Python数据分析教程(一):Numpy
原文链接:https://blog.onefly.top/posts/13140.html
数据的纬度
一维数据:列表和集合类型
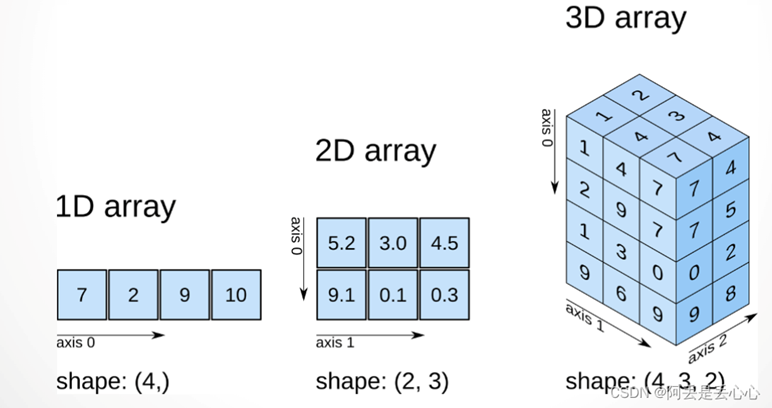
二维数据:列表类型
多维数据:列表类型
高维数据:字典类型或数据表示格式,如json、xml、yaml

维度:一组数据的组织形式

列表和数组:一组数据的有序结构

Numpy
Numpy介绍
NumPy是一个开源的Python科学计算基础库,包含:
一个强大的N维数组对象ndarray
广播功能函数
整合C/C++/Fortran代码的工具
线性代数、傅里叶变换、随机数生成等功能
NumPy是SciPy、Pandas等数据处理或科学计算库的基础
模块导入:
import numpy as np
N维数组对象:ndarray
数组对象可以去掉元素间运算所需的循环,使一维向量更像单个数据
设置专门的数组对象,经过优化,可以提升这类应用的运算速度————科学计算中,一个维度所有数据的类型往往相同
数组对象采用相同的数据类型,有助于节省运算和存储空间

ndarray实例
- ndarray是一个多维数组对象,由两部分构成:
- 实际的数据
- 描述这些数据的元数据(数据维度、数据类型等)
- ndarray数组一般要求所有元素类型相同(同质),数组下标从0开始

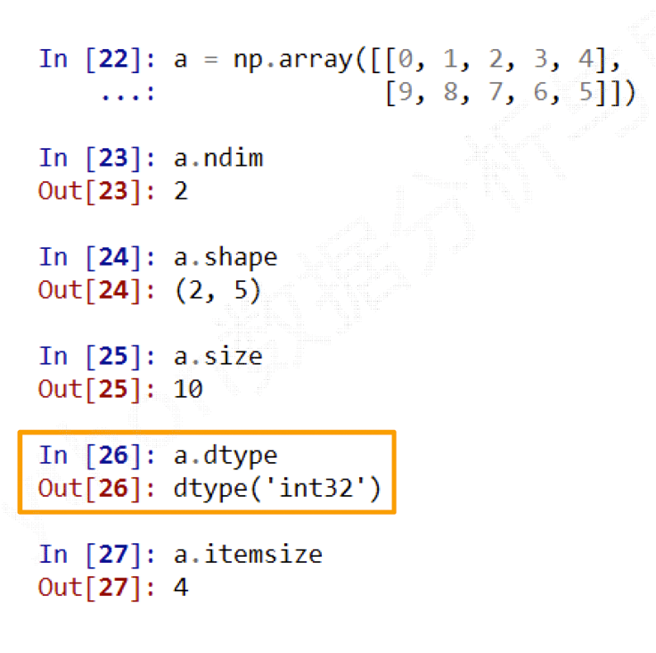
ndarray对象的属性
#属性&说明
.ndim #秩,即轴的数量或维度的数量
.shape #ndarray对象的尺度,对于矩阵,n行m列
.size #ndarray对象元素的个数,相当于.shape中n*m的值
.dtype #ndarray对象的元素类型
.itemsize #ndarray对象中每个元素的大小,以字节为单位
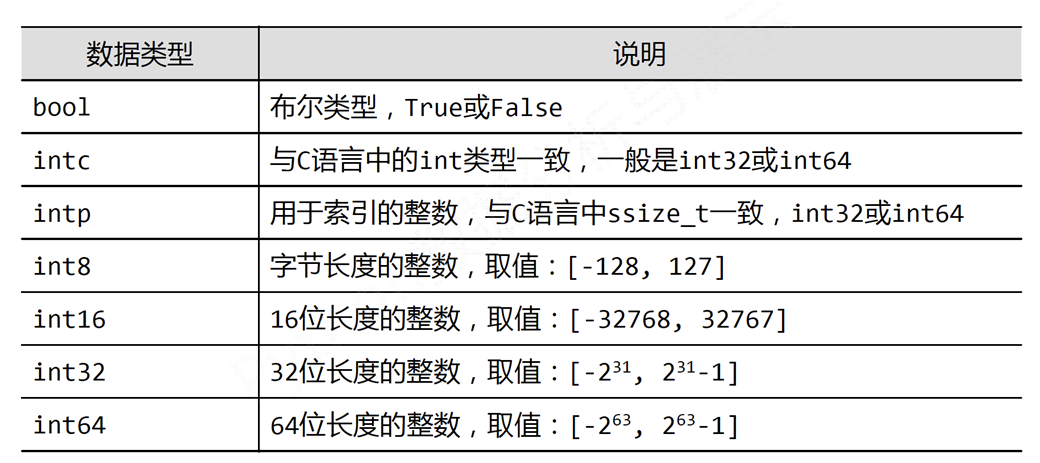
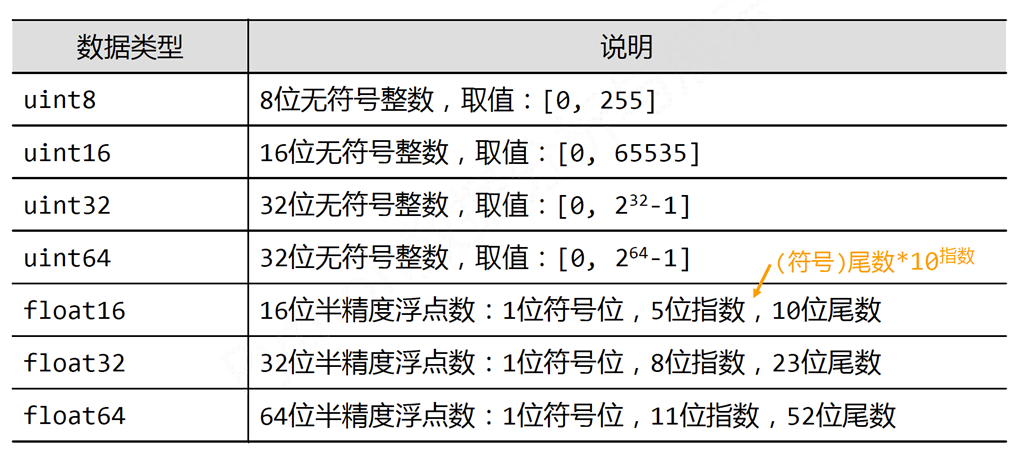
ndarray的元素类型
ndarray数组的创建方法
- 从Python中的列表、元组等类型创建ndarray数组
- 使用NumPy中函数创建ndarray数组,如:arange, ones, zeros等
- 从字节流(raw bytes)中创建ndarray数组
- 从文件中读取特定格式,创建ndarray数组
通过列表创建ndarray:

使用函数创建ndarray:
#函数&说明
np.arange(n) #类似range()函数,返回ndarray类型,元素从0到n-1
np.ones(shape) #根据shapes生成一个全l数组,shape是元组类型
np.zeros(shape) #根据shape生成一个全数组,shape是元组类型
np.full(shape,val) #根据shape:生成一个数组,每个元素值都是val
np.eye(n) #创建一个正方的n*n单位矩阵,对角线为1,其余为0
ndarray数组的变换:
对于创建后的ndarray数组,可以对其进行维度变换和元素类型变换
#方法&说明
.reshape(shape) #不改变数组元素,返回一个shape形状的数组,原数组不变
.resize(shape) #与.reshape()功能一致,但修改原数组
.swapaxes(ax1,ax2) #将数组n个维度中两个维度进行调换
.flatten() #对数组进行降维,返回折叠后的一维数组,原数组不变

数组的索引和切片
- 索引:获取数组中特定位置元素的过程
- 切片:获取数组元素子集的过程
一维数组的索引和切片

多维数组索引

多维数组切片

ndarray数组的运算
NumPy一元函数:
#函数&说明
np.abs(x)
np.fabs(x)#计算数组各元素的绝对值
np.sqrt(x)#计算数组各元素的平方根
np.square(x)#计算数组各元素的平方
np.log(x)
np.1og10(x)
np.1og2(x)#计算数组各元素的自然对数、10底对数和2底对数
np.ceil(x)
np.floor(x)#计算数组各元素的ceiling值或f1oor值
np.rint(x)#计算数组各元素的四舍五入值
np.modf(x)#将数组各元素的小数和整数部分以两个独立数组形式返回
np.cos(x)np.cosh(x)
np.sin(x)np.sinh(x)#计算数组各元素的普通型和双曲型三角函数
np.tan(x)np.tanh(x)
np.exp(x)#计算数组各元素的指数值
np.sign(x)#计算数组各元素的符号值,1(+),0,-1(-)
NumPy二元函数:
#函数&说明
+ - * / ** #两个数组各元素进行对应运算
np.maximum(x,y)
np.fmax()
np.minimum(x,y)
np.fmin() #元素级的最大值/最小值计算
np.mod(x,y) #元素级的模运算
np.copysign(x,y) #将数组y中各元素值的符号赋值给数组x对应元素
>< >= <= == != #算术比较,产生布尔型数组
Numpy数据存取:
csv格式:

np.savetxt(frame,array,fmt='%.18e',delimiter=None)
- frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件
- array:存入文件的数组
- fmt:写入文件的格式,例如:%d%.2f%.18e
- delimiter:分割字符串,默认是任何空格
其他:
np.loadtxt(frame,dtype=np.float,delimiter=None,
unpack=False)
- frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件
- dtype:数据类型,可选
- delimiter:分割字符串,默认是任何空格
- unpack:如果True,读入属性将分别写入不同变量
其他:
a.tofile(frame, sep='', format='%s')
np.fromfile(frame, dtype=float, count=‐1, sep='')
numpy随机数函数子库:
np.random.*
#函数&说明
rand(d0,d1,..,dn) #根据d0-dn创建随机数数组,浮点数,[0,1),均匀分布
randn(d0,d1,..,dn) #根据d0-dn创建随机数数组,标准正态分布
randint(low[,high,shape]) #根据shapet创建随机整数或整数数组,范围是[low,high)
seed(s) #随机数种子,s是给定的种子值
shuffle(a) #根据数组a的第1轴进行随排列,改变数组×
permutation(a) #根据数组a的第1轴产生一个新的乱序数组,不改变数组x
choice(a[,size,replace,p]) #从一维数组a中以概率p抽取元素,形成size形状新数组 replace表示是否可以重用元素,默认为False
uniform(low,high,size) #产生具有均匀分布的数组,low起始值,high结束值,size形状
normal(loc,scale,size) #产生具有正态分布的数组,loc均值,scale标准差,size形状
poisson(lam,size) #产生具有泊松分布的数组,lam随机事件发生率,size形状
numpy统计函数:
np.*
#函数&说明
sum(a,axis=None) #根据给定轴axis计算数组a相关元素之和,axis整数或元组
mean(a,axis=None) #根据给定轴axis计算数组a相关元素的期望,axis整数或元组
average(a,axis=None,weights=None) #根据给定轴axis计算数组a相关元素的加权平均值
std(a,axis=None) #根据给定轴axis计算数组a相关元素的标准差
var(a,axis=None) #根据给定轴axis计算数组a相关元素的方差
min(a)
max(a) #计算数组a中元素的最小值、最大值
argmin(a)
argmax(a) #计算数组a中元素最小值、最大值的降一维后下标
unravel_index(index,shape) #根据shape?将一维下标index转换成多维下标
ptp(a) #计算数组a中元素最大值与最小值的差
median(a) #计算数组a中元素的中位数(中值)
numpy替换函数:
- np.where(condition, x, y) ——满足条件(condition),输出x,不满足输出y。
- 只有条件 (condition),没有x和y,则输出满足条件 (即非0) 元素的坐标 (等价于numpy.nonzero)

numpy数据存取
CSV文件
np.loadtxt()
np.savetxt()
多维数据存取
a.tofile()
np.fromfile()
np.save()
np.savez()
np.load()
随机函数
np.random.rand()
np.random.randn()
np.random.randint()
np.random.seed()
np.random.shuffle()
np.random.permutation()
np.random.choice()
原文链接:https://ranxi2001.github.io/posts/13140.html
Python数据分析教程(一):Numpy的更多相关文章
- python数据分析三剑客之: Numpy
数据分析三剑客之: Numpy 一丶Numpy的使用 numpy 是Python语言的一个扩展程序库,支持大维度的数组和矩阵运算.也支持针对数组运算提供大量的数学函数库 创建ndarray # 1 ...
- python 数据分析工具之 numpy pandas matplotlib
作为一个网络技术人员,机器学习是一种很有必要学习的技术,在这个数据爆炸的时代更是如此. python做数据分析,最常用以下几个库 numpy pandas matplotlib 一.Numpy库 为了 ...
- Python数据分析教程(二):Pandas
Pandas导入 Pandas是Python第三方库,提供高性能易用数据类型和分析工具 Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用 两个数据类型:Series, Da ...
- Python数据分析工具库-Numpy 数组支持库(一)
1 Numpy数组 在Python中有类似数组功能的数据结构,比如list,但在数据量大时,list的运行速度便不尽如意,Numpy(Numerical Python)提供了真正的数组功能,以及对数据 ...
- $python数据分析基础——初识numpy库
numpy库是python的一个著名的科学计算库,本文是一个quickstart. 引入:计算BMI BMI = 体重(kg)/身高(m)^2 假如有如下几组体重和身高数据,让求每组数据的BMI值: ...
- python数据分析教程大全
第一篇:Anaconda安装和使用 第二篇:Jupyter norebook使用 第三篇:pandas教程 第四篇:numpy教程 第五篇:Matplotlib教程 第六篇:实战项目 期待吗?(微笑脸 ...
- Python数据分析工具库-Numpy 数组支持库(二)
1 shape变化及转置 >>> a = np.floor(10*np.random.random((3,4))) >>> a array([[ 2., 8., 0 ...
- 【Python 数据分析】module 'numpy' has no attribute 'array'
安装好Numpy模块后,开始做了几个小测试都可以运行,但是当我创建numpy.py这个文件后 numpy.py import numpy y = numpy.array([[11,4,2],[2,6, ...
- python数据分析2之numpy
源代码 # -*- coding: utf-8 -*- """ Spyder Editor This is a temporary script file. " ...
随机推荐
- Codeforces Round #789 (Div. 2)
题集链接 A. Tokitsukaze and All Zero Sequence 题意 Tokitsukaze 有一个长度为 n 的序列 a. 对于每个操作,她选择两个数字 ai 和 aj (i≠j ...
- 广西省行政村边界shp数据/广西省乡镇边界/广西省土地利用分类数据/广西省气象数据/降雨量分布数据/太阳辐射数据
数据下载链接:数据下载链接 广西壮族自治区,地处中国南部,北回归线横贯中部,属亚热带季风气候区.南北以贺州--东兰一线为界,此界以北属中亚热带季风气候区,以南属南亚热带季风气候区. 数据范围:全 ...
- 5-21 拦截器 Interceptor
Spring MVC拦截器 什么是拦截器 拦截器是SpringMvc框架提供的功能 它可以在控制器方法运行之前或运行之后(还有其它特殊时机)对请求进行处理或加工的特定接口 常见面试题:过滤器和拦截器的 ...
- vite搭建一个vue2的框架
01-创建一个基础的模板框架 npm init vite@latest 02-安装依赖 npm install npm install vue@2.x vue-template-compiler@2 ...
- CSS(十四):盒子模型
页面布局的本质 网页布局过程: 先准备好相关的网页元素,网页元素基本都是盒子. 利用CSS设置好盒子样式,然后放到相应的位置 往盒子里面装内容 网页布局的本质:就是利用CSS摆盒子 盒子模型 组成 所 ...
- 1000-ms-HashMap 线程安全安全问题
问题: HashMap是否是线程安全 详解 http://www.importnew.com/21396.html 有源码分析 和代码性能比较 CHM性能最好 HashMap不是线程安全的:Hasht ...
- wdos centos64位通过yum来升级PHP
通过yum list installed | grep php可以查看所有已安装的php软件 使用yum remove php -- 将所有的包删除 通过yum list php*查看是否有自己需要安 ...
- 一网成擒全端涵盖,在不同架构(Intel x86/Apple m1 silicon)不同开发平台(Win10/Win11/Mac/Ubuntu)上安装配置Python3.10开发环境
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_200 时光荏苒,过隙白驹,即将进入2022年,著名敏捷开发语言Python也放出了3.10最终版,本次我们来展示一下在不同的系统和 ...
- 二位数组——扩展:冒泡排序、Arrays类
1.冒泡排序 速记口诀(升序) n个数字来排队:两两相比小靠前:外层循环n-1:内层循环n-i-1. 示例:定义一个数组,用冒泡排序将数组进行升序排序 关键代码: 输出结果: 2.Arrays 类 ...
- Babylon.js 入门简介和开发实例
Babylon.js是一款WebGL开发框架,和Three.js类似. Three.js是由社区推动的,比Babylon.js要成熟些,而Babylon.js是微软推动的,和微软的相关技术结合更好. ...