Scrapy爬虫框架快速入门
安装scrapy
pip install scrapy -i https://pypi.douban.com/simple/
安装过程可能遇到的问题
- 版本问题导致一些辅助库没有安装好,需要手动下载并安装一个辅助库Twisted
- 运行时候:ModuleNotFoundError: No module named 'attrs'
pip install attrs --upgrade - 运行时候:Loading "scrapy.core.downloader.handlers.http.HTTPDownload Handler" for scheme "https"
pip install pywin32
创建项目
CMD进入需要创建项目的目录下,输入命令
scrapy startproject ×××

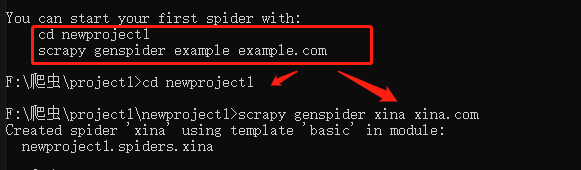
命令基本不需要死记硬背,正如下图所示,会告诉你接下来需要输入的命令
设置实体文件(建立要获取的字段)
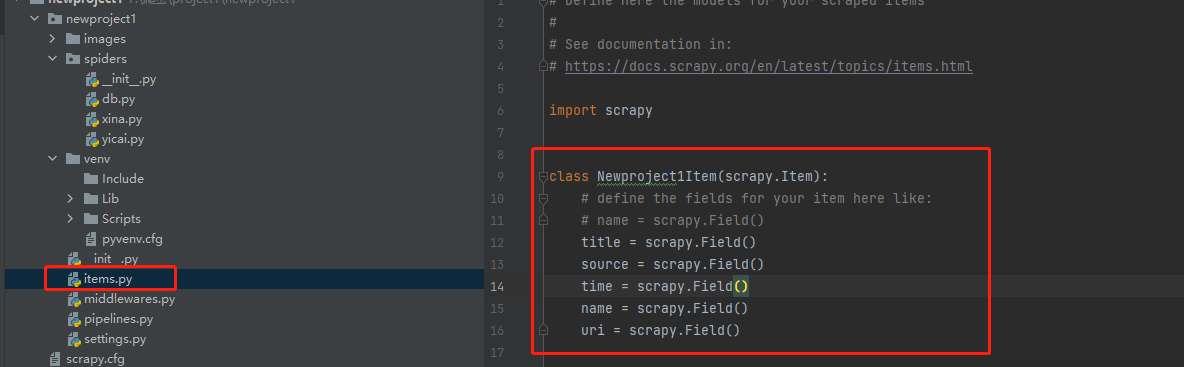
这个文件内会写入后续需要爬取的字段,scrapy.Field()就是变量存储区域,通过“spiders”里的爬虫文件获取的内容都会存储在此处设置的区域里。
然后以实体文件作为中转站,将这些变量传输到其他文件中,例如,传输到管道文件中进行数据存储等处理。设置完实体文件,就可以在实战中应用刚才创建的变量了。
修改设置文件(设置Robots协议和User-Agent,激活管道文件)
运行爬取文件可能会遇到DEBUG:Forbidden by robots txt 说明百度的Robots协议禁止Scrapy框架直接爬取。
解决这个问题可以通过设置文件20行左右的位置把OBEY置为False

设置User-Agent同样在设置文件40行左右位置,添加一行User-Agent

要进行数据的爬后处理,即将数据写入数据库或文件等后续操作。所以先要激活管道
后面的数字只是排序的顺序,越小越靠前
如果管道文件有新增类名,就需要在这里添加

在文件夹“spiders”中编写爬虫逻辑(核心爬虫代码)
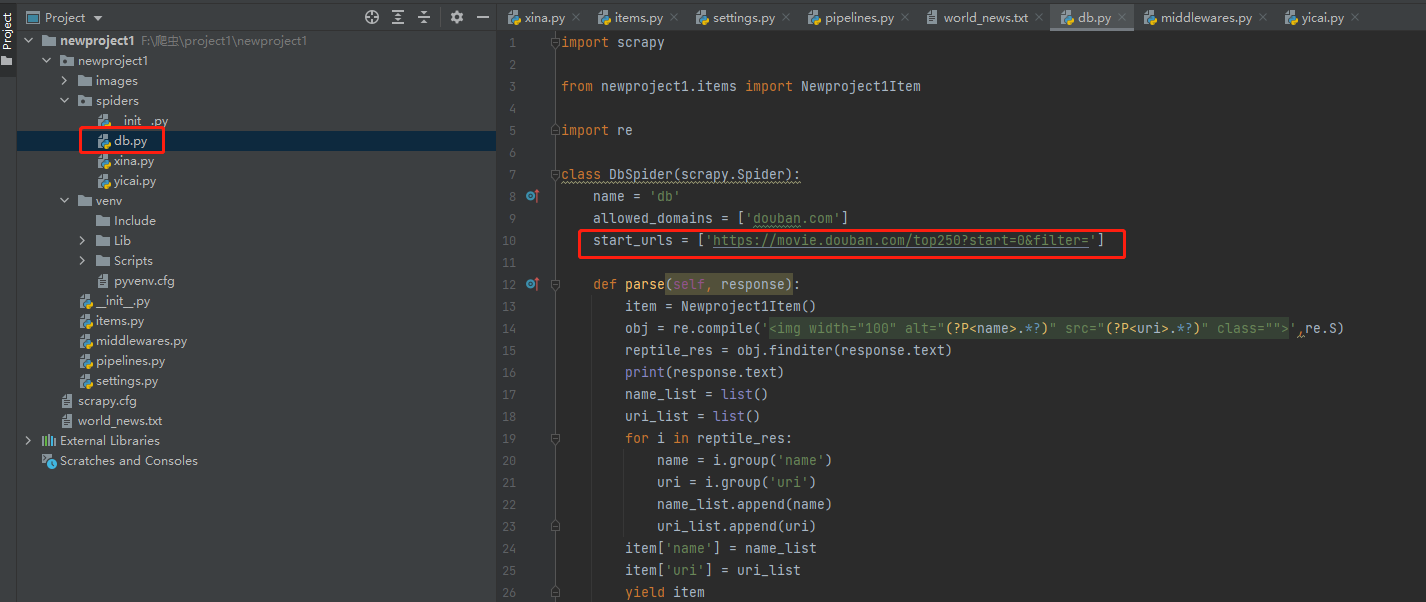
第10 行start_urls是一个列表存放需要爬取的url,如果需要爬取多个地址(例如存在ajex动态页面爬取),可以往这个start_urls列表中append多个地址
爬虫代码基本都在parse中
第13行实例化items,就是实例化需要提取的字段
后面几行都是基本的爬虫代码这里就解释了,需要说一下的是response.text才是网页源代码
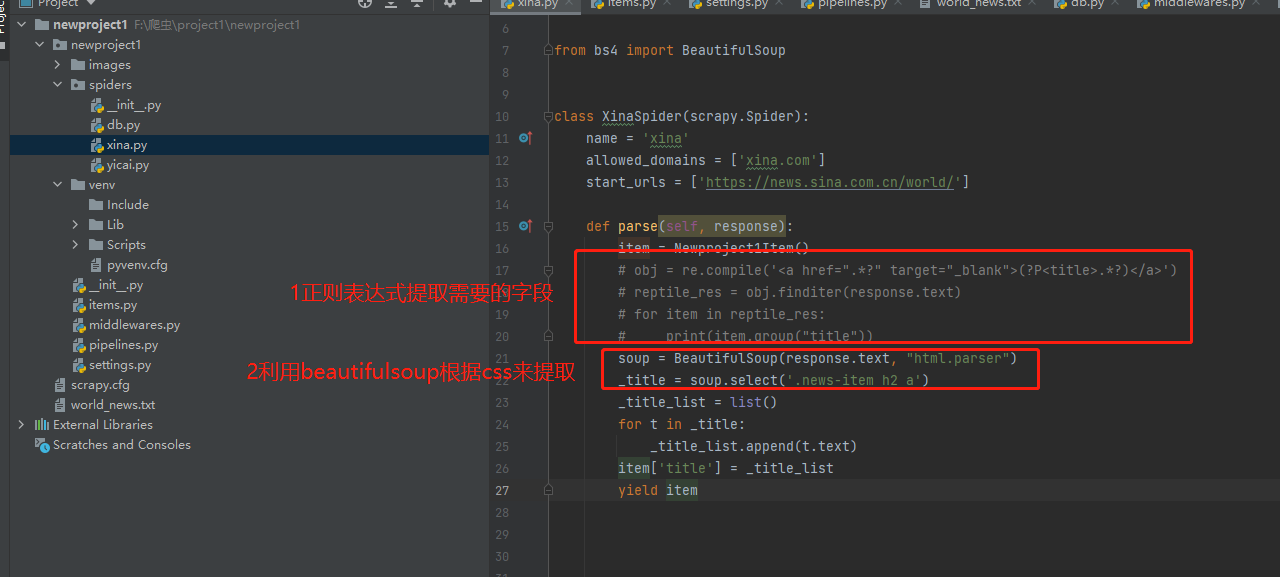
注:除了常见的用正则表达式提取,还有一个库比较常见就是Beautifulsoup
设置管道文件(爬后处理)
爬取后需要存入文件或者下载文件
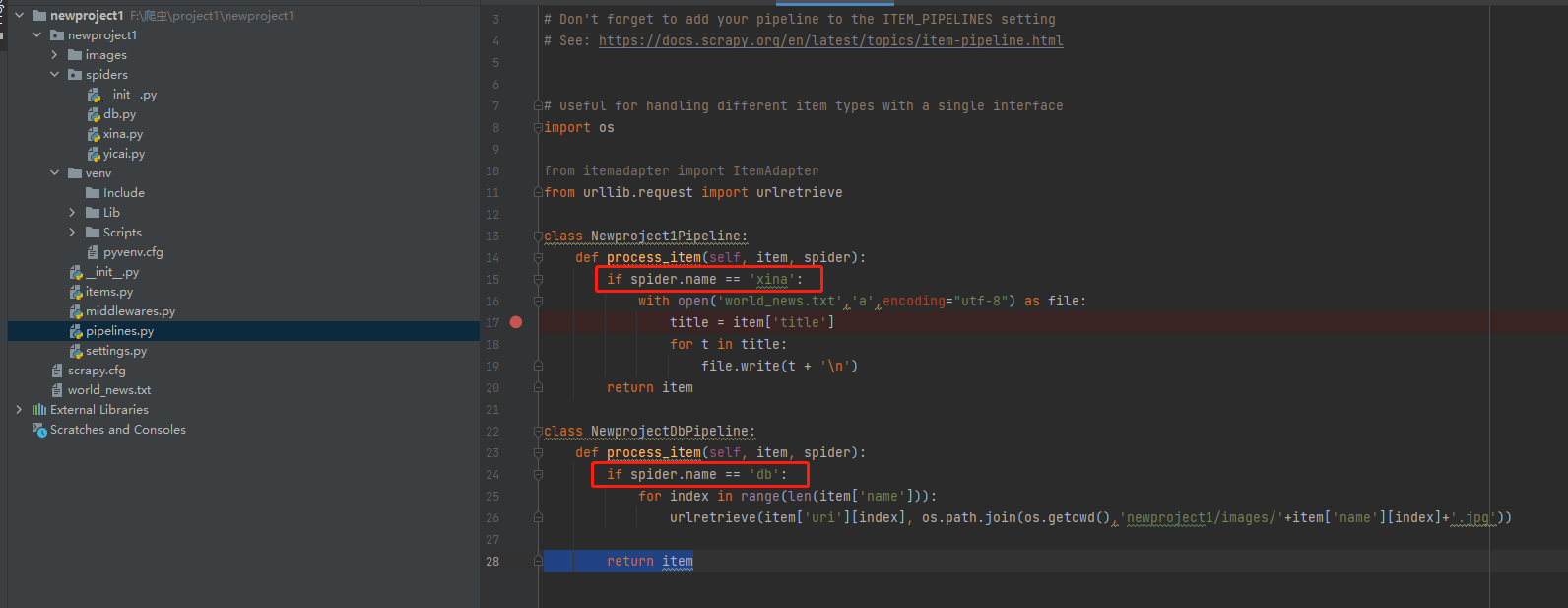
这里需要说一下,第15行和第24行去判断spider.name是为了在运行的时候进行区分。
当然写管道的时候,可以把所有处理方式写在一个类中,通过spider.name去进行区分,也可以像下图一样用不同的类去写。但如果是不同的类就需要到设置文件中把新增类添加到设置中去。
第26行urlretrieve()函数是用来下载图片
最后运行
最后在命令行输入
scrapy crawl ****
Scrapy爬虫框架快速入门的更多相关文章
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- Scrapy爬虫框架与常用命令
07.08自我总结 一.Scrapy爬虫框架 大体框架 2个桥梁 二.常用命令 全局命令 startproject 语法:scrapy startproject <project_name> ...
随机推荐
- c++算法竞赛常用板子集合(持续更新)
前言 本文主要包含算法竞赛一些常用的板子,码风可能不是太好,还请见谅. 后续会继续补充没有的板子.当然我太菜了有些可能写不出来T^T 稍微有些分类但不多,原谅我QwQ 建议 Ctrl + F 以快速查 ...
- JDK8下载安装及环境配置
Java基础知识 Java的三种版本 JavaSE :标准版,主要用于开发桌面程序,控制台开发等等 JavaME:嵌入式开发,主要用于开发手机,小家电等等,目前使用的比较少 JavaEE:企业级开发, ...
- 前端性能优化——首屏时间&&白屏时间
1.首屏时间概念 首屏时间是指用户打开一个网站时,直到浏览器首页面内容渲染完成的时间. 2.白屏时间概念 白屏时间即是,浏览器开始显示内容的时间,所以我们一般认为解析完<head>的时刻, ...
- Nginx反向代理实现Tomcat+Jpress和halo
一.利用Nginx反向代理Jpress+Tomcat 1.环境准备 服务器 IP地址 作用 系统版本 Proxy代理服务器 10.0.0.101 负载均衡Nginx Web服务器 Ubuntu2004 ...
- Python基础指面向对象:2、动静态方法
面向对象 一.动静态方法 在类中定义的函数有多种特性 1.直接在类中定义函数 再类中直接定义函数,默认绑定给对象,类调用时有几个参数就要传几个参数,对象调用时该函数的第一个参数默认为对象 # 定义 ...
- LAPM概述及配置
一.LAMP概述 1.1LAMP的概念 LAMP架构是目前成熟的企业网站应用模式之一,指的是协同工作的一整套系统和相关软件,能够提供动态web站点服务及其应用开发环境 LAMP是一个缩写词,具体包括L ...
- 「浙江理工大学ACM入队200题系列」问题 L: 零基础学C/C++85——完美数
本题是浙江理工大学ACM入队200题第八套中的L题 我们先来看一下这题的题面. 题面 题目描述 任何一个自然数的约数中都有1和它本身,我们把小于它本身的因数叫做这个自然数的真约数. 如6的所有真约数是 ...
- 部署redis集群
1.redis部署 redis单实例部署参考:https://www.cnblogs.com/silgen/p/16537299.html 版本:6.2.7 集群:6个节点(redis集群至少3个节点 ...
- webpack 配置echarts 按需加载
引入babel-plugin-equire插件,方便使用.yarn add babel-plugin-equire -D 在.babelrc文件中的配置 { "presets": ...
- docker使用代理(in home)
docker 使用 http http_proxy https://docs.docker.com/config/daemon/systemd/ # 代理 和 国内 镜像源 不要 同时使用,... # ...