使用Harr特征的级联分类器实现目标检测
前言
最近在学习人脸的目标检测任务时,用了Haar人脸检测算法,这个算法实现起来太简洁了,读入个.xml,调用函数就能用。但是深入了解我发现这个算法原理很复杂,也很优秀。究其根源,于是我找了好些篇相关论文,主要读了2001年Paul Viola和Michael Jones在CVPR上发表的一篇可以说是震惊了计算机视觉的文章,《Rapid Objection Dection using a Boosted Cascade of Simple Features》。这个算法最大的特点就是快!在当时,它能够做到实时演示人脸检测效果,这在当时的硬件情况下是非常震惊的,且还具有极高的准确率。同时在2011年,这篇论文在科罗多拉的会议上获得了“十年内影响最为深远的一篇文章”。在我们知道这篇文章有多么的NB之后,接下来我们来细细的品味这篇文章的技术细节。
根据论文Abstract描述,该论文主要有三个巨大贡献:
- 第一个贡献是引入了“积分图”的图像表示方法,它能够加快检测时的计算速度;
- 第二个贡献是提出了一个基于AdaBoost的学习算法,它能够从大量的数据中提取少量且有效的特征来学习一个高效的分类器;
- 第三个贡献是提出了注意力级联的算法,它能够让分类器更多聚焦于object-like区别,而不是与被检测目标无关的背景图像等区域,也是极大的加快了目标检测速度。
总结起来就是,Haar级联算法实际上是使用了boosting算法中的AdaBoost算法,Harr分类器用AdaBoost算法构建了一个强分类器进行级联,而再底层特征特区上采用的是更加高效的矩形特征以及积分图方法,即:
Haar分类器 = Haar-like特征 + 积分图法 + AdaBoost算法 + 级联
1. Haar-like特征提取
注意:由于原论文中对于Haar-like特征的描述过少,很多细节不完整,这部分将会详细介绍论文中没有讲的算法细节。
1.1 基本Haar特征
Haar-like是一种非常经典的特征提取算法,尤其是它与AdaBoost组合使用时对人脸检测有着非常不错的效果。虽然一般提及到Haar-like的时候,都会和AdaBoost、级联分类器、人脸检测、积分图一起出现,但是Haar-like本质上只是一种特征提取算法。它涉及到了三篇经典论文,尤其是第三篇论文,让它快速发展。
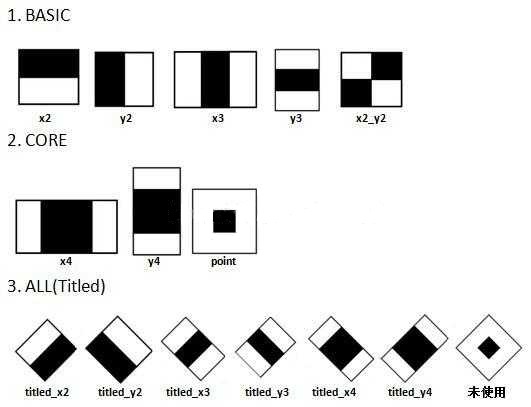
最原始的Haar-like特征是在《A general framework for object detection》中提出的,它定义了四个基本特征结构,如下图所示:
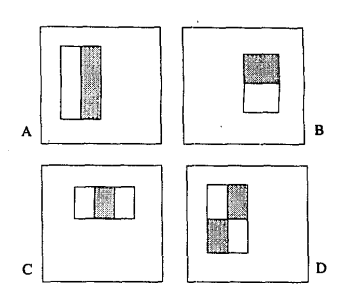
可以将这个它们理解成为一个窗口,这个窗口将在图像中做步长为1的滑动,最终遍历整个图像。它的整体遍历过程是:当一次遍历结束后,窗口将在宽度或长度上,窗口将在宽度或长度上成比例的放大,再重新之前遍历的步骤,直到放大到最后一个比例后结束(放大的最大比例一般是与原图像相同大小比例)。
例子:以x3特征为例,在放大+平移过程中白:黑:白面积比始终是1:1:1。首先在红框所示的检测窗口中生成大小为3个像素的最小x3特征;之后分别沿着x和y平移产生了在检测窗口中不同位置的大量最小3像素x3特征;然后把最小x3特征分别沿着x和y放大,再平移,又产生了一系列大一点x3特征;然后继续放大+平移,重复此过程,直到放大后的x3和检测窗口一样大。这样x3就产生了完整的x3系列特征。
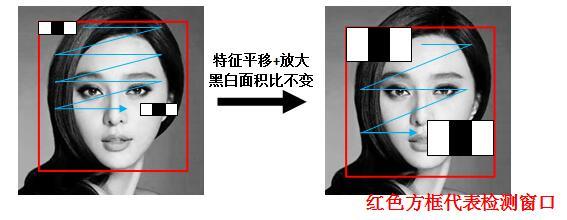
同样,通过我们上文中关于Haar-like特征的遍历过程可知,Haar特征可以在检测窗口中由放大+平移产生(黑:白区域面积比始终保持不变)。那么这些通过放大 + 平移的子特征总共有多少个呢?Rainer Lienhart在他的论文中给出了解释:假设检测窗口大小为\(W*H\),矩阵特征大小为\(w*h\),X和Y为表示矩形特征在水平和垂直方向能放大的最大比例系数:
Y = [\frac{H}{h}]
\]
其中\(W\)和\(H\)是整个图像的宽高,\(w\)和\(h\)是Harr窗口的初始宽高,可以放大的倍数为\(X·Y\)。
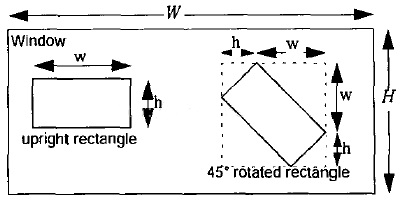
根据以上,在检测窗口Window中,一般矩形特征(upright rectangle)的数量为:
\]
以x3的特征(即特征大小的pixel为1x3)为例来解释这个公式:
- 特征框竖直放大1倍,即无放大,竖直方向有(H-h+1)个特征
- 特征框竖直放大2倍,竖直方向有(H - 2h + 1)个特征
- 特征框竖直放大3倍,竖直方向有(H - 3h + 1)个特征
- 如此到竖直放大Y = floor(H/h)倍,竖直方向有1个特征,即(H-Y*h+1)
那么竖直方向总共有:
(H - h + 1) + (H - 2h + 1) + (H - 3h + 1) + ...... + (H - Y*h + 1) = Y[H + 1 - h(1 + Y)/2]个特征。水平方向同理可得。
考虑到水平和竖直方向缩放是独立的,当x3特征在24*24大小的检测窗口时,此时(W=H=24,w=3,h=1,X=8,Y=24),一共能产生27600个子特征。
1.2 扩展Haar特征
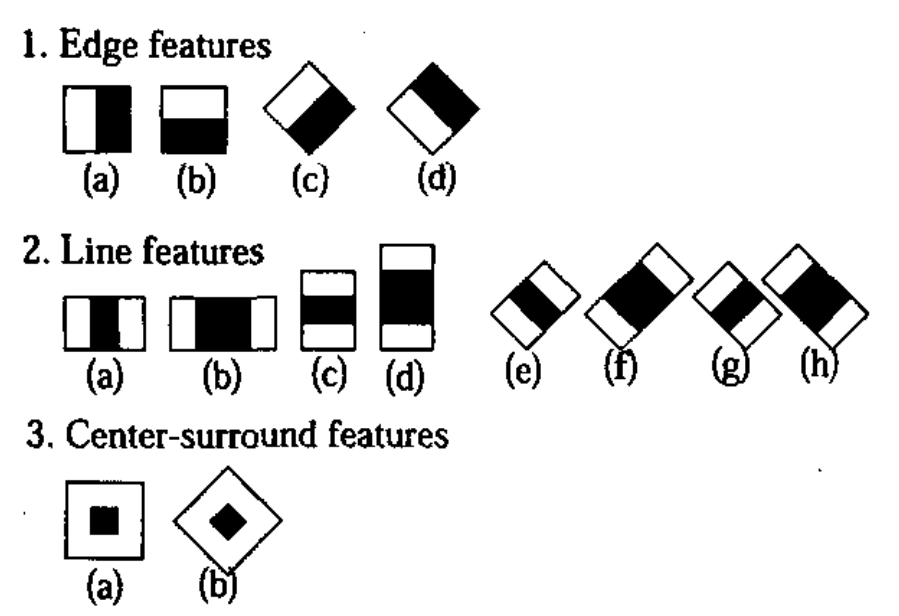
在基本的四个Haar特征基础上,文章《An entended set of Haar-like features for rapid objection detection》将原来的4个特征拓展为14个。这些拓展特征主要增加了旋转性,能够提取到更丰富的边缘信息。比如:如果一张要检测的人脸不是人脸,是一张侧脸的时候,此时基本的四个Haar特征就没法对其进行有效的特征提取,于是其提出了以下拓展的Haar-like特征:
1.3 Haar特征值的计算
关于Haar特征的计算,按照Opencv代码,Haar特征值 = 整个Haar区域像素和 x 权重 + 黑色区域内像素和 x 权重。
\]
比如上图中的x3和y3特征,其\(weight_{all}=1,weight_{black}=-3\),上图中的\(point\)特征,\(weight_{all}=1,weight_{black}=-9\);其余11种特征均为\(weight_{all}=1,weight_{black}=-2\)。
所以,对于x2特征的特征值 = (黑 + 白) * 1 + 黑 * (-2) = 白 - 黑,对于Point特征值 = (黑 + 白) * 1 + 黑 (-9) = 白 - 8 * 黑。这个就是很多文章种所提到的”特征值=白色区域像素和减去黑色区域像素和”。
为什么要这样设置这种加权相减呢?由于有些特征它的黑白面积不相等,有的特征黑白面积相等,设置权值可以抵消黑白面积不等而带来的影响,保证所有Haar特征的特征值在灰度分布绝对均匀的图中为0(比如图像所有像素相等,那么它的特征值就会是0)。
接下来我们再对特征值的含义进行一个解释。以MIT人脸库中2706个大小为20*20的人脸正样本图像为数据,计算下图中位置的Haar特征值,结果如图所示:
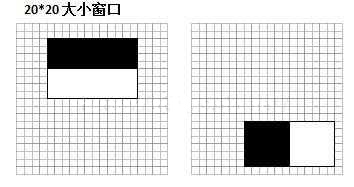
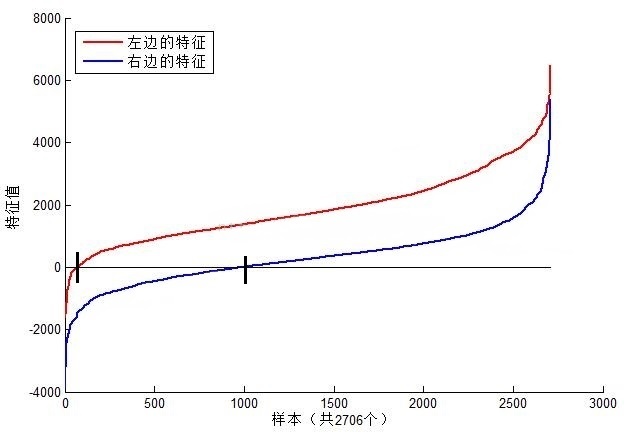
上图中左边特征结果为红色,右边为蓝色。可以看到,2个不同的Haar特征在同一组样本中具有不同的特征值分布,左边特征计算出的特征值基本都大于0,而右边特征的特征值基本均匀分布于0两侧(分布越均匀对样本的区分度越小)。正是由于样本中Haar特征值分布不同,导致了不同Haar特征分类效果不同。显而易见,对样本区分度越大的特征分类效果越好,即红色曲线对应的左边的Haar特征分类效果好于右边的Haar特征。同时,我们结合人脸可以知道,这个特征可以表示眼睛要比脸颊的颜色要深,因为能够很有效的进行区分。
总结之下,我们可以知道:
- 在检测窗口通过平移 + 放大可以产生一系列的Haar特征(也就是说,黑白面积比例相同,但是大小不同的特征可以算作多个特征),这些特征由于位置和大小不同,分类效果也各异。
- 通过计算Haar特征的特征值,可以有效将图像矩阵映射为1维特征值,有效实现了降维。
1.4 Haar特征的保存
在OpenCV的XML文件中,每一个Haar特征都被保存在2~3个形如:
\]
的标签,其中x和y代表Haar矩形左上角坐标(以检测窗口的左上角为原点),width和height表示矩形的宽和高,weight表示权重值。
1.5 Haar特征值标准化
由上图中两个特征计算的特征值可以发现,一个1218大小的Haar特征计算出的特征值变换范围从-2000 ~ +6000,跨度非常的大。这种跨度大的特性不利于量化评定特征值,所以需要进行数据标准化来压缩特征值范围。假设当前检测窗口中的图像为i(x,y),当前检测窗口为wh大小。OpenCV中标准化步骤如下:
计算检测窗口中间部分(w - 2) * (h - 2)的图像灰度值和灰度值平方和
\[sum = \sum i(x,y), sqsum = \sum i^2(x,y)
\]计算平均值:
\[mean = \frac{sum}{w*h} \\
sqmean = \frac{sqsum}{w*h}
\]计算标准化因子
- \[varNormFactor = \sqrt{sqmean - mean^2}
\] 标准化特征值:
\[normValue = \frac{featureValue}{varNormFactor}
\]
注意:在检测和训练时,数据标准化的方法一定要一致,否则可能由于标准化不同带来的误差导致模型无法工作。
2. 积分图计算
与Haar紧密相连的就是积分图了,它源自于这篇论文《Rapid Object Dection using a boosted cascade of simple features》,它使用积分图的方法快速计算了Haar特征。在上文中我们提到过,当x3特征在24*24大小的检测窗口(W=H=24,w=3,h=1,X=8,Y=24)滑动时,一共能产生27600个子特征。在计算这些特征值时,我们会有很多次重复且无效的计算,那么积分图的提出就是为了让其计算的更加高效。积分图只需要遍历一次图像就可以求出图像中所有区域像素和的快速算法,大大提高了图像特征值计算的效率。
积分图主要的思想是将图像从起点开始到各个点所形成的矩形区域像素之和作为一个数组的元素保存在内存中,当要计算某个区域的像素和时可以直接索引数组的元素,不用重新计算这个区域的像素和,从而加快了计算(这有个相应的称呼,叫做动态规划算法)。积分图能够在多种尺度下,使用相同的时间(常数时间)来计算不同的特征,因此大大提高了检测速度。
积分图是一种能够描述全局信息的矩阵表示方法。积分图的构造方式是:位置(,)处的值(,)是原图像(,)左上角方向所有像素(,)的和:
\]
积分图构建算法:
用s(i,j)表示行方向的累加和,初始化s(i,-1)=0;
使用ii(i,j)表示一个积分图像,初始化ii(-1,i) = 0;
逐行扫描图像,递归计算每个像素(i,j)行方向的累加和s(i,j)和积分图像ii(i,j)的值
\[s(i,j) = s(i,j-1) + f(i,j) \\
ii(i,j) = ii(i-1.j) + s(i,j)
\]扫描图像一遍,当到达图像右下角像素时,积分图ii就构建好了。
积分图构建好之后,图像中的任何矩阵区域的累加和都可以通过简单运算得到如图所示:
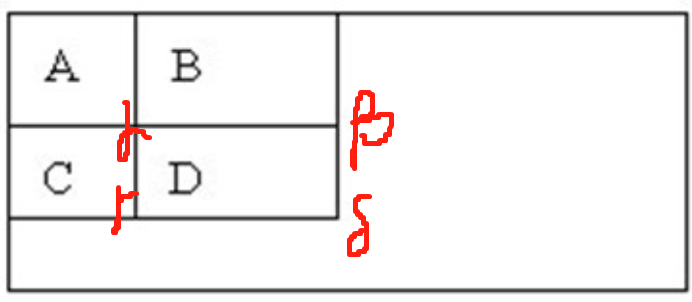
设D的四个顶点分别为α,β,γ,δ则D的像素和可以表示为
\]
而Haar-like特征值无非就是两个矩阵像素和的差,可以在常数时间内完成。
3. AdaBoost
Boosting方法是一种重要的集成学习技术,能够将预测精度仅比随即猜测略高的弱学习器增强为预测精度高的强学习器,这在直接构造学习器非常困难的情况下,为学习算法设计提供了一种有效的新思路和新方法,其中AdaBoost算法应用最广。
AdaBoost的全称是 Adaptive Boosting(自适应增强)的缩写,它的自适应在于:前一个基本分类器被错误分类的样本的权重会增大,而正确分类的样本的权重会减小,并再次用来训练下一个基本分类器。这样一来,那么被分错的数据,在下一轮就会得到更大的关注,所以,分类问题被一系列的弱分类器“分而治之”。同时,对弱分类器的组合,AdaBoost采用加权多数表决的方法,即加大分类器误差率小的弱分类器的权值,使其在表决中其较大作用,减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。AdaBoost的过程中的两个关键点是要把握两个权重的更新方法,一个是迭代时数据的权重更新,一个是迭代时分类器的权重更新【即下图中的模型系数】
算法步骤如下(下图来自李航的《统计学习方法》一书):


鉴于如果要写AdaBoost的例题讲解会占用很长的篇幅,而网上的资料及书籍很多,我就贴在下面了,如果想要真正理解AdaBoost算法训练过程,请看以下李航老师的《统计学习方法》中的案例或者下列网站:
如果你看完了其中一篇博客,我相信你已经能够理解AdaBoost算法了。那么对于下面这张图中的分类器学习算法
4. AdaBoost级联分类器
4.1 弱分类器结构
Haar特征和弱分类器的关系很简单,一个完成的弱分类器包括:
- 若干个Haar特征 + 和Haar特征数量相等的弱分类器阈值
- 若干个LeftValue
- 若干个RightValue
这些元素共同构成了弱分类器,却一不可。比如Haarcascade_frontalface_alt2.xml的弱分类器Depth=2,包含了2种形式,我们以下图为例:其包含2个Haar特征、1个LeftValue、2个RightValue和2个弱分类器阈(t1和t2)
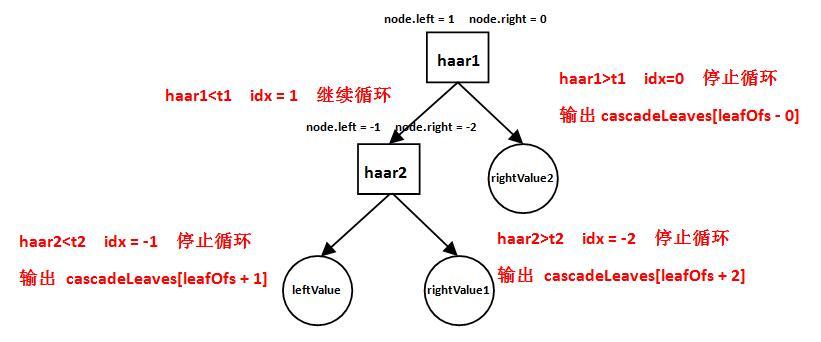
由图可知,它的工作方式如下:
- 计算第一个Haar特征的特征值haar1,与第一个弱分类器阈值t1对比,当haar1<t1时,进入步骤2;当haar1>t1时,该弱分类器输出rightValue2并结束。
- 计算第二个Haar特征值haar2,与第二个弱分类器阈值t2对比,当haar2<t2时输出leftValue;当haar2>t2时输出rightValue1。
即弱分类器的工作方式:通过计算出的Haar特征值与弱分类器阈值对比,从而选择最终输出leftValue和rightValue值中的哪一个。
4.2 强分类器结构
在OpenCV中,强分类器是由多个弱分类器“并列”而成,即强分类器中的弱分类器是两两互相独立的。在检测目标时,每个弱分类器独立运行并输出cascadeLeaves[leafOfs - idx]值,然后把当前强分类器中每一个弱分类器的输出值相加,即:
\]
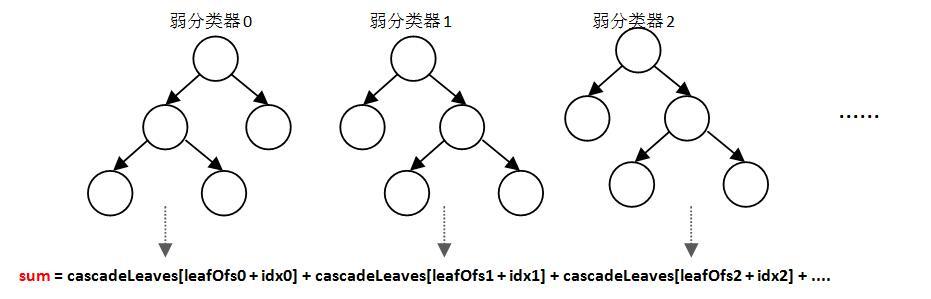
注意:leafOfs表示当前弱分类器中leftValue和rightValue在该数组中存储位置的偏移量,idx表示在偏移量leafOfs基础上的leftValue和rightValue值的索引,cascadeLeaves[leafOfs - idx]就是该弱分类器的输出.
之后与本级强分类器的stageThreshold阈值对比,当且仅当结果sum>stageThreshold时,认为当前检测窗口通过了该级强分类器。当前检测窗口通过所有强分类器时,才被认为是一个检测目标。可以看出,强分类器与弱分类器结构不同,是一种类似于“并联”的结构,我称其为“并联组成的强分类器”。
缩小图像就是把图像按照一定比例逐步缩小然后滑动窗口检测,如下图所示;
放大检测窗口是把检测窗口长宽按照一定比例逐步放大,这时位于检测窗口内的Haar特征也会对应放大,然后检测。

4.3 如何搜索目标
当检测窗口大小固定时,为了找到图像中不同位置的目标,需要逐次移动检测窗口(窗口中的Haar特征相应也随之移动),这样就可以遍历到图像的每一个位置;而为了检测到不同大小的目标,一般有两个做法:逐步缩小图像 or 逐步放大检测窗口。
4.4 级联分类器
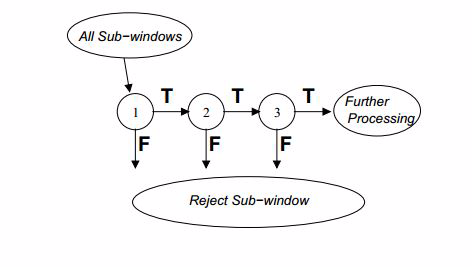
级联分类模型是树状结构可以用下图表示:
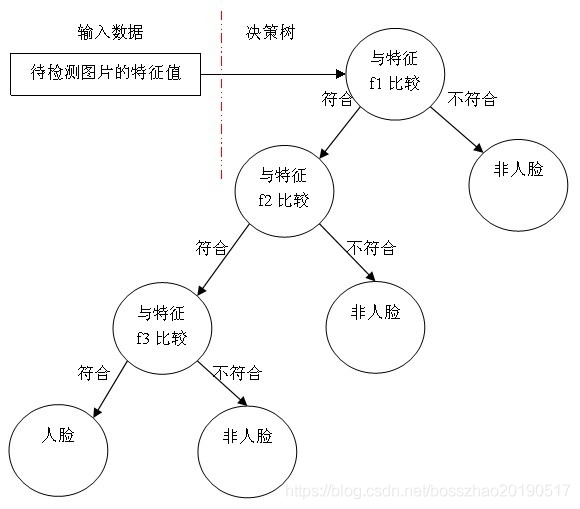
其中每一个stage都代表一级强分类器。当检测窗口通过所有的强分类器时才被认为是正样本,否则拒绝。实际上,不仅强分类器是树状结构,强分类器中的每一个弱分类器也是树状结构。由于每一个强分类器对负样本的判别准确度非常高,所以一旦发现检测到的目标位负样本,就不在继续调用下面的强分类器,减少了很多的检测时间。因为一幅图像中待检测的区域很多都是负样本,这样由级联分类器在分类器的初期就抛弃了很多负样本的复杂检测,所以级联分类器的速度是非常快的;只有正样本才会送到下一个强分类器进行再次检验,这样就保证了最后输出的正样本的伪正(false positive)的可能性非常低。
4.5 级联分类器的训练
4.5.1 弱分类器的训练步骤
级联分类器是如何训练的呢?首先需要训练出每一个弱分类器,然后把每个弱分类器按照一定的组合策略,得到一个强分类器,我们训练出多个强分类器,然后按照级联的方式把它们组合在一块,就会得到我们最终想要的Haar分类器。
一个弱分类器就是一个基本和上图类似的决策树,最基本的弱分类器只包含一个Haar-like特征,也就是它的决策树只有一层,被称为树桩(stump)。
以24x24的图像为例,如果直接用27600个特征使用AdaBoost训练,工作量是巨大的。所以必须有个筛选的过程,筛选出T个优秀的特征值(即最优弱分类器),然后把这个T个最优弱分类器传给AdaBoost进行训练。
现在有人脸样本2000张,非人脸样本4000张,这些样本都经过了归一化,大小都是20x20的图像。那么,对于78,460中的任一特征\(f_i\),我们计算该特征在这2000人脸样本、4000非人脸样本上的值,将这些特征值排序,然后选取一个最佳的特征值,在该特征值下,对于特征\(f_i\)来说,样本的加权错误率最低。
在确定了训练子窗口中(20x20的图像)的矩形特征数量(78,460)和特征值后,需要对每一个特征\(f\),训练一个弱分类器\(h(x,f,ρ,Θ)\) :
h(x,f,ρ,Θ) =\left\{
\begin{aligned}
1,ρf(x)<ρΘ \\
0,other \\
\end{aligned}
\right.
\]
其中f为特征,\(\theta\)为阈值,p指示不等号的方向,x代表一个检测的子窗口。对每个特征f,训练一个弱分类器\(h(x,f,ρ,Θ)\),就是确定f的最优阈值\(\theta\),使得这个弱分类器对所有训练样本分类误差最低。
弱分类器训练的具体步骤:
1、对于每个特征 ,计算所有训练样本的特征值,并将其排序:
2、扫描一遍排好序的特征值,对排好序的表中的每个元素,计算下面四个值:
计算全部正例的权重和+;
计算全部负例的权重和−;
计算该元素前之前的正例的权重和+;
计算该元素前之前的负例的权重和−;
选取当前元素的特征值\(F_{k,j}\)和它前面的一个特征值\(F_{k,j-1}\)之间的数作为阈值,所得到的弱分类器就在当前元素处把样本分开 —— 也就是说这个阈值对应的弱分类器将当前元素前的所有元素分为人脸(或非人脸),而把当前元素后(含)的所有元素分为非人脸(或人脸)。该阈值的分类误差为:
\[e = min(S^+ + (T^- - S^-),S^- + (T^+ - S^+))
\]
于是,通过把这个排序表从头到尾扫描一遍就可以为弱分类器选择使分类误差最小的阈值(最优阈值),也就是选取了一个最佳弱分类器。
由于一共有78,460个特征、因此会得到78,460个最优弱分类器,在78,460个特征中,我们选取错误率最低的特征,用来判断人脸,同时用此分类器对样本进行分类,并更新样本的权重
4.5.2 强分类器的训练步骤
给定训练样本集\(x_i,y_i\),i=1,2,4,5...N,共N个样本,\(y_i\)取值为0(负样本)或者1(正样本);设正样本的数量为\(n_1\),负样本的数量为\(n_2\);T为训练的最大循环次数;
初始化样本权重为\(\frac{1}{n_1+n_2}\),即为训练样本的初始概率分布
for t = 1,...T:
权重归一化:
\[w_{t,i} = \frac{w_{t,i}}{\sum_{j-1}^{n}w_{t,j}}
\]对每一个特征j,训练一个分类器\(h_j\);每个分类器只使用一种Haar特征进行训练,分类误差为:
\[ε_j = \sum_i{w_j|h_j(x_i) - y_i|}
\]从上一个步骤确定的分类器中,找出一个具有最小分类误差的弱分类器\(h_t\)。
更新每个样本对应的权重
\[w_{t+1,i} = w_t,i\beta_t^{1-e_i}
\]如果样本\(x_i\)被正确分类,则\(e_i=0\),否则\(e_i=1\),而
\[\beta_t = \frac{ε_t}{1-ε_t}
\]
最终形成的强分类器为:
\[h(x)=\left\{
\begin{aligned}
1,\sum_{t=1}^Tα_th_t(x) \geq \frac{1}{2}\sum_{t=1}^Tα_t \\
0,otherwise\end{aligned}
\right.
\]其中,\(α_t = log\frac{1}{\beta_t}\)
在使用Adaboost算法训练分类器之前,需要准备好正、负样本,根据样本特点选择和构造特征集。由算法的训练过程可知,当弱分类器对样本分类正确,样本的权重会减小;而分类错误时,样本的权重会增加。这样,后面的分类器会加强对错分样本的训练。最后,组合所有的弱分类器形成强分类器,通过比较这些弱分类器投票的加权和与平均投票结果来检测图像。
4.5.3 强分类器级联及训练
为了提高人脸检测的速度和精度,最终的分类器还需要通过几个强分类器级联得到。在一个级联分类系统中,对于每一个输入图片,顺序通过每个强分类器,前面的强分类器相对简单,其包含的弱分类器也相对较少,后面的强分类器逐级复杂,只有通过前面的强分类检测后的图片才能送入后面的强分类器检测,比较靠前的几级分类器可以过滤掉大部分的不合格图片,只有通过了所有强分类器检测的图片区域才是有效人脸区域。
这也对应了前文提到的该论文所提到的第三个重要贡献,第三个成果是在一个在级联结构中连续结合更复杂的分类器的方法,通过将注意力集中到图像中有希望的地区,来大大提高了探测器的速度。在集中注意力的方法背后的概念是,它往往能够迅速确定在图像中的一个对象可能会出现在哪里。更复杂的处理仅仅是为这些有希望的地区所保留。
训练过程如下:

根据论文来看,AdaBoost训练出来的强分类器一般具有较小的误识率,但是检测率不高。正确率就是TPR,误检率是FDR。
FalsePositiveRate = \frac{FP}{FP+TN},代表将真实负样本划分为正样本的概率
\]
较小的误识率的意思就是给我一个人脸特征,我把它判别为人脸特征的概率很高。检测率不是很高的意思就是给我一个不是人脸的特征,我将它划分为人脸特征的概率很高。
一般情况下,高检测率会导致高误识率,这是强分类阈值的划分导致的,要提高强分类器的检测率就要降低阈值,要降低强分类器的误识率就要提高阈值,这是个矛盾的事情。据参考论文的实验结果,增加分类器个数可以在提高强分类器检测率的同时降低误识率,所以级联分类器在训练时要考虑如下平衡,一是弱分类器的个数和计算时间的平衡,二是强分类器检测率和误识率之间的平衡。
另外在检测的过程中,因为TPR较高,所以一旦检测到某区域不是目标就可以直接停止后续检测。由于在人脸检测应用中非人脸区域占大部分,这样大部分检测窗口都能够很快停止,是分类速度得到很大的提高。
从上面所述内容我们可以总结Haar分类器训练的步骤:
- 寻找TP和FP作为训练样本
- 计算每个Haar特征在当前权重下的Best split threshold+leftvalue+rightvalue,组成了一个个弱分类器
- 通过WSE寻找最优的弱分类器
- 更新权重
- 按照minHitRate估计stageThreshold
- 重复上述1-5步骤,直到falseAlarmRate到达要求,或弱分类器数量足够。停止循环,输出stage。
- 进入下一个stage训练
5. 总结
写了好多了,这篇博客其实对《Rapid Objection Dection using a Boosted Cascade of Simple Features》的一个学习笔记,但是由于这篇论文在很多地方都交代的不是很清晰,而这个算法的原理又相当复杂,所以在学习的过程中我还额外看了一些与这篇论文相关的paper,以及借鉴了国内国外相关资料。关于这个算法,我觉得这篇论文中还有一些很细节的地方没有讲清楚,而我觉得这些细节也是能否成功复现这篇论文的关键点。比如如何有必要的对重叠的检测结果窗口进行合并,同时剔除零散分布的错误检测窗口,该功能就是NMS(Non-maximum suppresion),解决这种情况所用到的并查集(Union-Set)算法,是一种数据结构,我目前还在学习思考这一块儿的内容。再者,虽然我知道了AdaBoost、级联分类器的整体训练过程,但是具体到复现那个层次来描述整个算法的训练过程,我我还需要继续的去学习源代码。
学习完这篇算法的细节后,我进一步明白了,真的不要当一个调参侠。这个算法的python实现就那么几行,参数是那些个,实现起来可能很简单也很帅。但是这个算法的源代码的复杂程度、原理的精妙性,才是我们应该去重点关心的。尤其是搞人工智能这个领域的。
~:如果您发现文章中有出错的地方,欢迎您指正。同时也欢迎您在留言区讨论问题,共同学习。私信可E-mail:graywei2001@163.com.
6. 参考文献
[2] OpenCV AdaBoost + Haar目标检测技术内幕(上)
[3] OpenCV AdaBoost + Haar目标检测技术内幕(下)
[4] Python+OpenCV图像处理(九)——Haar特征描述算子
[5] Face Detection with Haar Cascade
[6] Face Detection with Haar Cascade — Part II
[7] Rapid Object Detection using a Boosted Cascade of Simple Features中英版
使用Harr特征的级联分类器实现目标检测的更多相关文章
- OpenCV中基于Haar特征和级联分类器的人脸检测
使用机器学习的方法进行人脸检测的第一步需要训练人脸分类器,这是一个耗时耗力的过程,需要收集大量的正负样本,并且样本质量的好坏对结果影响巨大,如果样本没有处理好,再优秀的机器学习分类算法都是零. 今年3 ...
- OpenCV开发笔记(五十五):红胖子8分钟带你深入了解Haar、LBP特征以及级联分类器识别过程(图文并茂+浅显易懂+程序源码)
若该文为原创文章,未经允许不得转载原博主博客地址:https://blog.csdn.net/qq21497936原博主博客导航:https://blog.csdn.net/qq21497936/ar ...
- [OpenCV]基于特征匹配的实时平面目标检测算法
一直想基于传统图像匹配方式做一个融合Demo,也算是对上个阶段学习的一个总结. 由此,便采购了一个摄像头,在此基础上做了实时检测平面目标的特征匹配算法. 代码如下: # coding: utf-8 ' ...
- OpenCV使用级联分类器实现人脸检测
一.概述 案例:使用opencv级联分类器CascadeClassifier+其提供的特征数据实现人脸检测,检测到人脸后使用红框画出来. API介绍:detectMultiScale( InputAr ...
- 利用Hog特征和SVM分类器进行行人检测
在2005年CVPR上,来自法国的研究人员Navneet Dalal 和Bill Triggs提出利用Hog进行特征提取,利用线性SVM作为分类器,从而实现行人检测.而这两位也通过大量的测试发现,Ho ...
- 使用级联分类器实现人脸检测(OpenCV自带的数据)
#include <opencv2/opencv.hpp> #include <iostream> using namespace cv; using namespace st ...
- opencv5-objdetect之级联分类器
这是<opencv2.4.9tutorial.pdf>的objdetect module的唯一一个例子. 在opencv中进行人脸或者人眼 或者身体的检测 首先就是训练好级联分类器,然后就 ...
- 机器学习-分类器-级联分类器训练(Train CascadeClassifier )
一.简介: adaboost分类器由级联分类器构成,"级联"是指最终的分类器是由几个简单分类器级联组成.在图像检测中,被检窗口依次通过每一级分类器,这样在前面几层的检测中大部分的候 ...
- OpenCV开发笔记(七十一):红胖子8分钟带你深入级联分类器训练
前言 红胖子,来也! 做图像处理,经常头痛的是明明分离出来了(非颜色的),分为几块区域,那怎么知道这几块区域到底哪一块是我们需要的,那么这部分就涉及到需要识别了. 识别可以自己写模板匹配.特征 ...
随机推荐
- DDOS流量攻击
0x01 环境 包含2台主机 attact 作为攻击方,使用Centos7.2 windows_server ,用于被攻击,同时抓包分析流量 ,任意版本均可.安装wireshark,用于抓包 0x02 ...
- SpringMVC实现文件上传功能
文件上传 文件上传要求form表单的请求方式必须为post,并且添加属性enctype="multipart/form-data" SpringMVC中将上传的文件封装到Multi ...
- grep 命令?
强大的文本搜索命令,grep(Global Regular Expression Print) 全局正则表达式搜索.grep 的工作方式是这样的,它在一个或多个文件中搜索字符串模板.如果模板包括空格, ...
- 使用SpringDataJdbc无法注册的情况
当 EnableJdbcRepositories 注解无法注册Repository仓库的时候,你可以查看下 你的实体是否存在@Table注解,没有请加上,这样就能扫描到了 @Table("b ...
- 利用事件的冒泡特性,为子标签添加Onclick事件
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <m ...
- 修改if-else多层嵌套的方法
例子:在判断三角形形状的一个程序中,会出现 if-else 的多层嵌套,可利用程序的顺序执行结构重构代码,使其更可读.如果还想保证代码的安全性,可以用函数封装这段代码. #include <st ...
- js技术之如何在JS中获取input的值
在JavaScript中获取input元素value的值: 方法一:var variations_number = $("#input的id名").val(); 1 <!DO ...
- 03-三高-并行并发&服务集群
三高项目 服务并行&并发 并行和并发 服务的搭建中,并行 并发.----并发. 集群 同质的(同样的配置,运行同样的程序,对外提供同样的服务). 修改同样的存储,可以认. (小建议 ...
- d面试题汇总
HTML Doctype作用,HTML5 为什么只需要写<!DOCTYPE HTML>? html5有哪些新特性?移除了哪些元素? 简述一下你对HTML语义化的理解? 行内元素有哪些,块级 ...
- 订单突破10000+,仅花1小时,APPx独家深入剖析背后的秘密!
拼多多:成立三年,获客三亿,月订单成交额达到恐怖的400亿,成功上市! 糕妈优选:营销活动推送1小时,订单超过10000+,商品成功刷屏朋友圈! 寻慢:一场活动净增7000+粉丝,付款转化率高达71% ...