47.DRF实现分页
分页Pagination
前端分页和后端分页的区别
前端分页
后端分页
如何选择分页
数据量比较小的时候建议一次性返回数据在前端进行分页,数据量庞大的话建议服务器分页单次请求单次返回
DRF中的分页
DRF中的分页介绍
- 将分页链接作为响应内容的一部分
- 响应头中包含分页链接,比如Content-Range或Link
- 可以通过将分页类设置None来选择是否关闭分页功能
自有分页VIew源码示例
# ListModelMixin源码 如果是常规view要实现分页,在视图中实现下述代码即可
class ListModelMixin:
def list(self, request, *args, **kwargs):
queryset = self.filter_queryset(self.get_queryset())
# self.paginate_queryset对原有的queryset数据集进行分页
page = self.paginate_queryset(queryset)
# 如果页号不为空
if page is not None:
#返回对应页的数据
serializer = self.get_serializer(page, many=True)
return self.get_paginated_response(serializer.data)
# 如果页号为空则返回全部数据
serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data)分页的settings设置
REST_FRAMEWORK = {
# drf的分页类位于rest_framework.pagination中
"DEFAULT_PAGINATION_CLASS":"",# 全局默认的指定分页类,如果视图想单独指定,与权限一样在view中单独设置
"PAGE_SIZE": #每一页显示多少数据
}DRF中的分页类使用详解
BasePagination:

PageNumberPagination:
# settings.py
REST_FRAMEWORK = {
# 指定分页类为PageNumberPagination
"DEFAULT_PAGINATION_CLASS":"rest_framework.pagination.PageNumberPagination",
"PAGE_SIZE":3 #每一页显示3条数据
}- 图1是没有设置分页时候的请求,返回全部6条数据
- 图2设置了分页后,默认不传page参数的请默认返回了第一页的数据
- 图3请求地址后加了page参数,page=2,则返回的是第二页的数据
- 也可以看出设置分页后response多了三个参数count是接口一共的数量,next是下一页的地址,previous是上一页地址

PageNumberPagination自定义分页类
from rest_framework import pagination
# 继承分页类
class PublicPagination(pagination.PageNumberPagination):
page_size = 2 # 每页显示的默认数据个数
page_query_param = 'page' # 页号,第几页的参数 ,比如定义为pages,那么请求分页的参数就应该是pages
page_size_query_param = 'page_size' # 自己指定每页显示多少个数
max_page_size = 100 # 最大允许设置的每页显示的数量
# last_page_strings用于指定表示请求最后一页的参数
# page=last的时候会直接到最后一页
# 如果不改参数的话,可以不用设置,不设置的话默认参数就是last
last_page_strings = 'last'
'''
自定义分页类
通过page_size指定默认的每页数据量,
page_size_query_param指定每页自定义的数据量的参数,如果请求page_size=4,则每页显示4个,否则走默认的2
max_page_size是允许设置的每页最大的数据量
'''# 导入自定义的分页类
from .pagination import PublicPagination
class CategoryViewSet(ModelViewSet):
queryset = Category.objects.all()
serializer_class = CategorySerializer
# 指定自定义的分页类,与权限、限量等不同,每个视图只允许指定一个分页类
# 对指定视图设置分页类,会覆盖settings中默认的全局配置
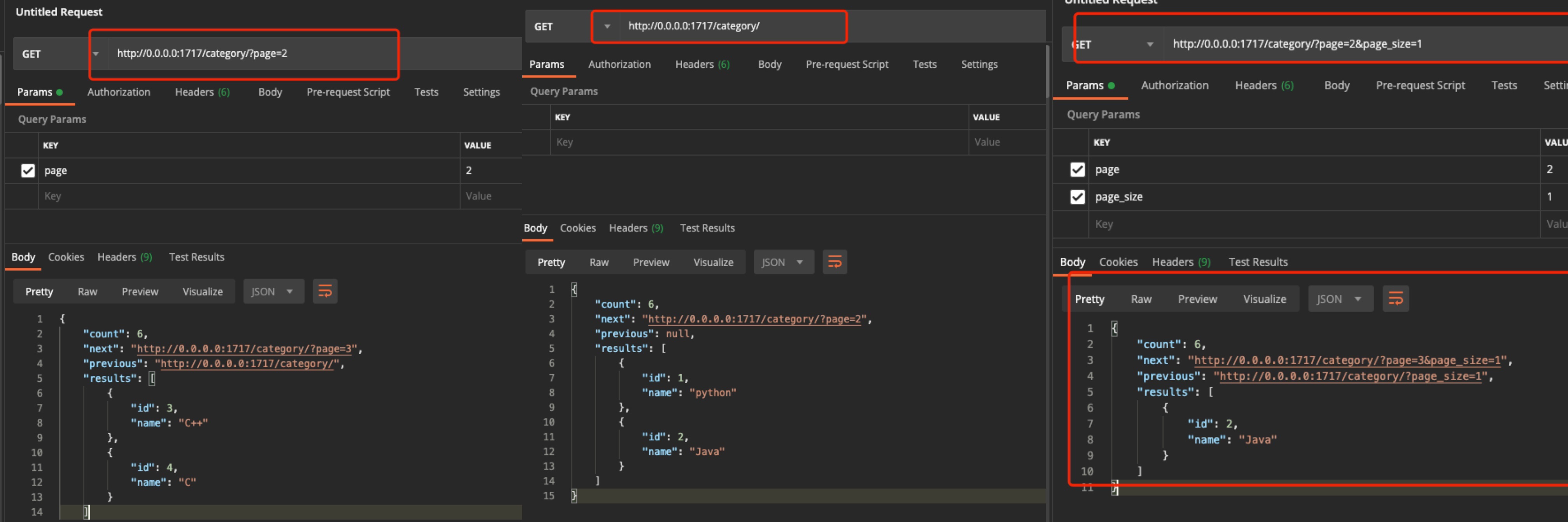
pagination_class = PublicPagination- 图1page=2,请求第二页的数据,返回2条,因为自定义分页类中的page_size覆盖了全局的page_size=3
- 图2没有指定page参数,默认返回第一页的两条数据
- 图3指定page=2,page_size=1,返回第二页的数据,用page_size指定1覆盖代码中设置的2,所以只显示1条数据
LimitOwsetPagination:
#view
class CategoryViewSet(ModelViewSet):
queryset = Category.objects.all()
serializer_class = CategorySerializer
# 给该指定LimitOffsetPagination分页类,也可以在settings指定全局
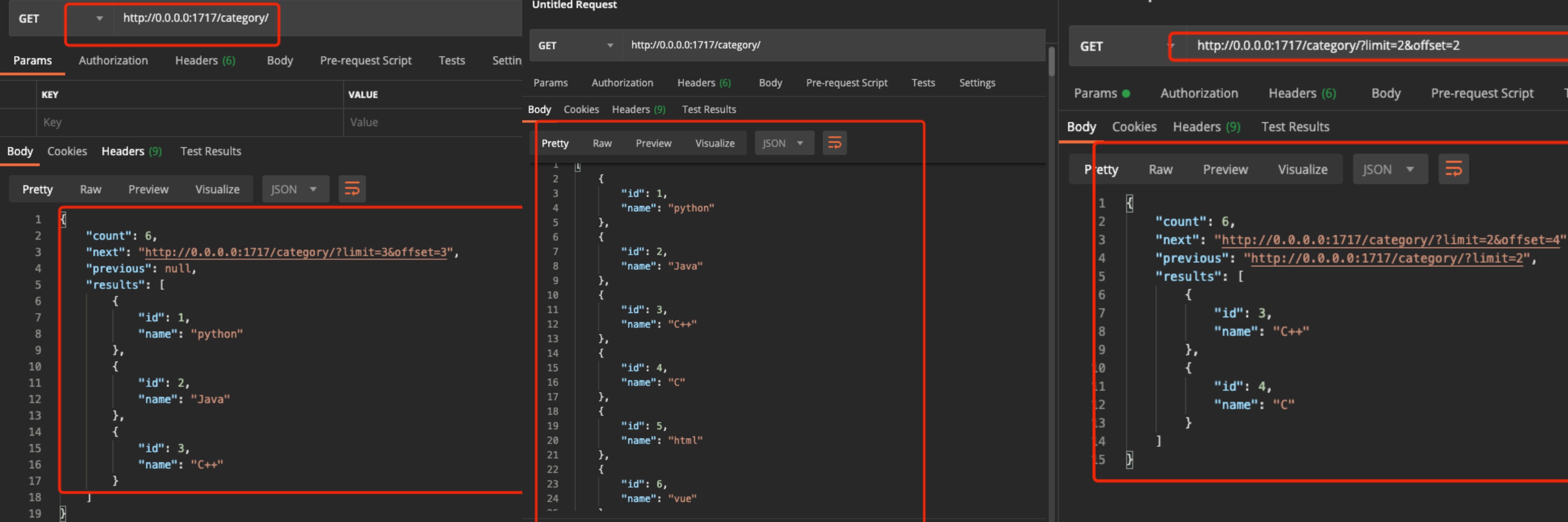
pagination_class = LimitOffsetPagination- 图1,没有传参返回了3条数据是因为在settings中page_size是3,默认从第一条开始取3条数据,下一页依次向后取3条
- 图2是将settings中的page_size删除掉,没有传递limit和offset参数就默认全部返回
- 图3是传入limit=2,offset=2,从第三条开始取2条数据
LimitOwsetPagination自定义分页类
# 继承LimitOffsetPagination分页类
class PublicLimitOffsetPagination(pagination.LimitOffsetPagination):
default_limit = 2 # 用于指定默认的limit数量
limit_query_param = 'lm' # 指定请求时候对应的limit参数名,如果是lm那么传参就是lm=
offset_query_param = 'of' ## 指定请求时候对应的offset参数名,如果是lm那么传参就是of=
max_limit = 4 # 最大的limit可设置数量CursorPagination:
CursorPagination分页类说明
- 显示一个正向和反向的控件,不允许我们任意导航到任意位置
- 要求结果集中有应该唯一的不变的排序方式
- 可以确保客户端在翻页时不会看到同一对象两次,即使在分页的同时有数据插入
- 对于超级大的数据量,使用前两个分页可能会效率低下,基于光标的分页具有固定的时间属性,不会因为数据变大而减慢
- 基于光标的分页的排序方式默认是使用created排序,如果使用默认排序则模型必须有created时间戳字段,首先显示最近添加的数据
- 可以覆盖pagination类的ordering属性,或者使用OrderingFilter过滤器类和CursorPagination来修改排序
- 使用时要注意应该有一个唯一不变的值,例如默认的created
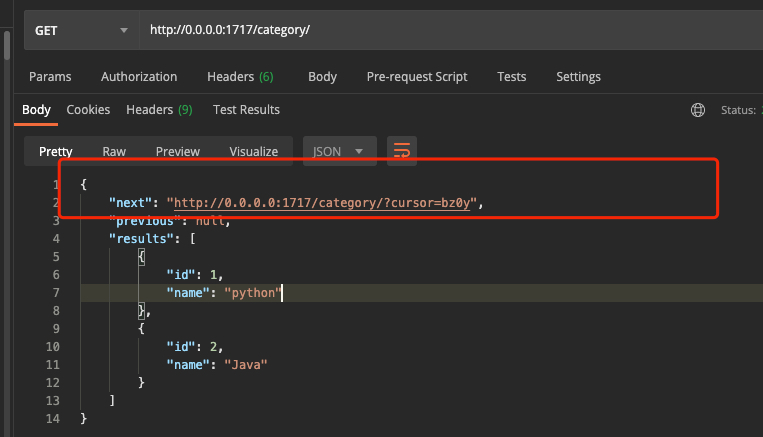
#settings设置
REST_FRAMEWORK = {
# 指定CursorPagination分页类
"DEFAULT_PAGINATION_CLASS": "rest_framework.pagination.CursorPagination",
"PAGE_SIZE": 2 # 每一页显示3条数据
}
自定义CursorPagination
#继承CursorPagination分页类
class PublicCursorPagination(pagination.CursorPagination):
ordering = '-created' #通过什么进行排序,默认created
page_size = 3 # 每页数据量
cursor_query_param = 'cs' #请求的参数字段,默认cursor
47.DRF实现分页的更多相关文章
- DRF的分页
DRF的分页 DRF的分页 为什么要使用分页 其实这个不说大家都知道,大家写项目的时候也是一定会用的, 我们数据库有几千万条数据,这些数据需要展示,我们不可能直接从数据库把数据全部读取出来, 这样 ...
- DRF框架(九)——drf偏移分页组件、drf游标分页组件(了解)、自定义过滤器、过滤器插件django-filter
drf偏移分页组件 paginations.py from rest_framework.pagination import LimitOffsetPagination class MyLimitOf ...
- drf偏移分页组件-游标分页-自定义过滤器-过滤器插件django-filter
drf偏移分页组件 LimitOffsetPagination 源码分析:获取参数 pahenations.py from rest_framework.pagination import Limit ...
- drf 的分页功能
1 settings中配置 page_size = 20 代表每页20条数据 REST_FRAMEWORK = { 'DEFAULT_PARSER_CLASSES': ( 'rest_framewor ...
- DRF之频率限制、分页、解析器和渲染器
一.频率限制 1.频率限制是做什么的 开放平台的API接口调用需要限制其频率,以节约服务器资源和避免恶意的频繁调用. 2.频率组件原理 DRF中的频率控制基本原理是基于访问次数和时间的,当然我们可以通 ...
- DRF 分页组件
Django Rest Framework 分页组件 DRF的分页 为什么要使用分页 其实这个不说大家都知道,大家写项目的时候也是一定会用的, 我们数据库有几千万条数据,这些数据需要展示,我们不可能直 ...
- DRF频率、分页、解析器、渲染器
DRF的频率 频率限制是做什么的 开放平台的API接口调用需要限制其频率,以节约服务器资源和避免恶意的频繁调用. 频率组件原理 DRF中的频率控制基本原理是基于访问次数和时间的,当然我们可以通过自己定 ...
- DRF之注册响应分页组件
注册器 注册器的作用就是以后我们不用自己手动的一条条的敲路径了,它可以帮助哦们直接去找对应的路由,不用传参了,知道这一点就可以了,不多说还是,上代码实例 第一步:导入模块from django.url ...
- DRF框架(八)——drf-jwt手动签发与校验、搜索过滤组件、排序过滤组件、基础分页组件
自定义drf-jwt手动签发和校验 签发token源码入口 前提:给一个局部禁用了所有 认证与权限 的视图类发送用户信息得到token,其实就是登录接口,不然进不了登录页面 获取提交的username ...
- drf-jwt手动签发与校验,drf小组件:过滤、筛选、排序、分页
复习 """ 频率组件:限制接口的访问频率 源码分析:初始化方法.判断是否有权限方法.计数等待时间方法 自定义频率组件: class MyThrottle(SimpleR ...
随机推荐
- TWS耳机蓝牙建连过程_HCI版本
TWS耳机信息:Enco Air2 手机信息:onePlus8 ColorOS V12.1 其他准备工作:手机进入开发者模式,打开本地日志开关.可参考上一篇文章 https://www.cnblog ...
- Nebula Graph介绍和SpringBoot环境连接和查询
Nebula Graph介绍和SpringBoot环境连接和查询 转载请注明来源 https://www.cnblogs.com/milton/p/16784098.html 说明 当前Nebula ...
- 我说HashMap初始容量是16,面试官让我回去等通知
众所周知HashMap是工作和面试中最常遇到的数据类型,但很多人对HashMap的知识止步于会用的程度,对它的底层实现原理一知半解,了解过很多HashMap的知识点,却都是散乱不成体系,今天一灯带你一 ...
- 学习Rust第一天 Rust语言特点
学习Rust之前,我觉得应该首先了解Rust语言的设计目的是什么?为什么会诞生这门语言?这门语言和其他的语言有什么不同. Rust语言的设计特点 高性能:rust拥有和C++相近的性能表现,所以在嵌入 ...
- 查看服务器出口ip
[root@iZap201hv2fcgry1alvbznZ ~]# curl cip.cc IP : xxx.xxx.xx.xx 地址 : 中国 浙江 绍兴 运营商 : 移动 数据二 : 浙江省绍兴市 ...
- CentOS下一些软件的安装
Git # 参数 -y 表示yes,不用询问直接安装 yum -y install git # 第一次安装需要一些配置 git config --global user.name "Your ...
- 深度学习之logistics回归
在开始之前,事先声明本文参考[中文][吴恩达课后编程作业]Course 1 - 神经网络和深度学习 - 第二周作业_何宽的博客-CSDN博客_吴恩达课后编程作业 加上自己的理解,希望可以不用重复看吴恩 ...
- 基于python的数学建模---时间序列
JetRail高铁乘客量预测--7种时间序列方法 数据获取:获得2012-2014两年每小时乘客数量 import pandas as pd import numpy as np import mat ...
- toB应用私有化交付发展历程、技术对比和选型
由于数据隐私和网络安全的考虑,大多数toB场景的客户需要私有化应用交付,也就是需要交付到客户的环境里,这样的客户有政府.金融.军工.公安.大型企业.特色行业等,这些私有化场景限制很多,如何提高私有化应 ...
- Java开发学习(四十三)----MyBatisPlus查询语句之查询投影
1.查询指定字段 目前我们在查询数据的时候,什么都没有做默认就是查询表中所有字段的内容,我们所说的查询投影即不查询所有字段,只查询出指定内容的数据. 具体如何来实现? @SpringBootTest ...