(原创)Stanford Machine Learning (by Andrew NG) --- (week 8) Clustering & Dimensionality Reduction
本周主要介绍了聚类算法和特征降维方法,聚类算法包括K-means的相关概念、优化目标、聚类中心等内容;特征降维包括降维的缘由、算法描述、压缩重建等内容。coursera上面Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml
(一)K-means聚类算法
Input data:未标记的数据集,类别数K;
算法流程:
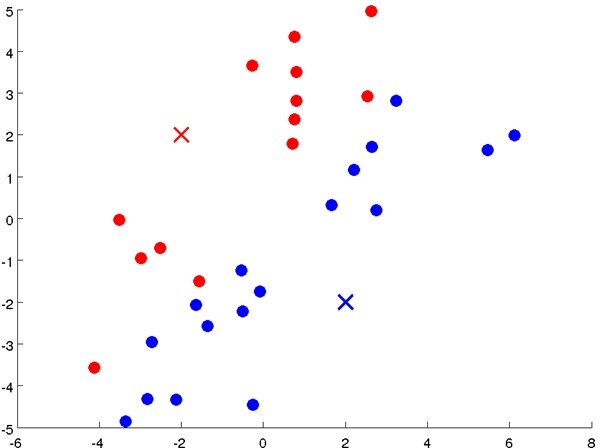
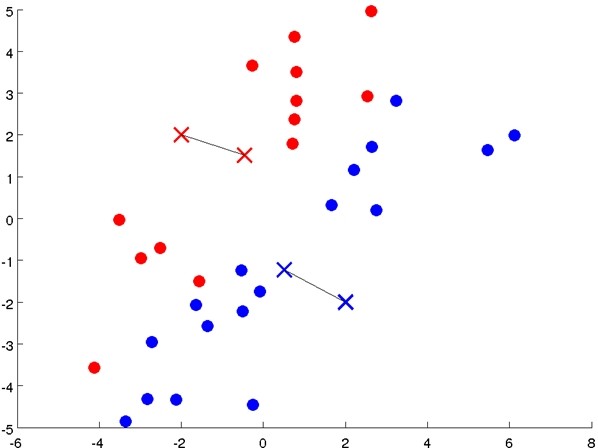
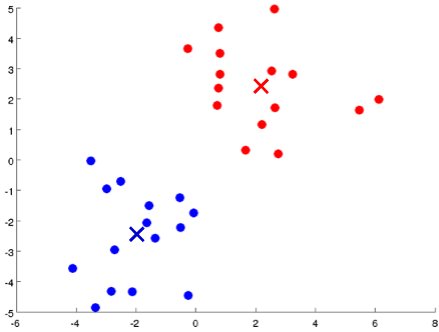
- 首先随机选择K个点,作为初始聚类中心(cluster centroids);
- 计算数据集中每个数据与聚类中心的距离,将其划分到与其最近的中心点那类;
- 重新计算每个类的平均值,并将其作为新的聚类中心;
- 重复步骤2-4直至聚类中心不再变化;
 |
 |
 |
Repeat {
for i = 1 to m
c(i):= index (from 1 to K) of cluster centroid closest to x(i)
for k = 1 to K
μk:= average (mean) of points assigned to cluster k}
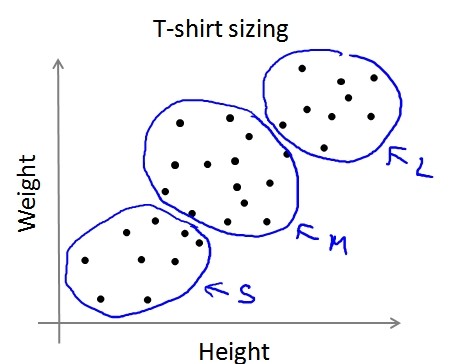
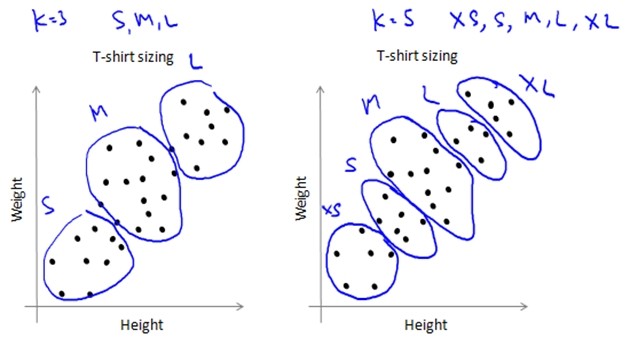
PS:K-means算法也可以用于在没有明显区分的情况下将数据分组,如T-shirt的尺寸问题。
优化目标(Optimization objective)
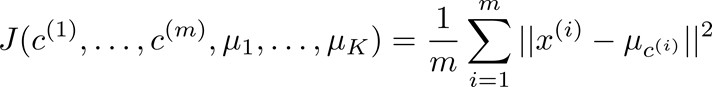
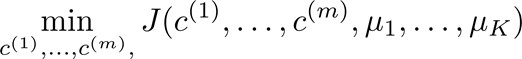

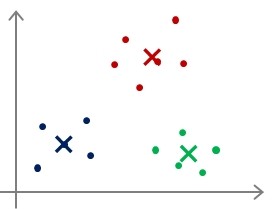
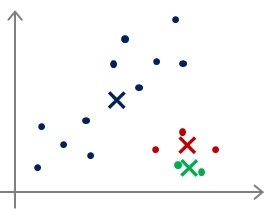
聚类中心初始化(Random initialization)
 |
 |
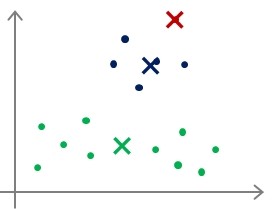 |
- 选择K<m,即聚类中心点的个数要小于所有训练集的数量;
- 随机选择K个训练实例,然后令K个聚类中心分别与这K个训练实例相等;
- 多次运行K-means算法,每次都进行随机初始化;
- 计算代价函数,选择代价最小的结果。
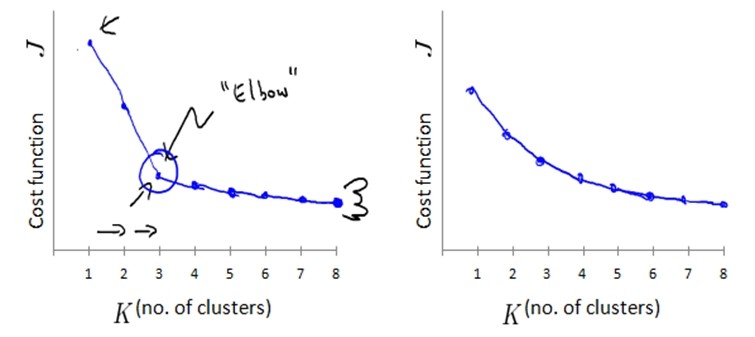
聚类数选择(Choosing the number of clusters)
(二)降维(Dimensionality Reduction)
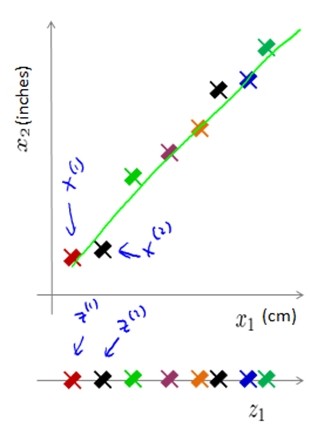
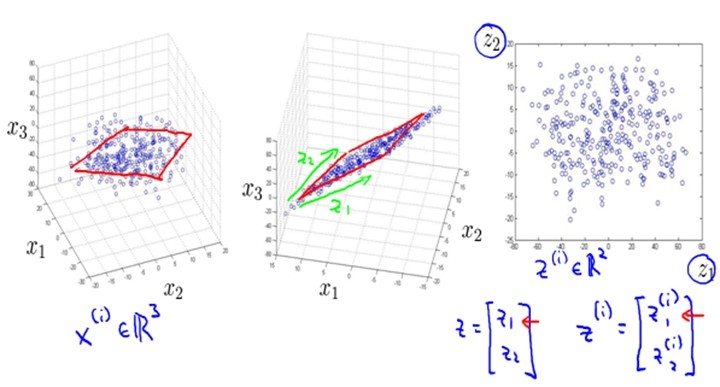
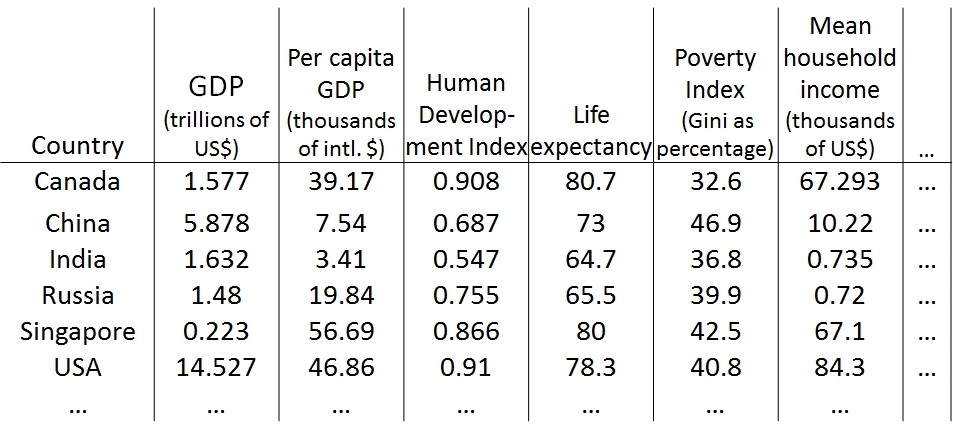
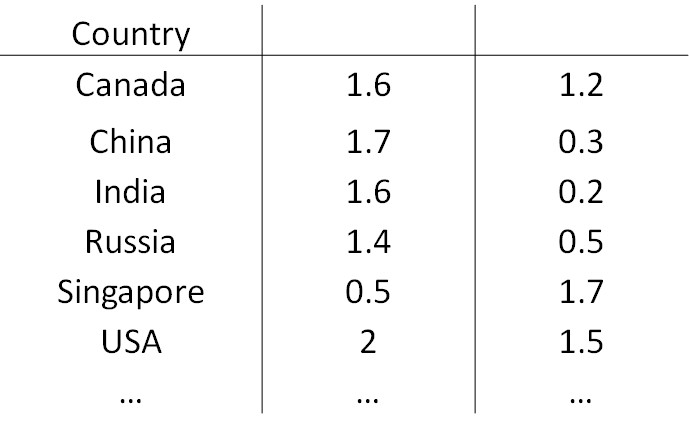
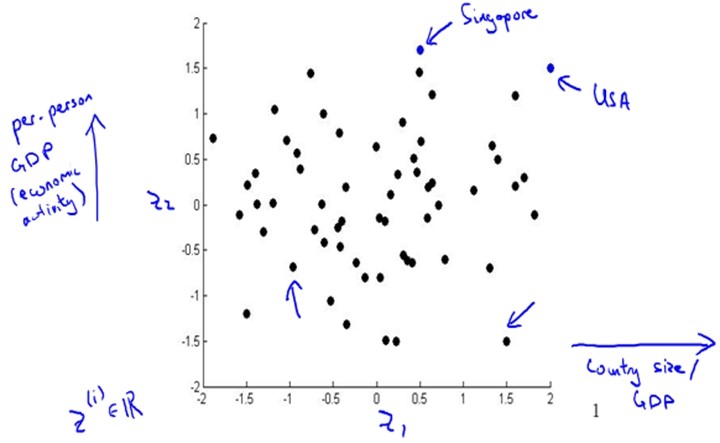
数据可视化(Data Visualization)
 |
 |
PCA(Principal Component Analysis )
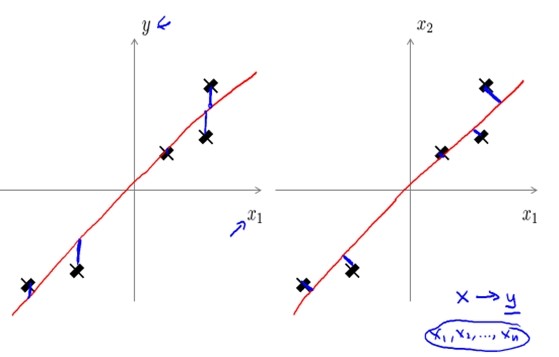
| PCA | Linear Regression |
| 投影误差最小(右图) | 预测误差最小(左图) |
| 无预测任务 | 需预测结果 |
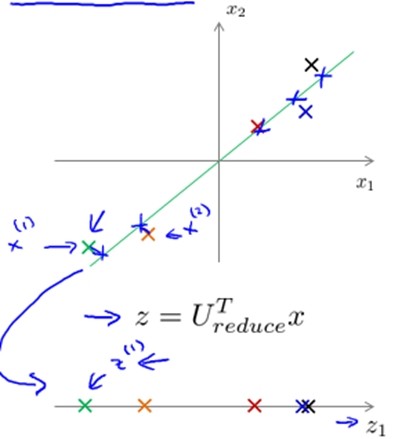
PCA算法
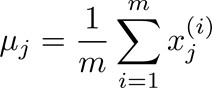
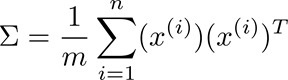
[U,S,V] = svd(Sigma);
其中U是最小投影误差的方向向量构成的矩阵。
Ureduce = U(:,1:k);
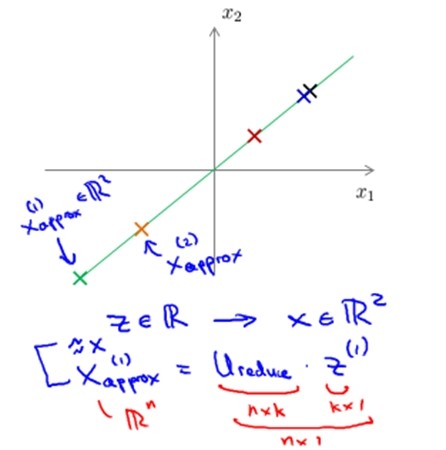
z = UTreduce *x;
压缩重建& k的选择
1. 压缩重建:
- 通过z = UTreduce *x计算特征向量z;其中x是n*1维,所以z是k*1维。
- 通过xapprox = UTreduce * z来近似得到原来的特征向量x;其中z是k*1。所以xapprox 是n*1维。
 |
 |
从上面的分析中可以看出,我们希望在误差尽量小的情况下k值尽量小,那么怎样选择k呢?
2. 方法一:
- 在k = 1时,使用PCA算法;
- 计算Ureduce,z(1),z(2),...,z(m),x(1)approx ,...,x(m)approx
- 检验是否?
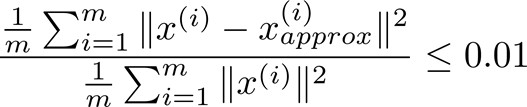 若否,则继续尝试k=2,k=3,.......
若否,则继续尝试k=2,k=3,.......
3. 方法二:
在Octave中使用svd函数时,[U,S,V] = svd(Sigma);其中的S是n*n的矩阵,只有对角线上有值,如下所示:
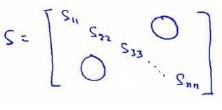
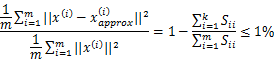 ≡
≡ 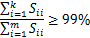
使用PCA的优势及应用
假如我们的输入特征向量是10000维,在使用PCA后可以降至1000维,这样可以加速训练过程,并减少内存。
PS:对于测试集和交叉验证集,同样可以使用训练集得到的Ureduce.由于我们将特征空间由n维减少到了k维,有人会认为这样做会避免过拟合,这样做也许有效,但不是很好的避免过拟合的方法。若要避免过拟合,还是应尝试正则化的方法。
HOMEWORK
好了,既然看完了视频课程,就来做一下作业吧,下面是Clustering & Dimensionality Reduction部分作业的核心代码:
1. findClosestCentroids
m = size(X,1);
dis_vec = zeros(K,1);
for i = 1:m
for j = 1:K
dis_vec(j) = sum((X(i,:)-centroids(j,:)).^2);
end
[v,k] = min(dis_vec);
idx(i) = k;
end
2. computeCentroids
tp_sum = zeros(K, n);
tp_num = zeros(K, 1);
for i = 1:m
cy = idx(i);
tp_sum(cy,:) = tp_sum(cy,:) + X(i,:);
tp_num(cy) += 1;
end
for j = 1:K
centroids(j,:) = tp_sum(j,:)/tp_num(j);
end
3. pca.m
sigma = (1/m)*X'*X;
[U,S,V] = svd(sigma);
4. projectData.m
Z = X*U(:,1:K);
5. recoverData.m
X_rec = Z* U(:,1:K)';
(原创)Stanford Machine Learning (by Andrew NG) --- (week 8) Clustering & Dimensionality Reduction的更多相关文章
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 10) Large Scale Machine Learning & Application Example
本栏目来源于Andrew NG老师讲解的Machine Learning课程,主要介绍大规模机器学习以及其应用.包括随机梯度下降法.维批量梯度下降法.梯度下降法的收敛.在线学习.map reduce以 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 7) Support Vector Machines
本栏目内容来源于Andrew NG老师讲解的SVM部分,包括SVM的优化目标.最大判定边界.核函数.SVM使用方法.多分类问题等,Machine learning课程地址为:https://www.c ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 9) Anomaly Detection&Recommender Systems
这部分内容来源于Andrew NG老师讲解的 machine learning课程,包括异常检测算法以及推荐系统设计.异常检测是一个非监督学习算法,用于发现系统中的异常数据.推荐系统在生活中也是随处可 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 4) Neural Networks Representation
Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 神经网络一直被认为是比较难懂的问题,NG将神经网络部分的课程分为了 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Linear Regression
Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 在Linear Regression部分出现了一些新的名词,这些名 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 3) Logistic Regression & Regularization
coursera上面Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 我曾经使用Logistic Regressio ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Introduction
最近学习了coursera上面Andrew NG的Machine learning课程,课程地址为:https://www.coursera.org/course/ml 在Introduction部分 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 5) Neural Networks Learning
本栏目内容来自Andrew NG老师的公开课:https://class.coursera.org/ml/class/index 一般而言, 人工神经网络与经典计算方法相比并非优越, 只有当常规方法解 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 6) Advice for Applying Machine Learning & Machine Learning System Design
(1) Advice for applying machine learning Deciding what to try next 现在我们已学习了线性回归.逻辑回归.神经网络等机器学习算法,接下来 ...
随机推荐
- $.on方法与$.click()的区别
1.$.on("click") 支持动态元素绑定事件,该事件是绑定到document上,只要符合条件的元素即可绑定事件,同时$.on()可以绑定多个事件 on方法 on(event ...
- 3.FireDAC组件快照
TFDManager 连接定义和Connect连接管理 TFDConnection 数据库连接组件,支持三种连接方式:1.持久定义(有一个唯一名称和一个配置文件,可以由FDManager管理) 例: ...
- Win10打开照片提示“无效的注册表值”解决方法
1.点开开始菜单,右键单击,选择“以管理员运行”[键盘win键+R]输入PowerShell. 2.输入Get-AppxPackage *photo* | Remove-AppxPackage后回车. ...
- WiderFace标注格式转PASCAL VOC2007标注格式
#coding=utf-8 import os import cv2 from xml.dom.minidom import Document def create_xml(boxes_dict,ta ...
- Android ADT插件更新后程序运行时抛出java.lang.VerifyError异常解决办法
当我把Eclipse中的 Android ADT插件从21.1.0更新到22.0.1之后,安装后运行程序抛出java.lang.VerifyError异常. 经过调查,终于找到了一个有效的解决办法: ...
- 虚拟存储管理中几种缺页中断算法(最佳置换法OPT)
缺页中断就是要访问的页不在主存,需要操作系统将其调入主存后再进行访问. 在进行内存访问时,若所访问的页已在主存,则称此次访问成功: 若所访问的页不在主存,则称此次访问失败,并产生缺页中断. 最佳置换法 ...
- mac date命令
usage: date [-jnu] [-d dst] [-r seconds] [-t west] [-v[+|-]val[ymwdHMS]] ... [-f fmt date | [[[mm]dd ...
- 封装ajax方法
function ajaxRequest(type, url, data, callback, loading, cache) { var ajaxConfig = { url: '', data: ...
- 在JAVASCRIPT中构建一个复杂的对象,并用JSON进行转换
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- GT-----FAQ整理
1.pss0,pss1,这里的序号0和1是什么意思? 说明选的目标调试 App 有至少 2 个进程,先启动的那个进程的 pss 值会被加后缀 0,后启动那个会被加后 缀 1.所有参数前面的“ ...