《Streaming Systems》第三章: Watermarks
定义
对于一个处理无界数据流的 pipeline 而言,非常需要一个衡量数据完整度的指标,用于标识什么时候属于某个窗口的数据都已到齐,窗口可以执行聚合运算并放心清理,我们暂且就给它起名叫 watermark 吧。
可以把系统当前处理时间当做 watermark 吗?显然不可以。第一章 已经讨论过,处理时间和事件时间的偏差是不确定的,根据处理时间无法对事件时间的进度进行准确衡量。
pipeline 的数据处理速率可以当做 watermark 吗?也不可以。pipeline 的数据处理速率不是一成不变的,会受到诸多因素的影响,也不能辅助判别数据的完整性。
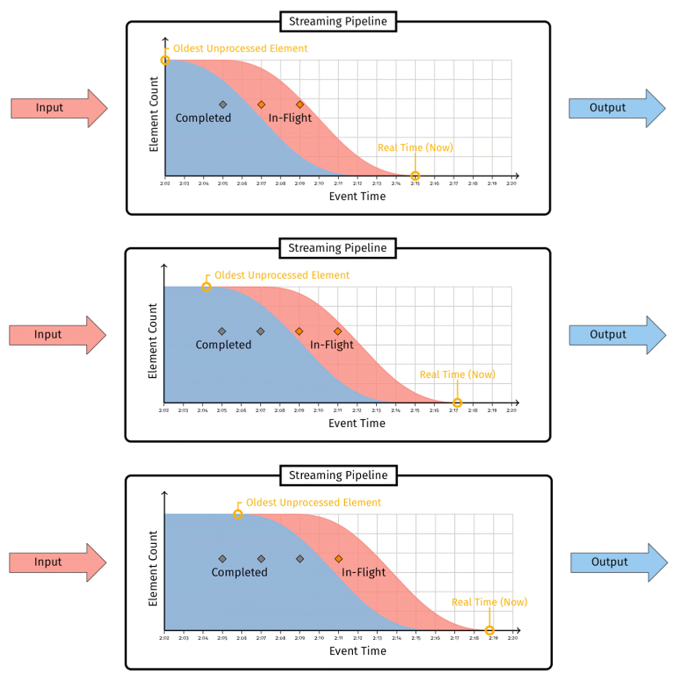
那选择什么作为 watermark 合适呢,从头捋捋吧。我们假设每个事件都携带一个事件时间戳,我们分析一下 pipeline 中的事件时间分布情况。pipeline 上游对接输入,输入管道中都是等待处理的数据,处理完成后将结果发往下游的输出。如 图 3-1 所示,我们将已经接收但是未被处理的数据标记为红色,将处理完成的数据标记为蓝色,pipeline 中会同时存在等待处理和已经处理的数据。随着时间的推移,越来越多的数据会加入到 “红色” 区域中等待处理,当然也有越来越多的数据被处理完成,从 “红色” 区域移入到 “蓝色” 区域。
图中右侧黄色指针表示当前时间,左侧黄色指针追踪的是红色区域的最左侧,即 最早的那个未被处理数据的事件时间。我们就用这个值定义 watermark。
用这个值定义 watermark 能满足我们的最初要求:
完整性
如果 watermark 已经超过了某个时间戳 T,由于其单调性,不会再对 T 之前的事件进行处理(迟到数据除外)。因此,我们可以正确地处理 T 之前的窗口聚合。可视性
如果一条消息由于任何原因卡在我们的 pipeline 中,watermark 不能 advance。 此外,我们将能够找到阻止 watermark 继续推进的问题根源。
Source Watermark 的创建
为了创建 watermark,我们需要为进入 pipeline 的每个消息分配一个逻辑事件时间戳。第二章 已经讨论过,watermark 无外乎两种类型:完美型 watermark 和启发式 watermark。创建哪种类型的 watermark 取决于数据源的本质。
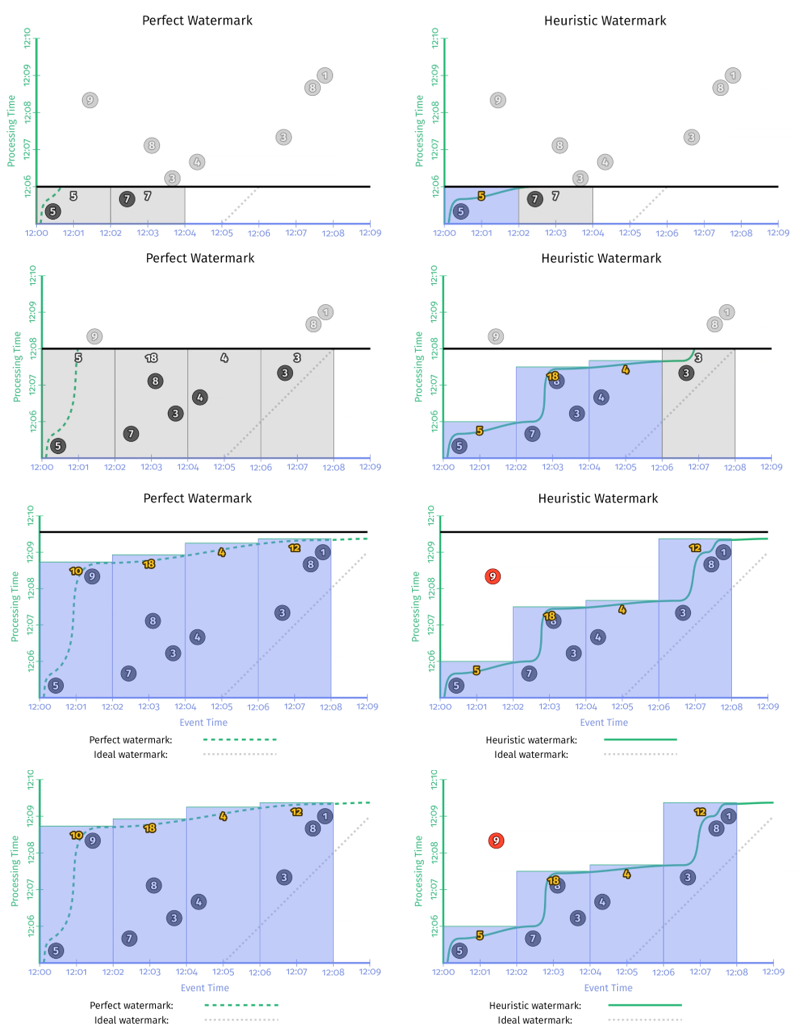
完美型 Watermark 的创建
完美型 watermark 严格保证不会有迟到数据出现。然而,这种完美型 watermark 的创建需要 100% 掌握数据源的情况,这对于分布式的数据源来说几乎不可能。以下是可以创建完美型 watermark 的例子:
摄入时间戳(Ingress Timestamping)
将数据进入系统的时间当作数据的事件时间。2016 年前几乎所有的流计算系统都是这样做的,这种方式非常简单,能保证数据单调递增,坏处是处理时间与数据真正的事件时间没有关系,数据真正的事件时间在计算过程中被抛弃了。按时间排序的静态日志集(Static sets of time-ordered logs)
比如某个 kafka topic 中,有固定数量的 partition,且每个 partition 中数据的 event time 严格单调递增。这种场景中,只需要知道有几个 partition,以及每个 partition 的待处理数据中最早的 eventtime 即可得出 watermark。
所以使用 perfect watermark 的关键是保证数据源数据在 event time 上单调递增。
启发式 Watermark 的创建
与完美型 watermark 相反,启发式 watermark 假设 event time 在 watermark 之前的数据已经到齐。当然,使用启发式 watermark 难免会遇到 late event,但是只要方式得当,是可以得到一个比较合理的启发式 watermark 的。系统还需要提供一种处理 late event 的方式来保证正确性。以下是使用启发式 watermark 的例子:
- 按时间排序的动态日志集(Dynamic sets of time-ordered logs)
一系列动态结构化日志文件(比如:每个日志文件内部的数据在 event time 上单调递增,但是文件之间时间没有关系)。所有文件的数据进入 Kafka 后,在 event time 上就不能保证单调递增了。在这种场景下,可以通过跟踪最早的待处理数据的 event time,数据增长率,网络拓扑,可用带宽等信息,来得到一个相对精确的 watermark。
创建启发式 watermark 时,没有一个统一的方式,需要根据数据源类型,数据分布等信息 case by case 的分析。一旦 watermark 被创建,其就会在 pipeline 中被传递下去,且类型不会变。这样整个 pipeline 的数据完整性问题就在数据源头被解决了。
Watermark 的传播
一个 pipeline 往往由多个 stage 组成,只有理解了 watermark 是如何在各个 stage 之间传播的,才能知道 watermark 是如何影响 pipeline 整体的。
什么是 PIPELINE STAGES
例如想统计某次比赛中,队伍中所有玩家的总得分,pipeline 中就会包含以下 3 个 stage:
- 消费原始数据
- 对每个玩家的得分进行聚合
- 对队伍中所有玩家的得分进行聚合
watermark 在数据源端创建生成,然后,随着数据的进展,流经系统中管道的各个阶段。如果管道包含多个阶段,我们更希望能够追踪到每个阶段的 watermark。可以把每个阶段的 watermark 想象成一个函数,函数的输入就是在此之前的所有阶段的输出。
我们可以在管道的每个算子、每个阶段的边界处追踪 watermark,这有助于我们实时掌握各个阶段数据处理的进度。我们给出边界 watermark 的定义:
input watermark
统计所有上游阶段的进展及完成度。对于源算子而言,输入 watermark 应该是一个专门创建 watermark 的特定函数;对于非源算子而言,输入 watermark 就是上游所有 实例/分区/分片 所输出的 watermark 的最小值。output watermark
体现当前阶段自身的进展,定义为所有输入 watermark 和当前阶段所有非迟到数据的事件时间的最小值。
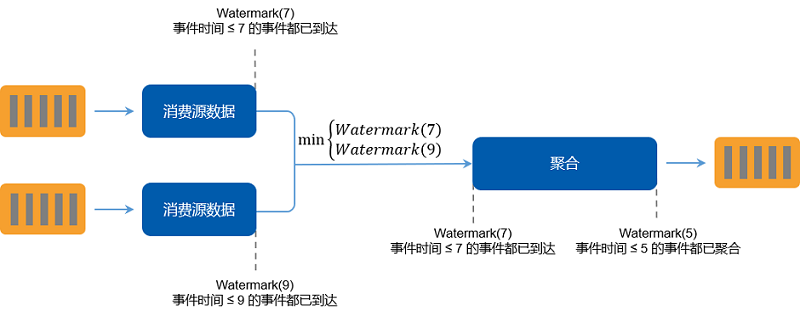
定义了 输入/输出 watermark 之后,我们就可以计算每个阶段的延迟了:延迟 = input watermark - output watermark。管道中的每个后续阶段都造成 watermark 的进一步延迟。
每个阶段的处理过程还可以做更细粒度的拆解。数据到达时,可能是先被写入缓存 state 中等待后续的聚合,聚合触发时,将计算结果写入 output buffer 中等待下游消费。如图 3-3 所示:
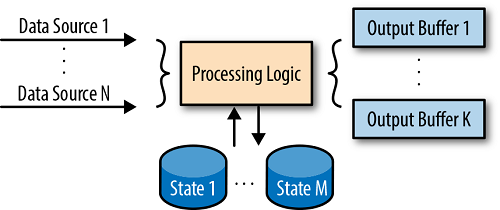
每个 output buffer 中的 watermark 也是可以被追踪的,所有 output buffer 的 watermark 的最小值就是该阶段的 output watermark。output watermark 自然也是以下指标中的最小值:
- 每个 source watermark —— 对于每个发送阶段
- 每个外部输入的 watermark —— 对于管道外部的源
- 每个 state 中的 watermark —— 对于每种可以持久化的状态
- 每个 output buffer 的 watermark —— 对于每个接收阶段
在这种粒度级别上提供 watermark 可以提供更好的系统行为的可见性。系统卡顿、延迟等问题的定位将更加方便。
理解 Watermark 的传播
为了更好地理解输入 watermark 和输出 watermark 的关系,以及他们是如何影响 watermark 的传播的,我们引入一个例子。本例中我们不再计算游戏中队伍的总得分了,我们关注的是用户的平均在线时长。在线时长实际上就是用户每次在线的会话窗口长度。
为了让这个例子更有意思也更贴近实际,假设我们在两个独立数据集上进行这项工作: 移动端数据集 和 PC端数据集,分别对应手机端玩家和 PC 端玩家。我们使用两个并行的 pipeline 分别处理两个数据集,两个 pipeline 的运行逻辑完全一致。那么就有:两个逻辑一致的 pipeline 在不同的数据集上执行着相同的操作,有着不同的输出 watermark。
读取移动端数据和 PC 端数据计算用户在线时长的逻辑如 示例 3-1 所示:
PCollection<Double> mobileSessions = io.read(new MobileInputSource())
.apply(Window.into(Sessions.withGapDuration(Duration.standardMinutes(1)))
.triggering(AtWatermark())
.discardingFiredPanes())
.apply(CalculateWindowLength());
PCollection<Double> consoleSessions = io.read(new ConsoleInputSource())
.apply(Window.into(Sessions.withGapDuration(Duration.standardMinutes(1)))
.triggering(AtWatermark())
.discardingFiredPanes())
.apply(CalculateWindowLength());
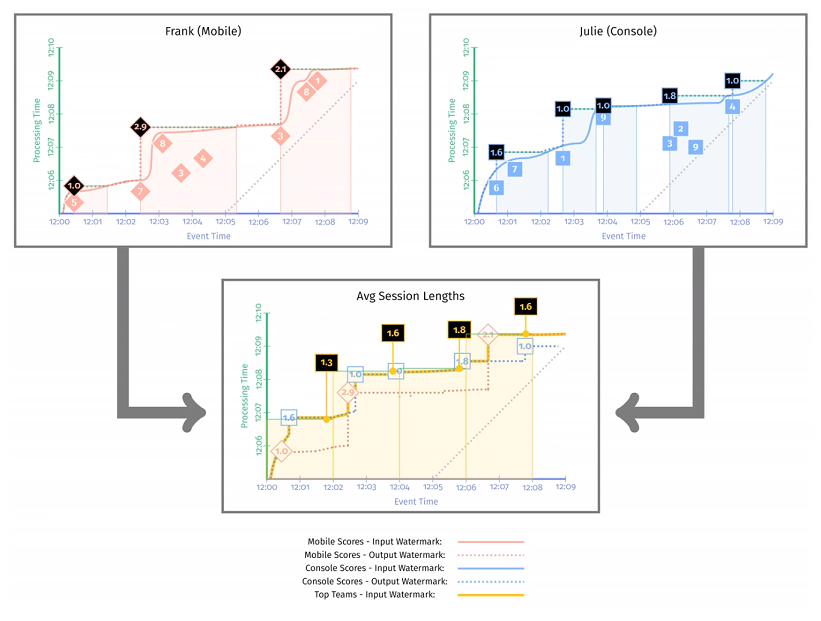
之前的例子中我们都是根据 Team 分组,本例中我们根据 User 分组。窗口划分方式选择会话窗口,并实现 CalculateWindowLength() 方法计算窗口长度。使用 AtWatermark() 作为触发器,数据累积模式选择 discardingFiredPanes()。两个 pipeline 在其中两个 user 的输出结果如 图 3-4 所示:移动端玩家 Frank 共玩了 3 局游戏,会话窗口时长分别是 1min,2.9min,2.1min;PC 端玩家 Julie 共玩了 5 局游戏,会话窗口时长分别是 1.6min,1.0min,1.0min,1.8min,1.0min。

示例 3-1 统计了移动端玩家和 PC 端玩家的在线时长,接下来我们结合两个数据集统计一下这款游戏所有用户的平均在线时长。这就需要把 示例 3-1 中两个 pipeline 的输出结果整合成一个,并将其作为输入进行第二阶段的计算,具体来说是采用滚动时间窗口的方式,统计各个时段内所有玩家的平均在线时长。如 示例 3-2 所示:
PCollection<Double> mobileSessions = io.read(new MobileInputSource())
.apply(Window.into(Sessions.withGapDuration(Duration.standardMinutes(1)))
.triggering(AtWatermark())
.discardingFiredPanes())
.apply(CalculateWindowLength());
PCollection<Double> consoleSessions = io.read(new ConsoleInputSource())
.apply(Window.into(Sessions.withGapDuration(Duration.standardMinutes(1)))
.triggering(AtWatermark())
.discardingFiredPanes())
.apply(CalculateWindowLength());
PCollection<Float> averageSessionlengths = PCollectionList
.of(mobileSessions).and(consoleSessions)
.apply(Flatten.pCollections())
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)))
.triggering(AtWatermark()))
.apply(Mean.globally());
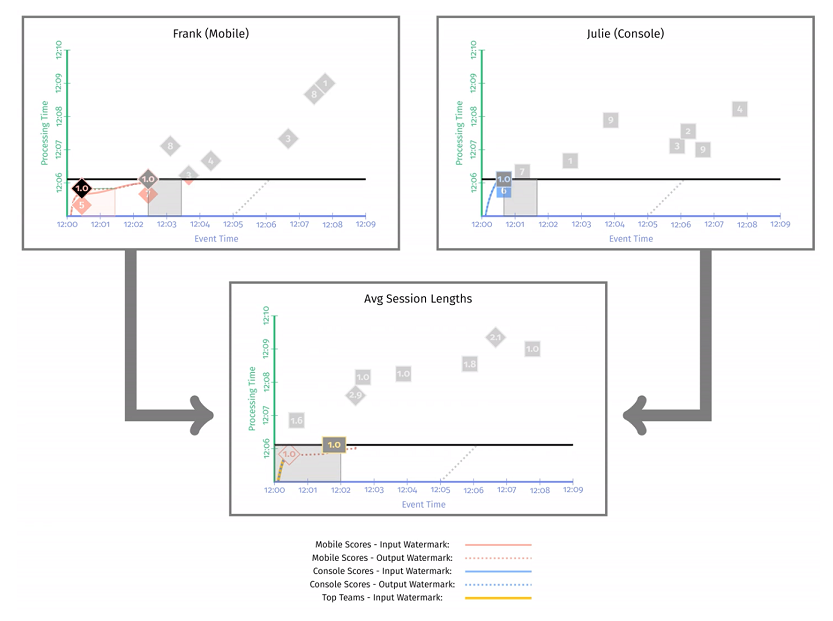
示例 3-2 的运行结果如 图 3-5 所示。首先看第一阶段,移动端的输入 watermark 用红色实线标记,输出 watermark 用红色虚线标记;PC 端的输入 watermark 用蓝色实线标记,输出 watermark 用蓝色虚线标记。第二阶段中计算平均会话长度的输入 watermark 用黄色实线标记。
下图这个快照时刻,移动端输出一个计算结果 1min,PC 端无结果输出,因此平均会话时长依旧是 1min。不过由于第二阶段的 watermark 还没有到达,仍为中间结果,用灰色标记。
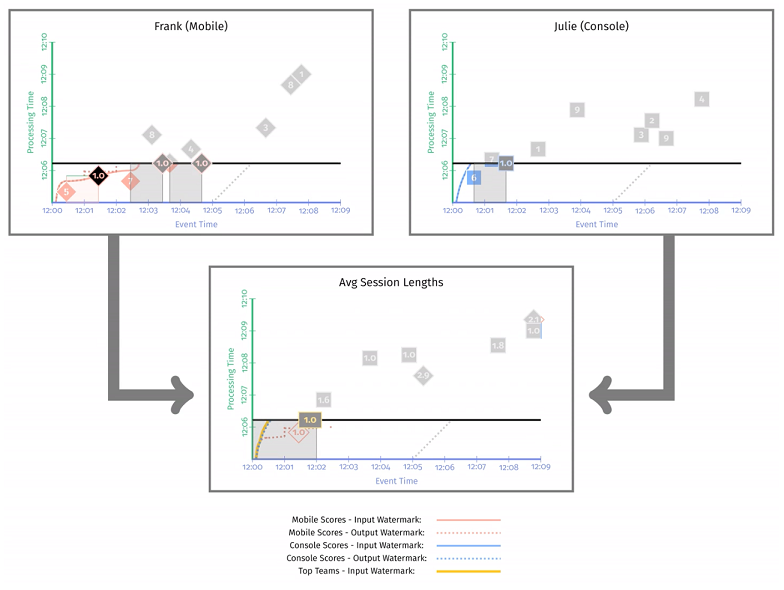
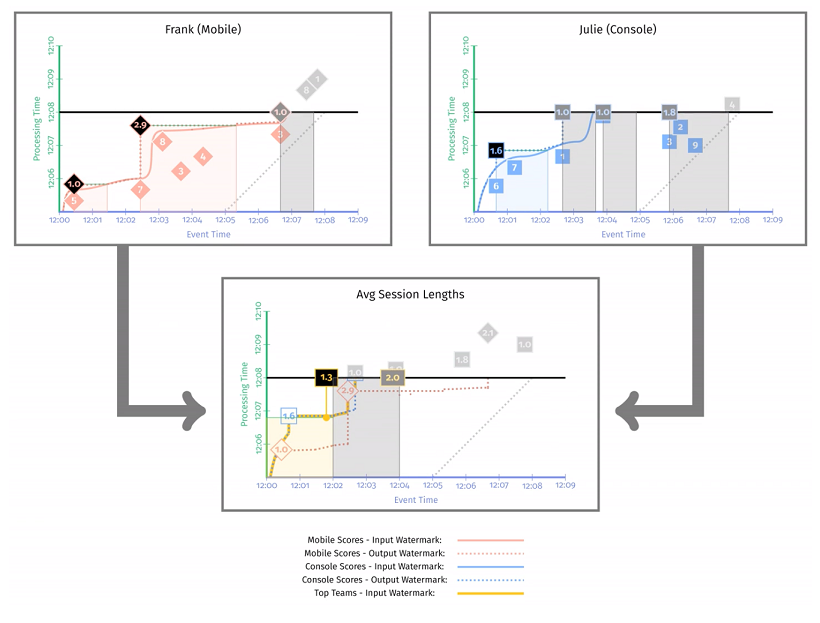
下图这个快照时刻,watermark 已经触发了 [12:00, 12:02] 窗口的实体化,这个时段内的平均会话时长 是 1min,同时窗口 [12:02, 12:04] 的当前结果是 1.6min,2.9min。
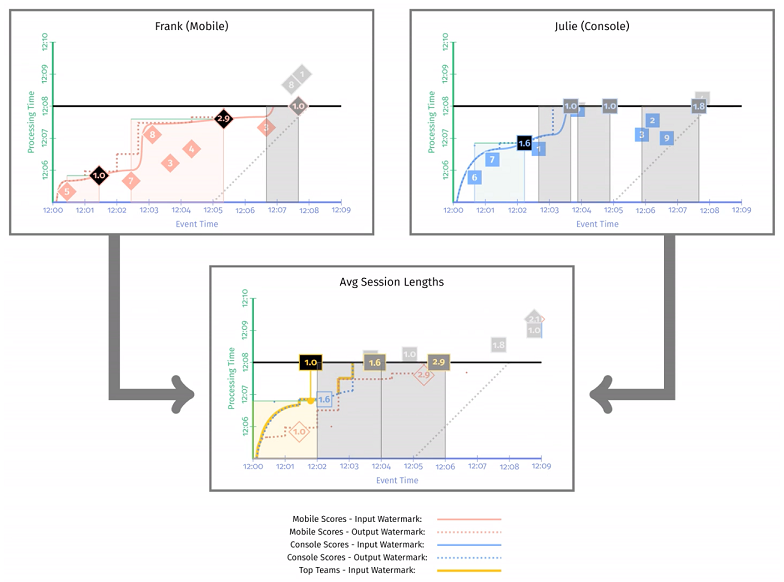
下图这个快照时刻,watermark 已经触发了 [12:02, 12:04],[12:04, 12:06] 窗口的实体化,平均会话时长分别是 (1.6 + 1) / 2 = 1.3min,(1.0 + 2.9) / 2 = 2min。同时窗口 [12:06, 12:08] 的中间结果是 1.8min。
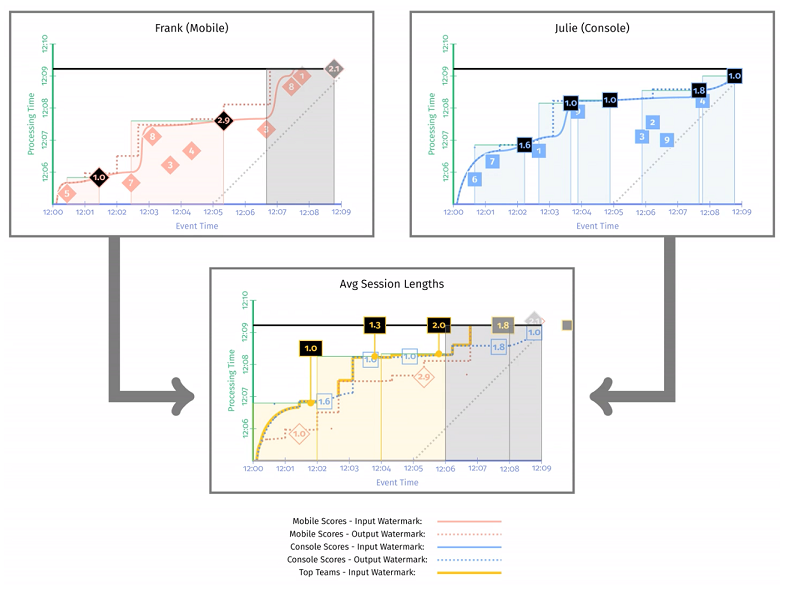
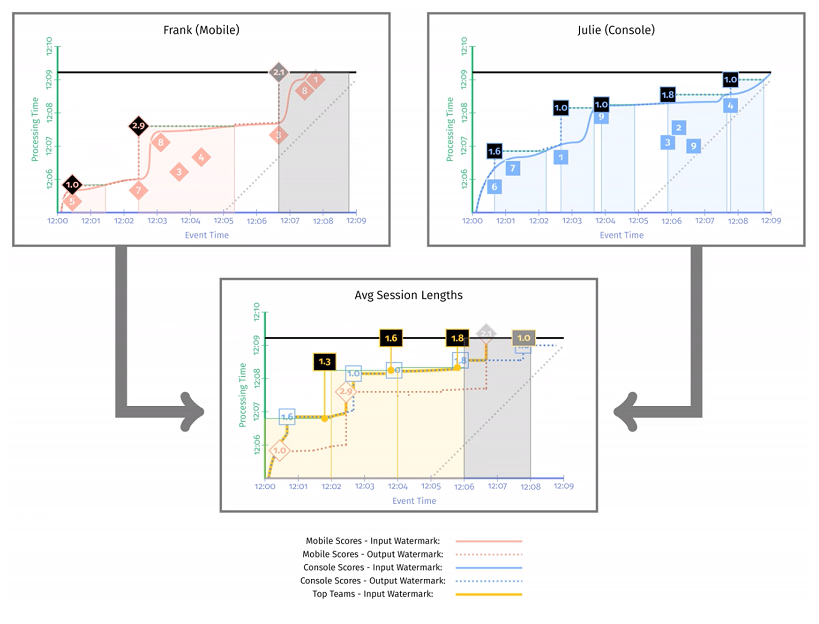
下图这个快照时刻,得到了移动端用户和 PC 端用户在各时段的平均在线时长,分别是 [12:00, 12:02] 平均在线 1min,[12:02, 12:04] 平均在线 1.3min,[12:04, 12:06] 平均在线 2min,[12:06, 12:08] 平均在线 1.8min。
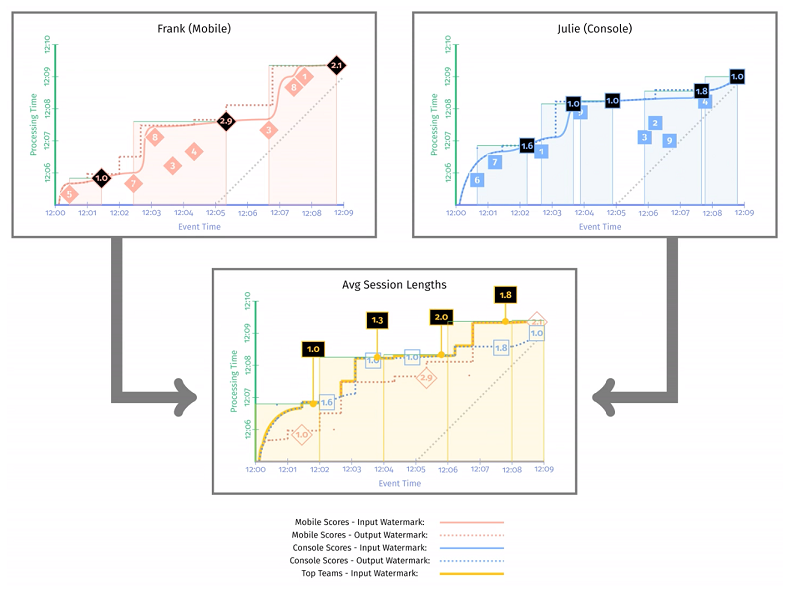
这里重要的两点是:
- 无论是移动端还是 PC 端,输出 watermark 一定晚于输出 watermark,因为计算过程消耗时间。
- 第二阶段的 input watermark 是第一阶段两个 output watermark 的最小值。
关于这一点,也不难理解。可是为什么从图中看,第二阶段的 output watermark (黄色线)整体是在第一阶段两个 input watermark (红色实线和蓝色实线)的上方呢?这难道不是说明,第二阶段的 input watermark 是第一阶段两个 output watermark 的最大值吗?
关于这个问题,其实我们说第二阶段的 input watermark 是第一阶段两个 output watermark 的最小值,实际上是 Event Time 的最小值,而不是 Processing Time 的最小值,而图中的纵轴为 Processing Time,要想比较 Event Time,需要把图旋转来看:
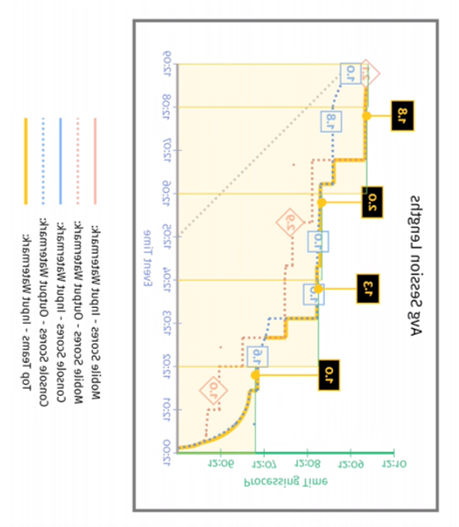
怎么样,当以 Event Time 为纵轴时,黄色线是不是等于 min(红色线, 蓝色线)?第一阶段两个 output watermark 的最小值这不就是第二阶段的 input watermark 嘛 O(∩_∩)O~~
Watermark 的传播与输出时间戳
在 图 3-5 中,我有意忽略了一个细节未提,那就是输出时间戳。仔细看图不难发现,实际上是把第一阶段中窗口的结束时间赋给了计算结果。这似乎是一个很自然的选择,但却不是唯一的选择。大多数情况下,以下选项都可以作为备选:
窗口的结束时间(End of the window)
如果您需要一个可以代表窗口边界的时间戳,那么窗口的结束时间是一个不错的选择。在稍后的分析中会发现,窗口的结束时间 是所有选项中最能保证 watermark 的平滑推进的。第一个非迟到数据的事件时间(Timestamp of first nonlate element)
用第一个非迟到数据的时间戳作为 watermark 是一个保守方案。然而,稍后我们会看到,这个选择可能会让 watermark 的推进过程受阻。某个特定数据的时间戳(Timestamp of a specific element)
在某种用例中,比如一个查询流 join 一个点击流,有时希望用查询流的时间戳做 watermark,有时又希望用点击流的时间戳做 watermark。
如果选择第一个非迟到数据的时间戳作为 watermark,如 示例 3-3 所示:
PCollection<Double> mobileSessions = io.read(new MobileInputSource())
.apply(Window.into(Sessions.withGapDuration(Duration.standardMinutes(1)))
.triggering(AtWatermark())
.withTimestampCombiner(EARLIEST)
.discardingFiredPanes())
.apply(CalculateWindowLength());
PCollection<Double> consoleSessions = io.read(new ConsoleInputSource())
.apply(Window.into(Sessions.withGapDuration(Duration.standardMinutes(1)))
.triggering(AtWatermark())
.withTimestampCombiner(EARLIEST)
.discardingFiredPanes())
.apply(CalculateWindowLength());
PCollection<Float> averageSessionlengths = PCollectionList
.of(mobileSessions).and(consoleSessions)
.apply(Flatten.pCollections())
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)))
.triggering(AtWatermark()))
.apply(Mean.globally());
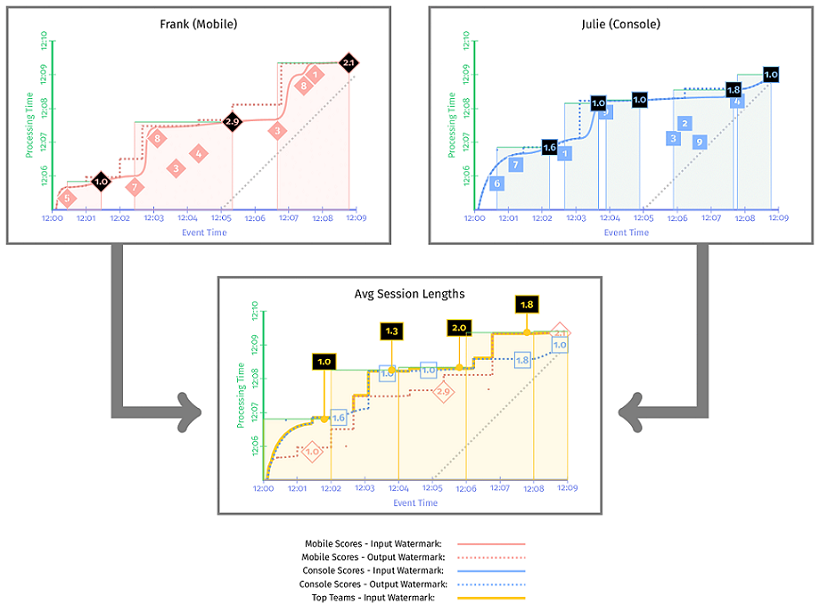
示例 3-3 的运行结果如 图 3-6 所示。首先看第一阶段,移动端的输入 watermark 用红色实线标记,输出 watermark 用红色虚线标记;PC 端的输入 watermark 用蓝色实线标记,输出 watermark 用蓝色虚线标记。第二阶段中计算平均会话长度的输入 watermark 用黄色实线标记。
下图这个快照时刻,移动端输出一个计算结果 1min,PC 端无结果输出。由于第二阶段的 watermark 还没有到达,仍为中间结果,用灰色标记。
下图这个快照时刻,watermark 已经触发了 [12:00, 12:02] 窗口的实体化,这个时段内的平均会话时长 是 (1 + 1.6) / 2 = 1.3min,同时窗口 [12:02, 12:04] 的当前结果是 2.0min(注意这个结果不是 (2.9 + 1 + 1) / 2 = 2.45min,两分钟的窗口平均在线时长超过 2min 显然是不合理的,最大值只能是 2min)。
下图这个快照时刻,watermark 已经触发了 [12:00, 12:02],[12:02, 12:04],[12:04, 12:06] 窗口的实体化,平均会话时长分别是 (1 + 1.6) / 2 = 1.3min,1.6min(由于同一个 session 跨越不同的窗口,计算方式会有不同之处),1.8min。
下图这个快照时刻,得到了移动端用户和 PC 端用户在各时段的平均在线时长,分别是 [12:00, 12:02] 平均在线 1.3min,[12:02, 12:04] 平均在线 1.6min,[12:04, 12:06] 平均在线 1.8min,[12:06, 12:08] 平均在线 1.6min。
与 图 3-5 相比,图 3-6 中的 watermark 被 hold 住了,因为 图 3-5 中的时间戳选的是窗口结束时间作为 watermark,图 3-6 中,选择的是第一个非迟到数据的时间戳作为 watermark。可以明显看出,第二阶段的 watermark 也被 hold 住了。(ps. 我觉得一点都不明显,是我瞎吗?)
两种时间戳选择方式的最终结果对比如 图 3-7 和 图 3-8 所示。
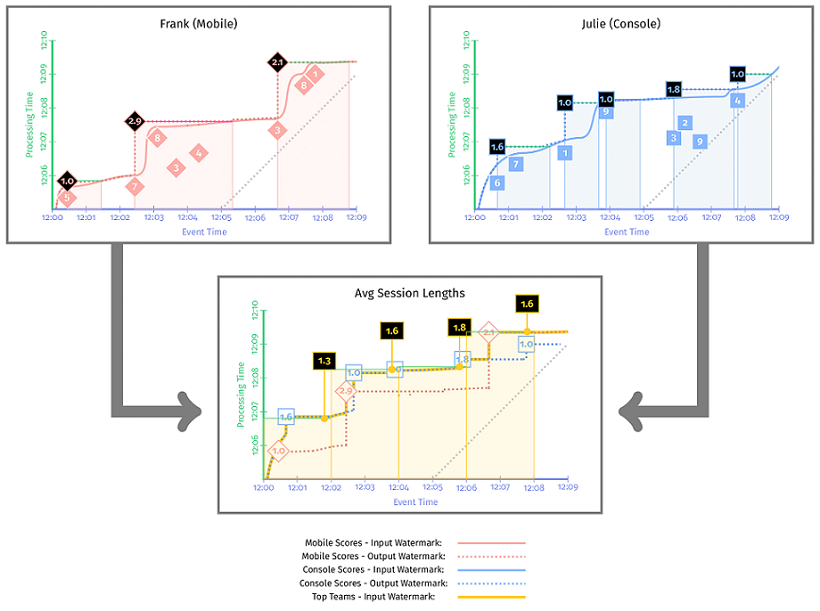
这里有两点需要特别注意:
watermark 延迟(watermark delay)
第二种方式 watermark 明显比第一种方式慢,因为只有窗口结束,watermark才能向前推进。Semantic differences(语义差别)
这两种方式计算结果不同,但是没有谁对谁错,它们只是本身不同而已,因此需要明确知道内部原理才能正确选择 watermark。
百分比 Watermark
watermark 含义是小于某个事件时间 t 的数据都已经到齐了。百分比 watermark 含义是小于某个事件时间 t 的数据已经到齐百分之多少了。
百分比 watermark 有什么作用?在业务逻辑上,如果 “绝大多数准确” 已经足够用,不需要保证绝对准确,就可以选择百分比 watermark,它不受数据分布中长尾部分 outlier 数据的影响,因此推进更快速、平滑。
图 3-9 所示为数据在事件时间上的分布情况,其整体呈现正态分布。标志数据 90% 都到齐的 watermark 和标志数据 100% 都到齐的 watermark 距离很近,二者区分还不明显,可是当数据中包含 outlier 时,数据整体分布就如 图 3-10 所示了,此时的 90% watermark 和 100% watermark 就相去甚远了。此时如果选择普通的 watermark,将会由于等待 outlier 产生延迟,而百分比 watermark 的优势就体现出来了,通过丢弃水印中的异常数据,百分比 watermark 仍然可以跟踪大部分分布而不被异常值延迟。
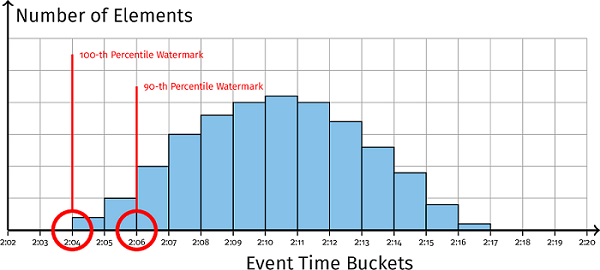
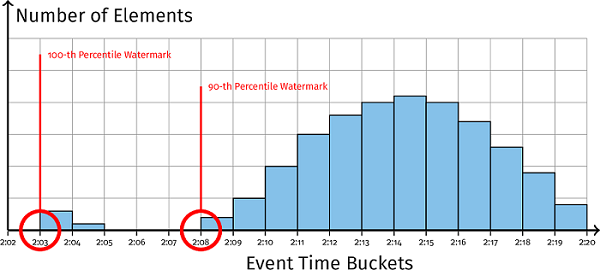
图 3-11 为百分比 watermark 的运行时序图。
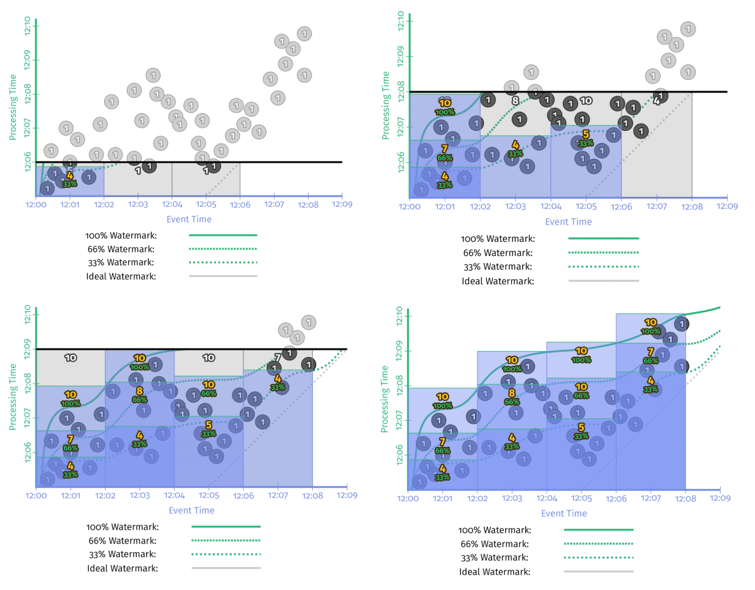
我们分别使用 33%、66%、100% watermark 追踪数据中的事件时间戳,和预期一样,33%、66% watermark 能够比100% watermark 更早触发窗口聚合计算。以 [12:00, 12:02) 窗口为例,33% watermark 约在 12:06 时刻触发了计算,此时窗口内只有 4 个数据到达。再看 66% watermark,还是同样的窗口,约在 12:07 时刻触发计算,此时窗口内有 7 个数据。100% watermark 在触发计算时窗口内包含了全局的 10 个数据,而此时已经是 12:08 时刻了。因此,百分位 watermark 为我们提供了一种调整延迟和结果精确性的权衡方法。
处理时间 Watermark
通过比较 watermark 和当前时间,我们就能计算系统延迟了。但是,如果处理是历史数据的话,就无法区分系统是在零延迟处理一个小时前的数据,还是在处理当前数据但是延迟了一个小时。即我们无法区分 stuck system 和 stuck data。
这时候就需要用到处理时间 watermark 了。我们用和事件时间 watermark 一样的方式来定义处理时间 watermark,不同的是:事件时间 watermark 取值于是最早未被处理的事件时间戳,处理时间 watermark 取值于 pipeline 中最早的未完成运算的算子,例如 I/O 堵塞,或处理过程中产生了异常等。关键定义对比一下原文:
We define the processing-time watermark in the exact same way as we have defined the event-time watermark, except instead of using the event-time timestamp of oldest work not yet completed, we use the processing-time timestamp of the oldest operation not yet completed.
如 图 3-12 所示,如果系统的事件时间 watermark 延迟一直增长,我们是无法区分数据有延迟还是系统有延迟的。
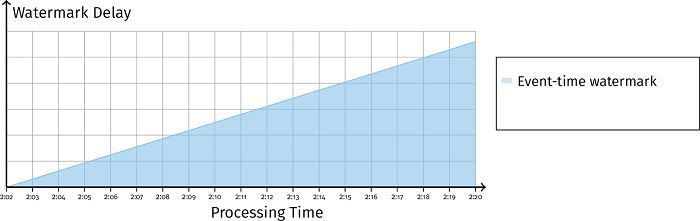
处理时间 watermark 为我们提供了一种区分系统延迟和数据延迟的理念。如果此时处理时间 watermark 延迟也一直增长的话,那就说明是系统的原因导致了延迟。
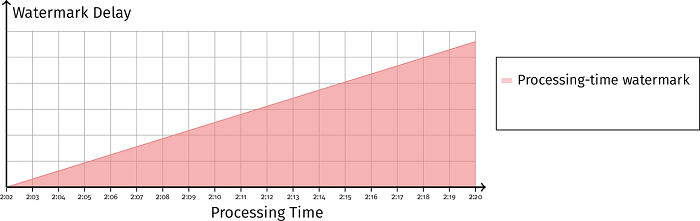
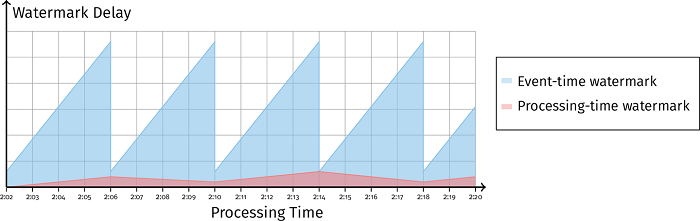
如果处理时间 watermark 延迟维持在稳定水平,事件时间 watermark 延迟一直增长,如 图 3-14 所示,这就告诉我们系统是暂时性地将数据缓存起来等待后续处理,而不是系统的处理步骤出现了延迟。
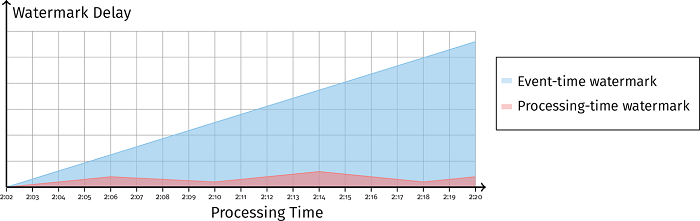
例如系统正在等待时间窗口边界的到来以进行聚合操作,当聚合操作完成时,缓存的数据被消费后,事件时间 watermark 就会回归正常水平。
Flink 中的 Watermark
接下来我们看看 Flink 中 watermark 的实现机制(原文中还介绍了 Google Cloud Dataflow 和 Google Cloud Pub/Sub 中 watermark 的实现机制,由于平时用到不多,暂时略去这部分内容的介绍)。
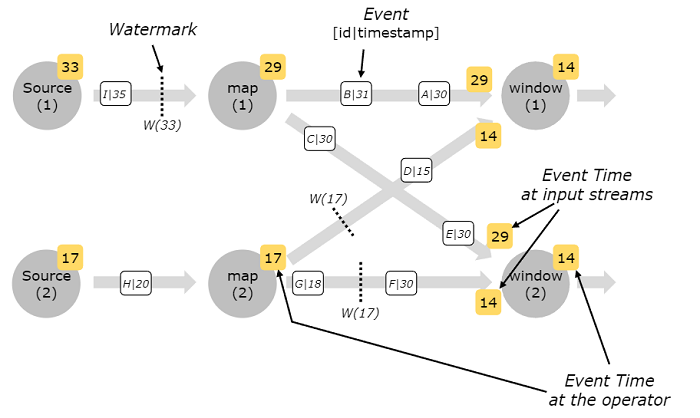
watermark 通常是在源算子部分生成,如果源算子有多个并行的子任务,每个子任务独立生成各自的 watermark。
watermark 和事件一样在流处理程序的 pipeline 中流动,当 watermark 流经算子时,就将算子的事件时间向前推进,每当算子推进了自己的事件时间,该算子就会产生一个新的 watermark 继续向下游的算子流去。
有的算子会同时消费多个流,比如 union 运算,或者跟在 KeyBy(...) 和 partition(...) 之后的算子,这类算子的事件时间就设为多个输入流的事件时间的最小值。当输入流的事件时间更新时,算子的事件时间也相应更新。
下图所示为事件和 watermark 在并行的 stream 中流动,算子追踪事件时间的过程:
本章小结
至此,我们已经探索了如何使用消息的事件时间给出流处理系统中进度的定义。具体来说,我们研究了 watermark 是如何在源处创建的,如何在整个管道中传播的。我们探究了更改输出窗口时间戳对 watermark 的影响。最后,我们探讨了流行的流处理系统中 watermark 的实现机制。
现在我们了解了 watermark 的工作机制,接下来我们将继续探讨当使用窗口和触发器进行更复杂查询的时候,watermark 是如何发挥更大作用的,第四章见。
《Streaming Systems》第三章: Watermarks的更多相关文章
- 《Streaming Systems》第二章: 数据处理中的 What, Where, When, How
本章中,我们将通过对 What,Where,When,How 这 4 个问题的回答,逐步揭开流处理过程的全貌. What:计算什么结果? 也就是我们进行数据处理的目的,答案是转换(transforma ...
- 《Streaming Systems》第一章: Streaming 101
数据的价值在其产生之后,将随着时间的流逝逐渐降低.因此,为了获得最大化的数据价值,尽可能实时.快速地处理新产生的数据就显得尤为重要.实时数据处理将在越来越多的场景中体现出更大的价值所在 -- 实时即未 ...
- 《Django By Example》第三章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:第三章滚烫出炉,大家请不要吐槽文中 ...
- 《Linux内核设计与实现》读书笔记 第三章 进程管理
第三章进程管理 进程是Unix操作系统抽象概念中最基本的一种.我们拥有操作系统就是为了运行用户程序,因此,进程管理就是所有操作系统的心脏所在. 3.1进程 概念: 进程:处于执行期的程序.但不仅局限于 ...
- Python黑帽编程3.0 第三章 网络接口层攻击基础知识
3.0 第三章 网络接口层攻击基础知识 首先还是要提醒各位同学,在学习本章之前,请认真的学习TCP/IP体系结构的相关知识,本系列教程在这方面只会浅尝辄止. 本节简单概述下OSI七层模型和TCP/IP ...
- 《Entity Framework 6 Recipes》中文翻译系列 (11) -----第三章 查询之异步查询
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 第三章 查询 前一章,我们展示了常见数据库场景的建模方式,本章将向你展示如何查询实体 ...
- 《Entity Framework 6 Recipes》中文翻译系列 (19) -----第三章 查询之使用位操作和多属性连接(join)
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 3-16 过滤中使用位操作 问题 你想在查询的过滤条件中使用位操作. 解决方案 假 ...
- 《python核心编》程课后习题——第三章
核心编程课后习题——第三章 3-1 由于Python是动态的,解释性的语言,对象的类型和内存都是运行时确定的,所以无需再使用之前对变量名和变量类型进行申明 3-2原因同上,Python的类型检查是在运 ...
- 精通Web Analytics 2.0 (5) 第三章:点击流分析的奇妙世界:指标
精通Web Analytics 2.0 : 用户中心科学与在线统计艺术 第三章:点击流分析的奇妙世界:指标 新的Web Analytics 2.0心态:搞定它.新的闪亮系列工具:是的.准备好了吗?当然 ...
随机推荐
- mybatis学习一:基于xml与注解配置入门实例与问题
注:本case参考自:http://www.cnblogs.com/ysocean/p/7277545.html 一:Mybatis的介绍: MyBatis 本是apache的一个开源项目iBatis ...
- 什么是 Hystrix?它如何实现容错?
Hystrix 是一个延迟和容错库,旨在隔离远程系统,服务和第三方库的访问点,当出现故障是不可避免的故障时,停止级联故障并在复杂的分布式系统中实现弹性.通常对于使用微服 构开发的系统,涉及到许多微服务 ...
- SpringBoot集成SpringBootDataElasticSearch
先放出依赖: <parent> <groupId>org.springframework.boot</groupId> <artifactId>spri ...
- 解决MySQL报错ERROR 2002 (HY000)
今天在为新的业务线搭架数据库后,在启动的时候报错 root@qsbilldatahis-db01:/usr/local/mysql/bin# ./mysql ERROR 2002 (HY000): C ...
- 学习SVN02
代码发布方案: 1,安装,优化 软件环境,(nginx,lvs) <-------运维工程师 2,程序代码(不断更新). <--------开发工程师,(开发,运维都可以发布) 3, ...
- Netty学习摘记 —— UDP广播事件
本文参考 本篇文章是对<Netty In Action>一书第十三章"使用UDP广播事件"的学习摘记,主要内容为广播应用程序的开发 消息POJO 我们将日志信息封装成名 ...
- web前端教程《每日一题》(1-99)完结
第1期(2016年4月6日): (1)js中关闭当前窗口的方法是:window.close(); 第2期(2016年4月7日): (1)js中使字符串中的字符变为小写的方法是:toLowerCase方 ...
- 从零到一:用Phaser.js写意地开发小游戏(Chapter 3 - 加载游戏资源)
回顾 上一节我们搭建了游戏的骨架,添加了四个游戏场景,分别是加载.开始.游戏.结束.那么这一节我们来介绍加载这个场景,顺带丰富一下各个场景的基本内容. Phaser.Loader Phaser框架自带 ...
- C#编写程序,用 while 循环语句实现下列功能
编写程序,用 while 循环语句实现下列功能:有一篮鸡蛋,不止一个,有人两个两个数,多余一个,三个三个数,多余一个,再四个四个地数,也多余一个,请问这篮鸡蛋至少有多少个. 代码: using Sys ...
- Android限制输入框内容
<EditText android:id="@+id/temper" android:hint="36.2" android:digits="1 ...