Python后端基础知识总结
1、所谓可变类型与不可变类型是指:是否可以在不改变原来数据的引用地址基础上,去修改数据。如果能直接修改那么就是可变,否则是不可变
不可变对象:该对象所指向的内存中的值不能被改变。当改变某个变量时候,由于其所指的值不能被改变,相当于把原来的值复制一份后再改变,这会开辟一个新的地址,变量再指向这个新的地址。
可变对象:该对象所指向的内存中的值可以被改变。变量(准确的说是引用)改变后,实际上是其所指的值直接发生改变,并没有发生复制行为,也没有开辟新的地址,通俗点说就是原地改变。
可变类型有: 列表、字典、集合
不可变类型有: 数字、字符串、元组
2、传参顺序:位置参数,元祖不定长参数,缺省参数,字典不定长参数
def sum_nums_3(a, *args, b=22, c=33, **kwargs):
3、linux系统下安装与卸载
离线安装(deb文件格式安装)与卸载:
sudo dpkg -i 安装包名 sudo dpkg –r 安装包名
在线安装(apt-get方式安装)与卸载:
sudo apt-get install 安装包 sudo apt-get remove 安装包名
4、并发与并行
并发:可使用的CPU核心数少于任务数,在一段时间内交替去执行任务。
并行:可使用的cpu核心数大于任务数时,任务同时进行
线程是并发,进程是并行。
5、进程和线程以及协程
多进程模块:multiprocessing 多线程模块:threading
多进程适合CPU密集任务(求π圆周率、科学计算、机器学习、通过大量计算才能接到结果的程序)
多线程适合IO(输入输出)密集型任务(文件操作、数据库操作、网络编程、爬虫程序)
区别对比:
①进程之间不共享全局变量
②线程之间共享全局变量,但是要注意资源竞争的问题,解决办法: 互斥锁或者线程同步
③创建进程的资源开销要比创建线程的资源开销要大
④进程是操作系统资源分配的基本单位,线程是CPU调度的基本单位
⑤线程不能够独立执行,必须依存在进程中
小结:
多进程要比多线程消耗的资源多,但是多进程开发比单进程多线程开发稳定性要强,某个进程挂掉不会影响其它进程。
多进程可以使用cpu的多核运行,多线程可以共享全局变量。
线程不能单独执行必须依附在进程里面
多进程开发比单进程多线程开发稳定性要强
协程:
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
这个问题被问的概率相当之大,其实多线程,多进程,在实际开发中用到的很少,除非是那些对项目性能要求特别高的,有的开发工作几年了,也确实没用过,你可以这么回答,
给他扯扯什么是进程,线程(cpython 中是伪多线程)的概念就行,实在不行你就说你之前写过下载文件时,用过多线程技术,或者业余时间用过多线程写爬虫,提升效率。
进程:一个运行的程序(代码)就是一个进程,没有运行的代码叫程序,进程是系统资源分配的最小单位,进程拥有自己独立的内存空间,所以进程间数据不共享,开销大。
线程: 调度执行的最小单位,也叫执行路径,不能独立存在,依赖进程存在一个进程至少有一个线程,叫主线程,而多个线程共享内存(数据共享,共享全局变量),从而极大地
提高了程序的运行效率。
协程:是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。 协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,
恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
6、互斥锁
互斥锁的作用就是保证同一时刻只能有一个线程去操作共享数据,保证共享数据不会出现错误问题
使用互斥锁的好处确保某段关键代码只能由一个线程从头到尾完整地去执行
使用互斥锁会影响代码的执行效率,多任务改成了单任务执行
互斥锁如果没有使用好容易出现死锁的情况
# 创建锁
mutex = threading.Lock()
# 上锁
mutex.acquire()
...这里编写代码能保证同一时刻只能有一个线程去操作, 对共享数据进行锁定...
# 释放锁
mutex.release()
7、死锁
死锁: 一直等待对方释放锁的情景就是死锁 死锁的结果:会造成应用程序的停止响应,不能再处理其它任务了。
原因:系统资源不足、资源分配不当又相互竞争资源、请求资源顺序不当
避免死锁的方法:
因为互斥是不可改变的,所以只能破坏其他三个条件中的一个来解除死锁,方法:剥夺资源、杀死其中一个线程。
避免死锁最简单的方法就是阻止循环等待条件,将系统中所有的资源设置标志位、排序,规定所有的进程申请资源必须以一定的顺序做操作来避免死锁
8、、TCP和UDP协议
TCP协议(可靠的,但是速度要略慢于UDP协议)是可靠传输协议,主要用于数据传输、文件上传下载、网络通信等等
UDP协议(速度要高于TCP协议,但是没有办法保证数据的安全性)是不可靠传输协议,主要用于视频通话等应用场景
TCP 的英文全拼(Transmission Control Protocol)简称传输控制协议,它是一种面向连接的、可靠的、基于字节流的传输层通信协议。
面向连接的:基于点对点连接的
TCP传输是一种可靠传输协议:给小伙伴发送5MB数据,小伙伴接收到的数据也应该是5MB
基于字节流的传输层通信协议:所有的数据传输都是基于字节流(二进制形式)
TCP是面向连接的,udp是面向非连接的。
TCP 是一对一的两点服务,即一条连接只有两个端点。
UDP 支持一对一、一对多、多对多的交互通信
tcp要求的资源更多。udp要求的资源更少。
tcp是可靠的。udp是非可靠的。
tcp速度慢,udp速度快。
tcp传输大文件,udp小文件。
tcp的可靠传输(记住):
① TCP 采用发送应答机制
② 超时重传
③ 错误校验
④ 流量控制和阻塞管理
9、HTTP:
HTTP协议是一个基于TCP传输协议传输数据的超文本传输协议
HTTP协议规定了浏览器和 Web 服务器通信数据的格式
http请求报文:
get请求报文:请求行、请求头、空行
post请求报文:请求行、请求头、空行、请求体(post请求可以允许没有请求体)
请求行:1、请求方式,2、请求资源路径,3、HTTP协议版本
响应报文:
1、响应行/状态行 2、响应头 3、空行 4、响应体
响应行:HTTP协议版本 状态码 状态描述
http和https的区别
http是无状态的,对传输数据未加密的传输协议,https协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。http要更快一些,端口也不一样http是80,https是443.
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,
于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。简单来说,
HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
HTTPS和HTTP的区别主要如下:
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全
10、URL:
URL就是网络资源的地址,简称网址,通过URL能够找到网络中对应的资源数据
组成部分:协议部分、域名部分、资源路径部分、查询参数部分 [可选]
开发者工具(比如谷歌浏览器)的Headers选项总共有三部分组成:1、General主要信息,2、Response Headers响应头,3、Request Headers请求头
11、深浅拷贝:
浅拷贝有三种形式:切片操作、工厂函数、copy 模块中的 copy 函数
深拷贝只有一种形式,copy 模块中的 deepcopy()函数
浅拷贝最多拷贝对象的一层,深拷贝可能拷贝对象的多层
copy.copy函数是浅拷贝,只对可变类型的第一层对象进行拷贝,对拷贝的对象开辟新的内存空间进行存储,不会拷贝对象内部的子对象。
不可变类型进行浅拷贝不会给拷贝的对象开辟新的内存空间,而只是拷贝了这个对象的引用。
copy.deepcopy函数 深拷贝:
可变类型进行深拷贝会对该对象到最后一个可变类型的每一层对象就行拷贝, 对每一层拷贝的对象都会开辟新的内存空间进行存储。
不可变类型进行深拷贝如果子对象没有可变类型则不会进行拷贝,而只是拷贝了这个对象的引用,否则会对该对象到最后一个可变类型的每一层对象就行拷贝,
对每一层拷贝的对象都会开辟新的内存空间进行存储。
12、正则表达式(看两眼就行):
可读性差,但通用性强,能在适用于很多种编程语言
. 表示匹配任意1个字符(除了\n)
[ ] 表示匹配[ ]中列举的1个字符
\d 表示匹配一个数字,即0-9
\D 表示匹配一个非数字,即不是数字
\s 表示匹配一个空白字符,即 空格,tab键
\S 表示匹配一个非空白字符
\w 表示匹配一个非特殊字符,即a-z、A-Z、0-9、_、汉字
\W 表示匹配一个特殊字符,即非字母、非数字、非汉字
* 表示匹配前一个字符出现0次或者无限次,即可有可无
+ 表示匹配前一个字符出现1次或者无限次,即至少有1次
? 表示匹配前一个字符出现1次或者0次,即要么有1次,要么没有
{m} 表示匹配前一个字符出现m次
{m,n} 表示匹配前一个字符出现从m到n次
13、进程间的通信方式(看两眼就行)
①匿名管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
②高级管道(popen):将另一个程序当做一个新的进程在当前程序进程中启动,则它算是当前程序的子进程,这种方式我们成为高级管道方式。
③有名管道 (named pipe) : 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
④消息队列( message queue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
⑤信号量( semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
⑥信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
⑦共享内存( shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
⑧套接字( socket ) : 套接口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。
14、Django中间件
Django在中间件中预设了六个方法,分别在不同阶段运行,对输入和输出进行干预。
①初始化:在服务器响应第一个请求时调用一次,判断是否启用当前中间件。
def init():
②处理请求前:在每个请求上调用,request对象产生之后,URL匹配之前调用,返回None或者httpResponse对象。
def process_request(request):
③处理视图前:在每个请求上调用,url匹配之后,视图函数调用之前调用,返回None或者httpResponse对象。
def process_view(request, view_func, view_args, view_kwargs):
④处理模板响应前:在每个请求上调用,返回实现了render方法的响应对象。
def process_template_response(request, response):
⑤处理响应后:所有响应返回浏览器之前被调用,在每个请求上调用,返回httpResponse对象
def process_response(request, response):
⑥异常处理:当视图抛出异常时调用,在每个请求上调用,返回一个httpResponse对象
def process_exception(request,exception):
补充:返回值可以是一个NONE,或者HttpResponse对象,如果是none,将继续处理这个请求,执行响应的视图,如果返回是Httpresponse对象,则直接将该对象返回给用户(如果返回httpResponse对象,django不会调用视图函数,将执行中间件的process_response方法并将应用到该httpResponse并返回结果)。
自定义中间件示例:
from django.utils.deprecation import MiddlewareMixin
class MD1(MiddlewareMixin):
def process_request(self, request):
print("MD1里面的 process_request")
def process_response(self, request, response):
print("MD1里面的 process_response")
return response
# 在settings.py的MIDDLEWARE配置项中注册上述两个自定义中间件:
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'middlewares.MD1', # 自定义中间件MD1
'middlewares.MD2' # 自定义中间件MD2
]
15、Nginx
一款开源的高性能http服务器和反向代理。
1、作为web服务器,处理静态文件和搜索文件的效率非常高。
2、最大支持五万个并发,但只占用很少的内存空间
3、稳定性高,配置简洁
4、强大的反向代理和负载均衡功能,平衡集群中的负载压力应用。
16、WSGI
WSGI是一种web服务器网关接口。他是一个web服务器(如Nginx,uWSGI等服务器)与web应用(如用FLASK框架写的程序)通信的一种规范。
17、uwsgi
uwsgi是一种线路协议(不是通信协议),常用于在与uWSGI服务器与其他网络服务器的数据通信。
18、uWSGI
uWSGI是一个web服务器,实现了WSGI、uwsgi,http等协议。Nginx中HttpUwsgiModule的作用就是与uWSGI服务器进行交换
19、Nginx和uWSGI服务器之间如何配合工作的
首先浏览器发送http请求到Nginx服务器,Nginx根据接收到的请求包,进行url分析,判断访问的资源类型,如果是静态资源,直接读取静态资源返回给浏览器,如果请求的是动态资源就转交给uWSGI服务器,uWSGI服务器根据自身的uwsgi和WSGI协议,找到对应的Django框架,Django框架下的应用进行逻辑处理后,将返回值发送到uWSGI服务器,然后uWSGI服务器再返回给Nginx,最后Nginx将返回值返回给浏览器进行渲染显示给用户。
20、对数据库的基本优化操作
对于强调快速读取的操作,对事物没有要求的,可以考虑使用MyISAM数据库引擎
①为了提高查询效率,可以做冗余字段设计,以空间换时间
②对搜索频率高的字段可以设置索引,唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件;更新非常频繁的字段不适合创建索引;
③字段类型的选择。选择占用字节少的,能用一个字节的就不用两个字节的,能用varchar确定字段长度时,就不要用text。
④尽量将字段设置为not null
⑤如果一个页面需要多次连接数据库,最好一次性取出所有需要的数据,减少对数据库的查询次数
⑥使用缓存减少与数据库的交互
⑦Django框架下的Querysets本来就有缓存。
敲代码时注意点:
能使用关联查询解决的尽量不要使用子查询
⑧使用外键来联系表与表之间的查询
⑨sql语句在使用时尽量大写(数据库在解析语句时会先转换成大写再执行)
使用慢查询工具找出效率低下的SQL语句进行优化;
⑩尽量避免在 where 子句中使用!=或<>操作符, MySQL只有对以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE
用户请求量大,单库太大,单表太大就需要分库分表。(分库分表的顺序应该是先垂直分,后水平分,因为垂直分更简单)
垂直分表:针对表内字段多而数据多,使用垂直切分。大表拆小表,将不常用的、数据量大的字段拆到拓展表
水平分表:因为单张表的数据量太大,使用水平切分,把表的数据按某种规则(RANGE,HASH取模等)切分成多张表,甚至多个库上的多张表,如user表拆分为user_0和user_1表。
垂直分库:单个库数据量大时,则使用垂直切分,根据业务切分成不同的库,并分别部署到不同主机上(单个主机资源有限)。
水平分库:将单张表的的数据切分到多个服务器上,每个服务器具有相应的库与表,只是表中数据集合不同。
水平分库分表切分规则:
RANGE:0到一万是一张表,一万零一到两万是一张表。
HASH取模,离散化:一个商场系统,一般都是将用户,订单作为主表,然后将和它们相关的作为附表,这样不会造成跨库事
务之类的问题。 取用户id,然后hash取模,分配到不同的数据库上。
还有地理区域和时间(如一年前的数据切到另外的表中)规则。

21、Django如何提升性能(高并发)
提升性能主要是两个指标,一个高并发,一个响应时间
1、尽量一次性取出所需要的数据,减少与数据库交互
2、当需要比较少字段数据时,可以使用qeryset.values和values_list
3、使用redis缓存数据
4、使用celery将耗时任务比如手机验证码、邮件等扔到队列中,异步执行
5、对数据库进行优化
6、如果要求很高的话,需要将框架二次开发,将框架拆掉,自己写socket实现http通信,底层用纯c,c++写提升效率。把orm框架干掉,自己编写封装与数据库交互的框架,因为orm效率比较低。
前端措施
1、减少http请求,比如使用雪碧图
2、充分利用浏览器缓存,将常用的css、js图标等静态资源缓存到浏览器本地。通过设置http头中的cache—control和expriress属性设置浏览器缓存
运维措施:
搭建集群,分库分表,分散压力,多花钱升级硬件就行了
22、redis持久化(redis默认开启RDB,AOF未开启)
1、RDB快照持久化
将内存中的数据写入磁盘进行持久化。在进行持久化时,redis会创建子进程来执行。执行BGSAVE命令,手动触发RDB持久化。
2、AOF追加文件持久化
redis可将执行的所有指令追加记录到文件中持久化存储
注意:(redis集群)
redis cluster 不支持事务
redis cluster 不支持多键操作,如mset
# 使用默认的就可以
# appendfsync always # 每个操作都写到磁盘中
appendfsync everysec # 每秒写一次磁盘,默认
# appendfsync no # 由操作系统决定写入磁盘的时机
https://www.cnblogs.com/jian0110/p/10205945.html
https://baijiahao.baidu.com/s?id=1654694618189745916&wfr=spider&for=pc
23、TPS
事务/秒。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。
24、redis的watch就是一个乐观锁
25、事务隔离级别
① Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
② Repeatable read (可重复读):可避免脏读、不可重复读的发生。
③ Read committed (读已提交):可避免脏读的发生。
④ Read uncommitted (读未提交):最低级别,任何情况都无法保证。
数据库事务的四大特性以及事务的隔离级别 https://www.cnblogs.com/kopok/p/15212528.html
补充:innodb和myisam引擎区别:
innodb支持事务,myisam不支持事务。
InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败;
InnoDB表必须有唯一索引(如主键)(用户没有指定的话会自己找/生产一个隐藏列Row_id来充当默认主键),而Myisam可以没有
Innodb存储文件有frm、ibd,而Myisam是frm、MYD、MYI
Innodb:frm是表定义文件,ibd是数据文件
Myisam:frm是表定义文件,myd是数据文件,myi是索引文件
InnoDB支持表级锁、行(默认)级锁,而MyISAM支持表级锁。(在执行不能确定扫描范围的sql语句时,innodb同样会锁全表。)
myisam使用非聚集索引,索引和数据分开,只缓存索引;innodb使用聚集索引,索引和数据存在一个文件。
myisam保存表具体行数;innodb不保存。
https://blog.csdn.net/qq_41706670/article/details/92836395
https://blog.csdn.net/qq_35642036/article/details/82820178?utm_medium=distribute.pc_relevant_t0.none-task-blog-2defaultBlogCommendFromMachineLearnPai2default-1.essearch_pc_relevant&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2defaultBlogCommendFromMachineLearnPai2default-1.essearch_pc_relevant
26、MySQL三范式
1、原子性,列不可拆分,表中的所有字段值都是不可分解的原子值
2、有主键,且其他字段必须完全依赖主键
3、非主键列必须直接依赖于主键,不能存在传递依赖,即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况
27、缓存雪崩
缓存雪崩是指缓存不可用或者大量缓存由于超时时间相同在同一时间段失效,大量请求直接访问数据库,数据库压力过大导致系统雪崩。
解决方案:
1、给缓存加上一定区间内的随机生效时间,不同的key设置不同的失效时间,避免同一时间集体失效。比如以前是设置10分钟的超时时间,那每个Key都可以随机8-13分钟过期,尽量让不同Key的过期时间不同。
2、采用多级缓存,不同级别缓存设置的超时时间不同,及时某个级别缓存都过期,也有其他级别缓存兜底。
3、利用加锁或者队列方式避免过多请求同时对服务器进行读写操作。
28、缓存穿透
缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:(1、缓存空对象,2、过滤请求 布隆过滤器)
- 约定:对于返回为NULL的依然缓存,对于抛出异常的返回不进行缓存,注意不要把抛异常的也给缓存了。采用这种手段的会增加我们缓存的维护成本,需要在插入缓存的时候删除这个空缓存,当然我们可以通过设置较短的超时时间来解决这个问题。
- 制定一些规则过滤一些不可能存在的数据,小数据用BitMap,大数据可以用布隆过滤器,比如你的订单ID 明显是在一个范围1-1000,如果不是1-1000之内的数据那其实可以直接给过滤掉。
布隆过滤器容量有限且不支持删除,随着里面内容的增加,误判率就会随之上升。请问,这个问题你们是怎么解决的?
首先,不支持删除的话,就换一个支持删除的布隆过滤器的轮子咯。
比如我前面的文章中提到的布谷鸟过滤器。
或者就是提前重构布隆过滤器。
比如在容量达到 50% 的时候,就申请一个新的更大的布隆过滤器来替换掉之前的过滤器。
只是需要注意的是,重建你得知道有那些数据需要进行重建的,所以你得有个地方来记录。
比如就是 Redis、数据库,甚至内存缓存都可以。
没落地过没关系,你底气十足的回答就行了。
你要相信,面试官八成也没落地过,你们看的说不定都是同一份资料呢。
注:布隆过滤器说存在的有可能存在,说不存在那肯定不存在
29、缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
对于大热点数据,可以在后台开启定时任务,专门更新某些快过期的数据。比如设置热点过期时间是十分钟,在第八分钟或第九分钟的时候主动更新。或者永不过期
30、面向对象
面向对象是相对于面向过程而言的。面向过程语言是一种基于功能分析的、以算法为中心的程序设计方法;而面
向对象是一种基于结构分析的、以数据为中心的程序设计思想。在面向对象语言中有一个有很重要东西,叫做类。
面向对象有三大特性:封装、继承、多态。
31、redis过期策略
①定时过期
每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
②惰性过期
只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存
③定期过期
每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
redis同时使用了惰性过期和定期过期:
Redis过期删除采用的是定期删除,默认是每100ms检测一次,遇到过期的key则进行删除,这里的检测并不是顺序检测,而是随机检测。那这样会不会有漏网之鱼?显然Redis也考虑到了这一点,当我们去读/写一个已经过期的key时,会触发Redis的惰性删除策略,直接回干掉过期的key。
如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。
32、redis缓存淘汰机制
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。(在实际应用中都设置了过期时间,设置volatile-lru策略)
33、mysql数据库和redis缓存操作顺序
先更新MySQL数据库,再删除redis缓存。
34、迭代器、生成器、装饰器、yield
35、如果因为一些原因,线上Redis挂了,然后所有请求打到数据库层导致数据库也挂了,这时该怎么进行恢复?
先把 Redis 和数据库服务重新启动起来。但是启动之前得先做个小操作,把流量摘掉,可以先把流量拦截在入口的地方,比如简单粗暴的通过 Nginx 的配置把请求都转到一个精心设计的错误页面,就是说这么一个意思。这样做的目的是为了防止流量过大,直接把新启动的服务,启动一个打挂一个的情况出现。
要是启动起来又扛不住了,三大利器:缓存、拆分、加钱。就是当 Redis 服务重新启动后,通过程序先放点已知的热点 key 进去后,系统再对外提供服务,防止缓存击穿的场景。
而且上面这一系列操作其实和开发人员的关系不大,主要是运维同学干的事儿。开发同学最多就是在设计服务的时候做到服务无状态,以达到快速水平扩容的目的。
然后回答预防方案:缓存雪崩、击穿和穿透
36、pipeline
可以一次性发送多条命令并在执行完后一次性将结果返回。
pipeline 通过减少客户端与Redis的通信次数来实现降低往返延时时间。
原理:
实现的原理是队列。
Client 可以将三个命令放到一个 tcp 报文一起发送。Server 则可以将三条命令的处理结果放到一个 tcp 报文返回。队列是先进先出,这样就保证数据的顺序性。
37、celery
Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
broker可以使用RabbitMQ (消息队列)或者Redis(缓存数据库)
celery充当生产者发布任务,然后任务缓存到中间人(或者说消息队列,redis充当)暂时存储,worker(celery充当)检测到消息队列中有任务后执行任务
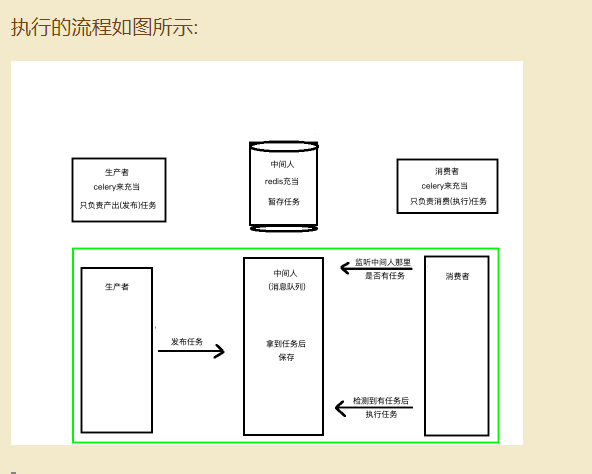
celery 是一个简单、灵活且可靠、处理大量消息的分布式系统,可以在一台或者多台机器上运行.
特点:
单个 Celery 进程每分钟可处理数以百万计的任务.
通过消息进行通信,使用消息队列( 中间人或broker )在生产者和消费者之间进行协调。
Celery 核心模块
Celery有一下5个核心角色
Task
就是任务,有异步任务和定时任务
Broker
中间人,接收生产者发来的消息即Task,将任务存入队列。任务的消费者是Worker。Celery本身不提供队列服务,推荐用Redis或RabbitMQ实现队列服务。
Worker
执行任务的单元,它实时监控消息队列,如果有任务就获取任务并执行它。
Beat
定时任务调度器,根据配置定时将任务发送给Broler。
Backend
用于存储任务的执行结果。
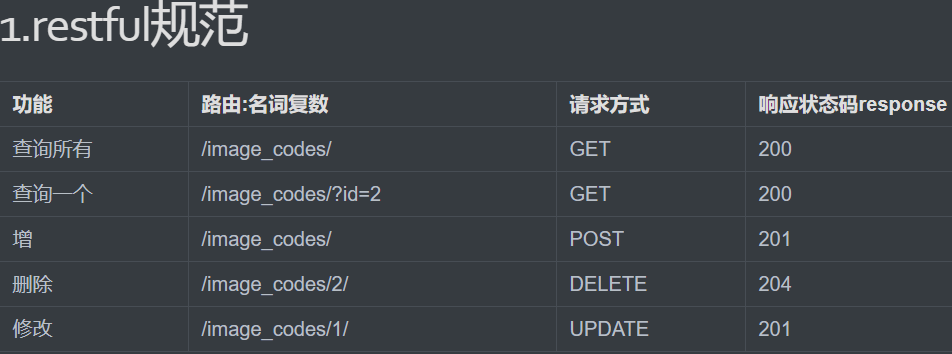
38、resful规范
39、分布式数据库主键ID的设计
使用UUID或者雪花算法
40、session共享
41、flask请求上下文和应用上下文
current_app、g是应用上下文 request、session是请求上下文
应用上下文:在flask 应用程序运行过程中,保存的一些配置信息,比如程序名、数据库连接、应用信息等。可以说他是request context中一个对app的代理人,它的作用主要是帮助 request 获取当前的应用。但它也不是一直存在的,它是伴 request 而生,随 request 而灭的。
请求上下文:保存了客户端和服务器交互的数据。flask从客户端获取请求后,为了处理请求需要让视图访问一些对象,如果就像请求对象通过参数传入到视图,处理过程中访问很多对象就会弄得有点乱,而请求上下文把对象变成了全局可访问,随用随取,也比较方便。
42、三次握手、四次挥手
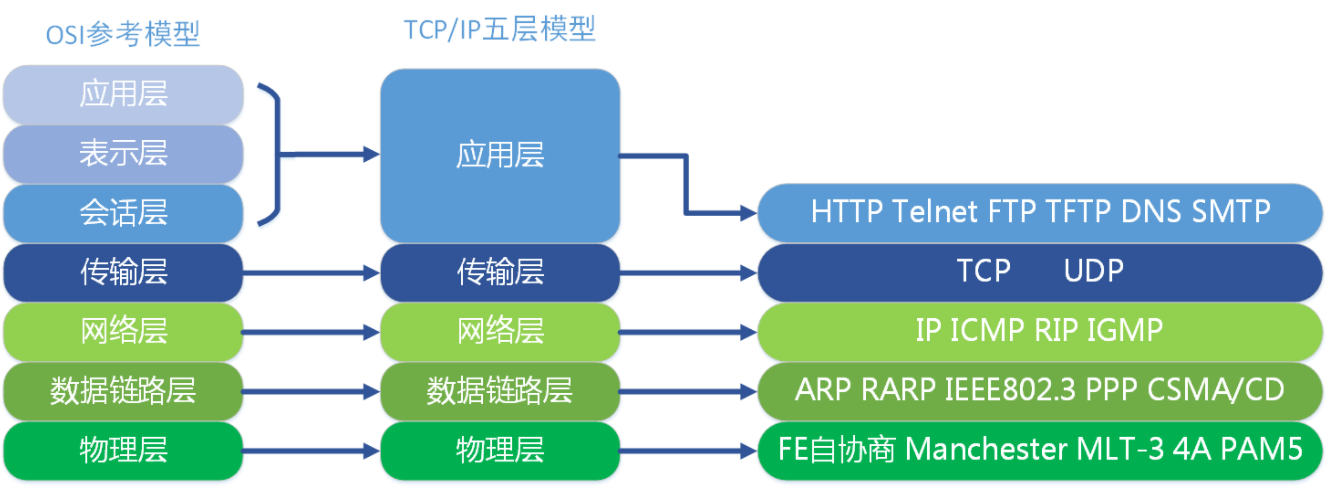
43、OSI七层模型与TCP/IP五层模型
OSI(开放式系统互联)七层模型:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层
TCP/IP五层模型:物理层、数据链路层、网络层、传输层、应用层
44、浏览器访问Web服务器通信流程
当我们在浏览器中输入http://www.baidu.com/为什么能打开百度的网页,这段时间到底经历了什么?
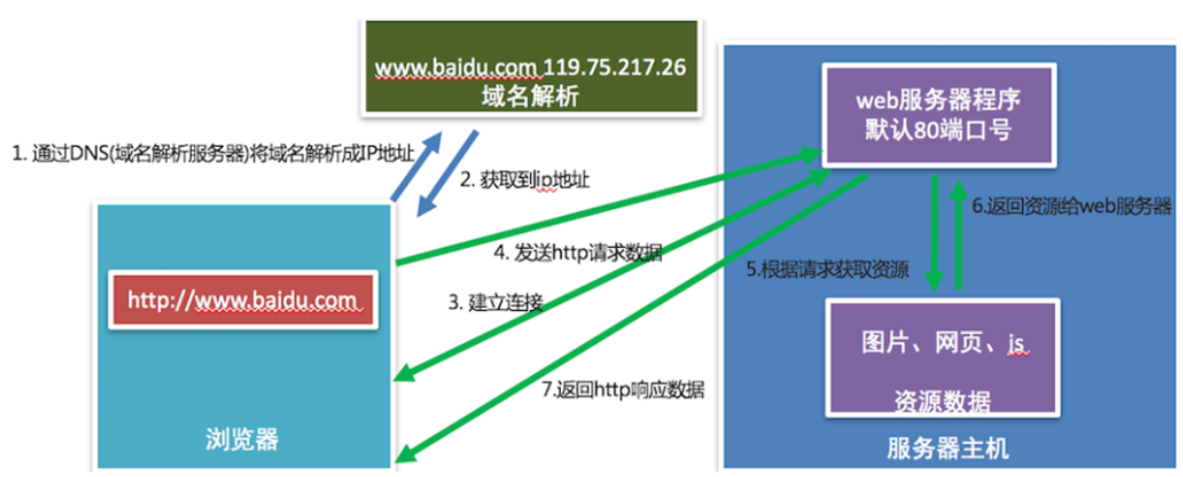
① 输入网址,然后请求DNS服务器,把域名翻译为IP地址(这个过程也可以通过ping命令测试)
② 有了百度的IP地址以后,客户端就会向Web服务器端发起请求(底层是基于TCP的,但是传输的数据格式是基于HTTP协议的),通过HTTP协议,发起请求
③ Web服务器接收到刚才浏览器端发起的HTTP请求,对请求的数据进行处理(看看你想要哪些数据,如网页、图片、音乐、视频等待),处理完成后,把数据组装为HTTP协议格式,然后返回给浏览器客户端。
④ 浏览器的客户端,接收到服务器返回的超文本数据以后,通过浏览器的内核对数据进行渲染,然后显示给用户。
45、url
统一资源定位符,通俗理解就是用于定位网络中资源地址,也就是我们常说的网址。
URL组成部分
① 协议部分 http://
② 域名部分 www.itheima.com
③ 资源路径部分 /index.html
④ 查询参数部分 [可选] /index.html?参数=参数值,如/indexhtml?page=1
46、面向对象
面向对象是相对于面向过程而言的。面向过程语言是一种基于功能分析的、以算法为中心的程序设计方法;而面
向对象是一种基于结构分析的、以数据为中心的程序设计思想。在面向对象语言中有一个有很重要东西,叫做类。
面向对象有三大特性:封装、继承、多态。
47. es为什么全文搜索这么快
https://www.cnblogs.com/dreamroute/p/8484457.html
https://www.jianshu.com/p/9c7d4bb3b093
像在mysql中模糊查找是不走索引的,查找速度相当慢
在es中,预先抓取数据,建立索引,通过FST压缩技术,将索引缓存到内存中,索引查找的操作基本在内存中完成,速度很快。es为字段内容创建了倒排索引,内容直接指向唯一标识,
比如文档ID,通过Term Index → Term Directionary → Posting List的方式进行查找,可以理解term index是一颗树,就像字典里的索引页一样,A开头的有哪些term,
分别在哪页,而且这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺
序查找。Term Directionary
中将所有的term排序,二分法查找term,logN的查找效率。Posting list就是一个int数组,存储了所有符合某个term的文档id(唯一标识)。
像在mysql中模糊查找是不走索引的,查找速度相当慢
在es中,es为字段创建了倒排索引,内容直接指向唯一标识,比如文档ID,通过Term Index → Term Directionary → Posting List的方式进行查找,
Elasticsearch分别为每个field都建立了一个倒排索引,Kate, John, 24, Female这些叫term,而[1,2]就是Posting List。Posting list就是一个int数组,存储了所有符合某个term的文档id(唯一标识)。可以理解term index是一颗树,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,而且这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。再结合FST的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term。
有顺序的id查找速度会更快,uuid会稍慢,不需要索引的字段最好指明,因为他是自动建立索引的
可以理解term index是一颗树,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,而且这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。再结合FST的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
Elasticsearch为了能快速找到某个term,将所有的term排序,二分法查找term,logN的查找效率,就像通过字典树查找一样,这就是Term Dictionary。
48、property装饰器
http://c.biancheng.net/view/4561.html
@property是python内置的一个装饰器,作用是将一个方法变成属性。
1、在使用@property装饰器之后,可以使用 类.方法名 不带括号的方式获取其返回值(必须存在的),但是 @property 装饰的函数,不能附带除self之外的其他参数;
2、在使用@prop.setter装饰器后,可以使用 类.方法名 来进行赋值,但是@prop.setter 装饰的函数,只能有除了self之外的一个参数。
49、主要用过哪些技术栈
web框架django用的多,也用过flask和drf。一般关系型数据库使用mysql,非关系型数据库用过redis、mongodb,在之前的公司redis用的比较多。像耗时任务,一般就是celery+redis或者rabbitmq解耦出来异步执行,搜索功能的通常都是haystack+es。保持登录状态cookie、session和jwt里面session和jwt用的多。代码管理用git。还有一些第三方库
49、oauth2.0的四种认证模式
授权码(authorization-code)
隐藏式(implicit)
密码式(password)
客户端凭证(client credentials)
https://blog.csdn.net/qq_37457564/article/details/107581986
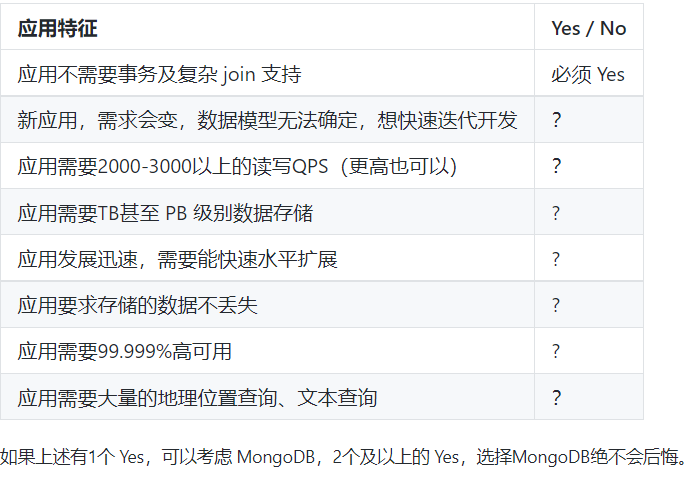
50、mongodb和redis
都说redis缓存、mongodb数据库,redis“缓存”的性质远大于其“数据存储“的性质,其中数据的增删改查也只是像变量操作一样简单;MongoDB却是一个“存储数据”的系统,增删改查可以添加很多条件,就像SQL数据库一样灵活
MongoDB使用JSON的变种BSON作为内部存储的格式和语法。针对MongoDB的操作都使用JSON风格语法,客户端提交或接收的数据都使用JSON形式来展现。对于项目的数据处理格式都是采用JSON的形式来处理的话,就很友好。mongodb也更适合大数据量存储。 redis的tps比mongodb更高一点。在事务这一块,虽然redis也挺弱,但是优于mongodb。
MongoDB和Redis都是NoSQL,采用结构型数据存储。二者在使用场景中,存在一定的区别,这也主要由于
二者在内存映射的处理过程,持久化的处理方法不同。MongoDB建议集群部署,更多的考虑到集群方案,Redis
更偏重于进程顺序写入,虽然支持集群,也仅限于主-从模式。
https://www.cnblogs.com/java-spring/p/9488227.html
https://www.cnblogs.com/daofaziran/p/11013469.html
51、TPS和QPS
TPS:Transactions Per Second,意思是每秒事务数;QPS:Queries Per Second,意思是每秒查询率,是一台服务器每秒能够响应的查询次数(数据库中的每秒执行查询sql的次数)
一、TPS:Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。TPS包括一条消息入和一条消息出,加上一次用户数据库访问。(业务TPS = CAPS × 每个呼叫平均TPS)
TPS是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。系统整体处理能力取决于处理能力最低模块的TPS值。
二、QPS:每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。
对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。
52、跨域
我们使用django-cors-headers扩展来解决后端对跨域访问的支持。
1、安装django-cors-headers 2、注册应用和中间件 3、设置白名单
跨域实现流程:
①浏览器会第一次先发送option请求询问后端是否允许跨域,后端查询白名单中是否有这两个域名
②如果域名在白名单中则在相应结果中告知浏览器允许跨域
③浏览器第二次发送post请求,携带用户登录数据到后端,完成登录验证操作
53、celery
Celery 组件
Celery 扮演生产者和消费者的角色
Producer :
任务生产者. 调用 Celery API , 函数或者装饰器, 而产生任务并交给任务队列处理的都是任务生产者。
Celery Beat :
任务调度器. Beat 进程会读取配置文件的内容, 周期性的将配置中到期需要执行的任务发送给任务队列。
Broker :
消息代理, 队列本身. 也称为消息中间件.。接受任务生产者发送过来的任务消息, 存进队列再按序分发给任务消费方(通常是消息队列或者数据库)。
Celery Worker :
执行任务的消费者, 通常会在多台服务器运行多个消费者, 提高运行效率。
Result Backend :
任务处理完成之后保存状态信息和结果, 以供查询。
通过task装饰器实现任务,通过delay方法调用任务。
54、在前后端分离开发中,一般是前端重定向
55、为什么mongodb需要创建索引
加快查询速度,进行数据的去重
56、索引的优缺点
优点:提高数据的查询速度
缺点:牺牲了数据库的插入和更新速度
mongodb20万条数据(id,名字,年龄)查找id188888 1毫秒,名字无索引耗费100左右,名字建立索引一两毫秒,年龄本来也是100毫秒左右,建立索引后比名字快点,也是1、2毫秒
57、mysql的解释
其实就是explain
查看语句执行情况,会出一个日志信息,查看消耗的时间什么的
58、复合索引(mongodb)
有多个索引都包含查询字段的时候:①当有若干个索引能适合查询用到的key时,优化器会同时并行使用索引进行查询,选择最快索引。
②优化器会定期或定查询次数重新进行最优索引的筛选
mysql中最左原则:
首先我们要知道最左匹配原则是什么?
最左匹配原则:最左优先,以最左边的为起点任何连续的索引都能匹配上, MySQL会一直向右匹配直到遇到范围查询(>,<,between,like)就停止匹配。
个人对最左前缀的理解
MySQL中的索引可以以一定顺序引用多列,这种索引叫作联合索引。如User表的name和city加联合索引就是(name,city),而最左前缀原则指的是,如果查询的时候查询条件精确匹配索引的左边连续一列或几列,则此列就可以被用到。如下:
select * from user where name=xx and city=xx ; //可以命中索引
select * from user where name=xx ; // 可以命中索引
select * from user where city=xx ; // 无法命中索引
这里需要注意的是,查询的时候如果两个条件都用上了,但是顺序不同,
如 city= xx and name =xx,那么现在的查询引擎会自动优化为匹配联合索引的顺序,这样是能够命中索引的。
由于最左前缀原则,在创建联合索引时,索引字段的顺序需要考虑字段值去重之后的个数,较多的放前面。ORDER BY子句也遵循此规则。
索引index1:(a,b,c),只会走a、a,b、a,b,c 三种类型的查询,其实这里说的有一点问题,a,c也走,但是只走a字段索引,不会走c字段。
59、mongodb
a.网站数据:mongo非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
b.缓存:由于性能很高,mongo也适合作为信息基础设施的缓存层。在系统重启之后,由mongo搭建的持久化缓存可以避免下层的数据源过载。
c.大尺寸、低价值的数据:使用传统的关系数据库存储一些数据时可能会比较贵,在此之前,很多程序员往往会选择传统的文件进行存储。
d.高伸缩性的场景:mongo非常适合由数十或者数百台服务器组成的数据库。适合集群部署
e.用于对象及JSON数据的存储:mongo的BSON数据格式非常适合文档格式化的存储及查询。

用在应用服务器的日志记录,查找起来比文本灵活,导出也很方便;存储一些监控数据
游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、更新物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来。社交场景,使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析视频直播,使用 MongoDB 存储用户信息、礼物信息
60、session共享问题如何解决
1、.把session加密后存在cookie中,每次session信息被写在客服端,然后经浏览器再次提交到服务器。这个方案的优点无需额外的服务器资源;缺点是由于受http协议头长度的限制,仅能够存储小部分的用户信息,同时Cookie化的 Session内容需要进行安全加解密(如:采用DES、RSA等进行明文加解密;再由MD5、SHA-1等算法进行防伪认证),另外它也会占用一定的带宽资源,因为浏览器会在请求当前域名下任何资源时将本地Cookie附加在http头中传递到服务器。我们知道Cookie是有长度限制的,而这也会限制Session数据的长度;Session数据本来都是服务端数据,而这个方案是让这些服务端数据到了外部网络及客户端,因此存在安全性上的问题
2、session服务器,专门存储session,还需要从服务器备份session,万一服务器宕机,需要从服务器补充上。
3、redis共享session
61、jwt禁用问题
首先:jwt使用情况是使用两个jwt,一个token用于登录,一个refesh_token专门用于刷新token,token和refresh_token载荷中有个isfreshtoken=True/false判断是哪个token。每次账号密码登录刷新两个token,前端自动调用接口使用refresh_token刷新token,refresh_token未过期且有user_id则刷新token。
针对修改密码和禁用用户账号。mysql数据库设置注销或者删除字段,对于注销或者封号的账号修改字段状态,在登录的时候会查询账号状态。
通过白名单黑名单的方式。(将用户id:新token存到数据库里,过期时间就是token过期时间。如果用户旧token登录成功,先校验是否在名单内,id没在名单内,正常访问视图。如果id在名单内则校验是否是存在数据库中的新token,是则放行,不是则返回403(和修改密码后的新token不一致,说明这是旧token,需要重新登录,保证了旧token无法使用))。
将用户id和更改密码时间存储redis,token登录后,先校验是否在名单内,然后校验时间是否大于密码更改时间,如果大于,说明是更改密码后的新token,通过。如果小于密码更改时间,则说明是旧token,返回403。对于refresh_token同样查看redis的名单中是否有refresh_token的id,如果有,则校验时间。名单中的各个key过期时间是refresh_token的过期时间,保证旧token和旧refresh_token不能用。注销或者封号同样将id和注销时间存到名单中,保证旧的token不能用,需要登录,登录时会查询mysql字段,无法登录。
62、缓存
SQLAlchemy起到一定的本地缓存作用(sql奥克梅)
在同一请求中多次相同的查询只查询数据库一次,SQLAlchemy做了本地缓存(类似Django中的Queryset查询结果集)
视图的响应结果(JSON),页面(HTML)在代码中加上@cache装饰器,可以缓存
63、redis和mysql应用场景
redis基于内存,读写速度非常快,也支持持久化,有两种持久化方式,但是容易受容量空间限制,虽然redis也有自己的缓存淘汰机制,但是比较受容量制约。
mysql基于磁盘,读写速度比redis慢,但是不易受容量空间限制。
应用场景:多数时候mysql为主,redis为辅,mysql做主存储,redis做缓存,加快访问速度,可以在需要高性能的部分,访问量大的数据使用redis,不需要高性能的部分使用mysql。但是redis在使用时注意缓存雪崩、缓存穿透和缓存击穿。
63、memcached和redis
mem可缓存图片和视频,redis支持更多的数据结构,redis可使用虚拟内存,redis可以持久化和灾难恢复,redis支持主从数据备份,redis可以做消息队列。我感觉图片视频存redis不划算,可以存mongodb中。(redis的Strings类型:一个String类型的value最大可以存储512M)
64、31、你常用的Nginx模块,用来做什么
rewrite模块,实现重写功能
access模块:来源控制
ssl模块:安全加密
ngx_http_gzip_module:网络传输压缩模块
ngx_http_proxy_module 模块实现代理
ngx_http_upstream_module模块实现定义后端服务器列表
ngx_cache_purge实现缓存清除功能
65、缓存的使用
你可以缓存特定视图的输出、你可以仅仅缓存那些很难生产出来的部分、或者你可以缓存你的整个网站。
在setting文件中配置caches,指明缓存缓存到哪里,ip和端口。如果使用memcached,可以在多台机器上运行memcached服务,缓存共享(这些程序会把这几个机器当做同一个缓存),在配置的时候location把所有ip、端口列出来就可以。(memcached在宕机时会丢失数据,所以只能是缓存解决方案,不能作为存储方案,不能完全代替硬盘存储)
可以做站点级缓存,缓存整个网站。把'django.middleware.cache.UpdateCacheMiddleware' 和 'django.middleware.cache.FetchFromCacheMiddleware' 添加到 MIDDLEWARE_CLASSES 设置里,update在最上面,fetch在最后。
单个view缓存。django.views.decorators.cache 定义了一个自动缓存视图response(响应)的 cache_page装饰器,直接将装饰器挂在视图上就可以
66、python设计模式
https://www.cnblogs.com/tangkaishou/p/9246353.html
https://www.jianshu.com/p/6a1690f0dd00
单例:目的是保证一个类只有一个实例 实现:基于__new__方法实现(推荐使用,方便),使用模块,使用装饰器(django的日志用到了单例)
工厂模式、建造者模式。。。
66、With文件操作,上下文管理器
当with体执行完将自动关闭打开的文件(with open在执行完后会自动关闭打开的文件,open还需要手动写一行close代码关闭文件)
实际上,在文件操作时,并不是不需要写文件的关闭,而是文件的关闭操作在 with 的上下文管理器中的协议方法里已经写好了。当文件操作执行完成后,
with语句会自动调用上下文管理器里的关闭语句来关闭文件资源。
==艾克sei特==
上下文管理器中有 __enter__ 和 __exit__ 两个方法,以with为例子,__enter__ 方法会在执行 with 后面的语句时执行,一般用来处理操作前的内容。
比如一些创建对象,初始化等;__exit__ 方法会在 with 内的代码执行完毕后执行,一般用来处理一些善后收尾工作,比如文件的关闭,数据库的关闭等。
67、解决跨域问题
# 第一种
安装django-cors-headers,注册应用corsheaders,注册中间件,跨域白名单
# 第二种 方法2:使用JSONP
使用Ajax获取json数据时,存在跨域的限制。不过,在Web页面上调用js的script脚本文件时却不受跨域的影响,
JSONP就是利用这个来实现跨域的传输。因此,我们需要将Ajax调用中的dataType从JSON改为JSONP(相应的API也需要支持JSONP)格式。
jsonp只能用于get请求
#方案3.直接修改Django中的views.py文件,原理是修改请求头
ACAO等于*
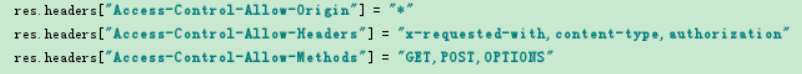
68、常见响应状态码
服务器向用户返回的状态码和提示信息,常用的有:
1XX 表示请求被接受,并需要处理
100 初始请求已被接受,客户端应当发送其余部分
101 服务器将遵从客户的请求转换到另外一种协议
2XX 请求成功,表示成功处理了请求
200 OK :服务器成功返回用户请求的数据
201 CREATED :用户新建或修改数据成功。
202 Accepted:表示请求已进入后台排队。
3XX 重定向
301 (永久移动)请求的网页已永久移动到新位置。服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新的位置
302 (临时移动)服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求
4XX 请求错误
400 INVALID REQUEST :用户发出的请求有错误。
401 Unauthorized :用户没有权限。
403 Forbidden :访问被禁止。
404 NOT FOUND :请求针对的是不存在的记录。
406 Not Acceptable :用户请求的的格式不正确。
5XX 服务器错误
500 INTERNAL SERVER ERROR :服务器发生错误。
500:(服务器内部错误)服务器遇到错误,无法完成请求
501:(尚未实施)服务器不具备完成请求的功能。例如,服务器无法识别请求方法时可能会返回此代码
502:(错误网关)服务器作为网关或代理,从上游服务器收到无效响应
503:(服务不可用)服务器目前无法使用(由于超载或停机维护)。通常,这只是暂时状态
504:(网关超时)服务器作为网关或代理,但是没有及时从上游服务器收到请求
505:(HTTP 版本不受支持)服务器不支持请求中所用的 HTTP 协议版本
69、flask
flask 是一个基于 Python 开发的 wsgi 微型框架。flask 有两个核心依赖库:Werkzug和jinjia。其中werkzeug 是一个用于实现 WSGI (什么是wsgi)应用的工具集,负责核心的逻辑模块,比如路由、请求和应答的封装、WSGI 相关的函数等;jinja负责模板的渲染,主要用来渲染返回给用户的 html文件内容。
70、集群和分布式
分布式是将一种业务拆分成多个子业务部署在多台服务器上,进而对外提供服务;而集群就是将多台服务器组合在一起提供同一种服务
Python后端基础知识总结的更多相关文章
- Python数据挖掘——基础知识
Python数据挖掘——基础知识 数据挖掘又称从数据中 挖掘知识.知识提取.数据/模式分析 即为:从数据中发现知识的过程 1.数据清理 (消除噪声,删除不一致数据) 2.数据集成 (多种数据源 组合在 ...
- Python 面向对象基础知识
面向对象基础知识 1.什么是面向对象编程? - 以前使用函数 - 类 + 对象 2.什么是类什么是对象,又有什么关系? class 类: def 函数1(): pass def 函数2(): pass ...
- python 爬虫基础知识一
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 网络爬虫必备知识点 1. Python基础知识2. P ...
- Python:基础知识
python是一种解释型.面向对象的.带有动态语义的高级程序语言. 一.下载安装 官网下载地址:https://www.python.org/downloads 下载后执行安装文件,按照默认安装顺序安 ...
- Python学习-基础知识-2
目录 Python基础知识2 一.二进制 二.文字编码-基础 为什么要有文字编码? 有哪些编码格式? 如何解决不同国家不兼容的编码格式? unicode编码格式的缺点 如何既能全球通用还可以规避uni ...
- 第2章 Python编程基础知识 第2.1节 简单的Python数据类型、变量赋值及输入输出
第三节 简单的Python数据类型.变量赋值及输入输出 Python是一门解释性语言,它的执行依赖于Python提供的执行环境,前面一章介绍了Python环境安装.WINDOWS系列Python编辑和 ...
- Python入门 ---基础知识
Python入门不知道这些你还是承早放弃吧!真的 Python 简介 Python 是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言. Python 的设计具有很强的可读性,相比其他语言 ...
- Python学前基础知识
Python基础计算机常识:硬件性能:CPU.内存输入设备:鼠标.键盘外部存储设备:硬盘输出设备;显示器.打印机(不算自带)通讯设备:无线网卡----------------------------- ...
- 10分钟学会Python函数基础知识
看完本文大概需要8分钟,看完后,仔细看下代码,认真回一下,函数基本知识就OK了.最好还是把代码敲一下. 一.函数基础 简单地说,一个函数就是一组Python语句的组合,它们可以在程序中运行一次或多次运 ...
- python编码基础知识
http://www.javaeye.com/topic/560229 一 预备知识 字符集1, 常用字符集分类ASCII及其扩展字符集作用:表语英语及西欧语言.位数:ASCII是用7位表示的,能表示 ...
随机推荐
- voxel体素网络滤波器
1.简介 在进行建图的时候,由于多个视角内存在视野重叠,即多个摄像头看到同样的像素点,这样在重叠区域内会存在大量的位置十分相近的点,这会占用很多内存空间.体素网络滤波保证了在某个一定大小的立方体内只有 ...
- 合肥光源储存环束流三维参数测量系统相关PV
合肥光源纵向震荡数据源相关PV 合肥光源纵向震荡数据源相关PV的增补 在上两文中公布了一些PV,依然有效. 本来发过了,那篇里的PV有些命名的不太好,比如PositionX.PositionY等,感觉 ...
- 世界UTC时间时区对照图
- LeetCode-587 安装栅栏及三种凸包算法的学习
来源:力扣(LeetCode)链接:https://leetcode-cn.com/problems/erect-the-fence 题目描述 在一个二维的花园中,有一些用 (x, y) 坐标表示的树 ...
- js获取input处理
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 【树莓派】在vscode中连接树莓派并编写代码
在树莓派里编写代码的话会比较麻烦因此可以在vscode中通过ssh连接树莓派并且编辑代码 参考: vscode通过ssh连接树莓派实现远程开发 VSCODE 远程开发树莓派 使用vscode打造pyt ...
- CLIP改进工作串讲(上)学习笔记
看了跟李沐学AI系列朱毅老师讲的CLIP改进工作串讲,这里记录一下. 1.分割 分割的任务其实跟分类很像,其实就是把图片上的分类变成像素级别上的分类,但是往往图片上能用的技术都能用到像素级别上来.所以 ...
- ts面试题
1.ts的内置数据类型2.ts中any和unknown3.如何将unknown指定为更具体的类型4.说说对ts中命名空间与模块的理解?区别?5.对ts的理解,和js的区别6.tsconfig.json ...
- JavaScript 类(class)
JavaScript 类(class) 类是用于创建对象的模板. 我们使用 class 关键字来创建一个类,类体在一对大括号 {} 中,我们可以在大括号 {} 中定义类成员的位置,如方法或构造函数. ...
- vue.js----之前端路由(二)
上一篇我们已经把vue框架搭好了,接下来我们进行路由模块 在src目录下新建router.js 添加如下代码 1 /** 2 * Created by sioxa on 2016/10/29 0029 ...