Django框架之单表操作
一、添加表记录
对于单表有两种方式
# 添加数据的两种方式
# 方式一:实例化对象就是一条表记录
Frank_obj = models.Student(name ="海东",course="python",birth="2000-9-9",fenshu=80)
Frank_obj.save()
# 方式二:
models.Student.objects.create(name ="海燕",course="python",birth="1995-5-9",fenshu=88)
二、查询表记录
查询相关API
# 查询相关API
# 1、all():查看所有
student_obj = models.Student.objects.all()
print(student_obj) #打印的结果是QuerySet集合
# 2、filter():可以实现且关系,但是或关系需要借助Q查询实现。。。
# 查不到的时候不会报错
print(models.Student.objects.filter(name="Frank")) #查看名字是Frank的
print(models.Student.objects.filter(name="Frank",fenshu=80)) #查看名字是Frank的并且分数是80的
# 3、get():如果找不到就会报错,如果有多个值,也会报错,只能拿有一个值的
print(models.Student.objects.get(name="Frank")) #拿到的是model对象
print(models.Student.objects.get(nid=2)) #拿到的是model对象
# 4、exclude():排除条件
print( models.Student.objects.exclude(name="海东")) #查看除了名字是海东的信息
# 5、values():是QuerySet的一个方法 (吧对象转换成字典的形式了,)
print(models.Student.objects.filter(name="海东").values("nid","course")) #查看名字为海东的编号和课程
#打印结果:<QuerySet [{'nid': 2, 'course': 'python'}, {'nid': 24, 'course': 'python'}]>
# 6、values_list():是queryset的一个方法 (吧对象转成元组的形式了)
print(models.Student.objects.filter(name="海东").values_list("nid", "course"))
#打印结果:< QuerySet[(2, 'python'), (24, 'python')] >
# 7、order_by():排序
print(models.Student.objects.all().order_by("fenshu"))
# 8、reverse():倒序
print(models.Student.objects.all().reverse())
# 9、distinct():去重(只要结果里面有重复的)
print(models.Student.objects.filter(course="python").values("fenshu").distinct())
# 10、count():查看有几条记录
print(models.Student.objects.filter(name="海东").count()) # 11、first()
# 12、last()
return render(request,"test.html",{"student_obj":student_obj})
# 13、esits:查看有没有记录,如果有返回True,没有返回False
# 并不需要判断所有的数据,
# if models.Book.objects.all().exists():
双下划线之单表查询
models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id小于1 且 大于10的值 models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in models.Tb1.objects.filter(name__contains="ven") #包括ven的
models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and startswith,istartswith, endswith, iendswith
对象可以调用自己的属性,用一个点就可以
还可以通过双下划线。。。
models.Book.objects.filter(price__gt=100) 价格大于100的书
models.Book.objects.filter(author__startwith= "张") 查看作者的名字是以张开头的
主键大于5的且小于2
price__gte=99大于等于
publishDate__year =2017,publishDate__month = 10 查看2017年10月份的数据
三、修改表记录
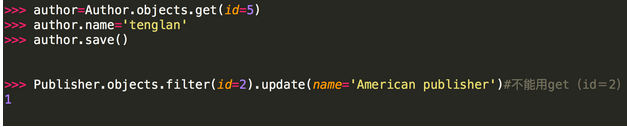
注意:
<1> 第二种方式修改不能用get的原因是:update是QuerySet对象的方法,get返回的是一个model对象,它没有update方法,而filter返回的是一个QuerySet对象(filter里面的条件可能有多个条件符合,比如name='alvin',可能有两个name='alvin'的行数据)。
<2>在“插入和更新数据”小节中,我们有提到模型的save()方法,这个方法会更新一行里的所有列。 而某些情况下,我们只需要更新行里的某几列。
此外,update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录update()方法会返回一个整型数值,表示受影响的记录条数。
注意,这里因为update返回的是一个整形,所以没法用query属性;对于每次创建一个对象,想显示对应的raw sql,需要在settings加上日志记录部分
四、删除表记录
删除方法就是 delete()。它运行时立即删除对象而不返回任何值。例如:e.delete()
def delstudent(request,id):
# 删除数据
models.Student.objects.filter(nid=id).delete()
return redirect("/test/")
你也可以一次性删除多个对象。每个 QuerySet 都有一个 delete() 方法,它一次性删除 QuerySet 中所有的对象。
例如,下面的代码将删除 pub_date 是2005年的 Entry 对象:
Entry.objects.filter(pub_date__year=2005).delete()
要牢记这一点:无论在什么情况下,QuerySet 中的 delete() 方法都只使用一条 SQL 语句一次性删除所有对象,而并不是分别删除每个对象。如果你想使用在 model 中自定义的 delete() 方法,就要自行调用每个对象的delete 方法。(例如,遍历 QuerySet,在每个对象上调用 delete()方法),而不是使用 QuerySet 中的 delete()方法。
在 Django 删除对象时,会模仿 SQL 约束 ON DELETE CASCADE 的行为,换句话说,删除一个对象时也会删除与它相关联的外键对象。例如:
b = Blog.objects.get(pk=1)
# This will delete the Blog and all of its Entry objects.
b.delete()
要注意的是: delete() 方法是 QuerySet 上的方法,但并不适用于 Manager 本身。这是一种保护机制,是为了避免意外地调用 Entry.objects.delete() 方法导致 所有的 记录被误删除。如果你确认要删除所有的对象,那么你必须显式地调用:
Entry.objects.all().delete()
五、编辑表格中的内容的涉及到的语法
编辑操作涉及到的语法 分析:
1、点击编辑,让跳转到另一个页面,拿到我点击的那一行
两种取id值的方式
方式一:
利用数据传参数(作为数据参数传过去了)
<a href="/edit/?book_id = {{book_obj.nid}}"></a> #相当于发了一个键值对
url里面就不用写匹配的路径了,
id = request.GET.get("book_id") #取值 方式二:
利用路径传参,得在url里面加上(\d+),就得给函数传个参数,无名分组从参数里面取值
<a href="/{{book_obj.nid}}"></a> 2、拿到id,然后在做筛选
id = request.GET.get("book_id")
book_obj = models.Book.objects.filter(nid=id) #拿到的是一个列表对象
注意:
1.取[0]就拿到对象了,,然后对象.属性就可以取到值了
2.用get,你取出来的数据必须只有一条的时候,,如果有多条用get就会报错,,,但是用get就不用加[0]了
book_obj = models.Book.objects.filter(nid=id)[0] 3、当点击编辑的时候怎么让input框里显示文本内容
value = "{{book_obj.title}}"
4、改完数据后重新提交
当提交的时候走action...../edit/}
隐藏一个input,
<input type="hidden" name = "book_id" value="{{book_obj.nid}}">
判断post的时候:
修改数据
方式一:save(这种方式效率是非常低的,不推荐使用,了解就行了)
修改的前提是先取(拿到要编辑的id值)
id = request.POST.get("book_id")
bk_obj = models.Book.objects.filter(nid=id)[0]
bk_obj.title = "hhhhhh" #这是写死了,不能都像这样写死了
bk_obj.save() 只要是用对象的这种都要.save
方式二:update
title = request.POST.get("title")
models.Book.objects.filter(nid=id).update(title=title,......)
跳转到index 如果是post请求的时候怎么找到id呢,
一、如果是数据传参:(也就是get请求的时候)
可以通过一个隐藏的input框,给这个框给一个name属性,value属性。通过request.POST.get("键"),,就可以得到id的值
二、如果是路径传参
可以通过传参的形式,当正则表达式写一个(\d+)的时候,就给函数传一个id,可通过这个id知道id.
Django框架之单表操作的更多相关文章
- Django模型层-单表操作
ORM介绍 MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的 ...
- Django day07 (二)单表操作
单表操作 -mysql数据库:settings里配置: DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME ...
- python 之 Django框架(orm单表查询、orm多表查询、聚合查询、分组查询、F查询、 Q查询、事务、Django ORM执行原生SQL)
12.329 orm单表查询 import os if __name__ == '__main__': # 指定当前py脚本需要加载的Django项目配置信息 os.environ.setdefaul ...
- Django【第6篇】:Django之ORM单表操作(增删改查)
django之数据库表的单表查询 一.添加表记录 对于单表有两种方式 # 添加数据的两种方式 # 方式一:实例化对象就是一条表记录 Frank_obj = models.Student(name =& ...
- Django图书管理系统(单表操作)
以下内容需要掌握: Python3 以及前端:HTML,CSS,jQuery,BootStrap,Django,JavaScript 开启Django新项目: 1,settings.py 数据库选择: ...
- Django(ORM单表操作)
默认使用sqllite数据库 修改为mysql数据库 创建数据库 在app models中编写创建数据库类 from django.db import models class Book(models ...
- Django框架ORM单表删除表记录_模型层
此方法依赖的表是之前创建的过的一张表 参考链接:https://www.cnblogs.com/apollo1616/p/9840354.html 1.删除方法就是delete(),它运行时立即删除对 ...
- Django框架ORM单表添加表记录_模型层
此方法依赖的表时之前创建的过的一张表 参考链接:https://www.cnblogs.com/apollo1616/p/9840354.html 方法1: # 语法 [变量] = [表名].obje ...
- web框架开发-Django模型层(1)之ORM简介和单表操作
ORM简介 不需要使用pymysql的硬编码方式,在py文件中写sql语句,提供更简便,更上层的接口,数据迁移方便(有转换的引擎,方便迁移到不同的数据库平台)…(很多优点),缺点,因为多了转换环节,效 ...
随机推荐
- windows7常用操作命令
1.打开命令行 按住Windows键加R键,打开运行窗口 2.打开笔记本 运行窗口中输入:notepad,点击确定或回车,打开记事本工具 主要作用:浏览网页时,看到一些有用的话,那么你是怎么把它记录下 ...
- 【实验一 】Spring Boot 集成 hibernate & JPA
转眼间,2018年的十二分之一都快过完了,忙于各类事情,博客也都快一个月没更新了.今天我们继续来学习Springboot对象持久化. 首先JPA是Java持久化API,定义了一系列对象持久化的标准,而 ...
- 第二百一十六节,jQuery EasyUI,Spinner(微调)组件
jQuery EasyUI,Spinner(微调)组件 学习要点: 1.加载方式 2.属性列表 3.事件列表 4.方法列表 本节课重点了解 EasyUI 中 Spinner(微调)组件的使用方法,这个 ...
- python 2个版本如何共存
我们在安装Python3(>=3.3)时,Python的安装包实际上在系统中安装了一个启动器py.exe,默认放置在文件夹C:\Windows\下面.这个启动器允许我们指定使用Python2还是 ...
- ar0331
aptina公司出品 分三个文档:ar0331_ds.pdf 数据表ar0331_dg.pdf 开发指导ar0331_rr_d.pdf 相关寄存器 色调映射(Tone Mapping):http:// ...
- kvm和qemu的关系
KVM (Kernel Virtual Machine) is a Linux kernel module that allows a user space program to utilize th ...
- Sql server不同数据类型间拼接(+)
)+'m' 输出 4m 若 +'m' 输出:在将 varchar 值 'm' 转换成数据类型 int 时失败.
- hdu 4539(状压dp)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4539 思路:跟poj1185简直就是如出一辙! #include<iostream> #i ...
- Laravel5.1 分页展示
Laravel为我们提供了一套分页的逻辑,我们无需自己实现分页逻辑,只需要执行几个简单的方法就能实现漂亮的分页. 1 simplePaginate 这是一种只显示上一页下一页的样式分页,我们来看看怎么 ...
- Laravel5.1 模型 --多态关联
什么是多态关联? 一个例子你就明白了:好比如说评论 它可以属于视频类 也可以属于文章类,当有个需求是 从评论表中取到视频类的数据,这就需要用到多态关联了. 简单的一句话总结:一张表对应两张表. 1 实 ...