从读写角度,带你了解数仓的IO基本框架
摘要:本文从读取和写入的角度分别描述了行存和列存的IO模型,并对文件结构做了简单介绍。
本文分享自华为云社区《GaussDB(DWS)基本IO框架》,作者: Naibaoofficial。
行存IO管理框架
存储结构
- OID(Object identifiers):对象的唯一标识。
- 每个表存在对应数据库的文件夹中,用relfilenode标识。
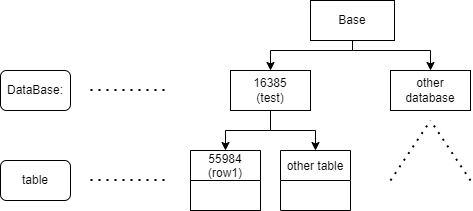
例如表row1,可以直接查询对应的文件
test=# select pg_relation_filepath('row1');
pg_relation_filepath
----------------------
base/16385/55984
(1 row)
- 每个表的读取写入以页(文件块)为基本单位,页的大小是一个BLCKSZ,默认8KB,其结构如下:
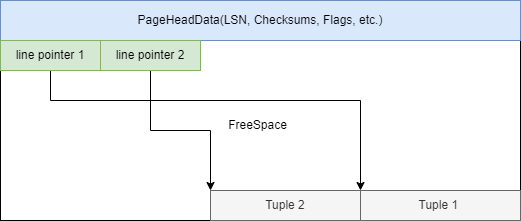
- Tuple保存了当前一行的数据,分为Header和Data两块,头部保存元组的相关信息(列数,事务信息,是否有Toast表等)。
- 每个Tuple最大为2kb,若Data过大无法压缩至2KB,则采用额外的Toast表存储,此时Tuple内的Data保存Toast表的相关信息。
GaussDB 行存框架:
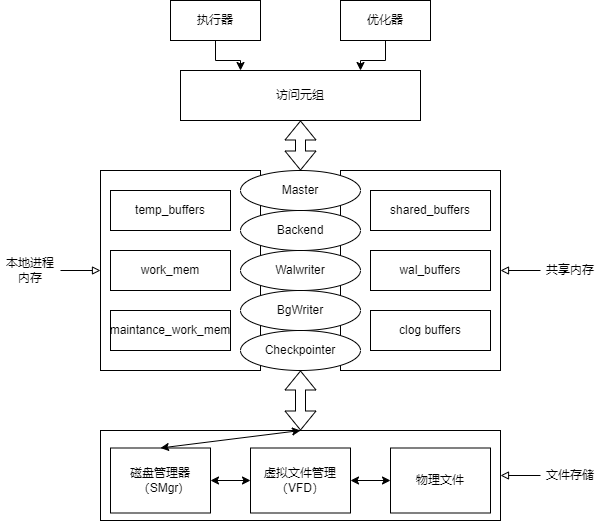
这里面涉及到几个比较大的内核机制:
- 本地缓存:
这里面的本地缓存介绍了三个比较常用的缓存结构,这里直接引用了官方的英文解释。
temp_buffers: Sets the maximum number of temporary buffers used by each database session. These are session-local buffers used only for access to temporary tables.
work_mem: Specifies the amount of memory to be used by internal sort operations and hash tables before writing to temporary disk files.
maintenance_work_mem: Specifies the maximum amount of memory to be used by maintenance operations, such as VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY.
- 共享内存:可由整个Gaussdb共享
包括shared_buffer和wal_buffer, 分别用来存放Page和Clog,Wal Segment。
- WalWriter,BgWriter:
主要是将共享内存的内容落盘,WalWriter一般是在事务提交时就需要落盘,但是有时候可以放弃一定的事务一致性原则,从而让WalWriter异步落盘加快速度。BgWriter负责将shared_buffer中的内容落盘。
- 外存管理:
负责上层与外存之间的文件交互。
IO管理框架:读取
读取的过程相对简单,就是从物理文件先装到shared_buffer中,然后从shared_buffers返回相关的结果。
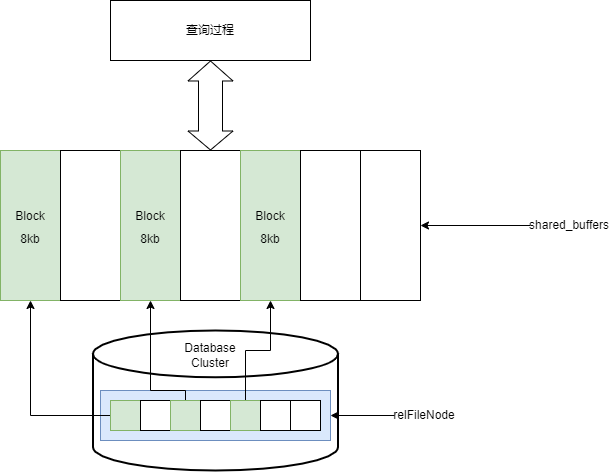
shared_buffers中就是以Page为单位进行存储的,因为每个Page的大小是固定的,所以shared_buffers能存放的page个数也就是确定的。这里面就需要考虑一个问题,因为这个资源是共享的,如果一个线程读取了大量的文件,这样势必会使得其他线程的缓存命中率下降。
GaussDB在这里引入了Ringbuffer的机制,可以限制一个线程所使用的shared_buffers的大小,从而解决掉这个问题。
IO管理框架:写入
- 写入操作是增加的新的元组,Update操作相当于先Delete,再Insert。
- INSERT
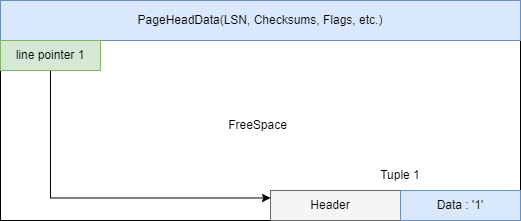
- UPDATE
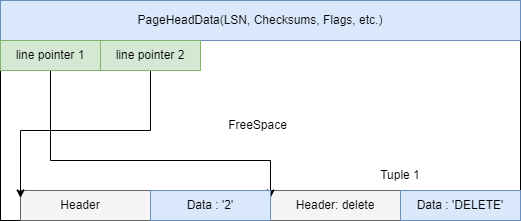
将旧元组标记为Dead,然后插入新的元组,由Vacuum负责清理。当然,这里面Data变为DELETE只是用来描述删除的是此Tuple,实际上Data当中的值是不变的。
- 写入的整体逻辑:
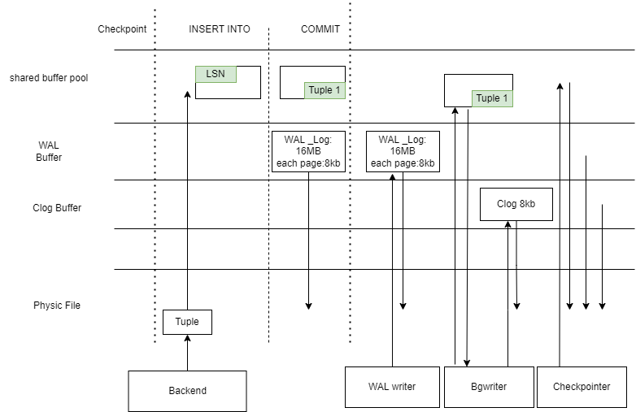
GaussDB行存在写入时,将元组信息先写入到shared_buffers,然后用bgwriter刷入磁盘,这样在事务提交时就可以避免磁盘的IO开销,提升性能,为了保证一致性和恢复,使用wal日志和checkpoints可以实现日志先落盘(也可以异步)和redo等操作。
列存的IO管理框架
列存的存储单元
- 列存的存储单元为CU(CStore Unit)
- CU的大小为8k对齐
- 适合大批量导入的场景
- 同一列的CU存在一个新文件中,大于1GB时,切换到新文件中。
- 列存用一个CUDesc的行存表描述CU的相关信息,可以理解成为一个Toast表。
- CUDesc:行存表,记录CU的相关信息, 主要属性如下:
- col_id,cu_id: 第col_id列,第cu_id个CU
- min, max, row_count, size
- cu_mode: information mask(RLE,LZ4,Delta表等)
- cu_pointer:指向每一个CU,记录delete bitmap
- magic:和CU头部的magic相同,校验使用
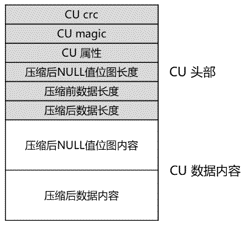
CU结构
列存索引
这里介绍两个索引,C-Btree和Psort,这里不做过多介绍。
主要涉及的是IO相关的内容。
C-Btree
- 索引结构和行存无差别,同样以行存形式存储
- C-Btree可以提升点查效率
- 存储key->ctid(cu_id, offset)
- 过程:
- 根据B-tree索引找到ctid集合
- 对集合进行批量排序(减少IO开销)
- 在CUDesc找到对应的cu_id,根据offset找到数据
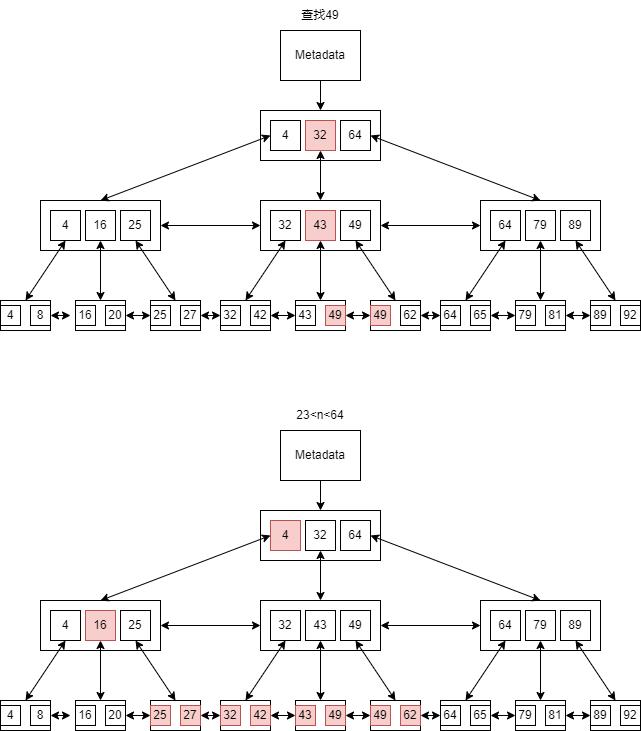
- 举例,等值查询 n=49, 范围查询 23<n<64。
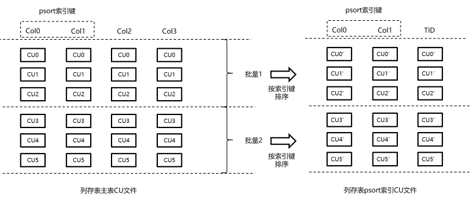
PSort
PSort是一个聚簇索引,对索引进行排序,然后将排序后的索引和行号存入一个新的表,用单独的列存表存储。
简单示意如下,图片来源:https://www.modb.pro/db/108155
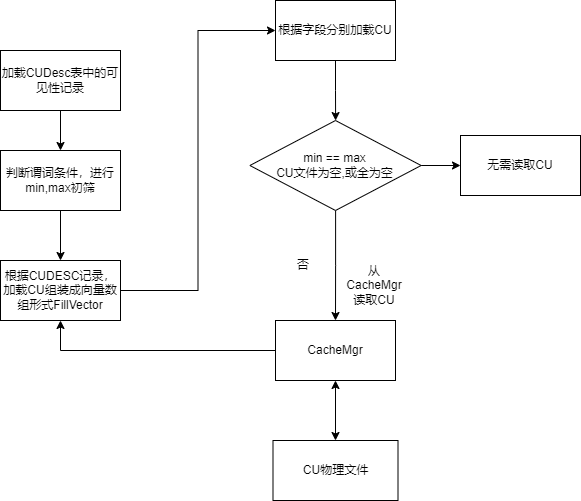
IO管理框架:读取
- 读取过程:
- 根据where条件,做MIN/MAX过滤的谓词条件
- 加载CUDesc
- MIN/MAX过滤
- 读取CU到CU Cache中
- 解析并填充
- CacheMgr: 用来缓存CU到内存中,可以提高重复查询的性能。
- CU的物理文件:
1. CStore_1.0: 当前基本不怎么实用
2. CStore_2.0: 重整了CU的文件结构,避免列数过多导致文件结构复杂。
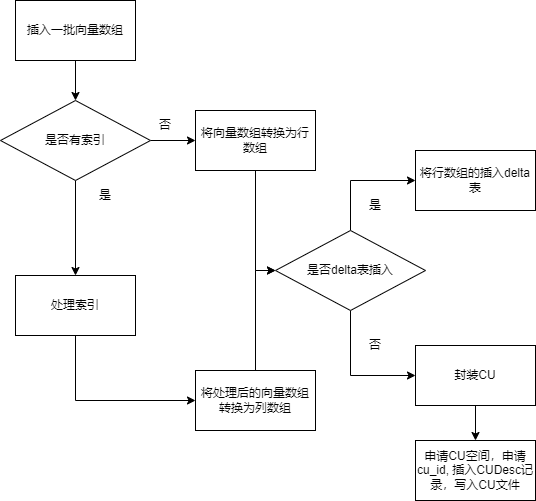
IO管理框架:写入
列存的插入要分两种情况,少量的插入和大量的插入,列存主要是对大批量数据设计的,因此为了弥补小量插入的打包CU性能开销,设计了一个delta行存表,用来记录插入结果,可以减少膨胀和提升性能,最后定期的整理。
- 写入框架如下
列存的删除比较简单,如果是delta表,先从delta表中删除满足谓词条件的记录,然后在CUDesc表中更新待删除CU的delete_bitmap。
从读写角度,带你了解数仓的IO基本框架的更多相关文章
- 对象流,它们是一对高级流,负责即将java对象与字节之间在读写的过程中进行转换。 * java.io.ObjectOutputStream * java.io.ObjectInputStream
package seday06; import java.io.Serializable;import java.util.Arrays; /** * @author xingsir * 使用当前类来 ...
- 带你封装自己的MVP+Retrofit+RxJava2框架(一)
前言 文本已经收录到我的Github个人博客,欢迎大佬们光临寒舍:我的GIthub博客 看完本篇文章的,可以看下带你封装自己的MVP+Retrofit+RxJava2框架(二),里面封装得到了改进 本 ...
- 从数据的角度带你深入了解IPFS
IPFS 和区块链有着非常紧密的联系, 随着区块链的不断发展,对数据的存储需求也越来越高.本文从IPFS 的底层设计出发, 结合源代码, 分析了IPFS 的一些技术细节. 一.概述 IPFS 和区块链 ...
- 小数组的读写和带Buffer的读写哪个快
定义小数组如果是8192个字节大小和Buffered比较的话 定义小数组会略胜一筹,因为读和写操作的是同一个数组 而Buffered操作的是两个数组
- 吉特仓库管理系统-ORM框架的使用
最近在园子里面连续看到几篇关于ORM的文章,其中有两个印象比较深刻<<SqliteSugar>>,另外一篇文章是<<我的开发框架之ORM框架>>, 第一 ...
- 从IT的角度思考BIM(二):模式与框架
我们满怀着美好期许,鼓起勇气敲响了 BIM 世界的大门.忽然人群中有人高呼:BIM 已死,大家都散了吧! 这时人群开始骚动起来.“我早就说这玩意是忽悠人的吧,你们不信还偏要来”,“我花了好多钱准备这次 ...
- 带标准IO带缓存区和非标准IO 遇到fork是的情况分析
废话不多说 直接代码 #include<stdio.h> #include<sys/types.h> #include<unistd.h> #include< ...
- 带你一文搞定 IO 流相关核心问题
问:简单谈谈 Java IO 流各实现类的特性? 答:java.io 包下面的流基本都是装饰器模式的实现,提供了各种类型流操作的便携性,常见的流分类如下. 以二进制字节方式读写的流: InputStr ...
- 文件读写(一)利用File静态类 System.IO.FileInfo、DirectoryInfo、DriveInfo
提供用于创建.复制.删除.移动和打开单一文件的静态方法,并协助创建 FileStream 对象. 一.读文件: 1.返回字符串:File.ReadAllText() string readText = ...
随机推荐
- 直播流媒体EasyDSS
访问官方 http://www.easydss.com/ 点击试用下载 根据不同需求 选择不同版本 (我选择的右边) 下载完解压 双击 start.bat 看见如下图则成功 网页输入 http://i ...
- 稳住,传输层里的TCP与UDP协议
传输层协议 1.TCP协议介绍及报文格式 2.TCP三次握手三次挥手 3.UDP协议介绍 1.传输层有两个协议:TCP(传输控制协议) UDP(用户数据协议) . TCP是面向连接的,可靠的进程到进 ...
- 2、网络并发编程--套接字编程、黏包问题、struct模块、制作简易报头、上传文件数据
昨日内容回顾 面向对象复习(json序列化类) 对象.类.父类的概念 三大特性:封装 继承 多态 双下开头的方法(达到某个条件自动触发) __init__:对象实例化自动触发 __str__:对象执行 ...
- Solution -「NOI 2012」「洛谷 P2050」美食节
\(\mathcal{Description}\) Link. 美食节提供 \(n\) 种菜品,第 \(i\) 种的需求量是 \(p_i\),菜品由 \(m\) 个厨师负责制作,第 \(j\) ...
- WMI简介和Event驻留
WMI (Windows Management Instrumentation,Windows管理规范) 从Windows 2000开始被包含于操作系统后,就一直是Windows操作系统的一部分. ...
- Nginx--Sorry, the page you are looking for is currently unavailable
- 一文了解如何源码编译Rainbond基础组件
Rainbond 主要由以下三个项目组成,参考官网详细 技术架构 业务端 Rainbond-UI 和 Rainbond-Console 合起来构成了业务层.业务层是前后端分离模式.UI是业务层的前端代 ...
- systemd配置文件填写了ExecStop=/usr/bin/kill -9 $MAINPID之后重启在messages发生了报错
原因在于systemd模块需要增加自动化检测,检测有一项为检测messages日志内是否有systemd的failed 写了一个检测脚本,脚本的检测messages内容为/bin/cat /var/l ...
- 防世界之Web_warmup
题目: 啥都没有,右键打开页面源代码查看一下 发现source.php源文件,输入http://111.200.241.244:53776/source.php看看 <?php high ...
- node + express 搭建服务器,修改为自动重启服务器
1.使用express搭建一个项目,步骤如下(安装node步骤已省略) a.全局安装express-generator和express npm i express-generator -g npm i ...