【大数据面试】【框架】Flume:Source的断点续传、重复数据、Channel选择
〇、用途
流式结构
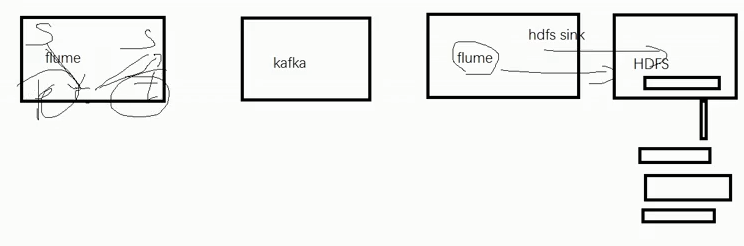
获取磁盘日志,拦截器过滤后,传递指定数据,写入HDFS或kafka
一、组成-Source、Channel、Sink
事务(put/take)
1、Source---taildir source:
(1)特点:断点续传+多目录(维护offset)
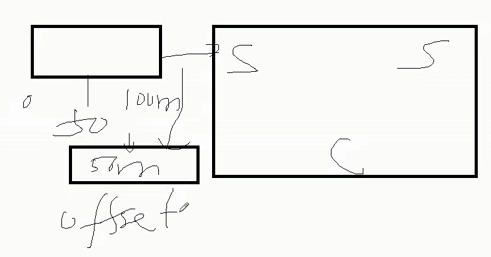
产生自哪个版本-Apache Flume1.7,CDH 1.6
(2)没有断点续传功能时如何使用?自定义方式实现
(3)taildir挂掉怎么办,是否有影响
首先不会丢数(断点续传),但是会产生重复数据(一条或一批次)
读取成功,写入失败
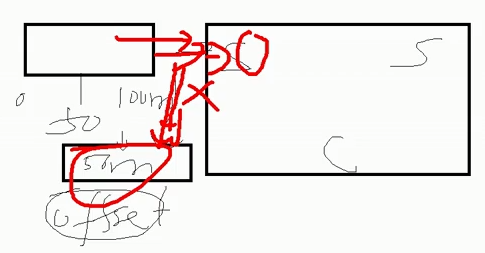
(4)怎么处理重复数据?
生产环境下通常不处理,处理方案
自身:可以在taildir source内部增加自定义事务
找兄弟:下一级处理(sparkStreaming、hive、dwd、flink过滤器),手段(group by去重、开窗取窗口最小,只取第一条、Redis集群帮助去重)
(5)taildir source是否支持递归遍历文件夹读取文件?
不支持,需要自定义
递归遍历文件夹+读取文件
2、Channel
(1)常见的Channel包括哪些及对应的特点
File Channel:数据存储在磁盘上(数据可靠性高、传输速度低),默认存储容量:100w个event
Memory Channel:数据存储于内存(传输速度快、可靠性差),默认容量是100个event
Kafka Channel:数据存储于kafka/基于磁盘(数据可靠性高、传输速度也快【kafka Channel》kafka sink+Memory Channel,原因:省去了sink阶段】),在flume 1.6版本产生(原因:有bug,可以设置前缀是否带topic,但不起作用)
kafka-topic_start/topic_event,增加了额外清洗的工作量,Flume 1.7解决了该问题
(2)生产环境下如何选择
如果下一级是kafka,通常会优先选择kafka channel
如果下一级不是kafka,金融、对钱要求准确的公司,选择File Channel
如果是普通日志,通常会选择memory Channel(JD每天丢失几百万数据,每天都是PB级数据)
3、HDFS sink
不做控制,会直接落盘,产生大量小文件
可以通过参数控制:时间、大小、event的个数【或】
时间:3600-7200s(1小时-2小时)
大小:128M
event的个数(0禁止)
二、三个器(拦截器、选择器、监控器)
1、拦截器
ETL拦截器、分类型拦截器
(1)ETL拦截器
实现:数据轻度清洗(判断是否是大括号开头结尾,为了保证传输效率/实时性)
判断了数据时间:13位,必须全部是数字
(2)分类型拦截器(11张表)
start
event(商品列表、商品详情、商品点击、
广告、
点赞、评论、收藏、故障、
后台活跃、通知)
哪张表与kafka有关系,要满足所有下一级消费者
创建成特定类,不产生重复数据,针对每个表创建一个topic
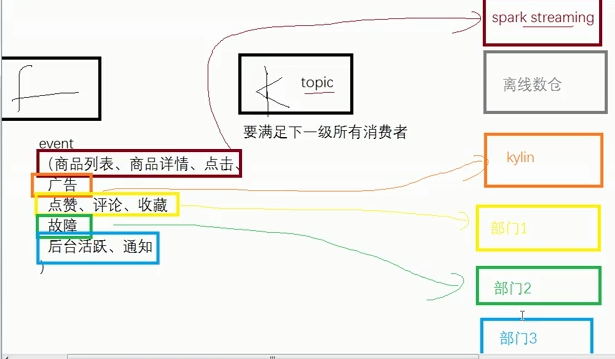
一张表一个topic,一定能满足下一级消费者
为了效率,可以做适当的聚合
(3)自定义拦截器的步骤
定义一个类,实现interceptor接口,重写内部的4个方法:
初始化、关闭、单event、多event、同时创建一个静态内部类Builder
打包==》上传至flume的lib包下==》在配置文件中关联拦截器
(4)可以不使用拦截器吗
可以不用,但需要在下一级hive的DWD层或sparkstreaming里面进行处理
(5)优势和劣势
优势:只处理一次,轻度处理,不会影响太多性能
劣势:影响性能,不适合像推荐这种对实时性要求比较高的场景
三、优化
1、File Channel可以配置多目录-多个磁盘
可以提高吞吐量
2、HDFS Sink
解决小文件:时间、大小、event的个数【或】
3、监控器
调整内存
找自己:提高自己内存
找朋友:增加flume台数
4、Flume挂掉后的操作
source挂掉,可能会产生重复数据(offset),使用事务解决
channel挂掉(File、Memory×、Kafka),会丢失100个event
【大数据面试】【框架】Flume:Source的断点续传、重复数据、Channel选择的更多相关文章
- 爬虫数据使用MongDB保存时自动过滤重复数据
本文转载自以下网站: 爬虫断了?一招搞定 MongoDB 重复数据 https://www.makcyun.top/web_scraping_withpython13.html 需要学习的地方: Mo ...
- MySQL中删除重复数据的简单方法,mysql删除重复数据
MYSQL里有五百万数据,但大多是重复的,真实的就180万,于是想怎样把这些重复的数据搞出来,在网上找了一圈,好多是用NOT IN这样的代码,这样效率很低,自己琢磨组合了一下,找到一个高效的处理方式, ...
- 删除一个表中的重复数据同时保留第一次插入那一条以及sql优化
业务:一个表中有很多数据(id为自增主键),在这些数据中有个别数据出现了重复的数据. 目标:需要把这些重复数据删除同时保留第一次插入的那一条数据,还要保持其它的数据不受影响. 解题过程: 第一步:查出 ...
- mysql 存储过程批量删除重复数据
表结构: LOAD DATA INFILE '/usr/local/phone_imsi_12' replace INTO TABLE tbl_imsi2number_new FIELDS TERMI ...
- SQL Server 一列或多列重复数据的查询,删除
业务需求 最近给公司做一个小工具,把某个数据库(数据源)的数据导进另一个数据(目标数据库).要求导入目标数据库的数据不能出现重复.但情况是数据源本身就有重复的数据.所以要先清除数据源数据. 于是就把关 ...
- Mysql中查找并删除重复数据的方法
(一)单个字段 1.查找表中多余的重复记录,根据(question_title)字段来判断 代码如下 复制代码 select * from questions where question_title ...
- php获取数组中重复数据的两种方法
分享下php获取数组中重复数据的两种方法. 1,利用php提供的函数,array_unique和array_diff_assoc来实现 <?php function FetchRepeatMem ...
- SQL Server 一列或多列重复数据的查询,删除(转载)
转载来源:https://www.cnblogs.com/sunxi/p/4572332.html 业务需求 最近给公司做一个小工具,把某个数据库(数据源)的数据导进另一个数据(目标数据库).要求导入 ...
- MongoDB实现数组中重复数据删除
这个功能真的是写死我了,对于MongoDB一点都不熟悉,本来想使用spring与MongoDB的融合mongoDBTemplate,发现压根不是web项目,懒得配置那些配置文件,就使用最原始的数据库操 ...
- mySql数据重复数据去重
1.问题来源:数据中由于并发问题,数据存在多次调用接口,插入了重复数据,需要根据多条件删除重复数据: 2.参考博客文章地址:https://www.cnblogs.com/jiangxiaobo/p/ ...
随机推荐
- MinIO Client完全指南
官方文档地址:http://docs.minio.org.cn/docs/master/minio-client-complete-guide 下载,添加云存储服务参考这篇文章:https://www ...
- Logstash:使用Logstash将电子邮件导入到Elasticsearch
- Redis 监控指标
监控指标 性能指标:Performance 内存指标: Memory 基本活动指标:Basic activity 持久性指标: Persistence 错误指标:Error 性能指标:Performa ...
- LeetCode - 统计数组中的元素
1. 统计数组中元素总结 1.1 统计元素出现的次数 为了统计元素出现的次数,我们肯定需要一个map来记录每个数组以及对应数字出现的频次.这里map的选择比较有讲究: 如果数据的范围有限制,如:只有小 ...
- FEX-EMU Wine踩坑记录
FEX是一个用于在ARM64平台运行X86软件的工具,比较成熟,但是网上资料很少,所以就写了这篇FEX运行Wine踩坑记录. Termux的Fex不能用(2022年5月) 要在debian系统安装fe ...
- 洛谷P1640 SCOI2010 连续攻击游戏 (并查集/匹配)
本题介绍两种做法: 1 并查集 1 #include<bits/stdc++.h> 2 using namespace std; 3 const int N=1000005; 4 int ...
- 洛谷P2827 [NOIP2016 提高组] 蚯蚓 (二叉堆/队列)
容易想到的是用二叉堆来解决,切断一条蚯蚓,其他的都要加上一个值,不妨用一个表示偏移量的delta. 1.取出最大的x,x+=delta: 2.算出切断后的两个新长度,都减去delta和q: 3.del ...
- <三>从编译器角度理解C++代码编译和链接原理
1代码 点击查看代码 **sum.cpp** int gdata=10; int sum(int a,int b){ return a+b; } **main.cpp** extern int gda ...
- SpringBoot (四) - 整合Mybatis,逆向工程,JPA
1.SpringBoot整合MyBatis 1.1 application.yml # 数据源配置 spring: datasource: driver-class-name: com.mysql.c ...
- 一天十道Java面试题----第四天(线程池复用的原理------>spring事务的实现方式原理以及隔离级别)
这里是参考B站上的大佬做的面试题笔记.大家也可以去看视频讲解!!! 文章目录 31.线程池复用的原理 32.spring是什么? 33.对Aop的理解 34.对IOC的理解 35.BeanFactor ...