synchronized 详解
Java synchronized 详解 Java语言的关键字,当它用来修饰一个方法或者一个代码块的时候,能够保证在同一时刻最多只有一个线程执行该段代码. 1.当两个并发线程访问同一个对象object ...
- Java Synchronized Blocks
From http://tutorials.jenkov.com/java-concurrency/synchronized.html By Jakob Jenkov A Java synchro ...
- java synchronized(一)
java synchronized主要用于控制线程同步,中间有很多小的细节,知识,这里我简单的整理一下,做个记录.主要用于方法和代码块的控制 先说说方法控制 模拟银行存款和取款,创建一个Account ...
- java synchronized使用
java synchronized 基本上,所有并发的模式在解决线程冲突问题的时候,都是采用序列化共享资源的方案.这意味着在给定时刻只允许一个任务访问该资源.这个一般通过在代码上加一条锁语句实现,因为 ...
- Java Synchronized 关键字
本文内容 Synchronized 关键字 示例 Synchronized 方法 内部锁(Intrinsic Locks)和 Synchronization 参考资料 下载 Demo Synchron ...
- Java synchronized 关键字详解
Java synchronized 关键字详解 前置技能点 进程和线程的概念 线程创建方式 线程的状态状态转换 线程安全的概念 synchronized 关键字的几种用法 修饰非静态成员方法 sync ...
- Java synchronized对象级别与类级别的同步锁
Java synchronized 关键字 可以将一个代码块或一个方法标记为同步代码块.同步代码块是指同一时间只能有一个线程执行的代码,并且执行该代码的线程持有同步锁.synchronized关键字可 ...
- java synchronized详解
Java语言的关键字,当它用来修饰一个方法或者一个代码块的时候,能够保证在同一时刻最多只有一个线程执行该段代码. 一.当两个并发线程访问同一个对象object中的这个synchronized(this ...
随机推荐
- 树莓派系统安装(ubuntu版本)无需屏幕
0.前提 所需物品:一个手机.一台电脑.一个树莓派.一张tf卡和一个读卡器.所需软件:Win32DiskImager.putty还需要ubuntu系统镜像源.这些我都放在百度网盘上了链接:https: ...
- (2)_引言Introduction【论文写作】
- layui表单使用开关滑块和复选框,渲染后台数据方法
提示:整个表格要在form标签内 定义开关模板 <div class="layui-form" lay-filter="layuiadmin-app-form-li ...
- CSS自定义属性 —— 别说你懂CSS相对单位
前段时间试译了Keith J.Grant的CSS好书<CSS in Depth>,其中的第二章<Working with relative units>,书中对relative ...
- 【wepy入门教程】48小时开发看美女微信小程序,万花阁
说明:本文只做小程序的开发过程记录:小程序仅供学习参考,严禁用于商业及非法用途 准备 不管是做网站还是做小程序,只要是To C,就少不了做内容,因此第一步依然是数据准备,从网上找到两个网站: http ...
- 《深入理解ES6》笔记—— Promise与异步编程(11)
为什么要异步编程 我们在写前端代码时,经常会对dom做事件处理操作,比如点击.激活焦点.失去焦点等:再比如我们用ajax请求数据,使用回调函数获取返回值.这些都属于异步编程. 也许你已经大概知道Jav ...
- 关于个人开源项目(vue app)的一些总结
关于个人开源项目(vue app)的一些总结 项目地址 https://github.com/BYChoo/record 项目简介 此项目名叫:Record.是以Vue全家桶(vue,vue-rout ...
- OllyDbg---call和ret指令
call和ret call指令 cal指令是转移到指定的子程序处,后面紧跟的操作数就是给定的地址. 例如,call 401362表示转移到地址401362处,调用401362处的子程序,当子程序调用完 ...
- LC-19
19. 删除链表的倒数第 N 个结点 思路基本直接出来,双指针,IndexFast 和 IndexSlow 中间相隔 N - 1, 这样 IndexFast 到了最后,IndexSlow 自然就是倒数 ...
- 如何在 Java 中实现 Dijkstra 最短路算法
定义 最短路问题的定义为:设 \(G=(V,E)\) 为连通图,图中各边 \((v_i,v_j)\) 有权 \(l_{ij}\) (\(l_{ij}=\infty\) 表示 \(v_i,v_j\) 间 ...