Redis如何实现多可用区?
在如今的业务场景下,高可用性要求越来越高,核心业务跨可用区已然成为标配。腾讯云数据库高级工程师刘家文结合腾讯云数据库的内核实战经验,给大家分享Redis是如何实现多可用区,内容包含Redis主从版、集群版原生架构,腾讯云Redis集群模式主从版、多AZ架构实现以及多AZ关键技术点,具体可分为以下四个部分:
第一部分:介绍Redis的原生架构,包含主从版及集群版;
第二部分:介绍腾讯云Redis架构,为了解决主从架构存在的问题,腾讯云使用了集群模式的主从版。其次为了更好的适应云上的Redis架构,引入了Proxy;
第三部分:分析原生Redis为何不能实现多AZ架构的高可用以及腾讯云是如何实现多可用区;
第四部分:分享实现多可用区的几个关键技术点,包含节点部署、就近接入及节点的选主机制。
Redis原生架构
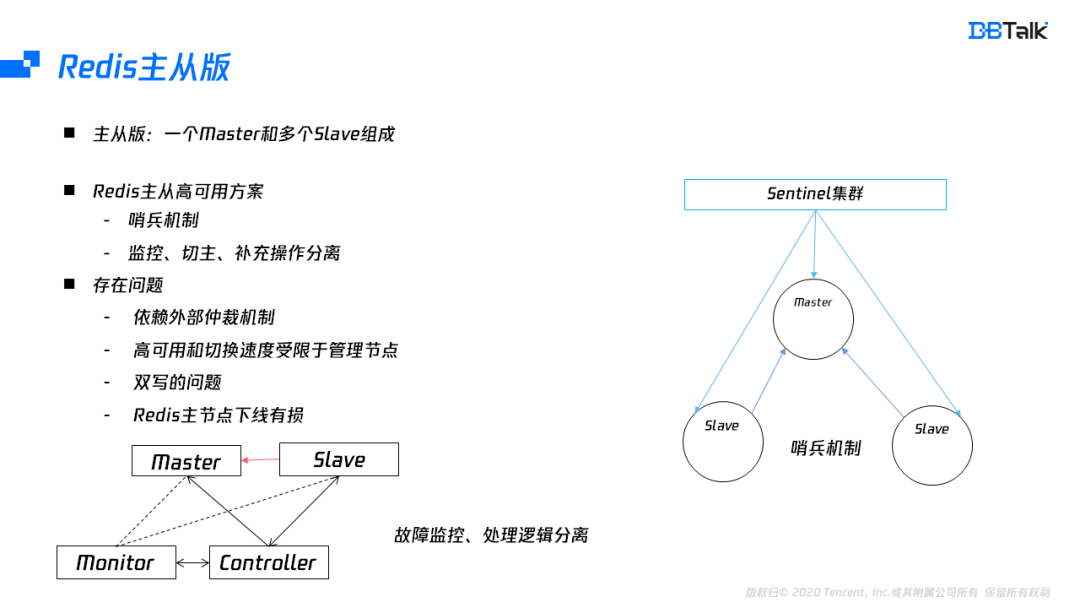
Redis的原生架构包含主从版及集群版。主从版是由一个master,多个slave组成。主从的高可用一般采用哨兵模式。哨兵模式在节点故障后,能自动把相应的节点进行下线处理,但是哨兵模式无法补节点。为了配合补从,需要管控组件进行协助,因此一般会将监控组件和管控组件配合完成主从版的一个高可用。无论是哪种方式,主从版的可用性依赖外部的仲裁组件,存在恢复时间长及组件本身的高可用问题。其次主从版还会导致双写的问题及提主有损的功能缺陷。
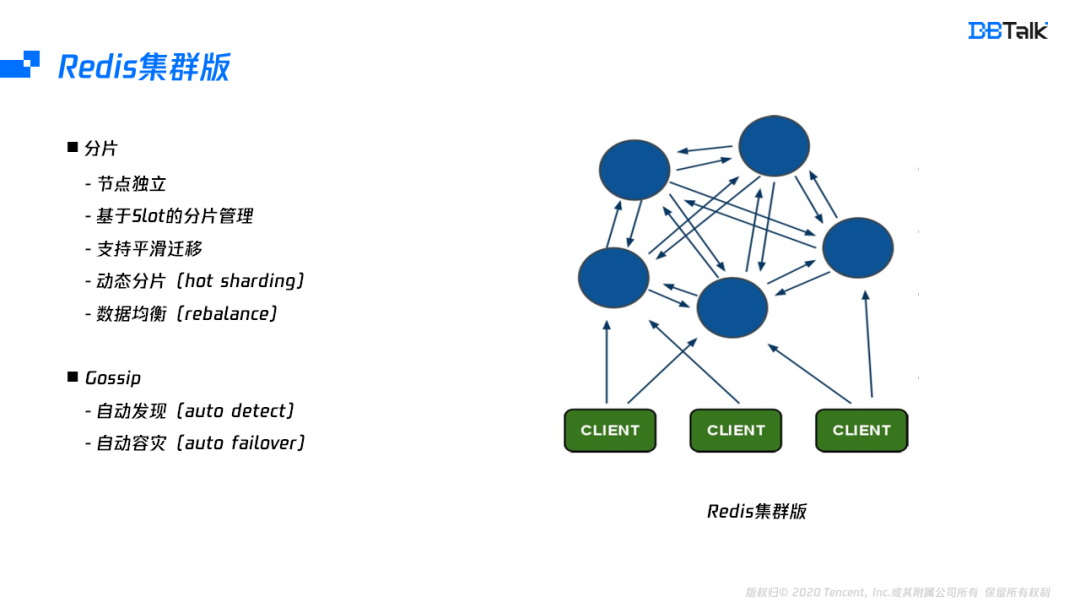
Redis的集群版中的每一个节点相互独立,节点之间通过Gossip协议来进行通信,每一个节点都保存了集群中所有节点的一个信息。集群版的数据基于slot进行分片管理,slot总共有16384个,节点的 slot并不是固定的,可以通过搬迁key的方案来完成slot的迁移,有了slot的搬迁功能,集群版可以实现数据均衡及分片的动态调整。
Redis集群版内部集成了Gossip协议,通过Gossip协议能完成节点的自动发现和自动成灾的功能。自动发现是指一个节点要加入到集群中,只需要加入集群中的任何一个节点,加入后,新节点的信息会通过Gossip推广到集群中的所有的节点。同理,当一个节点故障后,所有节点都会把故障信息发送给集群其它节点,通过一定的判死逻辑,它会让这个节点进行自动下线,这个也就是Redis集群版的自动容灾功能。
为了说明单可用区是如何部署的,我们需要进一步了解Redis集群版的自动容灾。自动容灾总共分为两个步骤,第一个就是我们的判死逻辑,当超过一半的主节点认为该节点故障,集群就会认为这个节点已经故障。此时从节点会发起投票,超过一半的主节点授权该节点为主节点时,它会将角色变为主节点,同时广播角色信息。
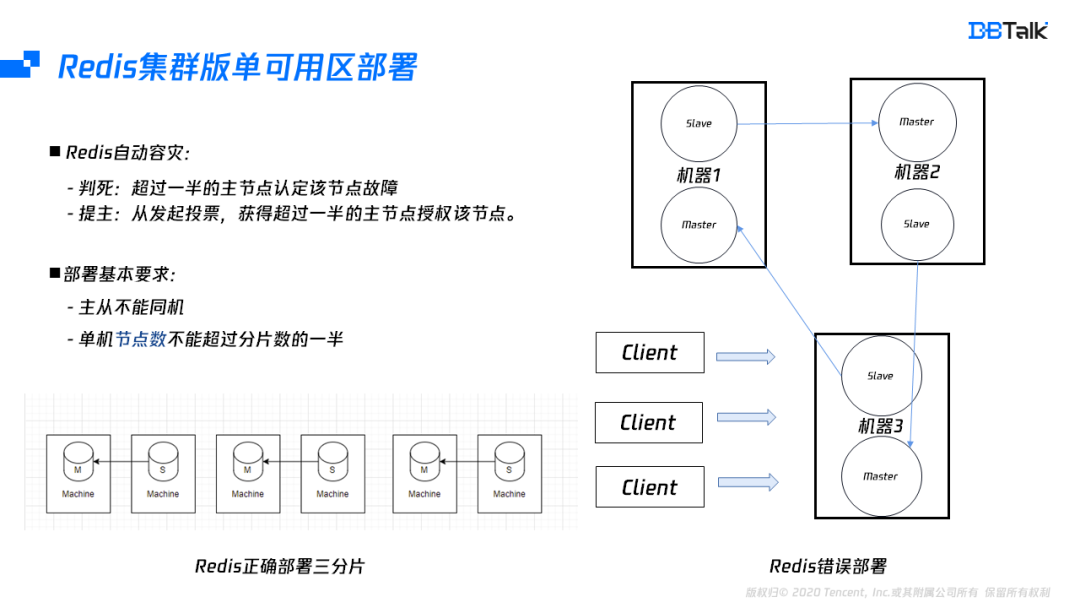
根据上面这两点分析,不难发现Redis集群版有两个部署要求,一个是主从不能同机,当主从同机的机器故障后,整个分片就相当于已经故障了,集群也就变为一个不可用的状态。其次是我们的节点数不能超过分片数的一半,这里要注意的是节点数,而不是只限制主节点数。
上图的右边部分是错误部署方式,在集群节点状态没有变化的情况下,是能够满足高可用的,但集群的主从发生切换后,一个机器上的主节点已经超过大多数,而这个大多数机器故障后,集群无法自动恢复。因此三分三从的集群版,要满足高可用总共需要六台机器。
腾讯云Redis架构
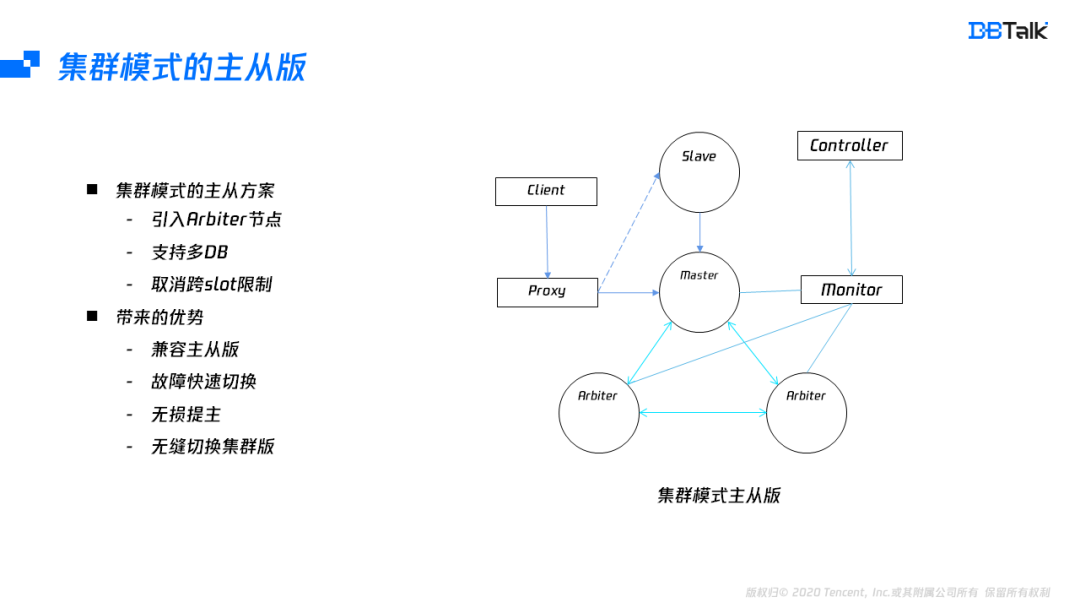
为了解决双主的问题及支持无损提主的操作,腾讯云上使用了集群模式的主从版。实现集群模式的主从版,先要解决三个问题:
第一个是集群模式需要至少3个投票(仲裁)节点的问题,由于主从版本只有一个Master,为了达到3个仲裁节点,我们引入了两个Arbiter节点,Arbiter只有投票权,不存储数据,通过这个改造后,就能够满足了集群版的高可用。
第二个是多DB问题,由于腾讯云上引入了Proxy,减少了对多DB管理的复杂,因此可以放开单DB限制。
最后一个是需要启用跨slot访问,在主从版中,所有的slot都在一个节点上面,不存在跨节点问题,因此可以取消跨slot限制。
解决完这几个主要问题后,集群模式可以达到完全兼容主从版,同时拥有集群版的自动容灾、无损提主及可以在业务支持的情况下,无缝升级为集群版。
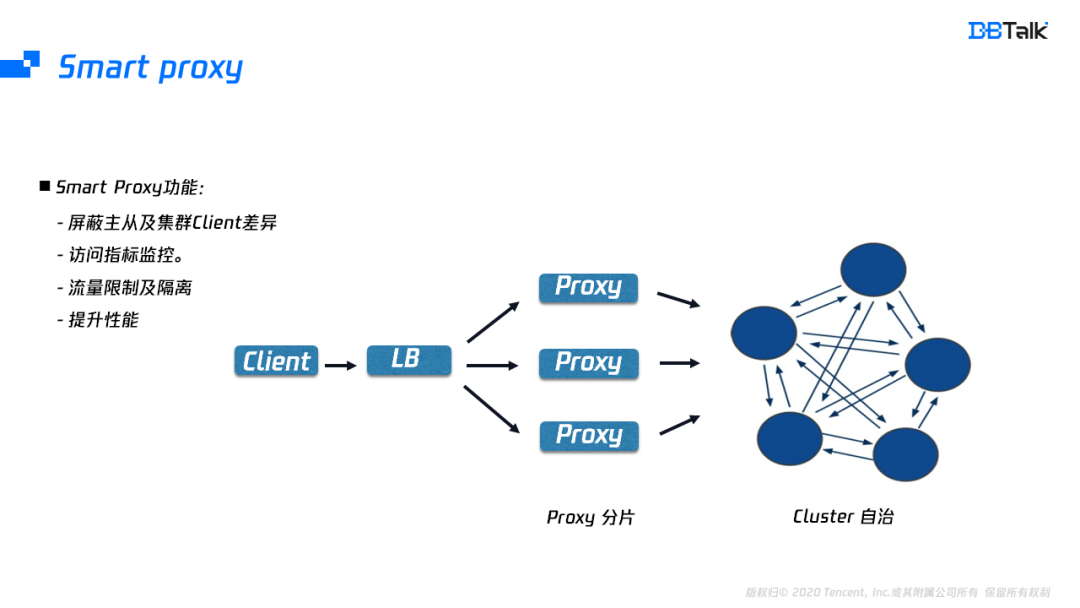
由于Client版本比较多,为了兼容不同的Client,腾讯云引入了Proxy。Proxy除了屏蔽Client的差异外,也屏蔽的后端Redis的版本差异,业务可以使用主从版的Client去使用后端的集群版。Proxy也补齐了Redis缺少的流量隔离及支持更丰富的指标监控,还能将多个连接的请求转换为pipeline请求转发到后端,提升Redis的性能。
Redis的多AZ架构
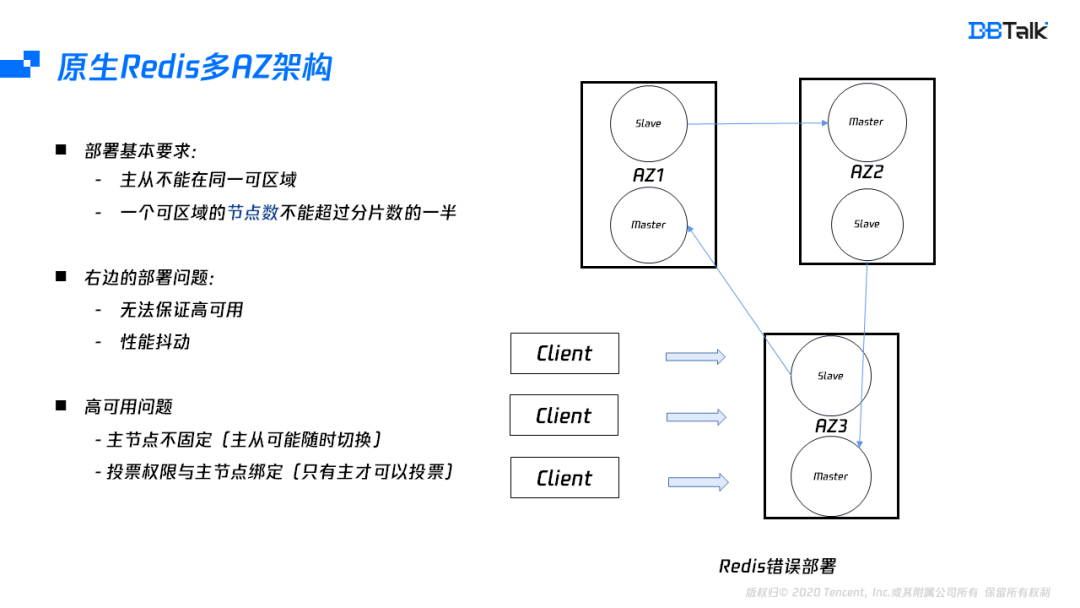
部署高可用的多可用区架构,需要至少满足两个条件:
主从不能部署到同一个可用区;
一个可用区的节点数不能超过分片数的一半。
如果我们部署一个三分片的实例,那应该需要个6个可用区才能真正保证它的高可用。即使可用区充足,它也会有性能的抖动,访问本可用区,性能和单可用区相同,但如果跨可用区访问,至少出现2ms延迟,因此原生的Redis是不适合多可用区的部署,为了实现高可用的部署,我们需要更深入的分析它的问题所在。这种场景的高可用不满足主要是由于主节点漂移,而投票权和主节点又是绑定关系。当投票权在不同可用区间切换后,导致超过大多数投票节点在该可用区,此时该可用区故障后就会出现集群无法恢复的情况。
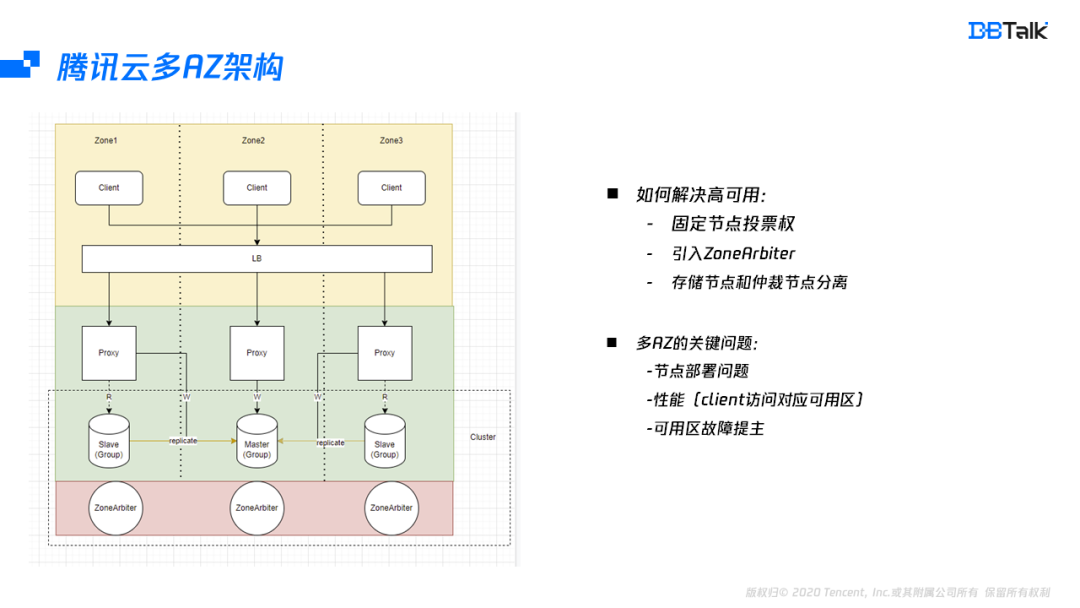
从上面分析可以看出,高可用的问题是由于投票权发生漂移导致的。假如能把投票权固定在某些节点上面,这样投票权就可以不再漂移。当然这里无法将投票权固定在从或者主节点上,对于多可用区,最好的方式就是引入了一个ZoneArbiter节点,它只做节点的判死及选主,不存储任何数据。这样投票权就从存储节点中分离出来。在投票权分离后,即使数据节点的Master可以位于一个可用区,从位于不同的可用区也能满足高可用。业务在主可用区中访问和单可用区访问性能是相同的。
多AZ的关键技术
保证高可用后,接下来介绍多可用区的三个关键的点:高可用如何部署、性能如何达到最优、可用区故障后保证集群自动恢复。
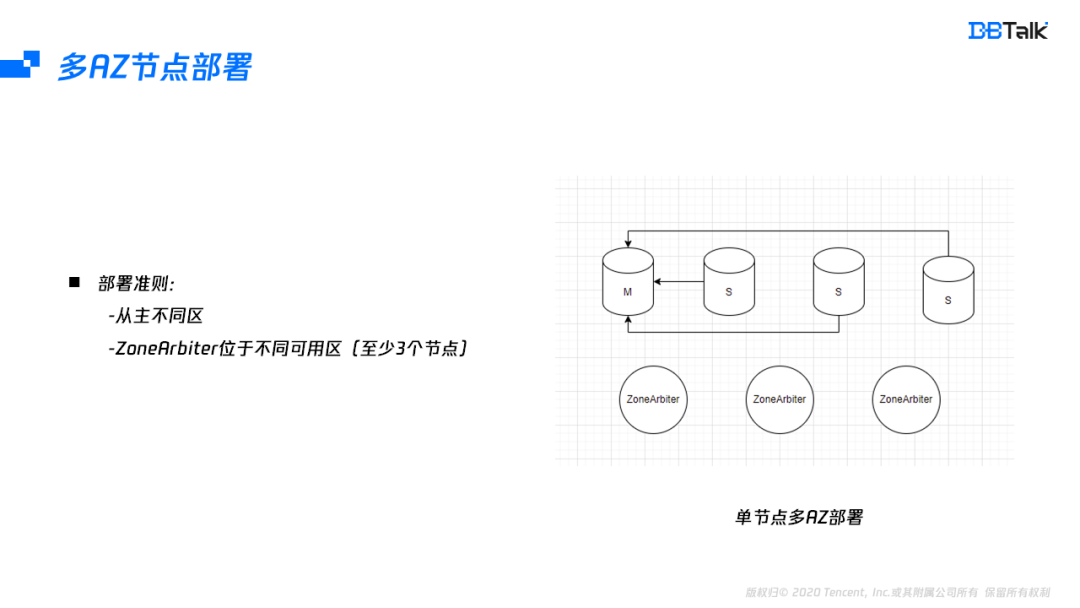
节点部署同样需要满足两个点:第一是主从不能同可用区,这个比较容易满足,只要有2个可用区即可,第二点是至少三个ZoneArbiter节点位于不同的可用区,第二个条件需要三个可用区,如果没有三个可用区的地域也可以将ZoneArbiter部署于就近的地域,因为数据节点和仲裁节点是分离的,位于其它可用区的节点只会出现判死及提主有毫秒级延迟,对性能和高可用不会有任何影响。
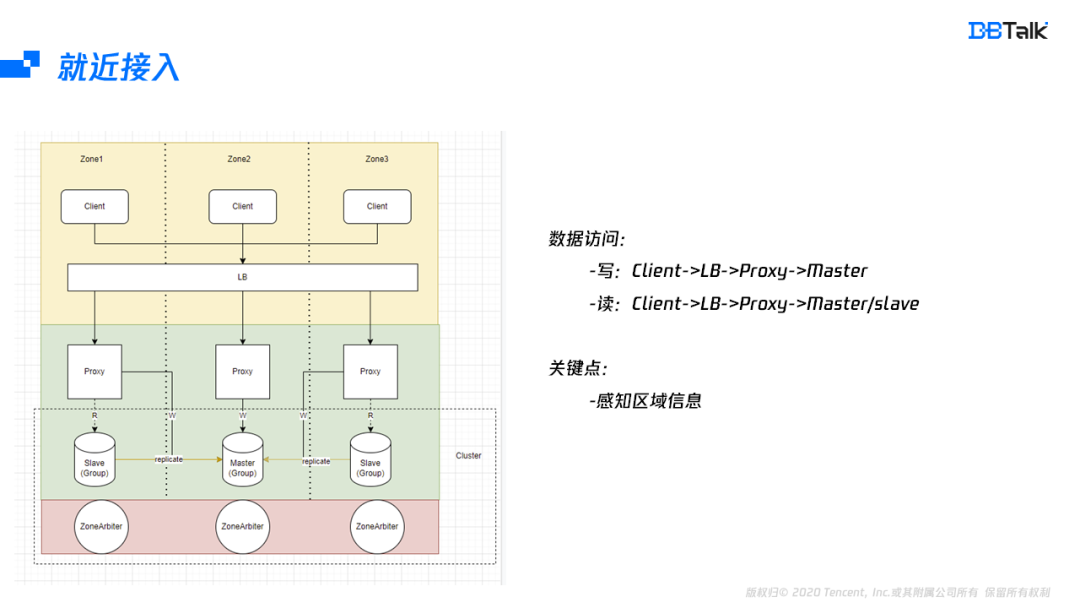
分析完部署后,再来看下数据的存储链路,存储链路分为读和写链路,写链路是从client到LB,再到Proxy,最后将数据写入到相应的Master。在读的时候,开启就近读的特性后,链路从client到LB,再到Proxy,最后选择一个就近的节点读取数据。就近路径选择包含LB的就近选择及Proxy的就近选择,LB要根据Client的地址选择相对应的Proxy。如果是读,Proxy要跟据自身所在可用区信息选择同可用区的节点进行读访问。如果是写,Proxy需要访问主可用区的Master节点。能实现就近访问,最关键的一个点就是要LB及Proxy要存储相关后端的可用区信息,有这些信息后,就能实现就近的路由选择。
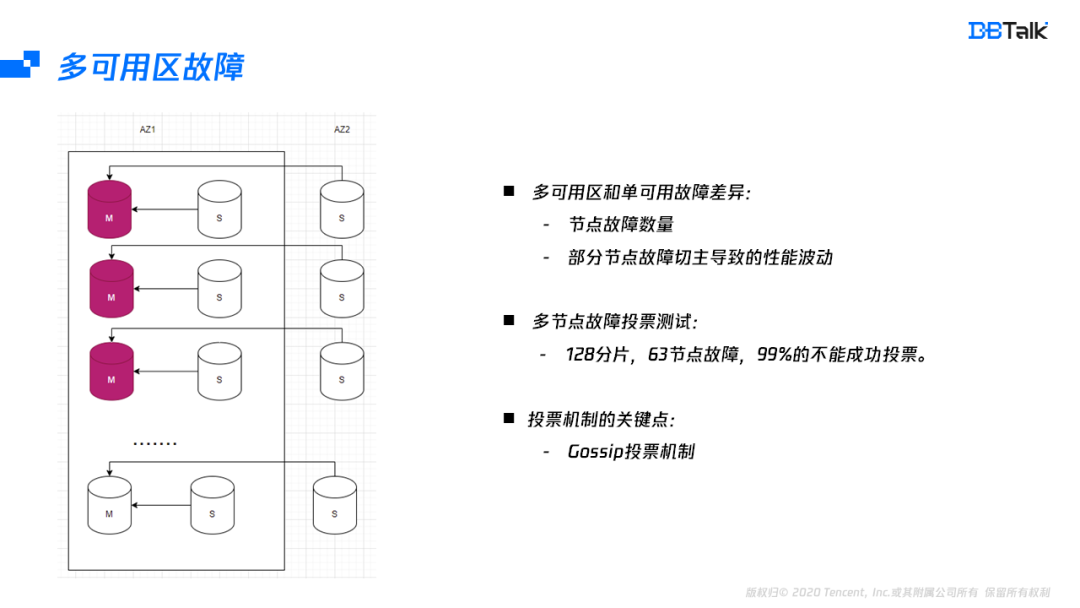
单可用区和多可用区故障的最大区别是:首先多可用区的某一节点故障后,主节点有可能切到其它可用区会导致性能波动。其次对于多可用区的实例,整个可用区故障后,需要投票的节点比单可用区的节点多。在多节点故障的场景测试中,128分片,63节点同时故障,99%以上都无法正常恢复集群。而无法恢复的关键就是Redis的选主机制导致。因此我们需要更深入的理解Redis的选主机制。
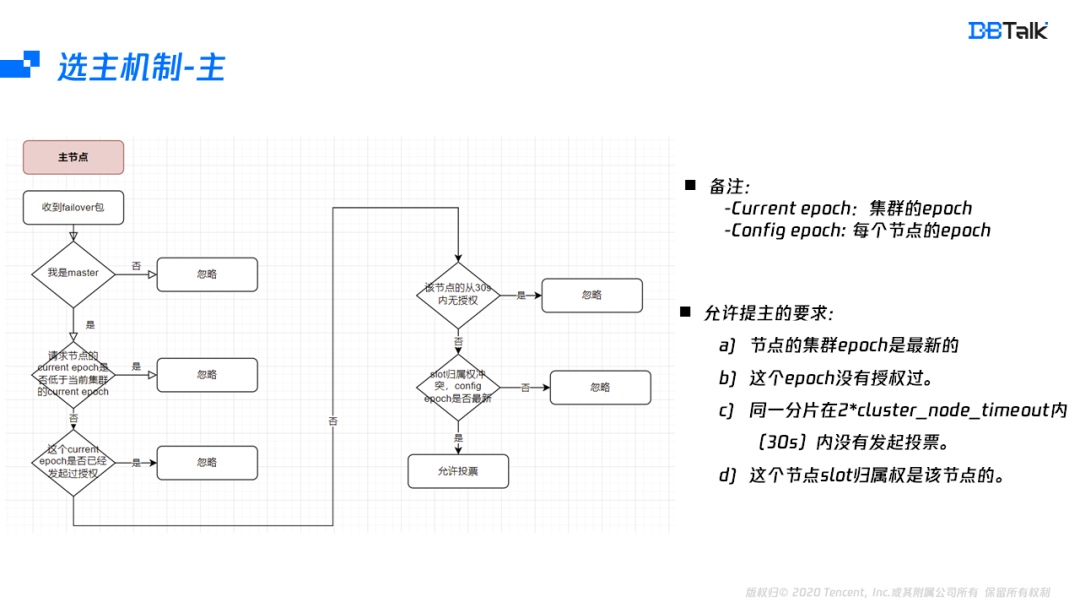
首先看下选主机制的授权机制,当主节点收到一个failover信息后,核对自身节点为Master,然后检查投票的这个节点集群的epoch是不是最新的,并且在这个epoch,并没有投票任何的节点,为了防止一个节点的多个从节点重复发起投票,这里在30s内不允许重复发起。最后再核对这个slot的归属权是否属于发起failover的这个节点,如果都没有问题,那么就会投票给该节点。
综上,允许该主节点投票的条件是:
- 发起投票的节点的集群信息是最新的;
- 一个epoch只能授权一个节点;
- 30s内同一分片只能授权一次;
- slot的归属权正确。
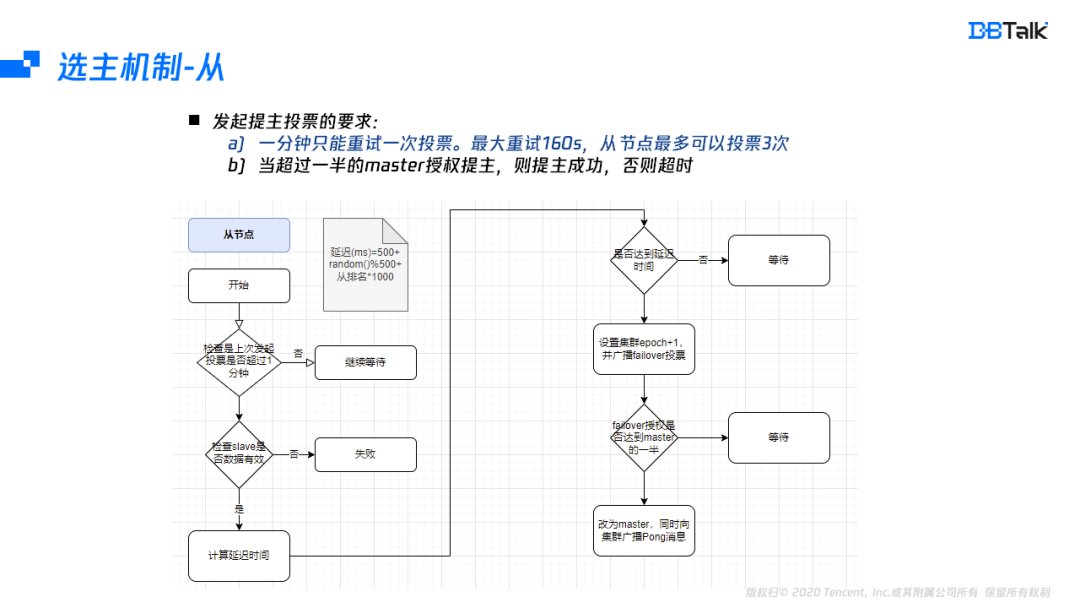
看完主节点的授权机制后,再看下从节点发起投票的机制。发起投票的流程是先核对1分钟内没有发起过投票,再核对该节点数据是否有效(不能和主断开160s)。从节点是有效的,就开始计算发起投票的时间,当投票时间到后,将集群的epoch+1,然后再发起failover,如果主节点的授权超过分片数的一半,则自身提为主节点,并广播节点信息。这里从节点投票有两个关键的点,一分钟只能重试一次投票,最大重试160s,从节点最多可以投票3次。当超过一半的master授权提主,提主成功,否则超时。
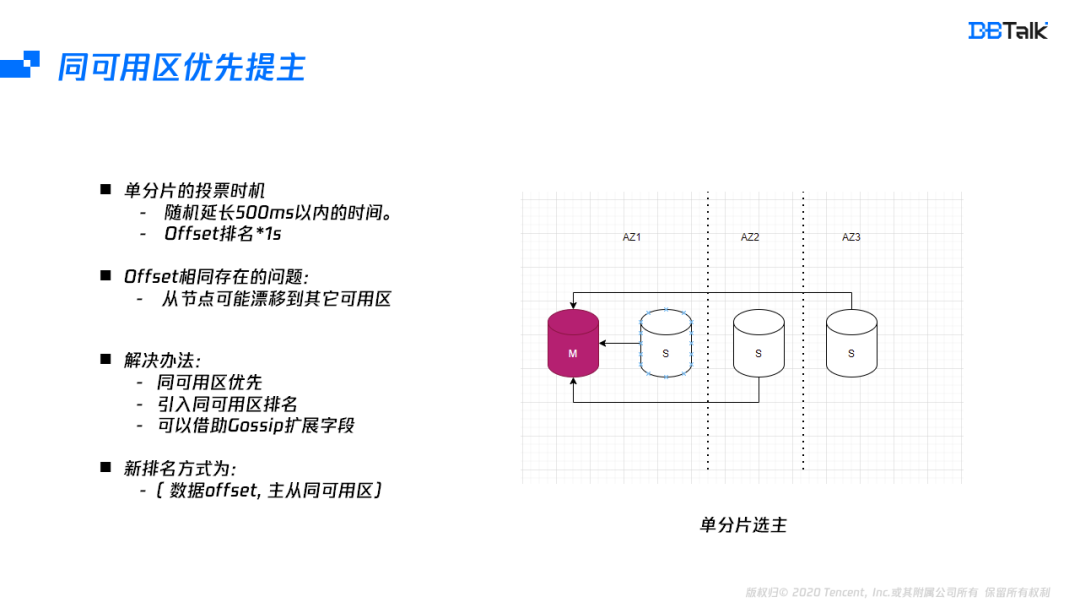
在某一主节点故障后,集群的选主尽量在同可用区中选择。一个分片不同从节点之间的选主时间由节点的offset排名及的500ms的随机时间决定。在写少读多情况下,offset排名大多时间是相同的。在单可用区场景下,随机选择一个节点本身无任何影响,但多可用区就会出现性能的抖动。因此这个就需要在排名中引入同可用区的排名。而同可用区的排名就需要要每个节点都知道所有节点的可用区信息。在Gossip中刚好有一个预留字段,我们将可用区信息存储在这个预留字段中,然后将这个节点的可用区信息会广播到所有节点中,这样每个节点都有所有节点的可用区信息。在投票的时候我们按照offset和可用区信息排名综合考虑来保证同可用区优先提主。
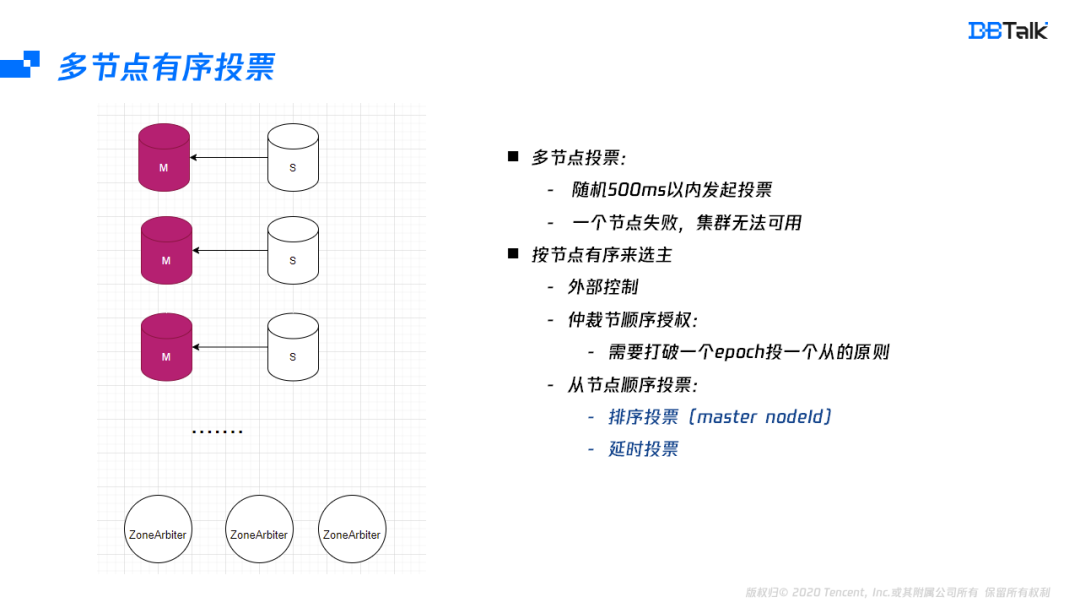
一个节点的选主分析完后,我们来分析下多节点故障的投票时机。多个节点发起投票时,会随机选择500毫秒内的一个时间点,然后发起投票。假如集群有100个主节点,500毫秒发起完投票,每个节点投票时间是5毫秒,5毫秒肯定是不够一个投票周期。在之前的多节点故障投票成功率测试结果也就证明了这种情况几乎不能成功。
投票不能成功的关机是集群不同节点投票是随机发起导致的,既然随机存在冲突,最直接的解决办法就是按顺序来投票。按顺序投票可以简单分为两种,一种是依赖外部的控制,引入外部依赖就需要保证它的高可用,一般情况下,存储链路的高可用最好不要依赖外部组件,否则会导致整体的可用性受外部组件加存储节点的高可用的影响。那再考虑下集群内部实现顺序投票,集群内部实现顺序投票也有两种方式,一个是仲裁节点按顺序来授权。但是这种方式很容易打破一个epoch投一个从节点的原则,打破后可能会导致投票结果不符合预期。还有一种解决办法是由从节点来顺序发起投票。
从节点要保证顺序发起投票,那就需要每个节点的排名是保证相同的,而节点ID在生命周期中是唯一的,且每个节点都有其它节点的ID信息,因此这里选择节点ID的排名是比较好的一种方案,每个从节点ID发起投票前,首先核对自己的节点ID是不是第一名,如果是就发起投票,如果不是就等待500ms。这个500ms是为了防止队头投票失败的场景。按这种方式优化后,投票都可以成功。由于本身是分布式的,这里还是存在着小概率失败,在失败后就需要外部监控,强行提主,保证集群的尽快恢复。
专家答疑
1.通过sentinel连接redis也会出现双写么?
答:双写是对存量的连接来说的,如果存量的连接没有断开,它会写入到之前的master节点,而新的连接会写入到新的master节点,此时就是双写。而集群模式出现双写最多15s(判死时间),因为15s后发现自身已经脱离大多数,会将节点切换为集群Fail,此时写入及读取出错,而规避了双写的问题。
2. 固定节点投票,这几个节点会不会成为单点
答:单点是不可规避的,比如1主1从,主挂了,那么从提主后,这个节点就是单点,出现单点是需要我们进行补从操作。而这里仲裁节点出现故障,补充一个节点即可,只要保证大多数仲裁节点正常工作即可,由于仲裁和数据访问是分离的,故障及补节点对数据访问无任何影响。
3. 整个可用区故障和可用区内节点故障failover的处理策略是什么?
答:不管是整个可用区故障还是单机故障导致的多节点故障,都应该采用顺序投票来完成,减少冲突,而如果同可用区有从节点,该节点应该优先提主。
4.想问下写请求,要同步等从复制完吗?
答:Redis不是强同步,Redis强同步需要使用wait命令来完成。
5.最大支持多少redis分片呢,节点多了使用gossip有会不会有性能问题?
答:最好不要超过500个,超过500个节点会出现ping导致的性能抖动,此时只能通过调大cluster_node_timeout来降低性能抖动
6.多区主节点,写同步如何实现?
答:可能想问的是全球多活实例,多活实例一般需要数据先落盘,然后再同步给其它节点,同步的时候要保证从节点先收到数据后,才能发送给多活的其它节点。还需要解决数据同步环路,数据冲突等问题。
7.当前选主逻辑和raft选主有大的区别吗?
答:相同的点都需要满足大多数授权,都有一个随机选择时间,不同的点Redis是主节点有投票权(针对多分片情况),而raft可认为是所有节点(针对单分片情况)。Raft数据写入要超一半节点成功才返回成。Redis使用弱同步机制(可以使用wait强势主从同步完返回),写完主节点立即返回,在主故障后,需要数据越新的节点优先提主(数据偏移值由Gossip通知给其它节点),但不保证它一定成功。
关于作者
刘家文,腾讯云数据库高级工程师,先后负责Linux内核及redis相关研发工作,目前主要负责腾讯云数据库Redis的开发和架构设计,对Redis高可用,内核开发有着丰富的经验。
Redis如何实现多可用区?的更多相关文章
- 云区域(region),可用区(AZ),跨区域数据复制(Cross-region replication)与灾备(Disaster Recovery)(部分1)
本文分两部分:部分1 和 部分2.部分1 介绍 AWS,部分2 介绍阿里云和OpenStack云. 1. AWS 1.1 AWS 地理组件概况 AWS 提供三种地理性组件: Regions:区域,即A ...
- Pod在多可用区worker节点上的高可用部署
一. 需求分析 当前kubernetes集群中的worker节点可以支持添加多可用区中的ECS,这种部署方式的目的是可以让一个应用的多个pod(至少两个)能够分布在不同的可用区,起码不能分布在同一个可 ...
- UCloud可用区的设计理念及功能图文详解
导读 过去的几个月内,UCloud对自身的云计算基础架构进行了全面升级,于日前宣布基础架构全面支持地域和可用区,并将可用区项目命名为Sixshot.通过这两层的设计架构来组织云服务,可以为用户提供高可 ...
- Redis Sentinel主从高可用方案
Redis Sentinel主从高可用方案 本文介绍一种通过Jed和Sentinel实现Redis集群(主从)的高可用方案,该方案需要使用Jedis2.2.2及以上版本(强制),Redis2.8及以上 ...
- AWS的区域和可用区概念解释
AWS的每个区域一般由多个可用区(AZ)组成,而一个可用区一般是由多个数据中心组成.AWS引入可用区设计主要是为了提升用户应用程序的高可用性.因为可用区与可用区之间在设计上是相互独立的,也就是说它们会 ...
- Redis Sentinel实现高可用配置
一般情况下yum安装redis的启动目录在:”/usr/sbin” :配置目录在”/etc/redis/”在其目录下会有默认的redis.conf和redis-sentinel.conf redis高 ...
- Redis主从配置及通过Keepalived实现Redis自动切换高可用
Redis主从配置及通过Keepalived实现Redis自动切换高可用 [日期:2014-07-23] 来源:Linux社区 作者:fuquanjun [字体:大 中 小] 一:环境介绍: M ...
- redis作为缓存场景使用,内存耗尽时,突然出现大量的逐出,在这个逐出的过程中阻塞正常的读写请求,导致 redis 短时间不可用
redis 突然大量逐出导致读写请求block 内容目录: 现象 背景 原因 解决方案 ref 现象 redis作为缓存场景使用,内存耗尽时,突然出现大量的逐出,在这个逐出的过程中阻塞正常的读写请 ...
- 亚马逊云 RDB数据故障转移(多可用区)
RDB关系数据库(Relational Database,RDB) 创建名为VPC for RDS的vpc 两个可用区,两组公内网 创建安全组 创建RDS数据库实例用的数据库子网组 创建RDS数据库实 ...
随机推荐
- 详解javascript的eventloop(二):eventloop和dom渲染
记住: JS是单线程的,他和dom渲染共用一个线程 JS执行的时候,会给dom渲染留一些时机 上一篇讲到eventloop的执行机制,但是在这个机制中的call stack执行完成后(包括第一遍的ev ...
- Python简单爬取Amazon图片-其他网站相应修改链接和正则
简单爬取Amazon图片信息 这是一个简单的模板,如果需要爬取其他网站图片信息,更改URL和正则表达式即可 1 import requests 2 import re 3 import os 4 de ...
- 关于C++类定义中不能声明该类对象,而Java中可以的原因
相信接触过C++的人,在学习Java的过程当中,会遇到这样一个问题:在Java中常常会在类定义中声明一个该类的对象(例如Person类定义中声明一些叫parents之类的Person对象),但是在C+ ...
- 我向PostgreSQL社区贡献的功能:空闲会话超时
经过约八个月的努力,终于完成了 PostgreSQL 空闲会话超时断开的功能. 该功能将在版本 14 中发布. 这是我第一次向 PostgreSQL 提供功能,虽然之前也有向社区提供过补丁,但是这次整 ...
- debian 11 开启 samba 共享文件夹
安装 apt-get install samba 安装时,提示搜索不到 此包时 解决办法1:apt-get update 更新源 解决办法2:更改镜像源,可以采用阿里云,网易云等镜像站里提供的镜 ...
- netty系列之:netty中的核心编码器bytes数组
目录 简介 byte是什么 netty中的byte数组的工具类 netty中byte的编码器 总结 简介 我们知道netty中数据传输的核心是ByteBuf,ByteBuf提供了多种数据读写的方法,包 ...
- XCTF练习题---MISC---pure-color
XCTF练习题---MISC---pure-color flag:flag{true_steganographers_doesnt_need_any_tools} 解题步骤: 1.观察题目,下载附件 ...
- 1001-MySQL学习-第一节自习课
MySQL学习(第一节自习课) 一. 软件下载.安装 下载地址:https://dev.mysql.com/downloads/installer/ 位置:mysql->installer-&g ...
- [笔记] 有向无环图 DAG
最小链覆盖 (最长反链) 最小链覆盖 \(=n-\) 最大匹配. 考虑首先每个点自成一条链,此时恰好有 \(n\) 条链,最终答案一定是合并(首尾相接)若干条链形成的. 将两点匹配的含义其实就是将链合 ...
- JS中的 && 、|| 、??、?. 运算符
javascript有不少好用的运算符,合理的使用可以大大提高工作效率,以下简单介绍了4种,具体如下: && 逻辑与运算(&&)是 AND 布尔操作.只有两个操作数都为 ...