[2] Bert 论文精读
BERT是NLP领域让预训练这件事情出圈的工作。
开篇Introduction介绍了两类主流的预训练方法:
1、feature-based,即基于特征的,即我首先通过预训练得到一些比较好的特征,然后将这些特征作为额外的训练数据输入到模型中,从而使得模型在训练起来变得容易很多;
2、fine-tuning,即基于微调的。即我首先用其他数据集做预训练,训练好之后,我再去用我所需要的针对我的任务的数据集做微调,对我的模型的权重做一些小改动。
这两种方法都有一种局限性,即二者都是单向的模型,而Bert不是,正如其名字:Bidirectional Encoder Representations from Transformers
这个idea的主要来源很明确:我们平时处理NLP问题的模型都是单向的,但是虽然我们读一句话的时候总是从左到右这么读下来,但是在做一些其他任务的时候比如阅读理解、Q&A等等问题的时候,我们总会看完整个句子的全貌从而去理解这个句子的文本语义,因此如果能够让模型也做到这一点,效果会不会更好呢?
在conclusion写了,作者其实是把ELM0和GPT的idea拼接在一起,说得简单一些,就是用ELMo的双向,用Transformer实现。但具体到BERT这篇工作,我觉得还有一个更出众的点子在于《完形填空》。
Bert是一个微调模型,即先预训练,然后微调。
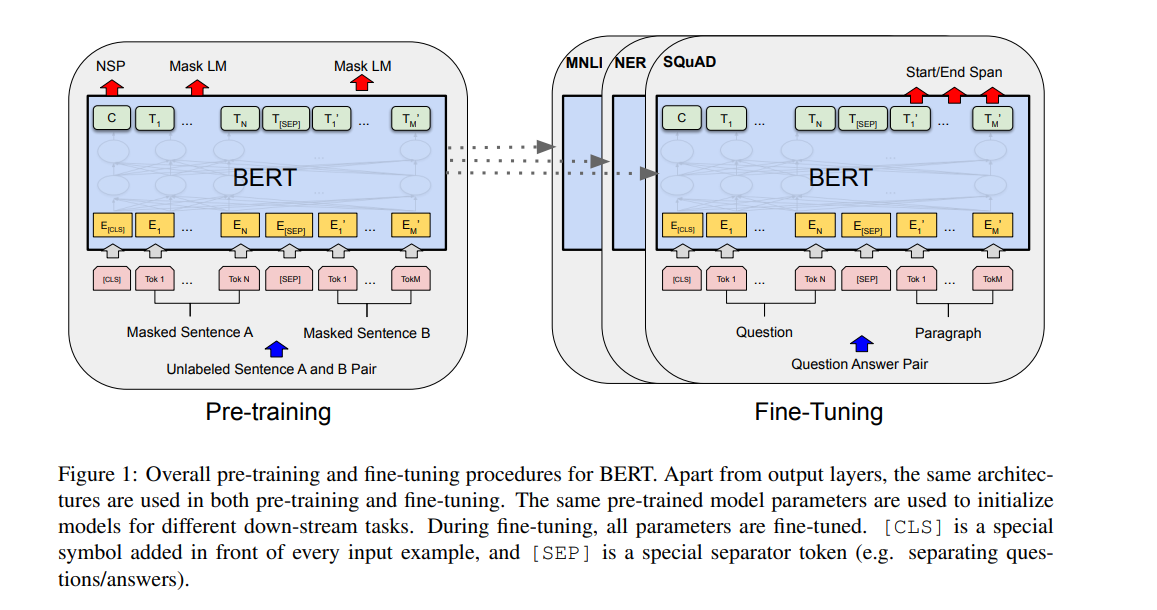
整体上来看,首先用一组没有label的数据做预训练,然后用有标号的对应下游任务的数据集去做微调。
其实说到底,Bert就是一个Transformer,只不过分成了预训练和微调。
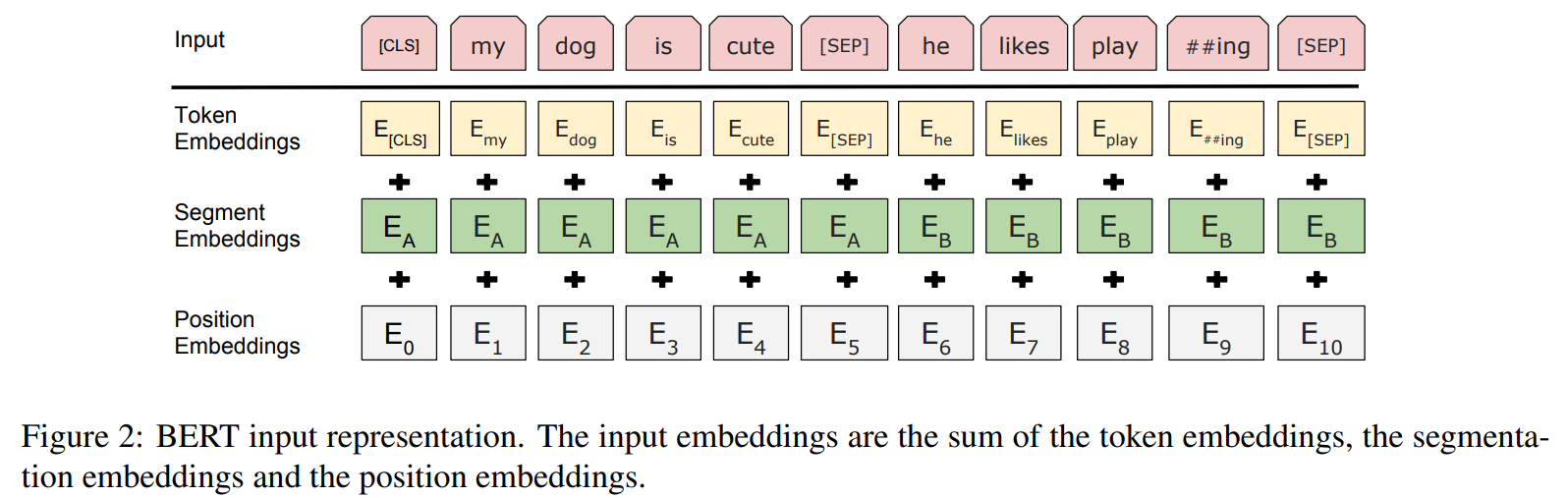
另外注意一下Bert的Embedding是三个:
在做完形填空的时候,Bert用了概率mask的trick。因为他们发现直接mask掉15%的数据存在很多问题,因此选择了另外20%特殊的点。其中,10%为随机替换一个词,我觉得可以理解成噪音;另外10%就是将答案暴露出来,用答案预测答案,算是对mask的一种补偿。
而在做句子连贯性预测的时候,则50%为连贯的一组句子,50%为不连贯。
此外,他还有一个小trick,即Wordpiece,将一些比较长的单词切开。因为长单词往往有多重含义的词根,这些词根组合在一起可以表示一个新的完整的意思,但是这种长单词大部分都出现频率都不是很高,因此将这些内容切开,可以更好地让模型学习到一句话中的语义碎片。比如将homeless拆分成home与less。
然后我发现,作为一篇深度学习的文章,作为一个深度学习模型,Bert竟然没有整体的模型架构!!这真的是我第一次见。
当然了,作者对于这个操作也解释了,“我们基本上是直接把Transformer源码拿过来用了,因此我们也没必要详细再讲一次。”
这个是很值得思考的,作者没有提出新的架构,这确实是一个缝合的文章,但是他却有5w的引用。
Bert更大的特点,我觉得是证明了一点,用更大的数据集训练更大的模型会更好,但其实这个东西早就被证实了。另外就是预训练和微调的理念在NLP的出圈。
[2] Bert 论文精读的更多相关文章
- BERT 论文阅读笔记
BERT 论文阅读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 由 @快刀切草莓君 ...
- 【深度学习 论文篇 02-1 】YOLOv1论文精读
原论文链接:https://gitee.com/shaoxuxu/DeepLearning_PaperNotes/blob/master/YOLOv1.pdf 笔记版论文链接:https://gite ...
- 用深度学习(DNN)构建推荐系统 - Deep Neural Networks for YouTube Recommendations论文精读
虽然国内必须FQ才能登录YouTube,但想必大家都知道这个网站.基本上算是世界范围内视频领域的最大的网站了,坐拥10亿量级的用户,网站内的视频推荐自然是一个非常重要的功能.本文就focus在YouT ...
- BERT论文解读
本文尽量贴合BERT的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进行翻译,其中有一些论文没有解释清楚或者笔者未能深入理解的地方,都有放出原文,如有不当之处,请各位多多包含,并 ...
- bert论文笔记
摘要 BERT是“Bidirectional Encoder Representations from Transformers"的简称,代表来自Transformer的双向编码表示.不同于 ...
- 【DL论文精读笔记】Object Detection in 20 Y ears: A Survey目标检测综述
目标检测20年综述(2019) 摘要 Abstract 该综述涵盖了400篇目标检测文章,时间跨度将近四分之一世纪.包括目标检测历史上的里程碑检测器.数据集.衡量指标.基本搭建模块.加速技术,最近的s ...
- AFM论文精读
深度学习在推荐系统的应用(二)中AFM的简单回顾 AFM模型(Attentional Factorization Machine) 模型原始论文 Attentional Factorization M ...
- Faster-RCNN论文精读
State-of-the-art object detection networks depend on region proposal algorithms to hypothesize objec ...
- 【DL论文精读笔记】 深度压缩
深度压缩 DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFM ...
- 【DL论文精读笔记】Image Segmentation Using Deep Learning: A Survey 图像分割综述
深度学习图像分割综述 Image Segmentation Using Deep Learning: A Survey 原文连接:https://arxiv.org/pdf/2001.05566.pd ...
随机推荐
- 艰难的 debug 经历,vscode 无法获取远程环境 ssh 报错,windows 11 ssh
背景介绍 要做系统结构实验,学校和华为云合作使用华为云的 aarch64 裸机,需要使用 ssh 远程开发,笔者为了追求良好的开发体验,决定使用 vscode 开发,实验环境配置过程中遇到了两个问题, ...
- Typora下载与安装 0.9.75版本
Typora下载与安装 效果图 一.简介 一款 Markdown 编辑器和阅读器 (0.9.75 版本 不需购买) 二.下载 下载地址:Typora 三.安装 1.下载文件后双击安装 2. 选择存放的 ...
- el-table 在第一行添加合计行和操作按钮
1.预计效果如下 2.前端及样式部分 1)el-table <el-table size="small" stripe style="width: 100%&quo ...
- Golang HTTP编程及源码解析
1.网络基础 基本TCP客户-服务器程序Socket编程流程如如下图所示. TCP服务器绑定到特定端口并阻塞监听客户端端连接, TCP客户端则通过IP+端口向服务器发起请求,客户-服务器建立连接之后就 ...
- MFC中的RTTI(Runtime Type Identification, 运行时类型识别)详解(参考《深入浅出MFC》)
在MFC中的RTTI的实现,主要是利用一个名为CRuntimeClass的结构来链接各个"有关系的类"的信息来实现的.简单来说,就是在需要用到RTTI技术的类内建立CRuntime ...
- LinkedList内部实现原理
LinkedList内部实现原理 java list 同ArrayList内部原理一样 我们先创建一个LinkedList对象LinkedList<String> li = new Lin ...
- PostgreSQL数据库运行日志
PostgreSQL运行日志可以实现日志输出记录,默认是没有启动记录.这个日志一般是记录服务器与DB的状态,比如各种Error信息,定位慢查询SQL,数据库的启动关闭信息,发生checkpoint过于 ...
- AI 能多强「GitHub 热点速览」
不知道 AI 在你那边是什么样的具象,在我这就是各种搞图:从给线稿图上色,到直接给你生成一张小色图,AI 最近是真出风头,本周热点速览也收录了 2 个 AI 项目,也和图像有关.还有一个和 AI 相关 ...
- Supported OPs and DPU Limitations
Currently Supported Operators source:https://www.xilinx.com/html_docs/xilinx2019_2/vitis_doc/zmw1606 ...
- AttributeError: module 'requests' has no attribute 'get' 报错分析
这个报错与代码时没有关系 当文件名与调用模块名重合时,系统找不到我们调用的requests模块. 在命名时,我们要注意不要重合.