聊聊FASTER和进程内混合缓存
最近有一个朋友问我这样一个问题:
我的业务依赖一些数据,因为数据库访问慢,我把它放在Redis里面,不过还是太慢了,有什么其它的方案吗?
其实这个问题比较简单的是吧?Redis其实属于网络存储,我对照下面的这个表格,可以很容易的得出结论,既然网络存储的速度慢,那我们就可以使用内存RAM存储,把放Redis里面的数据给放内存里面就好了。
| 操作 | 速度 |
|---|---|
| 执行指令 | 1/1,000,000,000 秒 = 1 纳秒 |
| 从一级缓存读取数据 | 0.5 纳秒 |
| 分支预测失败 | 5 纳秒 |
| 从二级缓存读取数据 | 7 纳秒 |
| 使用Mutex加锁和解锁 | 25 纳秒 |
| 从主存(RAM内存)中读取数据 | 100 纳秒 |
| 在1Gbps速率的网络上发送2Kbyte的数据 | 20,000 纳秒 |
| 从内存中读取1MB的数据 | 250,000 纳秒 |
| 磁头移动到新的位置(代指机械硬盘) | 8,000,000 纳秒 |
| 从磁盘中读取1MB的数据 | 20,000,000 纳秒 |
| 发送一个数据包从美国到欧洲然后回来 | 150 毫秒 = 150,000,000 纳秒 |
提出这个方案以后,接下来就遇到了另外一个问题:
但是数据比我应用的内存大,这怎么办呢?
笔者突然回想起来,似乎从来没有考虑过数据比应用大是该怎么处理,面对这种性能问题,最方便的方案就是直接扩容,在基础设施完备的公司,一般只需要提交一个工单"8G->64G"就能解决这个问题,这种成本似乎不是该考虑的事情。
不过对于有一些朋友的公司,因为多个方面的原因(主要还是预算),没有办法扩容机器。或者体量非常大,每个实例扩容1GB内存,数万个容器就是非常大的开销。
于是我们可以采用一些内存+磁盘的缓存方式,因为现在大多数都是SSD磁盘,服务器NVME顺序读写速度早已突破7GB/s,随机读写早已突破100K IOPS,而且还可以通过RAID0进一步增加性能。
最简单的就是我们在本地跑一个Sqlite,然后将数据缓存到本地磁盘中,但是Sqlite并不是专业的KV Store,读写性能并不是特别好。KV-Store的话还有基于LSM-Tree的RocksDB、LevelDB等等。
不过那些KV都是C++的实现,在C#中集成需要Bind和P/Invoke,需要自己编译比较麻烦;这让我想起了多年前微软开源FASTER项目。
FASTER
项目如其名,FASTER是目前蓝星最快的KV-Store(开源的项目中),根据论文中的性能表现,它可以实现1.6亿次操作/秒,当然这一切也是有代价的,就是它目前只支持简单的几种操作,Read、Upser、RMW和Delete,不过这已经够了,毕竟在缓存场景这些操作就足够了。

在它2018年开源和论文发表时,我就有关注,不过当时它的API易用性不够,另外C#版本存在一些问题,所以一直都没有体验它,现在它经过几年的迭代,易用性得到了很大的提高,一些之前存在的问题也已经修复。
笔者简单的体验了一下它,可以说这是我使用过比较复杂的的KV-Store了,从它的API使用风格来说,它的设计的目的只有一个,那就是性能。
简单体验FASTER
具体的使用详情大家可以直接看官方文档,Github开源地址和文档在文末给出,需要详细了解的可以查看文档。首先就是安装NuGet包:
<PackageReference Include="Microsoft.FASTER.Core" Version="2.0.22" />
然后下面简单的几行代码就可以把Demo运行起来了,它支持In-Memroy(内存模式)和混合模式。和对数据库操作需要创建链接一样,它的维度是session,注意这个session就代表一个线程对它进行读写,如果多线程场景,那么每个线程对应的session应该要不一致,要单独创建,当然我们也可以把它池化。
// 内存模式
using var fasterKvSetting = new FasterKVSettings<string, string>(null);
// 混合模式
using var fasterKvSetting = new FasterKVSettings<long, byte[]>("./faster-query");
// 创建fasterKv Store
using var fasterKv = new FasterKV<long, byte[]>(fasterKvSetting);
var session = fasterKv.For(new SimpleFunctions<long, byte[]>()).NewSession<SimpleFunctions<long, byte[]>>();
// 准备一个utf-8字符
var str = "yyds"u8.ToArray();
// 写入
session.Upsert(1024, str);
// 读取
var result = session.Read(1024);
Console.WriteLine($"{Encoding.UTF8.GetString(result.output)}");
输出结果就是yyds。
另外也有丰富的参数可以调整内存占用,以下列出了几个相关的内存占用参数,当然,更低的内存使用,意味着更多的使用磁盘空间,性能也就会下降的越多:
IndexSize: 主Hash索引的大小,以字节为单位(四舍五入为2的幂)。最小大小为64字节。MemorySize: 表示混合日志的内存部分的大小(四舍五入为2的幂)。注意,如果日志指向类键或值对象,则此大小仅包括对该对象的8字节引用。日志的旧部分溢出到存储中。LogSettings: 这些是几个与日志相关的设置,例如页面大小的 PageSize。ReadCacheEnable: 是否为存储提供并启用了单独的读缓存。ReadCacheMemorySize: 读缓存内存占用大小,ReadCachePageSize: 读缓存页面大小
跑个分试试
那么FASTER到底有多强呢?笔者构建了一个测试,和我们常用的ConcurrentDictionary做比较,那是我能找到在.NET平台上差不多的东西,按道理来说我们应该和RocksDB、LevelDB来比较。
ConcurrentDictionary应该是.NET平台上性能最好的纯内存KV Store了,严格来说它和FASTER并不是不能相提并论,而且受制于笔记本的性能,无法做大数量的测试,要知道FASTER的场景是大型数据集。
为了方便的统计内存占用,我构建了一个结构体类型,如下所示,它应该占用32字节:
Add测试
我分别构建了不同的场景来测试Add性能,测试的构建如下所示:
- ConcurrentDictionary 单线程模式
- FasterKV 内存+磁盘混合 10~100%内存占用模式
- FasterKV 纯内存模式
- 以上模式的6个线程并发访问模式
代码如下所示:
[GcForce]
[Orderer(SummaryOrderPolicy.FastestToSlowest)]
[MemoryDiagnoser]
[HtmlExporter]
public class AddBench
{
private const int ThreadCount = 6;
private const int NumCount = 200_0000;
private ConcurrentDictionary<long, Data> _concurrent;
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private static async Task FasterInternal(double percent, bool inMemory = false, bool multi = false)
{
FasterKVSettings<long, Data> kvSetting;
if (inMemory)
{
kvSetting = new FasterKVSettings<long, Data>(null);
}
else
{
// 总计内存大小 总数 * (key + 每个Data需要占用的内存)
var dataByte = NumCount * (Unsafe.SizeOf<Data>() + 8 + 8);
// 计算memorySize 计划只使用{percent * 100}%的内存 需要是2的次幂
var memorySizeBits = (int) Math.Ceiling(Math.Log2(dataByte * percent));
// 根据数量计算IndexSize 需要是2的次幂
var numBucketBits = (int) Math.Ceiling(Math.Log2(NumCount));
kvSetting = new FasterKVSettings<long, Data>("./faster-add", deleteDirOnDispose: true)
{
IndexSize = 1L << numBucketBits,
MemorySize = 1L << memorySizeBits
};
// 不分页
kvSetting.PageSize = kvSetting.MemorySize;
}
using var fkv = new FasterKV<long, Data>(kvSetting);
if (multi)
{
await FasterMultiThread(fkv);
}
else
{
FasterSingleThread(fkv);
}
kvSetting.Dispose();
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private static void FasterSingleThread(FasterKV<long, Data> fkv)
{
using var session = fkv.For(new SimpleFunctions<long, Data>()).NewSession<SimpleFunctions<long, Data>>();
for (int i = 0; i < NumCount; i++)
{
session.Upsert(i, new Data());
}
session.CompletePending(true);
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private static async Task FasterMultiThread(FasterKV<long, Data> fkv)
{
const int perCount = NumCount / ThreadCount;
var tasks = new Task[ThreadCount];
for (var i = 0; i < ThreadCount; i++)
{
var i1 = i;
var session = fkv.For(new SimpleFunctions<long, Data>())
.NewSession<SimpleFunctions<long, Data>>();
tasks[i] = Task.Run(() =>
{
var j = i1 * perCount;
var length = j + perCount;
for (; j < length; j++)
{
session.Upsert(j, new Data());
}
session.CompletePending(true);
});
}
await Task.WhenAll(tasks);
}
[Benchmark]
public async Task Faster_Hybrid_10per_Memory_Add()
{
await FasterInternal(0.10);
}
[Benchmark]
public async Task Faster_Hybrid_25per_Memory_Add()
{
await FasterInternal(0.25);
}
[Benchmark]
public async Task Faster_Hybrid_50per_Memory_Add()
{
await FasterInternal(0.50);
}
[Benchmark]
public async Task Faster_Hybrid_90per_Memory_Add()
{
await FasterInternal(0.90);
}
[Benchmark]
public async Task Faster_Hybrid_100per_Memory_Add()
{
await FasterInternal(1.0);
}
[Benchmark]
public async Task Faster_Default_InMemory_Add()
{
await FasterInternal(0, true);
}
[Benchmark]
public async Task Faster_Hybrid_10per_Memory_Multi_Add()
{
await FasterInternal(0.10, multi: true);
}
[Benchmark]
public async Task Faster_Hybrid_25per_Memory_Multi_Add()
{
await FasterInternal(0.25, multi: true);
}
[Benchmark]
public async Task Faster_Hybrid_90per_Memory_Multi_Add()
{
await FasterInternal(0.90, multi: true);
}
[Benchmark]
public async Task Faster_Hybrid_100per_Memory_Multi_Add()
{
await FasterInternal(1.0, multi: true);
}
[Benchmark]
public async Task Faster_Hybrid_50per_Memory_Multi_Add()
{
await FasterInternal(0.50, multi: true);
}
[Benchmark]
public async Task Faster_Default_InMemory_Multi_Add()
{
await FasterInternal(0, true, true);
}
[Benchmark]
public void Concurrent_Add()
{
_concurrent = new ConcurrentDictionary<long, Data>(1, NumCount);
for (long i = 0; i < NumCount; i++)
{
_concurrent.TryAdd(i, new Data());
}
}
[Benchmark]
public async Task Concurrent_Multi_Add()
{
const int perCount = NumCount / ThreadCount;
var tasks = new Task[ThreadCount];
_concurrent = new ConcurrentDictionary<long, Data>(1, NumCount);
for (var i = 0; i < ThreadCount; i++)
{
var i1 = i;
tasks[i] = Task.Run(() =>
{
var j = i1 * perCount;
var length = j + perCount;
for (; j < length; j++)
{
_concurrent.TryAdd(j, new Data());
}
});
}
await Task.WhenAll(tasks);
}
}
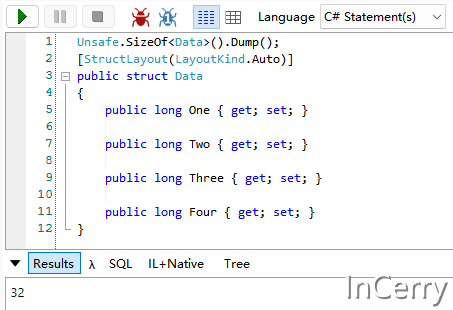
结果如下所示:
- FASTER的多线程写入性能非常不错,而且似乎使用内存的多少对写入性能影响不是很大
- 单线程的话FASTER整体是不如ConcurrentDictionary的
- FASTER确实是能节省内存,设置混合模式时,相较ConcurrentDictionary节省60%的内存
Query测试
Query测试我一共创建了100W条记录,然后测试了如下场景:
- 单线程读取
- 多线程读取
[GcForce]
[Orderer(SummaryOrderPolicy.FastestToSlowest)]
[MemoryDiagnoser]
[HtmlExporter]
public class QueryBench
{
public const int Threads = 6;
public const int NumCount = 100_0000;
private static readonly Random Random = new(NumCount);
private static readonly long[] RandomIndex =
Enumerable.Range(0, 1000).Select(i => Random.NextInt64(0, (int)(NumCount * 0.10))).ToArray();
private static readonly ConcurrentDictionary<long, Data> Concurrent;
private static readonly FasterKV<long, Data> FasterKvHybrid;
private static readonly FasterKV<long, Data> FasterKvInMemory;
private static readonly ClientSession<long, Data, Data, Data, Empty, SimpleFunctions<long, Data>> HybridSession;
private static readonly ClientSession<long, Data, Data, Data, Empty, SimpleFunctions<long, Data>> InMemorySession;
static QueryBench()
{
// 初始化字典
GC.Collect();
var heapSize = GC.GetGCMemoryInfo().HeapSizeBytes;
Concurrent = new ConcurrentDictionary<long, Data>(Threads, NumCount);
for (long i = 0; i < NumCount; i++)
{
Concurrent.TryAdd(i, new Data());
}
Helper.PrintHeapSize("Concurrent", heapSize);
// 初始化混合FasterKv
heapSize = GC.GetGCMemoryInfo().HeapSizeBytes;
// 总计内存大小 总数 * (key + 每个Data需要占用的内存)
var dataByte = NumCount * (Unsafe.SizeOf<Data>() + 8 + 8);
// 计算memorySize 计划只使用50%的内存 需要是2的次幂
var memorySizeBits = (int) Math.Ceiling(Math.Log2(dataByte * 0.5));
// 根据数量计算IndexSize 需要是2的次幂
var numBucketBits = (int) Math.Ceiling(Math.Log2(NumCount));
var kvHybridSetting = new FasterKVSettings<long, Data>("./faster-query", deleteDirOnDispose: true)
{
IndexSize = 1L << numBucketBits,
MemorySize = 1L << memorySizeBits
};
// 32分页
kvHybridSetting.PageSize = kvHybridSetting.MemorySize / 32;
Console.WriteLine($"memorySizeBits:{memorySizeBits},numBucketBits:{numBucketBits},{kvHybridSetting}");
FasterKvHybrid = new FasterKV<long, Data>(kvHybridSetting);
HybridSession = FasterKvHybrid.For(new SimpleFunctions<long, Data>()).NewSession<SimpleFunctions<long, Data>>();
for (long i = 0; i < NumCount; i++)
{
HybridSession.Upsert(i, new Data());
}
HybridSession.CompletePending(true);
Helper.PrintHeapSize("Faster Hybrid", heapSize);
// 初始化In Memory
GC.Collect();
heapSize = GC.GetGCMemoryInfo().HeapSizeBytes;
var inMemorySetting = new FasterKVSettings<long, Data>(null);
FasterKvInMemory = new FasterKV<long, Data>(inMemorySetting);
InMemorySession = FasterKvInMemory.For(new SimpleFunctions<long, Data>()).NewSession<SimpleFunctions<long, Data>>();
for (long i = 0; i < NumCount; i++)
{
InMemorySession.Upsert(i, new Data());
}
InMemorySession.CompletePending(true);
Helper.PrintHeapSize("Faster In Memory", heapSize);
}
[Benchmark]
public async Task Faster_Hybrid_Multi_Query()
{
var tasks = new Task[Threads];
for (int i = 0; i < Threads; i++)
{
var session = FasterKvHybrid.For(new SimpleFunctions<long, Data>())
.NewSession<SimpleFunctions<long, Data>>();
tasks[i] = Task.Run(() =>
{
Data data = default;
for (int j = 0; j < RandomIndex.Length; j++)
{
session.Read(ref RandomIndex[j], ref data);
}
});
}
await Task.WhenAll(tasks);
}
[Benchmark]
public void Faster_Hybrid_1Thread_Query()
{
Data data = default;
for (long j = 0; j < RandomIndex.Length; j++)
{
HybridSession.Read(ref RandomIndex[j], ref data);
}
}
[Benchmark]
public async Task Faster_InMemory_Multi_Query()
{
var tasks = new Task[Threads];
for (int i = 0; i < Threads; i++)
{
var session = FasterKvInMemory.For(new SimpleFunctions<long, Data>())
.NewSession<SimpleFunctions<long, Data>>();
tasks[i] = Task.Run(() =>
{
Data data = default;
for (int j = 0; j < RandomIndex.Length; j++)
{
session.Read(ref RandomIndex[j], ref data);
}
});
}
await Task.WhenAll(tasks);
}
[Benchmark]
public void Faster_InMemory_Query()
{
Data data = default;
for (long j = 0; j < RandomIndex.Length; j++)
{
InMemorySession.Read(ref RandomIndex[j], ref data);
}
}
[Benchmark]
public void Concurrent_Query()
{
for (long j = 0; j < RandomIndex.Length; j++)
{
Concurrent.TryGetValue(RandomIndex[j], out _);
}
}
[Benchmark]
public async Task Concurrent_Multi_Query()
{
var tasks = new Task[Threads];
for (int i = 0; i < Threads; i++)
{
tasks[i] = Task.Run(() =>
{
for (long j = 0; j < RandomIndex.Length; j++)
{
Concurrent.TryGetValue(RandomIndex[j], out _);
}
});
}
await Task.WhenAll(tasks);
}
}
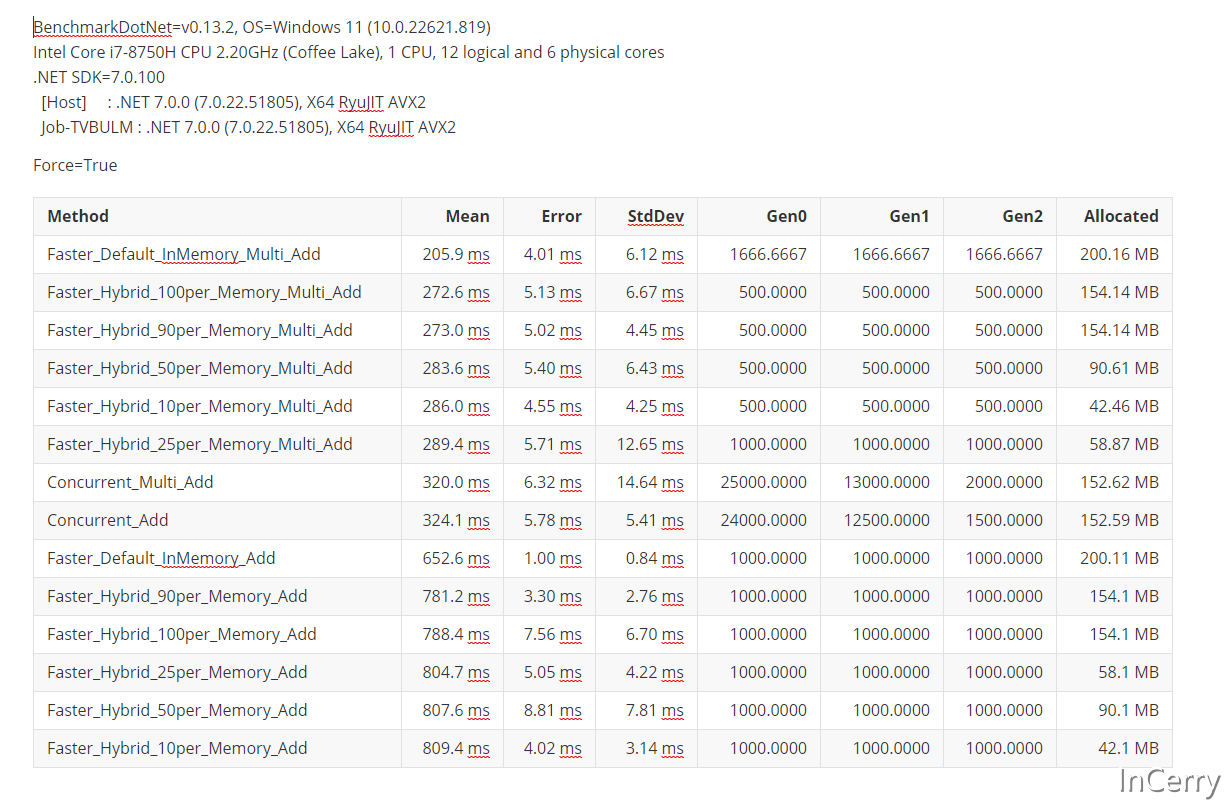
结果如下所示,这里是100%读的场景:
- 似乎内存不足对于FASTER的读性能影响挺大的,这也是必然的结果,毕竟SSD再快也没有内存快
- 另外根据我的测试结果来说,FASTER纯内存模式在100%纯读取的场景没有Concurrent那么快
官方测试结果
由于我的测试结果不是很准确,我又继续查找有没有其它的性能评测的结果,并没有找到什么有价值的。于是从论文和Wiki中找到了一些数据,和大家解读一下我比较感兴趣的部分。
Faster论文
这是在Faster 2018年的论文中提到的一些,如下所示:
https://www.microsoft.com/en-us/research/uploads/prod/2018/03/faster-sigmod18.pdf
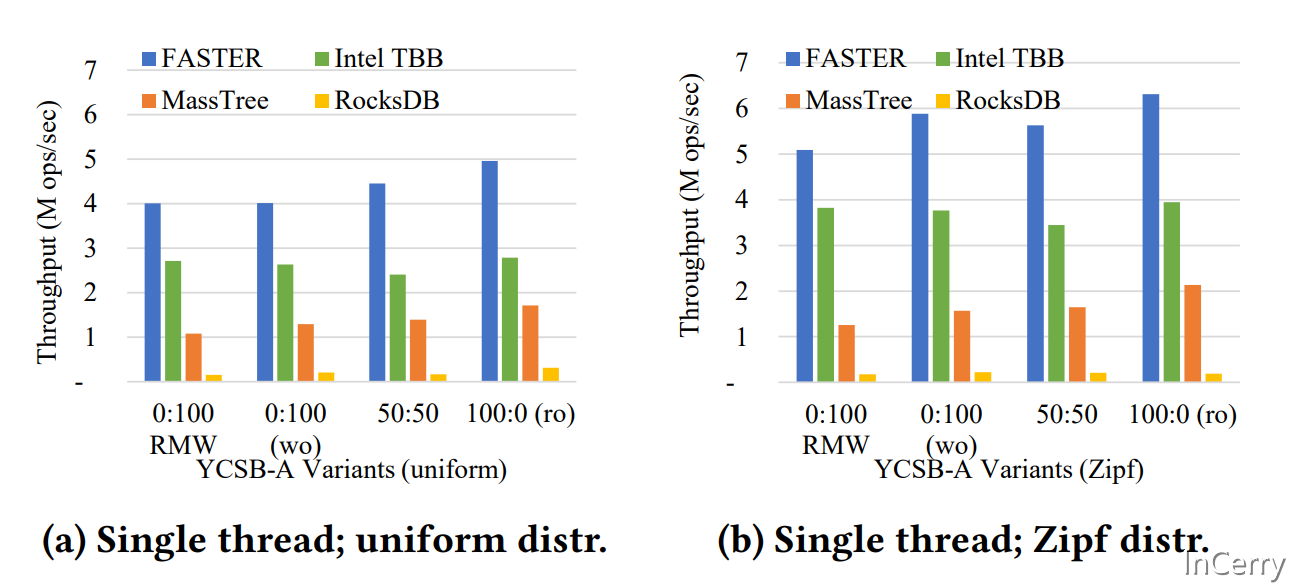
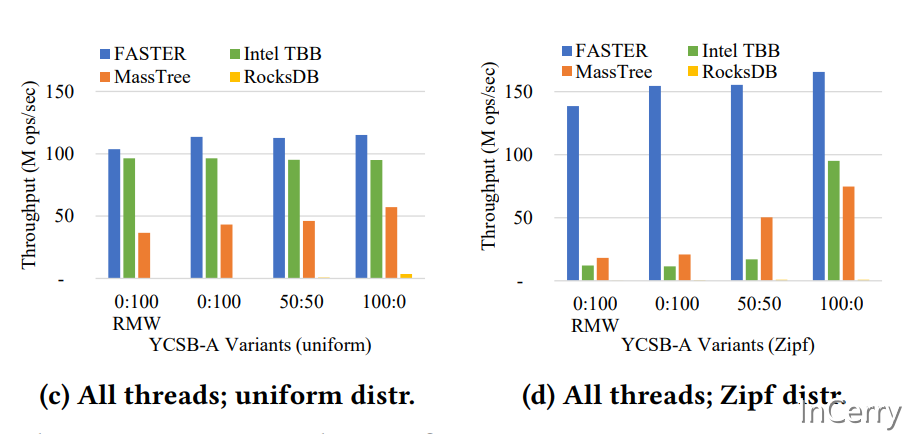
上图是单线程情况下,跑YCSB-A(uniform)数据集和YCSB-A(Zipf)数据集的结果。可以看到在单线程的场景,FASTER速度远超于同类Intel TBB、MassTree、RocksDB等数据库。
文中的0:100、50:50、100:0是代表全写、50%写50读、全读的场景。另外FASTER支持Read-Modify-Write,RMW就是代表进行这个操作的性能。
Yahoo! Cloud Serving Benchmark (YCSB) 是一个Java语言实现的主要用于云端或者服务器端的数据库性能测试工具,其内部涵盖了常见的NoSQL数据库产品,如Cassandra、MongoDB、HBase、Redis等等。
在多线程的情况下,FASTER的读性能达到了惊人的1.6亿/s。
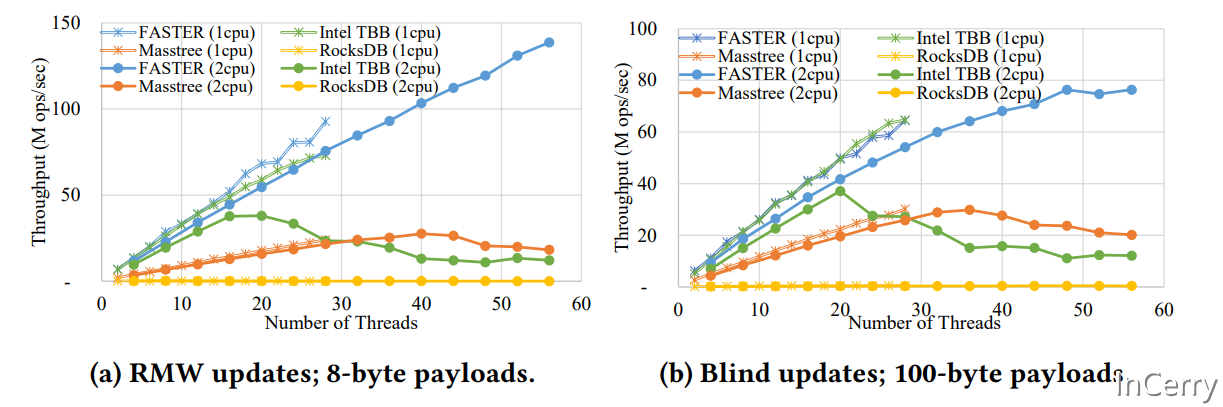
上图是在单核和双核的更新性能数据,可以看到FASTER蓝色的线是远超同类产品,特别是在线程数变多以后,其它都是下降趋势,它是程上升趋势。
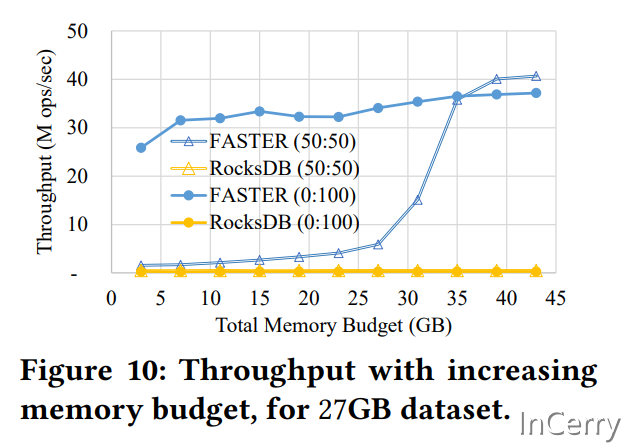
上图是表示,分别在使用5GB~45GB内存加载27GB数据时的吞吐量,分别是50%的读写,和100%的写。可以看到写性能几乎不受内存大小的影响,这也佐证了我的测试结果。
C# FasterKV性能测试
这是翻阅微软Github项目时,看到专门针对于C#的FasterKV和ConcurrentDictionary的测试。不过它只有纯内存模式的测试,并不包含内存+硬盘混合模式。
https://github.com/microsoft/FASTER/wiki/Performance-of-FASTER-in-C%23#introduction
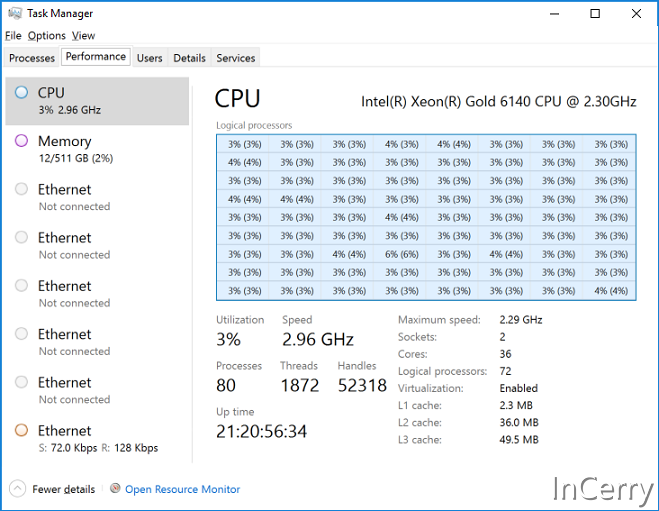
这里它使用了一台36核72线程的512GB服务器进行测试。分别测试大型数据集(2.5亿个键)和小型数据集(250万个键)进行实验。
大数据集场景
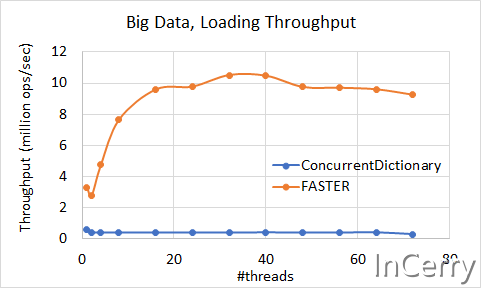
上图是大型数据集的加载速度,可以发现FASTER的加载速度确实很快,是ConcurrentDictionary的好10~50倍,性能还在上涨。
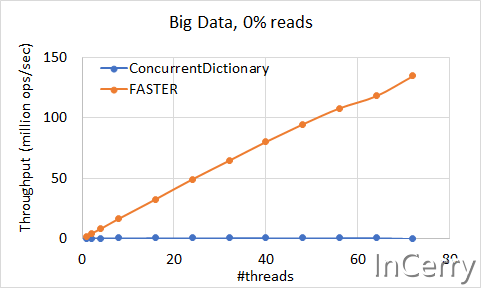
上图是100%写入时的场景,随着线程数量的增加还在上涨,远超ConcurrentDictionary,这和我们的测试结果相符合。
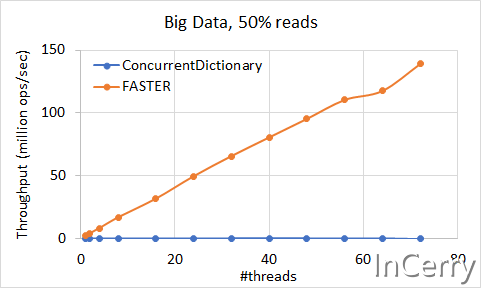
上图是分别进行50%读写的场景,可以发现吞吐量还是非常的不错的。
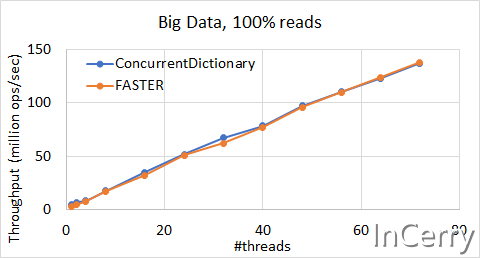
如果是100%纯度的场景,还是ConcurrentDictionary会更好。不过这也不是FASTER的适用场景,因为在这样的工作负载中不存在并发瓶颈,也不存在对内存的写操作。这两个系统都受到读取缓存失败次数的限制,并具有相似的性能。
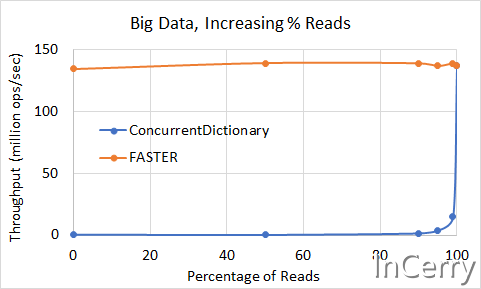
上图显示了来自上面72个线程的数据,以 x 轴上的读取百分比表示。当您的工作负载中涉及到一小部分更新时,FASTER 提供了数量级更好的性能。随着非常高的读取百分比超过90% ,两个系统的性能开始像预期的那样趋于一致。
Int64类型的Key
因为ConcurrentDictionary对(Int32、Int64)类型有特殊的优化,所以将Key的类型替换为Int64做了下面的测试。
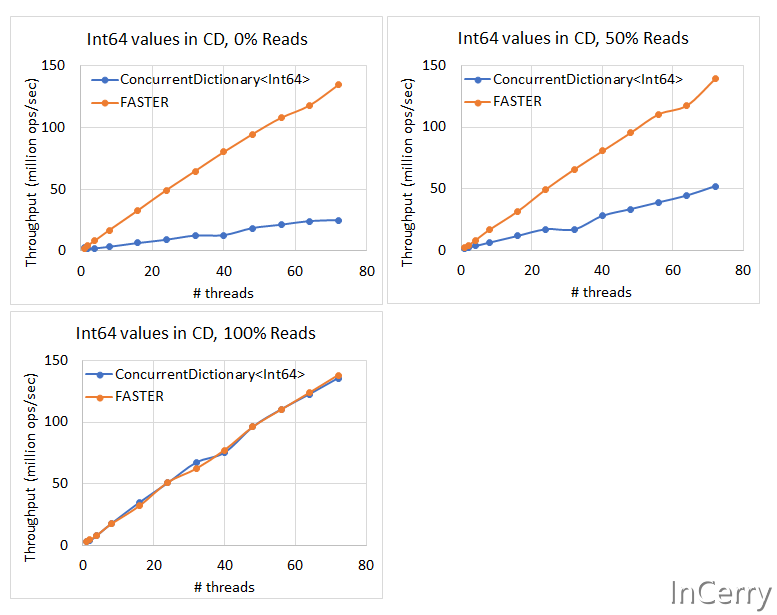
可以看到(Int32、Int64)类型确实让ConcurrentDictionary更快了,不过在有写入操作的场景,还是FASTER更胜一筹。
这也解释了一些我们上面的测试中,为什么ConcurrentDictionary在读场景那么快的原因之一,就是我们用了Int64作为Key。
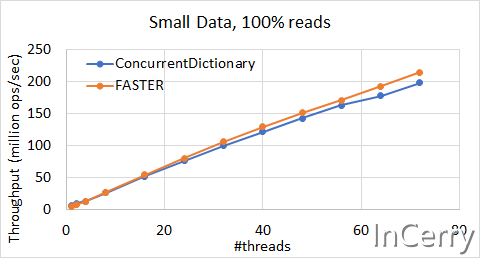
小数据集场景
这个场景我就不解读了,和大数据集场景表现基本一致。
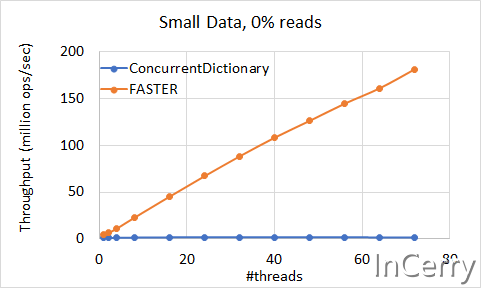
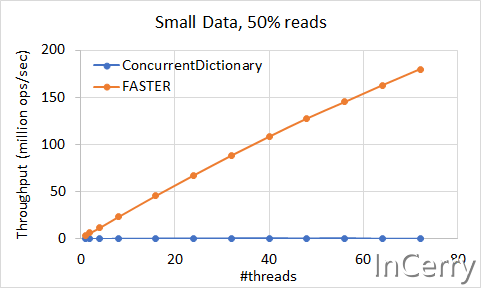
总结
通过对FASTER的测试和翻阅论文,从目前的结果来说,在以下单机场景比较适合使用FASTER:
- 只需要简单的Read、Write和Read-Modify-Write的场景
- 非100%读取操作的场景,这种场景由于没有锁争用,FASTER不如字典
另外FASTER也提供了Server版本,可以通过网络访问。另外在我的测试中,读取性能和官方测试有较大的出入,感觉是使用方法和参数上出了问题,因为FASTER整体还是比较复杂,笔者需要更多的时间去了解原理和测试。
回到最开始的那个问题,FASTER可以作为内存+磁盘进程内缓存使用吗?
我的答案是可以,它虽然比不上纯内存的ConcurrentDictionary,但是有着远超RocksDB等同类KV Store的性能。不过它不适合100%读的缓存,最好是那些既有读,又有写的场景;如果需要100%读,可能我们需要看看其它的工具是否能满足我们的需求。
参考文献及附录
- https://microsoft.github.io/FASTER/docs/fasterkv-basics/
- https://github.com/microsoft/FASTER/wiki/Performance-of-FASTER-in-C%23#introduction
- https://www.microsoft.com/en-us/research/uploads/prod/2018/03/faster-sigmod18.pdf
- https://blog.csdn.net/weixin_43705457/article/details/123133324
聊聊FASTER和进程内混合缓存的更多相关文章
- Java的进程内缓存框架:EhCache (转)
EhCache 是一个纯Java的进程内缓存框架,具有快速.精干等特点,是Hibernate中默认的CacheProvider. Ehcache缓存的特点: 1. 快速. 2. 简单. 3. 多种缓存 ...
- Java的进程内缓存框架:EhCache
EhCache 是一个纯Java的进程内缓存框架,具有快速.精干等特点,是Hibernate中默认的CacheProvider. Ehcache缓存的特点: 1. 快速. 2. 简单. 3. 多种 ...
- Spring Boot 2.x基础教程:进程内缓存的使用与Cache注解详解
随着时间的积累,应用的使用用户不断增加,数据规模也越来越大,往往数据库查询操作会成为影响用户使用体验的瓶颈,此时使用缓存往往是解决这一问题非常好的手段之一.Spring 3开始提供了强大的基于注解的缓 ...
- spring boot:使用spring cache+caffeine做进程内缓存(本地缓存)(spring boot 2.3.1)
一,为什么要使用caffeine做本地缓存? 1,spring boot默认集成的进程内缓存在1.x时代是guava cache 在2.x时代更新成了caffeine, 功能上差别不大,但后者在性能上 ...
- 缓存机制总结(JVM内置缓存机制,MyBatis和Hibernate缓存机制,Redis缓存)
一.JVM内置缓存(值存放在JVM缓存中) 我们可以先了解一下Cookie,Session,和Cache Cookie:当你在浏览网站的时候,WEB 服务器会先送一小小资料放在你的计算机上,Cooki ...
- Android源码——Activity进程内启动
进程内启动Activity MainActivity组件向ActivityManagerService发送一个启动SubActivityInProcess组件的进程间通信请求: ActivityMan ...
- ZeroMQ接口函数之 :zmq_inproc – ØMQ 本地进程内(线程间)传输方式
ZeroMQ API 目录 :http://www.cnblogs.com/fengbohello/p/4230135.html ——————————————————————————————————— ...
- HOOK函数(一)——进程内HOOK
什么是HOOK呢?其实很简单,HOOK就是对Windows消息进行拦截检查处理的一个函数.在Windows的消息机制中,当用户产生消息时,应用程序通过调用GetMessage函数取出消息,然后把消息放 ...
- 在VC6.0下如何调用Delphi5.0开发的进程内COM
因为本人的语言水平很差,考大学时150的总分,我考了个60分.外语也是,初中及格过一次,会考及格过一次.其它的时间好像从没有及格过.所以我不写文章,因我一百字的文章给我写,至少要出八九个错别字.哈哈… ...
- 【转载】进程内COM与进程外COM
原文:http://www.cnblogs.com/jyz/archive/2009/03/08/1406229.html 1.进程内和进程外Com COM/DCOM 组件可以在DLL 或EXE 文档 ...
随机推荐
- C#使用BouncyCastle生成PKCS#12数字证书
背景 生成数字证书用于PDF文档数字签名 数字证书需要考虑环境兼容性,如linux.windows 网上资料不全或版本多样 本文章主要介绍了在C#中使用BouncyCastle生成PKCS#12个人信 ...
- Kotlin快速上手
一.Kotlin基础 1.数据类型声明 在Kotlin中要定义一个变量需要使用var关键字 //定义了一个可以修改的Int类型变量 var number = 39 如果要定义一个常量可以使用val关键 ...
- 写给前端的 react-native 入门指南
前言 本文主要介绍 react-native(下称 RN) 的入门, 和前端的异同点 文章不涉及功能的具体实现 选择优势 我们先说说, 为什么很多人会选择使用 RN .他对应的特性和普通 Web 的区 ...
- ELK技术-IK-中文分词器
1.背景 1.1 简介 ES默认的分词器对中文分词并不友好,所以一般会安装中文分词插件,以便能更好的支持中文分词检索. 本例参考文档:<一文教你掌握IK中文分词> 1.2 IK分词器 IK ...
- 写个续集,填坑来了!关于“Thread.sleep(0)这一行‘看似无用’的代码”里面留下的坑。
"我报名参加金石计划1期挑战--瓜分10万奖池,这是我的第2篇文章,点击查看活动详情" 你好呀,我是居家十三天只出了一次小区门的歪歪. 这篇文章是来填坑的,我以前写文章的时候也会去 ...
- Windows服务器限制进程CPU使用率
在Windows server 2012 之前的服务系统 2008和2008 R2中有系统资源管理器System Resource Manager可以管理系统的CPU和内存使用情况.特别对于一些自己开 ...
- Deployment必须包含资源对象
Deployment 是一个控制器,能够用来控制 pod 数量跟期望数量一致,配置 pod 的发布方式 Deployment 会按照给定策略进行发布指定 pod,保证在更新过程中不可用数量在限定范围内 ...
- 使用Portainer管理其他主机的docker应用有两种方式
官方文档地址:https://docs.portainer.io/v/ce-2.9/admin/environments/add/docker 第一种方式 是在其他主机的docker 启动中放开237 ...
- 在 K8S 上部署以 mysql 数据库作为后端存储的单机版 nacos
Nacos 被用于: 服务发现 微服务配置信息管理 部署 nacos 时,需要用到如下两个镜像,这两个镜像均来自于 nacos 官方发布到 docker hub 的镜像, nacos/nacos-se ...
- Elasticsearch的ETL利器——Ingest节点
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484473&idx=1&sn=1b3b07b ...