Java线程池浅析
1. 什么是线程池?我们为什么需要线程池?
线程池即可以存放线程的容器,若干个可执行现成在“容器”中等待被调度。
我们都知道,线程的生命周期中有以下状态:新建状态(New)、就绪状态(Runnable)、运行状态(Running)、阻塞状态(Blocked)、死亡状态(Dead)。当一个线程任务执行完成之后,就会被销毁,然后其他任务继续创建线程。所以就会存在大量的cpu时间用到了线程的新建和死亡,然而一个线程我们没有必要去重复创建。所以线程池的任务就是,在启动时、批量任务开始时,先创建包含N个核心线程的线程池。这N个核心线程在没有任务时,会一直处于就绪状态,资源不会被释放。当任务提交后,我们就可以直接从线程池中取出线程来执行,省略了线程的新建和销毁的CPU时间。
我们使用线程池也是为了充分利用硬件,使系统能够存在更高的效率。同时,我们使用线程池也解决了线程运行时统一管理更加麻烦的问题。
2. Java线程池的结构
我们可以看到Java源码中的线程池结构如下所示:
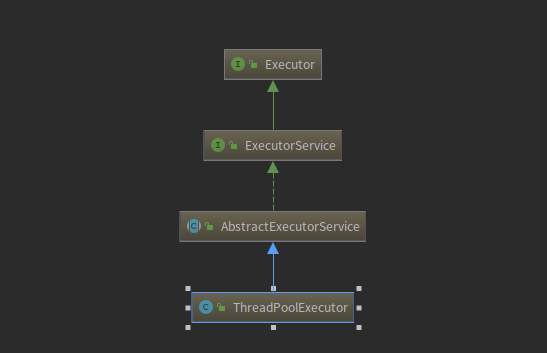
下面我们对这4层结构进行看看:
Executor Interface
- 他是线程池的顶级接口,这个接口中只存在一个方法:void execute(Runnable)
- 此接口通常被称为执行器,通过Executor去执行一个任务。此方法的主要作用就是在给定的时间执行线程。
public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
*/
void execute(Runnable command);
}
ExecutorService Interface
- 这个接口继承了执行器接口Executor,对Executor进行扩展,主要围绕“线程池”的概念增加了2类方法:线程操控(提交线程、停止线程)、线程状态(任务执行状态获取)
public interface ExecutorService extends Executor {
void shutdown();
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
AbstractExecutorService Abstract
- 抽象类。实现ExecutorService接口。
- 给出了提交线程执行策略。且扩展了submit(...)方法,提供了invokeXXX(...)方法
在这里我要问一个问题:看完上述的结构你们认为,任务执行即线程执行,是在哪个方法中?
这个问题就是submit方法和executor方法的区别。顶级方法定义的是一个executor方法即执行器,那么为什么还要存在submit方法?刚才我们看到executor方法是没有返回值的,切只支持Runnable参数。所以我们提交了线程,但是如果无法知道线程执行结果或执行过程中的问题,那我感觉线程池存在的意义少了一大半。
我们查看submit的源码可以发现,在submit方法中是先获取task的Future对象,然后交给execute去执行。在讲此任务的Future对象返回。Future对象的作用就是能够阻塞且等到线程执行完成,获取此线程的执行结果。所以执行任务还是在执行器的executor方法中执行,而submit的意义在扩展执行器方法,返回此线程的执行详情。
public abstract class AbstractExecutorService implements ExecutorService {
//这个源码不方便,还是去ide中看吧
}
ThreadPoolExecutor Class
- 继承抽象类AbstractExecutorService
- 此类才是我们说的线程池类。此类中才存在这“池”的概念。
- 实现executor
- 实现“池”,存在核心线程、最大线程、最小线程、存活时间、拒绝策略等等
- 实现获取线程状态
- 实现线程池操控:如关闭、执行策略等
源码较长建议跳过哈还是在ide上看更方便
public class ThreadPoolExecutor extends AbstractExecutorService {
}
3. Executors
此类可看作线程池的默认实现类。可通过Executors获得默认几种类型的线程池:可变大小的线程池、可调度线程池、固定大小的线程池、单线程线程池、工作窃取线程池(jdk8)。
虽然在此类中给出了默认实现,但是我们使用线程池时不建议使用此类创建。但是提供的几种线程池的类型还是值得学习的。
CacheThreadPool
- 可缓存线程池:即可变大小线程池。
- 此种线程池内线程大小不固定,没有核心线程数量,同样最大线程数量为Integer.MAX_VALUE,可以认为没有最大线程数量。失效时间为60s。
- 存放线程的队列使用的是SynchronousQueue队列,容量为Integer.MAX_VALUE
- 可自定义线程工厂。
- 使用默认拒绝策略。
- 源码实现:
//方法
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
FixedThreadPool
- 固定大小线程池,核心线程数量即最大线程数量。
- 创建时需要参数设置线程数量。核心线程==最大线程,线程过期时间为0s,但是不存在非核心线程,因此过期时间不生效。
- 使用LinkedBlockingQueue队列存储线程,容量为Integer.MAX_VALUE
- 可自定义线程工厂生成线程。使用默认拒绝策略。
- 源码实现:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
SingThreadExcutor
- 只有一个线程的线程池。
- 核心线程只有一个,最大线程也是一个,过期时间不生效
- 队列选用LinkedBlockingQueue,容量为Integer.MAX_VALUE
- 使用默认拒绝策略,可自定义线程工厂
- 源码:
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
ScheduledThreadPool
- 可调度的线程池:实现线程的调度,如定时执行、延迟执行、周期执行等
- 可调度线程池返回的是ScheduledExecutorService,它同ThreadPoolExecutor一样继承自抽象类ExecutorService,创建时可设置核心线程大小,也可得到一个单线程可调度线程池。
- 队列使用DelayedWorkQueue
- 源码:
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1, threadFactory));
}
WorkStealingPool
- 在jdk8中新加入的线程池:工作窃取线程池。什么是工作窃取线程池?
- 假设共有三个线程同时执行, A, B, C。当A,B线程池尚未处理任务结束,而C已经处理完毕,则C线程会从A或者B中窃取任务执行,这就叫工作窃取。通过工作窃取的方式,使得多核的 CPU 不会闲置,总会有活着的线程让 CPU 去运行。WorkStealingPool 背后是使用 ForkJoinPool实现的,执行不保证线程执行顺序。
可以去了解以下Work-Steal算法,如何实现工作窃取
- 源码:
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
4. 拒绝策略
RejectedExecutionHandler接口:
public interface RejectedExecutionHandler {
/**
* Method that may be invoked by a {@link ThreadPoolExecutor} when
* {@link ThreadPoolExecutor#execute execute} cannot accept a
* task. This may occur when no more threads or queue slots are
* available because their bounds would be exceeded, or upon
* shutdown of the Executor.
*
* <p>In the absence of other alternatives, the method may throw
* an unchecked {@link RejectedExecutionException}, which will be
* propagated to the caller of {@code execute}.
*/
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
里面只有rejectedExecution方法。当创建的线程大于线程池最大线程数的时候,新任务就会被拒绝,就会调用这个接口中的方法。
实现接口就可以实现对拒绝线程的处理。
ThreadPoolExecutor自带了4种拒绝策略。分别是:CallerRunsPollicy, AbortPolicy, DiscardPolicy, DiscardOldestPolicy。
1、AbortPolicy:默认使用的拒绝策略
ThreadPoolExecutor线程池默认使用的拒绝策略,不做处理,直接抛出异常:
/**
* A handler for rejected tasks that throws a {@link RejectedExecutionException}.
*/
public static class AbortPolicy implements RejectedExecutionHandler {
/**
* Creates an {@code AbortPolicy}.
*/
public AbortPolicy() { } /**
* Always throws RejectedExecutionException.
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
2、CallerRunsPolicy
在任务被拒绝后,会调用当前线程池的所在的线程去执行被拒绝的任务。因为使用线程池所在的线程去执行,所以会导致主线程阻塞。
/**
* A handler for rejected tasks that runs the rejected task
* directly in the calling thread of the {@code execute} method,
* unless the executor has been shut down, in which case the task
* is discarded.
*/
public static class CallerRunsPolicy implements RejectedExecutionHandler {rRunsPolicy() { } /**
* Executes task r in the caller's thread, unless the executor
* has been shut down, in which case the task is discarded.
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
3、DiscardPolicy
这个怎么说呢,discard 丢弃。就是如果被拒绝直接丢弃。我们可以在源码中看到,实现了一个空的 rejectedExecution方法,但是很懒,什么都没有做。
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() { }
/**
* Does nothing, which has the effect of discarding task r.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
4、DiscardOldestPolicy
从discard我们看出这个策略也和丢弃相关。此策略作用就是,当任务被拒绝添加时,会抛弃任务队列中最旧的任务,也就是最先加入队列中的任务,然后再添加这个新任务。可以看一下源码:
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() { }
/**
* Obtains and ignores the next task that the executor
* would otherwise execute, if one is immediately available,
* and then retries execution of task r, unless the executor
* is shut down, in which case task r is instead discarded.
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
源码中直接获取线程池的Queue,去除最前端的一个,然后把现在这个加入队列。
5. 线程队列
我们上面说Executors的默认5种线程池的时候应该就注意到,每种线程池类型都会对应一个存储线程池队列类型。所以说每种队列的特性也和线程池的特性相关。
1、CacheThreadPool使用的SynchronousQueue
CacheThreadPool线程池的特性就是可变线程数量,最大线程数量为Integer.MAX_VALUE。所以线程的数量不是固定且随着任务的提交逐渐增加。那么SynchronousQueue的作用是什么呢?
/**
* A {@linkplain BlockingQueue blocking queue} in which each insert
* operation must wait for a corresponding remove operation by another
* thread, and vice versa. A synchronous queue does not have any
* internal capacity, not even a capacity of one. You cannot
* {@code peek} at a synchronous queue because an element is only
* present when you try to remove it; you cannot insert an element
* (using any method) unless another thread is trying to remove it;
* you cannot iterate as there is nothing to iterate. The
* <em>head</em> of the queue is the element that the first queued
* inserting thread is trying to add to the queue; if there is no such
* queued thread then no element is available for removal and
* {@code poll()} will return {@code null}. For purposes of other
* {@code Collection} methods (for example {@code contains}), a
* {@code SynchronousQueue} acts as an empty collection. This queue
* does not permit {@code null} elements.
*
* <p>Synchronous queues are similar to rendezvous channels used in
* CSP and Ada. They are well suited for handoff designs, in which an
* object running in one thread must sync up with an object running
* in another thread in order to hand it some information, event, or
* task.
*
* <p>This class supports an optional fairness policy for ordering
* waiting producer and consumer threads. By default, this ordering
* is not guaranteed. However, a queue constructed with fairness set
* to {@code true} grants threads access in FIFO order.
*
* <p>This class and its iterator implement all of the <em>optional</em>
* methods of the {@link Collection} and {@link Iterator} interfaces.
*
*/
public class SynchronousQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
……
}
我们可以从SynchronousQueue的接口及其解释中看到:1、SynchronousQueue实现的是BlockingQueue接口;2、注释中说的很清楚:此队列没有内部容量,每个插入操作必须等待上一个线程的移除操作。所以在CacheThreadPool中SyncchronousQueue队列就是直接提交给线程执行,而不做对任务的存储操作。这样我们的每一个提交的任务都会新建一个线程及时去执行他。
如果使用Executors去创建CacheThreadPool线程池,设置的线程池大小为Integer.MAX_VALUE,同时又不存在队列大小限制,所以直到线程数量达到MAX_VALUE之前,都不会走拒绝策略。MAX_VALUE就理解为无限大吧,在达到这个数字之前肯定已经OOM了。
- 那么,这个队列的存在的意义是什么?
SynchronousQueue的作用在jdk和注释中也写的很清楚,上面具体的意思就是类似CSP和Ada中使用的集合通道,此策略可以避免具有内部依赖行的请求集出现锁。例如任务T1,T2存在内部关联,T1需要先运行,那么先提交T1,再提交T2,当使用SynchronousQueue时可以保证,T1必定先被执行,在T1执行完成之前,T2不可能插入到队列中。这里你就要抛去CacheThreadPool的影响,单独考虑队列的功能及其作用。线程池是选择适合策略的队列去使用。而SynchronousQueue刚好能够完美做到这一点。
2、FixedThreadPool和SignThreadExcutor使用的LinkedBlockingQueue
LinkedBlockingQueue如果不指定大小,默认为Integer.MAX_VALUE。从名称我们就可以看出,使用链表的形式去存储的队列。
FixedThreadPool和SignThreadExcutor只有核心线程,所以当任务达到核心线程是,需要存储一个未知数量的任务,链表形式再好不过。因此当LinkedBlockingQueue队列不设置大小的时候,新任务一直累加,会导致OOM问题。
3、ScheduledThreadPool使用的DelayedWorkQueue和DelayQueue
这里理解以下DelayedWorkQueue和DelayQueue两者的区别:
- DelayedWorkQueue是ScheduledThreadPoolExecutor类为了实现线程的调度而专门为Runable接口实现的一个延迟队列。此队列功能与DelayQueue一致。主要起到延迟执行任务。
/**
* Specialized delay queue. To mesh with TPE declarations, this
* class must be declared as a BlockingQueue<Runnable> even though
* it can only hold RunnableScheduledFutures.
*/
static class DelayedWorkQueue extends AbstractQueue<Runnable>
implements BlockingQueue<Runnable> { /*
* A DelayedWorkQueue is based on a heap-based data structure
* like those in DelayQueue and PriorityQueue, except that
* every ScheduledFutureTask also records its index into the
* heap array. This eliminates the need to find a task upon
* cancellation, greatly speeding up removal (down from O(n)
* to O(log n)), and reducing garbage retention that would
* otherwise occur by waiting for the element to rise to top
* before clearing. But because the queue may also hold
* RunnableScheduledFutures that are not ScheduledFutureTasks,
* we are not guaranteed to have such indices available, in
* which case we fall back to linear search. (We expect that
* most tasks will not be decorated, and that the faster cases
* will be much more common.)
*
* All heap operations must record index changes -- mainly
* within siftUp and siftDown. Upon removal, a task's
* heapIndex is set to -1. Note that ScheduledFutureTasks can
* appear at most once in the queue (this need not be true for
* other kinds of tasks or work queues), so are uniquely
* identified by heapIndex.
*/
……
}
- DelayQueue是一个单独的延迟队列,队列内保存的元素必须实现Delayed接口,只有你的任务实现了Delayed接口,才能够传入此队列做参。
/**
* An unbounded {@linkplain BlockingQueue blocking queue} of
* {@code Delayed} elements, in which an element can only be taken
* when its delay has expired. The <em>head</em> of the queue is that
* {@code Delayed} element whose delay expired furthest in the
* past. If no delay has expired there is no head and {@code poll}
* will return {@code null}. Expiration occurs when an element's
* {@code getDelay(TimeUnit.NANOSECONDS)} method returns a value less
* than or equal to zero. Even though unexpired elements cannot be
* removed using {@code take} or {@code poll}, they are otherwise
* treated as normal elements. For example, the {@code size} method
* returns the count of both expired and unexpired elements.
* This queue does not permit null elements.
*
* <p>This class and its iterator implement all of the <em>optional</em>
* methods of the {@link Collection} and {@link Iterator} interfaces.
* The Iterator provided in method {@link #iterator()} is <em>not</em>
* guaranteed to traverse the elements of the DelayQueue in any
* particular order.
*
*/
public class DelayQueue<E extends Delayed> extends AbstractQueue<E>
implements BlockingQueue<E> {
……
}
SecheduledThreadPool创建的ScheduledThreadPoolExecutor线程池主要实现了线程的调度性,如定时执行、周期执行等。而我认为主要的作用的还是DelayedWorkQueue队列。因为SecheduledThreadPoolExecutor线程池继承ThreadPoolExecutor,而在构造中,使用DelayedWorkQueue队列,重写了submit方法和增加了一些调度方法。
我们可以看以下ScheduledThreadPoolExecutor类的构造源码,所以这里控制线程此的是他的父类ThreadPoolExecutor,核心线程池参数制定,最大线程数量为MAX_VALUE,线程存活时间是10min。因此如果使用Executors创建可调度线程池仍然会存在OOM风险。
public class ScheduledThreadPoolExecutor
extends ThreadPoolExecutor
implements ScheduledExecutorService {
/** 构造 */
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE,
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,
new DelayedWorkQueue());
}
……
}
4、如无特殊需求推荐使用:ArrayBlockingQueue
此队列和LinkBlockingQueue相对使用数组实现,因为是数组,所以是一个“有界队列”,我们在使用的时候必须设置数组大小,也可选择是否采用FIFO方式处理任务。
所以日常使用中无特殊需要我是非常推荐使用此队列作为线程池的任务队列。
6. 线程池的执行判断顺序
- 先说结果:判断是否达到核心线程数、 判断任务队列是否已满、 判断是否超过最大线程数量、 执行拒绝策略。
我们上面了解了线程池的结构,所以在线程池执行线程,都是由执行器方法进行,所以我们看以下执行器方法的实现:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
//这里判断当前线程数量是否大于核心线程数
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//1、线程数大于核心线程数;2、添加任务失败
//这里首先判断线程池是否停止,停止之后拒绝所有线程。
//然后把任务添加到队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//1、线程池已经停止;2、队列已经满
//继续添加任务,不过这里传参数是false。如果是true,线程大小是跟核心线程数相比,false线程数大小是跟最大线程数相比较
else if (!addWorker(command, false))
reject(command);
}
除了看源码之外,我们同样可以实现一个线程池来执行以下,查看线程执行的顺序。
7. 使用规范
1、不要使用Executors创建线程池。
使用Executors创建的默认线程池都存在这内存泄露的风险:
FixedThreadPool和SiginThreadPool两个允许最大的队列长度都是Integer.MAX_VALUE,因此会堆积大量的任务而导致OOM。
CacheThreadPool和ScheduleThreadPool两者允许创建的线程数量都为Integer.MAX_VALUE,可能会创建大量的线程从而导致OOM。
Java线程池浅析的更多相关文章
- Java 线程池框架核心代码分析--转
原文地址:http://www.codeceo.com/article/java-thread-pool-kernal.html 前言 多线程编程中,为每个任务分配一个线程是不现实的,线程创建的开销和 ...
- Java线程池使用说明
Java线程池使用说明 转自:http://blog.csdn.net/sd0902/article/details/8395677 一简介 线程的使用在java中占有极其重要的地位,在jdk1.4极 ...
- (转载)JAVA线程池管理
平时的开发中线程是个少不了的东西,比如tomcat里的servlet就是线程,没有线程我们如何提供多用户访问呢?不过很多刚开始接触线程的开发攻城师却在这个上面吃了不少苦头.怎么做一套简便的线程开发模式 ...
- Java线程池的那些事
熟悉java多线程的朋友一定十分了解java的线程池,jdk中的核心实现类为java.util.concurrent.ThreadPoolExecutor.大家可能了解到它的原理,甚至看过它的源码:但 ...
- 四种Java线程池用法解析
本文为大家分析四种Java线程池用法,供大家参考,具体内容如下 http://www.jb51.net/article/81843.htm 1.new Thread的弊端 执行一个异步任务你还只是如下 ...
- Java线程池的几种实现 及 常见问题讲解
工作中,经常会涉及到线程.比如有些任务,经常会交与线程去异步执行.抑或服务端程序为每个请求单独建立一个线程处理任务.线程之外的,比如我们用的数据库连接.这些创建销毁或者打开关闭的操作,非常影响系统性能 ...
- Java线程池应用
Executors工具类用于创建Java线程池和定时器. newFixedThreadPool:创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这些线程.在任意点,在大多数 nThread ...
- Java线程池的原理及几类线程池的介绍
刚刚研究了一下线程池,如果有不足之处,请大家不吝赐教,大家共同学习.共同交流. 在什么情况下使用线程池? 单个任务处理的时间比较短 将需处理的任务的数量大 使用线程池的好处: 减少在创建和销毁线程上所 ...
- Java线程池与java.util.concurrent
Java(Android)线程池 介绍new Thread的弊端及Java四种线程池的使用,对Android同样适用.本文是基础篇,后面会分享下线程池一些高级功能. 1.new Thread的弊端执行 ...
- [转 ]-- Java线程池使用说明
Java线程池使用说明 原文地址:http://blog.csdn.net/sd0902/article/details/8395677 一简介 线程的使用在java中占有极其重要的地位,在jdk1. ...
随机推荐
- api进阶Day3使用文件流对文件进行复制、使用块读写一组字节,使用byte数组提高读写的效率、返回当前时间。
使用文件流对文件进行复制: package io; import java.io.FileInputStream; import java.io.FileNotFoundException; impo ...
- Web _Servlet(url-pattern)的配置与优先级
url-pattern的配置方式有三种: 1.完全路径匹配:以 '/' 开始 例: /ServletDemo1 , /aaa/ServletDemo2 , /aa/bb/ServletDemo3 ...
- 利用shell脚本提高访问GitHub速度
Github由于做了域名限制,所以访问比较慢,编写了个脚本达到做本地域名解析提高GitHub的访问速度 #!/usr/bin/env bash # 该脚本用来提升github的访问速度 ROOT_UI ...
- 【基础知识】C++算法基础(快速排序)
快速排序: 1.执行流程(一趟快排): 2.一趟快排的结果:获得一个枢纽,在此左边皆小于此数,在此右边皆大于此数,因此可以继续使用递归获得最终的序列.
- HashMap记录
1.HashMap接收null的键值 2.HashMap是非synchronized的 3.HashMap使用hashCode找到bucket的位置.bucket中存储的是键和值 4.当HashCod ...
- 利用fread读取二进制文件的bug
最近在做一个项目时需要读取二进制文件,我用C语言的fread进行读取,代码如下: FILE *fp; int read_data; fopen_s(&fp, file_path, " ...
- PHP程序的“Missing argument 3”的错误提示解决方法
是在定义函数时为三个参数,但实际调用时只调了两个参数 解决办法: 一种:在调用函数地方补全调用的参数 二种:修改函数传入参数值,设置带有默认值, Missing argument 3 fo ...
- Openssl自签证书|Nginx配置全站HTTPS,包括WSS(websocket)
一.生成自签证书 如果有购买证书的,可忽略此步骤. 生成方法一: openssl genrsa -des3 -out ca.key 1024 openssl rsa -in ca.key -out c ...
- git 本地项目初始化提交至仓库
命令行指令 Git初始化配置 git config --global user.name"abc" git config --global user.email"1234 ...
- 后端006_登录之后返回Token
现在开始我们就可以写登录相关的东西了.首先登录相关的流程是这样的,前端输入用户和密码传给后端,后端判断用户名和密码是否正确,若正确,则生成JWT令牌,若不正确,则需要让前端重新输入,前端如果拿到了JW ...