连表操作join 子查询 SQL补充 数据库软件navicat pymysql模块
多表查询的两种方法
方式1:连表操作
语法:
select * from (表1) inner\right\left\union join (表2) on (拼接条件)
inner join 内连接
select * from emp inner join dep on emp.dep_id=dep.id;
只连接两张表中公有的数据部分
left join 左连接
select * from emp left join dep on emp.dep_id=dep.id;
以左表为基准 展示左表所有的数据 如果没有对应项则用NULL填充
right join 右连接
select * from emp right join dep on emp.dep_id=dep.id;
以右表为基准 展示右表所有的数据 如果没有对应项则用NULL填充
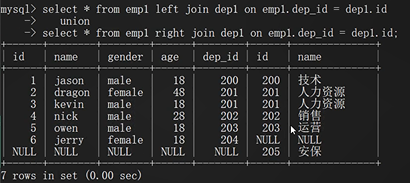
union 全连接
select * from emp left join dep on emp.dep_id=dep.id
union
select * from emp right join dep on emp.dep_id=dep.id;
以左右表为基准 展示所有的数据 各自没有的全部NULL填充
'''
学会了连表操作之后也就可以连接N多张表
思路:将拼接之后的表起别名当成一张表再去与其他表拼接 再起别名当一张表 再去与其他表拼接 其次往复即可
'''
准备拼接的表:
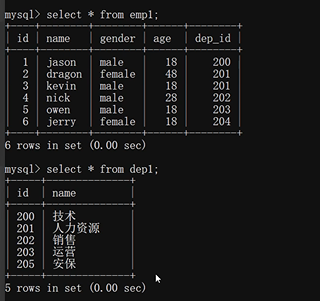
内连接:
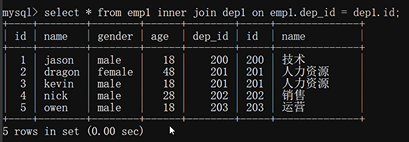
只有进行链接的两个标准,都存在与连接标准相匹配的数据才会被保留下来。emp1.dep_id和dep1.id这两列,有数据是重复的。保留这些重复数据(200,201,201,202,203)所在的那一整行,
丢弃每个表独有的:如(emp的dep_id=204这一行,dep1的id=205这一行)。
左连接:
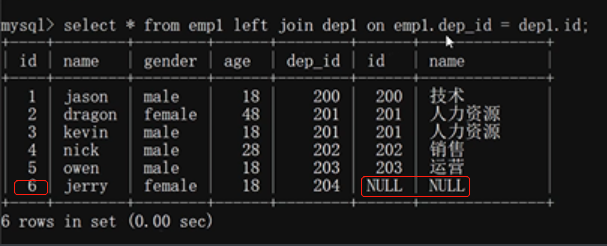
关键字left join左边的emp1为左表,以左表为基准 展示左表所有的数据 右表有数据对应就对应 没有数据对应就写NULL
右连接:
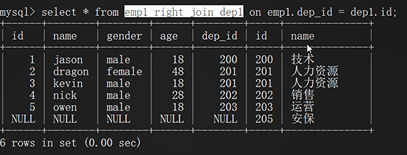
union 全连接:全部展示
方式2:子查询
子查询:将一条SQL语句用括号括起来当成另外一条SQL语句的查询条件
题目:求姓名是jason的员工部门名称
子查询类似于我们日常生活中解决问题的方式>>>:分步操作
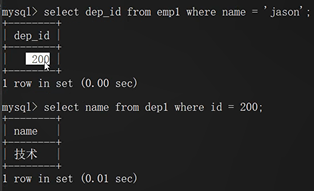
步骤1:先根据jason获取部门编号
select dep_id from emp where name='jason';
步骤2:再根据部门编号获取部门名称
select name from dep where id=200;
总结
select name from dep where id=(select dep_id from emp where name='jason');
'''
很多时候多表查询需要结合实际情况判断用哪种 更多时候甚至是相互配合使用
'''
通过第一条查询获取到dep_id=200:
将第一条语句作为第二条语句的查询条件:

SQL补充知识点
1.分组之前字段拼接 concat concat_ws
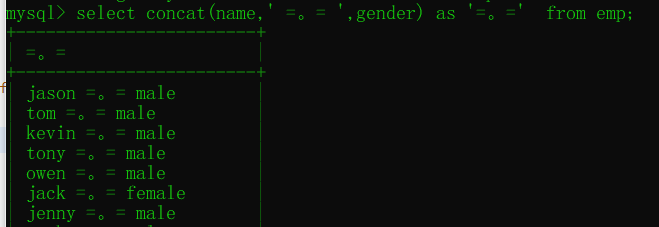
concat用于分组之前的字段拼接操作
select concat(name,'$',gender) from emp;
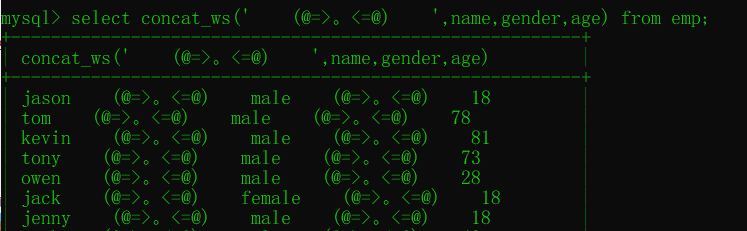
concat_ws拼接多个字段并且中间的连接符一致 concat偷懒版本
select concat_ws('|',name,gender,age,dep_id) from emp;
concat使用:
concat_ws使用:
2.SQL执行判断条件 exists
语法:sql1 exists sql2
sql2有结果的情况下才会执行sql1 否则不执行sql1 返回空数据

exists前面的语句是否执行 取决于后面的sql语句是否有结果
如果有结果就执行 前面这个sql语句 没有结果就不执行前面这个sql语句
相当于exist括号里面装的是一个判断条件 根据这个来决定前面的sql是否执行
3.表相关SQL补充
原表:
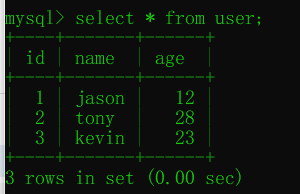
修改表名 alter table ... rename ...
alter table 表名 rename 新表名; # 修改表名
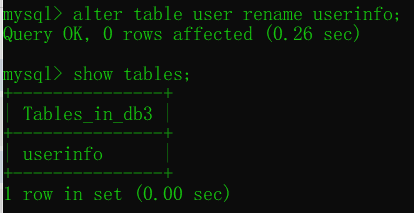
添加字段 alter table ... add ... after/first
alter table 表名 add 字段名 字段类型(数字) 约束条件; # 添加字段

alter table 表名 add 字段名 字段类型(数字) 约束条件 after 已有字段;
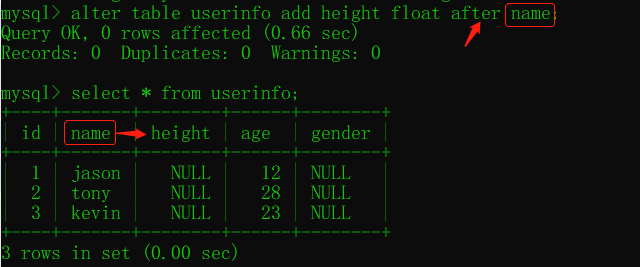
alter table 表名 add 字段名 字段类型(数字) 约束条件 first;
修改字段名 alter table ... change/modify
alter table 表名 change 旧字段名 新字段名 字段类型(数字) 约束条件;
alter table 表名 modify 字段名 新字段类型(数字) 约束条件;
删除字段名 alter table ... drop
alter table 表名 drop 字段名; # 删除字段
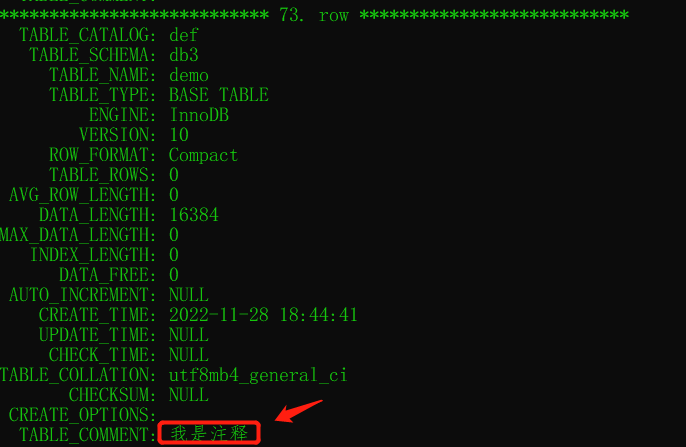
给表添加注释 commit
可以给表添加注释:
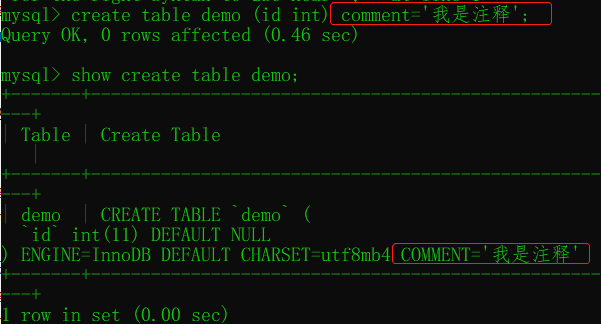
注释有两个查看位置:
- 使用代码
show create table 表名 - 去数据库information_schema里面查看。
information_schema这是个临时库,存储数据在内存。use一下这个库,然后查询:
select * from tables \G可以在众多结果找到我们刚刚创建的表:
可视化软件navicat
第三方开发的用来充当数据库客户端的简单快捷的操作界面
无论第三方软件有多么的花里胡哨 底层的本质还是SQL
能够操作数据库的第三方可视化软件有很多 其中针对MySQL最出名的就是Navicat
1.浏览器搜索Navicat直接下载
版本很多、能够充当的数据库客户端也很多
2.破解方式
先试用在破解、直接下载破解版(老版本)、修改试用日期
3.常用操作
有些功能可能需要自己修改SQL预览
创建库、表、记录、外键
逆向数据库到模型、模型创建(通过画图的形式创表)
新建查询可以编写SQL语句并自带提示功能
SQL语句注释语法
--、#、\**\
运行、转储SQL文件
美化SQL 相当于pycharm格式化代码
建立连接
- 链接服务端
- 填写信息
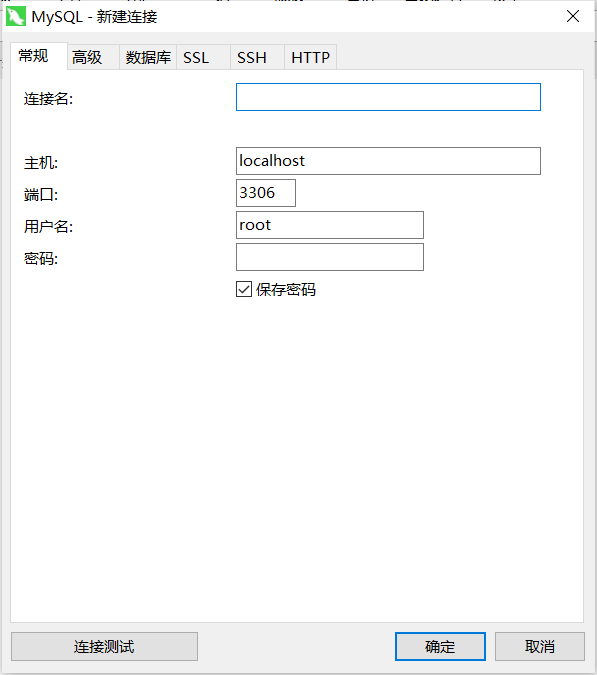
这里的主机指的是mysql服务端,mysql运行在本地就填localhost,在公网就填公网ip。
先点击测试连接,再点击确定。
转储和运行SQL文件
Navicat可以将自己的数据库打包成SQL文件,给别人使用。也可以运行别人打包的SQL文件,获取别人的数据库全部信息。
转储生成sql文件:
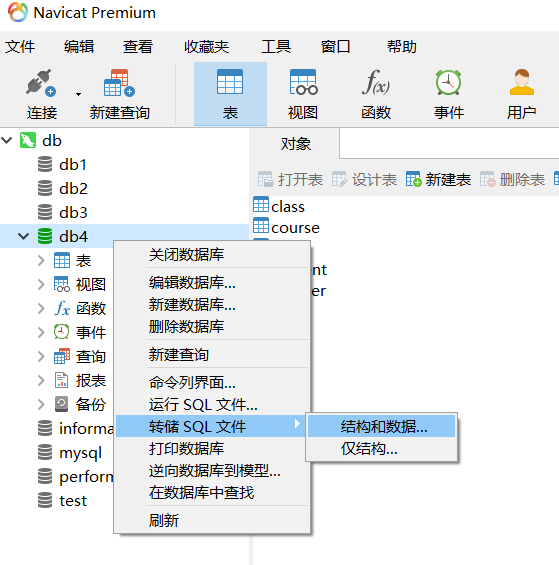
运行sql文件:
- 首先需要先新建一个数据库或者打开一个数据库(重要)
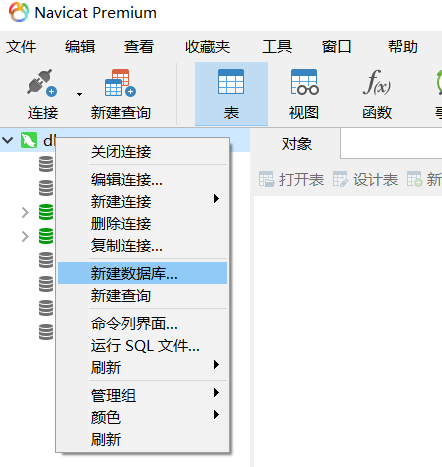
- 右键数据库,点击运行SQL文件:
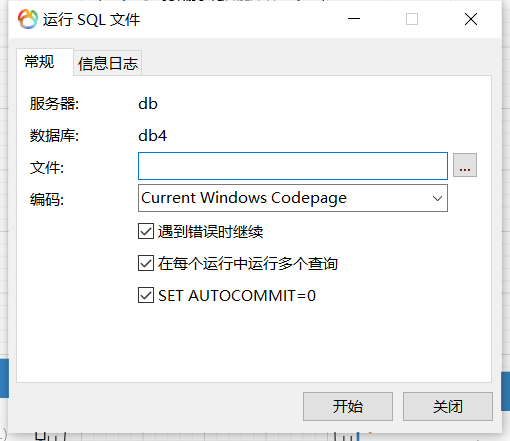
选择要运行的SQL文件即可
添加外键的注意事项
先创建被外键关联的表,给被关联的表录入数据。
再创建有外键的表,先创建外键字段,保存表:
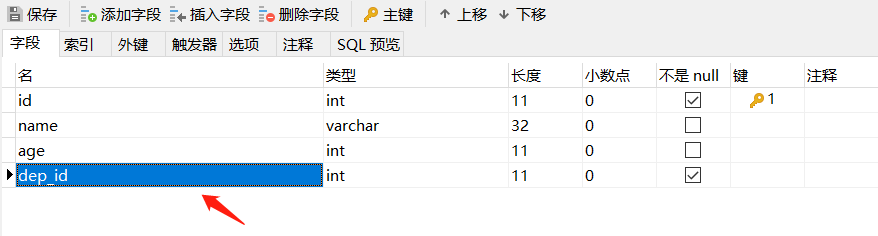
再将创建的外键进行绑定
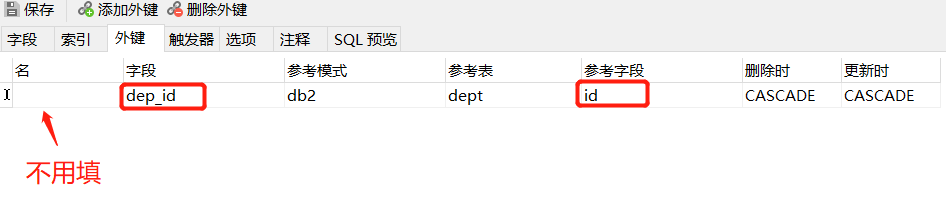
这里有个坑就是:
添加外键的时候 要注意 自己表外键的数据类型 和参考的目标表的字段数据类型要相同
不然会报错error: cannot add foreign key constraint
创建好了就保存可以按快捷键ctrl+s创建好的外键

补充: 创键一对一外键时 可以修改SQL语句
1.比如给userinfo添加对于user_msg的外键

2.还是先创建字段

3.添加外键
无法修改SQL 如何添加一对一外键?
多表查询练习题
"""
编写复杂的SQL不要想着一口气写完
一定要先明确思路 然后一步步写一步步查一步步补
"""
1、查询所有的课程的名称以及对应的任课老师姓名
4、查询平均成绩大于八十分的同学的姓名和平均成绩
7、查询没有报李平老师课的学生姓名
8、查询没有同时选修物理课程和体育课程的学生姓名
9、查询挂科超过两门(包括两门)的学生姓名和班级
-- 1、查询所有的课程的名称以及对应的任课老师姓名
# 1.先确定需要用到几张表 课程表 分数表
# 2.预览表中的数据 做到心中有数
-- select * from course;
-- select * from teacher;
# 3.确定多表查询的思路 连表 子查询 混合操作
-- SELECT
-- teacher.tname,
-- course.cname
-- FROM
-- course
-- INNER JOIN teacher ON course.teacher_id = teacher.tid;
-- 4、查询平均成绩大于八十分的同学的姓名和平均成绩
# 1.先确定需要用到几张表 学生表 分数表
# 2.预览表中的数据
-- select * from student;
-- select * from score;
# 3.根据已知条件80分 选择切入点 分数表
# 求每个学生的平均成绩 按照student_id分组 然后avg求num即可
-- select student_id,avg(num) as avg_num from score group by student_id having avg_num>80;
# 4.确定最终的结果需要几张表 需要两张表 采用连表更加合适
-- SELECT
-- student.sname,
-- t1.avg_num
-- FROM
-- student
-- INNER JOIN (
-- SELECT
-- student_id,
-- avg(num) AS avg_num
-- FROM
-- score
-- GROUP BY
-- student_id
-- HAVING
-- avg_num > 80
-- ) AS t1 ON student.sid = t1.student_id;
-- 7、查询没有报李平老师课的学生姓名
# 1.先确定需要用到几张表 老师表 课程表 分数表 学生表
# 2.预览每张表的数据
# 3.确定思路 思路1:正向筛选 思路2:筛选所有报了李平老师课程的学生id 然后取反即可
# 步骤1 先获取李平老师教授的课程id
-- select tid from teacher where tname = '李平老师';
-- select cid from course where teacher_id = (select tid from teacher where tname = '李平老师');
# 步骤2 根据课程id筛选出所有报了李平老师的学生id
-- select distinct student_id from score where course_id in (select cid from course where teacher_id = (select tid from teacher where tname = '李平老师'))
# 步骤3 根据学生id去学生表中取反获取学生姓名
-- SELECT
-- sname
-- FROM
-- student
-- WHERE
-- sid NOT IN (
-- SELECT DISTINCT
-- student_id
-- FROM
-- score
-- WHERE
-- course_id IN (
-- SELECT
-- cid
-- FROM
-- course
-- WHERE
-- teacher_id = (
-- SELECT
-- tid
-- FROM
-- teacher
-- WHERE
-- tname = '李平老师'
-- )
-- )
-- )
-- 8、查询没有同时选修物理课程和体育课程的学生姓名(报了两门或者一门不报的都不算)
# 1.先确定需要的表 学生表 分数表 课程表
# 2.预览表数据
# 3.根据给出的条件确定起手的表
# 4.根据物理和体育筛选课程id
-- select cid from course where cname in ('物理','体育');
# 5.根据课程id筛选出所有跟物理 体育相关的学生id
-- select * from score where course_id in (select cid from course where cname in ('物理','体育'))
# 6.统计每个学生报了的课程数 筛选出等于1的
-- select student_id from score where course_id in (select cid from course where cname in ('物理','体育'))
-- group by student_id
-- having count(course_id) = 1;
# 7.子查询获取学生姓名即可
-- SELECT
-- sname
-- FROM
-- student
-- WHERE
-- sid IN (
-- SELECT
-- student_id
-- FROM
-- score
-- WHERE
-- course_id IN (
-- SELECT
-- cid
-- FROM
-- course
-- WHERE
-- cname IN ('物理', '体育')
-- )
-- GROUP BY
-- student_id
-- HAVING
-- count(course_id) = 1
-- )
-- 9、查询挂科超过两门(包括两门)的学生姓名和班级
# 1.先确定涉及到的表 分数表 学生表 班级表
# 2.预览表数据
-- select * from class
# 3.根据条件确定以分数表作为起手条件
# 步骤1 先筛选掉大于60的数据
-- select * from score where num < 60;
# 步骤2 统计每个学生挂科的次数
-- select student_id,count(course_id) from score where num < 60 group by student_id;
# 步骤3 筛选次数大于等于2的数据
-- select student_id from score where num < 60 group by student_id having count(course_id) >= 2;
# 步骤4 连接班级表与学生表 然后基于学生id筛选即可
SELECT
student.sname,
class.caption
FROM
student
INNER JOIN class ON student.class_id = class.cid
WHERE
student.sid IN (
SELECT
student_id
FROM
score
WHERE
num < 60
GROUP BY
student_id
HAVING
count(course_id) >= 2
);
SQL文件:
链接:https://pan.baidu.com/s/1LUu3U8VHc4oxT58zhJyfRg
提取码:pur1
pymysql模块
基本使用 cursor=pymysql.cursors.DictCursor
pymysql模块
pip3 install pymysql
import pymysql
# 1.连接MySQL服务端
db = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123',
db='db4_03',
charset='utf8mb4'
)
# 2.产生游标对象
# cursor = db.cursor() # 括号内不填写额外参数 数据是元组 指定性不强 [(),()]
cursor = db.cursor(cursor=pymysql.cursors.DictCursor) # [{},{}]
# 3.编写SQL语句
# sql = 'select * from teacher;'
sql = 'select * from score;'
# 4.发送SQL语句
affect_rows = cursor.execute(sql) # execute也有返回值 接收的是SQL语句影响的行数
print(affect_rows)
# 5.获取SQL语句执行之后的结果
res = cursor.fetchall()
print(res)
获取数据 fetchall
fetchall() 获取所有的结果
fetchone() 一次读一个数据,每次都基于上次的位置往后面读。
fetchmany() 获取指定数量的结果集数据
ps:注意三者都有类似于文件光标移动的特性
读取结果集可以类比读取文件 光标读取到末尾了 再继续读就没有内容了 所以多次使用fetchall 第二次及以后都获取的是空。
fetchall:
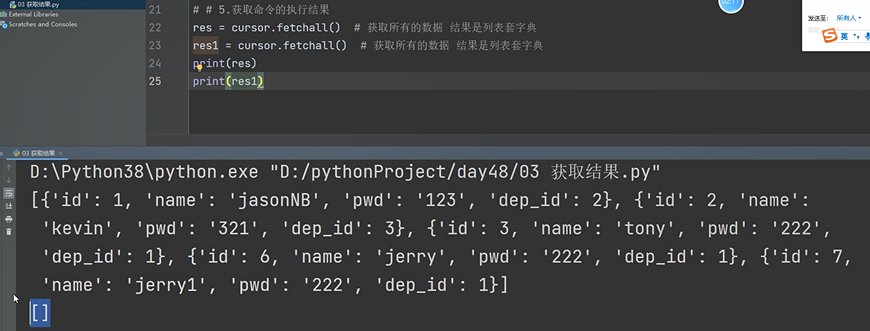
fetchone:

移动光标 scroll
cursor.scroll(1,'relative') # 基于当前位置往后移动1位
cursor.scroll(1,'absolute') # 基于数据的开头往后移动一位
注意这个输入的数字 是要≥0的。
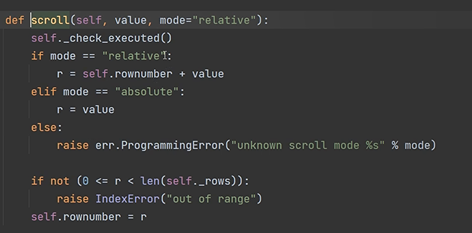
≥0的
增删改二次确认 commit autocommit=True
在pymysql.connect里添加autocommit=True
# 可以针对增 删 改的操作 进行自动确认(无需写代码二次确认)
db.commit() # 针对 增 删 改 需要二次确认(代码确认)
补充方法 rowcount rollback executemany
对于光标对象:
cursor.rowcount # 用于获取查询结果的条数
对于connect方法产生的db对象:
rollback # 数据回滚 用于增删改出错的情况 将数据库状态回复到commit之前 相当于什么事都没发生
executemany(sql,[(),(),(),()...]) # 用于执行多条sql数据
有好多条数据 sql 要插入时,使用cursor.executemany,对于数据列表[( ),( )]每个元祖都是一条数据:
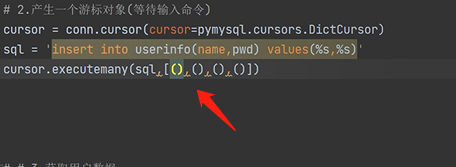
一次性执行多条sql语句:

确保数据的一致性
插入一条数据,要么全部插入要么都不插入,不会出现插入一半的情况,这称之为事务的原子性。
增删改都是对数据库进行更改的操作,而更改操作都必须是一个事务,所以这些操作的标准写法是:
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()
引入动态字典生成SQL语句
添加字段的时候需要修改我们构建的SQL语句,这不是我们想要的。所以引入字典动态生成SQL:
import pymysql
db = pymysql.connect(host='localhost',
port=3306,
user='root',
passwd='123',
db='db1', # can be changed
charset='utf8mb4', # default
autocommit=True, # set to True
)
cursor = db.cursor(cursor=pymysql.cursors.DictCursor)
# dict
data = {
'id': '2200320',
'name': 'John Doe',
'age': '12',
}
table = 'students'
keys = ','.join(data.keys()) # create a str like 'id,name,age'
values = ','.join(['%s'] * len(data)) # make format symbols like '%s,%s,%s'
sql = 'INSERT INTO {table} ({keys}) VALUES ({values})'.format(table=table, keys=keys, values=values)
print(sql) # INSERT INTO students (id,name,age) VALUES (%s,%s,%s)
try:
if cursor.execute(sql,tuples=(data.values())):
print('Success')
db.commit()
except Exception:
print('Error')
db.rollback()
db.close()
更新数据时的主键配置 ON DUPLICATE KEY UPDATA
在某些应用情境下,我们关心表中会不会出现重复数据,如果出现了,我们希望更新数据而不是重复保存一次。我们需要实现:如果数据存在,就更新数据;如果数据不存在,则插入数据。
可以给插入语句添加约束条件:ON DUPLICATE KEY UPDATA 意思是如果主键已经存在,就执行更新操作。
完整的SQL写法:INSERT INTO stundent(id,name,age) VALUES(%s,%s,%s) ON DUPLICATE KEY UPDATA id = %s,name = %s, age = %s 注意这里%s是占位符,可以通过execute第二个参数给他传进去。这样写即可实现主键不存在便插入数据,主键存在则更新数据。
while循环 + fetchone
fetchall方法全部获取数据,如果数据量很大,那么占用的开销也会非常高
所以可以使用:
sql = 'SELECT * FROM students WHERE age >= 20'
try:
cursor.execute(sql)
print('count:',cursor.rowcount)
row = cursor.fetchone()
while row:
print('row:',row)
row = cursor.fetchone()
excpet:
print('error')
SQL注入 execute
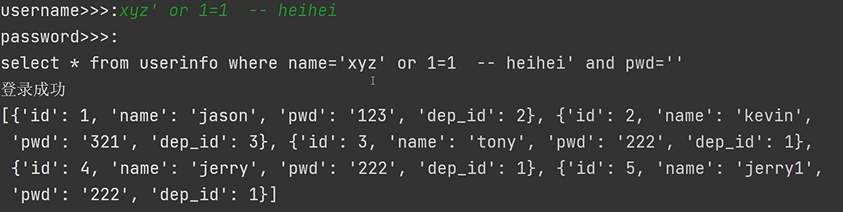
现象1:输对用户名就可以登录成功
现象2:不需要对的用户名和密码也可以登录成功
SQL注入:利用特殊符合的组合产生特殊的含义 从而避开正常的业务逻辑
select * from userinfo where name='jason' -- kasdjksajd' and pwd=''
select * from userinfo where name='xyz' or 1=1 -- aksdjasldj' and pwd=''
解决的措施:1.禁止用户输入 2.用正则把特殊符号去掉 3.pymysql自带工具自动过滤
针对上述的SQL注入问题 核心在于手动拼接了关键数据 交给execute处理即可
sql = " select * from userinfo where name=%s and pwd=%s "
cursor.execute(sql, (username, password))
实例:
练习
SQL练习题
1、查询所有的课程的名称以及对应的任课老师姓名
SELECT
cname,
tname
FROM
course
INNER JOIN teacher ON course.teacher_id = teacher.tid;
2、查询学生表中男女生各有多少人
SELECT gender,count(gender) FROM student GROUP BY gender
3、查询物理成绩等于100的学生的姓名
SELECT
sname,
num
FROM
( SELECT student_id, num FROM score INNER JOIN course ON course.cid = score.course_id WHERE cname = '物理' AND num = 100 ) AS std_id
INNER JOIN student ON std_id.student_id = student.sid
4、查询平均成绩大于八十分的同学的姓名和平均成绩
-- SELECT * FROM score WHERE num>=80
-- 拼学生名字
-- SELECT * FROM student INNER JOIN score ON score.student_id=student.sid WHERE num>=80
-- 按学生分组
SELECT
sname,
avg( num )
FROM
student
INNER JOIN score ON score.student_id = student.sid
WHERE
num >= 80
GROUP BY
student_id
5、查询所有学生的学号,姓名,选课数,总成绩
SELECT
student_id,
sname,
count( course_id ),
avg( num )
FROM
student
INNER JOIN score ON student.sid = score.student_id
GROUP BY
sname
6、 查询姓李老师的个数
SELECT * FROM teacher WHERE tname like '%李%'
7、 查询没有报李平老师课的学生姓名
8、 查询物理课程比生物课程高的学生的学号
SELECT
wl.student_id
FROM
( SELECT * FROM score WHERE course_id = 1 ) AS sw
INNER JOIN ( SELECT * FROM score WHERE course_id = 2 ) AS wl ON sw.student_id = wl.student_id
WHERE
wl.num > sw.num
9、 查询没有同时选修物理课程和体育课程的学生姓名
SELECT
student_id
FROM
score
INNER JOIN course ON score.course_id = course.cid
WHERE
cname = '物理'
OR cname = '体育'
GROUP BY
student_id
HAVING
count( course_id ) = 1
10、查询挂科超过两门(包括两门)的学生姓名和班级
、查询选修了所有课程的学生姓名
12、查询李平老师教的课程的所有成绩记录
SELECT num FROM score WHERE course_id in (2,4) #坑
13、查询全部学生都选修了的课程号和课程名
SELECT GROUP_CONCAT(student_id) FROM score GROUP BY course_id
14、查询每门课程被选修的次数
SELECT course_id,count(student_id) FROM score GROUP BY course_id
15、查询之选修了一门课程的学生姓名和学号
SELECT student_id,count(course_id) as one FROM score GROUP BY student_id HAVING one = 1
16、查询所有学生考出的成绩并按从高到低排序(成绩去重)
SELECT * FROM score ORDER BY num desc
17、查询平均成绩大于85的学生姓名和平均成绩
18、查询生物成绩不及格的学生姓名和对应生物分数
19、查询在所有选修了李平老师课程的学生中,这些课程(李平老师的课程,不是所有课程)平均成绩最高的学生姓名
20、查询每门课程成绩最好的前两名学生姓名
21、查询不同课程但成绩相同的学号,课程号,成绩
22、查询没学过“叶平”老师课程的学生姓名以及选修的课程名称;
23、查询所有选修了学号为1的同学选修过的一门或者多门课程的同学学号和姓名;
24、任课最多的老师中学生单科成绩最高的学生姓名
基于pymysql用户注册登录
# user rigister and login application use pymysql instead
import pymysql
db = pymysql.connect(host='localhost',
port=3306,
user='root',
passwd='123',
db='db1', # can be changed
charset='utf8mb4', # default
autocommit=True, # set to True
)
# 1.create cursor object
cursor = db.cursor(cursor=pymysql.cursors.DictCursor) # add cursor configuration
# 2. get user data
user_name = input('Enter user name>>>').strip()
pass_word = input('Enter password>>>').strip()
# 3.write SQL statement
sql = "select * from userinfo where name='%s' and pwd='%s'" # action to '%s' don't forget --> ''
# solved problem: pymysql.err.OperationalError: (1054, "Unknown column 'jason' in 'where clause'")
print(sql)
# 4.execute SQL statemen
cursor.execute(sql,(user_name, pass_word)) # execute function can solved SQL injection
# 5.get result
result = cursor.fetchall()
# 6.rigister result
if result:
print('welcome!')
print(result)
else:
print('username or password is incorrect')
# 7.sql injection problem
# real sql = select * from userinfo where name='jason' -- kdwokodwdkoa' and pwd='123'
连表操作join 子查询 SQL补充 数据库软件navicat pymysql模块的更多相关文章
- ylb:SQL 表的高级查询-多表连接和子查询
ylbtech-SQL Server: SQL Server-表的高级查询-多表连接和子查询 SQL Server 表的高级查询-多表连接和子查询. 1,ylb:表的高级查询-多表连接和子查询 返回顶 ...
- MS sql server 基础知识回顾(二)-表连接和子查询
五.表连接 当数据表中存在许多重复的冗余信息时,就要考虑将这些信息建在另一张新表中,在新表中为原表设置好外键,在进行数据查询的时候,就要使用到连接了,表连接就好像两根线,线的两端分别连接两张表的不同字 ...
- MySQL多表查询之外键、表连接、子查询、索引
MySQL多表查询之外键.表连接.子查询.索引 一.外键: 1.什么是外键 2.外键语法 3.外键的条件 4.添加外键 5.删除外键 1.什么是外键: 主键:是唯一标识一条记录,不能有重复的,不允许为 ...
- MySQL开发——【联合查询、多表连接、子查询】
联合查询 所谓的联合查询就是将满足条件的结果进行拼接在同一张表中. 基本语法: select */字段 from 数据表1 union [all | distinct] select */字段 fro ...
- 分页用到的子查询sql语句
说明(2017-8-31 23:30:22): 1. 分页用到的子查询sql语句 select * from(select *,ROW_NUMBER() over(order by id)as num ...
- 在论坛中出现的比较难的sql问题:32(row_number函数+子查询 sql循环取差值)
原文:在论坛中出现的比较难的sql问题:32(row_number函数+子查询 sql循环取差值) 所以,觉得有必要记录下来,这样以后再次碰到这类问题,也能从中获取解答的思路. sql循环取差值,该怎 ...
- mysql之子查询、视图、事务及pymysql等
数据准备 CREATE TABLE `emp` ( `id` int(0) NOT NULL AUTO_INCREMENT, `name` varchar(10) NOT NULL, `gender` ...
- 查询Sql Server数据库对象结构
查询Sql Server数据库对象结构 查询数据库 查询架构 查询表 查询列 查询存储过程 查询视图 1.查询某一服务器下所有数据库 select t.[name] as 数据库 from sys.d ...
- 读《程序员的SQL金典》[3]--表连接、子查询
一.表连接-JOIN 1. 自连接实例 查询类型相同的订单信息. SELECT O1 .*,O2.* FROM T_Order O1 JOIN T_Order O2 ON O1 .FTypeId= O ...
- MySQL数据库学习笔记(六)----MySQL多表查询之外键、表连接、子查询、索引
本章主要内容: 一.外键 二.表连接 三.子查询 四.索引 一.外键: 1.什么是外键 2.外键语法 3.外键的条件 4.添加外键 5.删除外键 1.什么是外键: 主键:是唯一标识一条记录,不能有重复 ...
随机推荐
- 《深入理解Elasticsearch》读书笔记 ---重点概念汇总
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247483918&idx=1&sn=a9f2ad3 ...
- Wine 安装迅雷5.8.14.176
测试过的系统版本:Kubuntu 22.04 测试过的Wine版本 Wine7.8 程序下载地址: https://pan.baidu.com/s/1pSgunVH3WtACssX5we3DdQ 提取 ...
- 微信小程序实现与登录
一.小程序的实现原理 在小程序中,渲染层和逻辑层是分开的,双线程同时运行,渲染层和逻辑层这两个通信主体之间的通讯以及通讯主体与第三方服务器之间的通信,都是通过微信客户端进行转发.小程序启动运行两种情况 ...
- PHP全栈开发(八):CSS Ⅰ 选择器
直到目前为止,我们把从HTML中的数据是如何通过PHP到服务器端,然后又通过PHP到数据库,然后从数据库中出来,通过PHP到HTML的整个过程通过一个案例过了一遍. 可以说,这些才刚刚开始.下面我们开 ...
- 手把手教你玩转 Gitea|在 Windows 系统上安装 Gitea
Gitea 支持在 Windows 系统上安装和使用.Gitea 本身作为一个单体应用程序,即点即用,如需长期驻留作为后台服务并开机运行就要依靠 Windows 服务工具 sc.exe. 通过本文,你 ...
- 分布式存储系统之Ceph集群MDS扩展
前文我们了解了cephfs使用相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/16758866.html:今天我们来聊一聊MDS组件扩展相关话题: 我们 ...
- struts2 标签总结
<s:if>判断字符串的问题: 1.判断单个字符:<s:if test="#session.user.username=='c'"> 这样是从session ...
- 【C++】GoogleTest进阶之gMock
gMock是什么 当我们去写测试时,有些测试对象很单纯简单,例如一个函数完全不依赖于其他的对象,那么就只需要验证其输入输出是否符合预期即可. 但是如果测试对象很复杂或者依赖于其他的对象呢?例如一个函数 ...
- GO编译时不避免引入外部动态库的解决方法
简介 最近碰到一个问题,有一个流量采集的组件中使用到了github.com/google/gopacket 这个库,这个库使用一切正常,但是唯独有一个缺点,编译后的二进制文件依赖于libpcap.so ...
- 2022年整理最详细的java面试题、掌握这一套八股文、面试基础不成问题[吐血整理、纯手撸]
这里是参考B站上的大佬做的面试题笔记.大家也可以去看视频讲解!!! 文章目录 1.面向对象 2.JDK.JRE.JVM区别和联系 3.==和equals 4.final 5.String .Strin ...