4.10:Spark之wordcount
〇、概述
1、拓扑结构
2、目标
使用spark完成计数实验
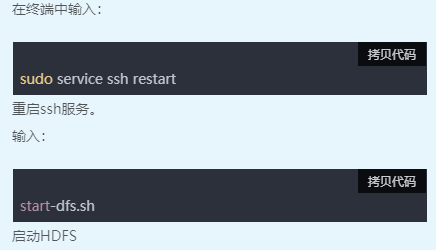
一、启动环境
二、新建数据文件

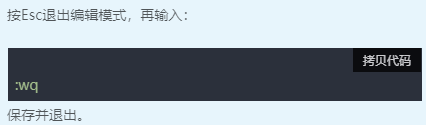
三、查看文件内容

四、启动spark服务
五、编写代码
复制以下代码到shell中(复制后在终端右键->粘贴):
import org.apache.spark.HashPartitioner
import java.io.PrintWriter
import java.io.File val links = sc.parallelize(List(("A",List("B","C")),("B",List("A","C")),("C",List("A","B","D")),("D",List("C")))).partitionBy(new HashPartitioner(100)).persist() var ranks=links.mapValues(v=>1.0) for (i <- 0 until 10) {
val contributions=links.join(ranks).flatMap {
case (pageId,(links,rank)) => links.map(dest=>(dest,rank/links.size))
}
ranks=contributions.reduceByKey((x,y)=>x+y).mapValues(v=>0.15+0.85*v)
} ranks.sortByKey().collect() var input = sc.textFile("hdfs://localhost:9000/wordcount/srcdata/article.data")
val writer = new PrintWriter(new File("/home/user/bigdata/spark_output.txt"))
writer.println(input.flatMap(x=>x.split(" ")).countByValue())
writer.close()
input.flatMap(x=>x.split(" ")).countByValue()
之后可以查看输出结果。

4.10:Spark之wordcount的更多相关文章
- [转] 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? [sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需 ...
- Spark版wordcount,并根据词频进行排序
import org.apache.spark.{SparkConf, SparkContext}/** * Created by loushsh on 2017/10/9. */object Wor ...
- 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需要 ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- 1.spark的wordcount解析
一.Eclipse(scala IDE)开发local和cluster (一). 配置开发环境 要在本地安装好java和scala. 由于spark1.6需要scala 2.10.X版本的.推荐 2 ...
- Spark 实现wordcount
配置完spark之后,使用spark实现wordcount,这一部分完全参考<深入理解Spark:核心思想与源码分析> 依然使用hadoop wordcountTest的那几个txt文件 ...
- spark 例子wordcount topk
spark 例子wordcount topk 例子描述: [单词计算wordcount ] [词频排序topk] 单词计算在代码方便很简单,基本大体就三个步骤 拆分字符串 以需要进行记数的单位为K,自 ...
- .Net for Spark 实现 WordCount 应用及调试入坑详解
.Net for Spark 实现WordCount应用及调试入坑详解 1. 概述 iNeuOS云端操作系统现在具备物联网.视图业务建模.机器学习的功能,但是缺少一个计算平台产品.最近在调研使用 ...
- 在IDEA中编写Spark的WordCount程序
1:spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包 ...
- spark学习之IDEA配置spark并wordcount提交集群
这篇文章包括以下内容 (1)IDEA中scala的安装 (2)hdfs简单的使用,没有写它的部署 (3) 使用scala编写简单的wordcount,输入文件和输出文件使用参数传递 (4)IDEA打包 ...
随机推荐
- SQL注入篇——sqli-labs各关卡方法介绍
主要是记下来了每关通过可以采用的注入方式,可能部分关卡的通关方式写的不全面,欢迎指出,具体的获取数据库信息请手动操作一下. 环境初始界面如下: sql注入流程语句: order by 3--+ #判断 ...
- CentOS使用yum方式安装yarn和nodejs
# 使用epel-release.repo源安装的nodejs版本是6.17.1,有些前端项目使用的话会提示版本太低,具体下图 # 命令执行后的详细情况:curl -sL https://rpm.no ...
- 5.使用nexus3配置npm私有仓库
当我们运行前端项目的时候,常常在解决依赖的时候会加上一个参数npm install --registry=https://registry.npm.taobao.org将源指定为淘宝的源,以期让速度加 ...
- 使用 kubectl 执行 Rolling Update(滚动更新)
Rolling Update滚动更新 通过使用新版本的 Pod 逐步替代旧版本的 Pod 来实现 Deployment 的更新,从而实现零停机.新的 Pod 将在具有可用资源的 Node(节点)上进行 ...
- Qt+ECharts开发笔记(五):ECharts的动态排序柱状图介绍、基础使用和Qt封装Demo
前言 上一篇的demo使用隐藏js代码的方式,实现了一个饼图的基本交互方式,并预留了Qt模块对外的基础接口. 本篇的demo实现了自动排序的柱状图,实现了一个自动排序柱状图的基本交互方式,即Qt ...
- P3402 可持久化并查集
P3402 通过主席树维护不同版本的并查集,注意要采用按秩合并的方式,路径压缩可能会爆. 1 #include <bits/stdc++.h> 2 using namespace std; ...
- IDEA中直接将 SpringBoot项目打包成 Docker镜像时 pom.xml的配置
<plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactI ...
- day10-习题
习题 1.Homework01 (1) D -- 没有在别名上加引号(ps:别名的as可以省略) (2) B -- 判断null或非空不能用不等于号 (3) C 2.Homework02 写出查看de ...
- ciscn 2022 misc 部分wp
目录 everlasting_night ez_usb everlasting_night 提示是注意png数据块 然后注意图片通道数据可以用来lsb解码 下载是一张图片,尝试几种方法之后没有太大 ...
- sql面试50题------(21-30)
文章目录 21.查询不同老师所教不同课程平均分从高到低显示 23.使用分段[100,85),[85,70),[70,60),[<60] 来统计各科成绩,分别统计各分数段人数:课程ID和课程名称 ...