Python爬虫教程-24-数据提取-BeautifulSoup4(二)
Python爬虫教程-24-数据提取-BeautifulSoup4(二)
本篇介绍 bs 如何遍历一个文档对象
遍历文档对象
- contents:tag 的子节点以列表的方式输出
- children:子节点以迭代器形式返回
- descendants:所有子孙节点
- string:用string打印出标签的具体内容,不带有标签,只有内容
- 案例代码27bs3.py文件:https://xpwi.github.io/py/py爬虫/py27bs3.py
# BeautifulSoup 的使用案例
# 遍历文档对象
from urllib import request
from bs4 import BeautifulSoup
url = 'http://www.baidu.com/'
rsp = request.urlopen(url)
content = rsp.read()
soup = BeautifulSoup(content, 'lxml')
# bs 自动解码
content = soup.prettify()
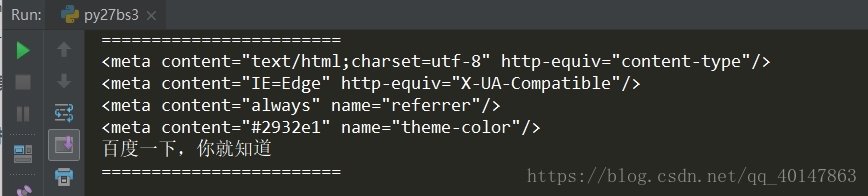
print("=="*12)
# 使用 contents
for node in soup.head.contents:
if node.name == "meta":
print(node)
if node.name == "title":
print(node.string)
print("=="*12)
运行结果
常用string打印出标签的具体内容,不带有标签,只有内容
当然,如果觉得遍历太耗费资源,没有必要遍历的时候,可以使用搜索
搜索文档对象
- find_all(name, attrs, recursive, text, ** kwargs)
- 使用find_all(),返回的列表格式,也就是说如果 find_all(name='meta') ,如果有多个 meta 就以列表形式返回
- name 参数:按照哪个字符搜索,可以传入的内容为
- 1.字符串
- 2.正则表达式,使用正则需要编译:
例如:我们需要打印所有以 me 开头的标签内容
tags = soup.find_all(re.compile('^me')) - 3.也可以是列表
- keyword 参数,可以用来表示属性
- text:对应 tag 的文本值
- 案例代码27bs4.py文件:https://xpwi.github.io/py/py爬虫/py27bs4.py
# BeautifulSoup 的使用案例
# 搜索文档对象
from urllib import request
from bs4 import BeautifulSoup
import re
url = 'http://www.baidu.com/'
rsp = request.urlopen(url)
content = rsp.read()
soup = BeautifulSoup(content, 'lxml')
# bs 自动解码
content = soup.prettify()
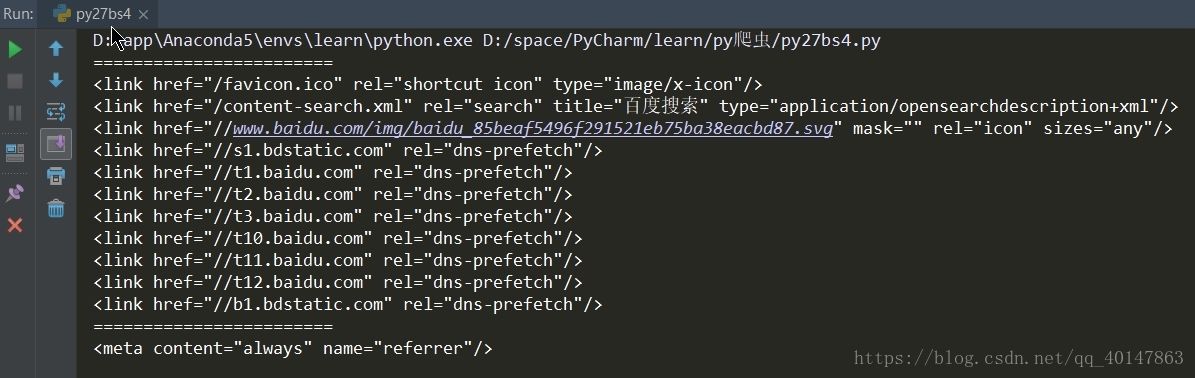
# 使用 find_all
# 使用 name 参数
print("=="*12)
tags = soup.find_all(name='link')
for i in tags:
print(i)
# 使用正则表达式
print("=="*12)
# 同时使用两个条件
tags = soup.find_all(re.compile('^me'), content='always')
# 这里直接打印 tags 会打印一个列表
for i in tags:
print(i)
运行结果:
因为使用两个条件,所以只匹配到一条 meta
下一篇介绍,BeautifulSoup 的 css 选择器
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-24-数据提取-BeautifulSoup4(二)的更多相关文章
- Python爬虫教程-23-数据提取-BeautifulSoup4(一)
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据,查看文档 https://www.crummy.com/software/BeautifulSoup/bs4/doc. ...
- Python爬虫教程-25-数据提取-BeautifulSoup4(三)
Python爬虫教程-25-数据提取-BeautifulSoup4(三) 本篇介绍 BeautifulSoup 中的 css 选择器 css 选择器 使用 soup.select 返回一个列表 通过标 ...
- Python爬虫教程-19-数据提取-正则表达式(re)
本篇主页内容:match的基本使用,search的基本使用,findall,finditer的基本使用,匹配中文,贪婪与非贪婪模式 Python爬虫教程-19-数据提取-正则表达式(re) 正则表达式 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-18-页面解析和数据提取
本篇针对的数据是已经存在在页面上的数据,不包括动态生成的数据,今天是对HTML中提取对我们有用的数据,去除无用的数据 Python爬虫教程-18-页面解析和数据提取 结构化数据:先有的结构,再谈数据 ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(1)
一.数据类型及解析方式 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的数据. 非结构化数据:先有数据,再有结构, 结构化数 ...
- Python爬虫教程-34-分布式爬虫介绍
Python爬虫教程-34-分布式爬虫介绍 分布式爬虫在实际应用中还算是多的,本篇简单介绍一下分布式爬虫 什么是分布式爬虫 分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集.单机爬虫就是只在一 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
随机推荐
- 停不下来队 Scrum Meeting 博客汇总
停不下来队 Scrum Meeting 博客汇总 一.Alpha阶段 [Alpha]Scrum Meeting#1 [Alpha]Scrum Meeting#2 [Alpha]Scrum Meetin ...
- FlutterToast 使用
参看 FlutterToast 开源库 https://github.com/PonnamKarthik/FlutterToast
- Docker 镜像加速
通过 Docker 官方镜像加速,中国区用户能够快速访问最流行的 Docker 镜像.该镜像托管于中国大陆,本地用户现在将会享受到更快的下载速度和更强的稳定性,从而能够更敏捷地开发和交付 Docker ...
- U盘拷贝大文件提示文件过大无法拷贝解决方案
工具: 计算机 windows操作系统 U盘 原因:由于U盘的格式问题导致的,当期的磁盘格式是FAT32类型的,无拷贝过大的文件 方法:接下来修改U盘类型,且不格式化U盘 1.键盘win+R快捷键弹出 ...
- 浅谈Cordova优缺点与环境部署(转载)
浅谈Cordova优缺点与环境部署 作者:苏华杰 简介 Cordova是一个用基于HTML.CSS和JavaScript的,用于创建跨平台移动应用程序的快速开发平台.它使开发者能够利用iPhone.A ...
- (转)基于CentOS 7安装Zabbix 3.4和Zabbix4.0
原文:https://blog.csdn.net/leshami/article/details/78708049 CentOS 7环境下Zabbix4.0的安装和配置实例-----------htt ...
- PHP面向对象的基本原则
对象内部是高内聚的 ——对象只负责一项特定的功能(职能可大可小) ——所有对象相关的内容都封装到对象内部 高内聚就是该有的都有,用的时候不会缺胳膊少腿! 对象对外是低耦合的 ——外部世界可以看到对象的 ...
- python+requests抓取页面图片
前言: 学完requests库后,想到可以利用python+requests爬取页面图片,想到实战一下.依照现在所学只能爬取图片在html页面的而不能爬取由JavaScript生成的图片,所以我选取饿 ...
- selenium+Python(截图保存错误页面)
异常捕捉与错误截图 创建错误截图文件夹,目录结果如下: 用例不可能每一次运行都成功,肯定运行时候有不成功的时候,关键是我们捕捉到错误,并以把并错误截图保存,这将是一个非常棒的功能,也会给我们错误定位带 ...
- 数据链路层差错检测之循环冗余检验CRC
引用https://blog.csdn.net/wenqiang1208/article/details/71641414 为什么引入CRC 现实的通信链路都不会是理想的.这就是说,比特在传输的过程中 ...