Scrapy框架-scrapy框架快速入门
1.安装和文档
- 安装:通过pip install scrapy即可安装。
- Scrapy官方文档:http://doc.scrapy.org/en/latest
- Scrapy中文文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
- 注意事项:
在ubuntu上安装scrapy之前,需要先安装以下依赖:
sudo apt-get install python3-dev build-essential python3-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev,然后再通过pip install scrapy安装。
如果在windows系统下,提示这个错误ModuleNotFoundError: No module named 'win32api',那么使用以下命令可以解决:pip install pypiwin32。
2.快速入门
2.1 创建项目
要使用Scrapy框架创建项目,需要通过命令来创建。首先进入到你想把这个项目存放的目录。
然后使用以下命令创建:scrapy startproject [项目名称]
2.2 目录结构介绍
# 创建一个项目步骤
# 2.1.1 在D盘创建一个文件夹`spiders_code`
# 2.1.2 打开cmd终端,cd到刚才创建的文件夹`spiders_code`
# 2.1.3 执行命令`D:\spiders_code> scrapy startproject qsbk`创建项目
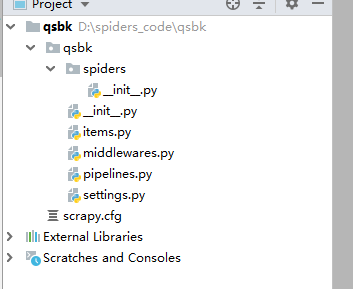
以下介绍下主要文件的作用:
- items.py:用来存放爬虫爬取下来数据的模型。
- middlewares.py:用来存放各种中间件的文件。
- pipelines.py:用来将items的模型存储到本地磁盘中。
- settings.py:本爬虫的一些配置信息(比如请求头、多久发送一次请求、ip代理池等)。
- scrapy.cfg:项目的配置文件。
- spiders包:以后所有的爬虫,都是存放到这个里面
3.使用Scrapy框架爬取糗事百科段子
3.1 使用命令创建一个爬虫
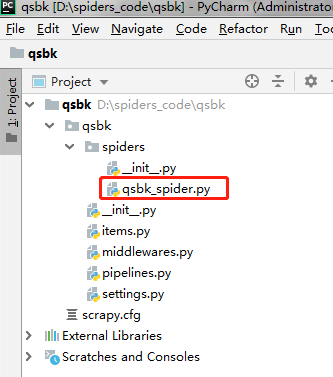
D:\spiders_code\qsbk>scrapy genspider qsbk_spider "qiushibaike.com"

创建了一个名字叫做qsbk的爬虫,并且能爬取的网页只会限制在qiushibaike.com这个域名下。
创建爬虫后,再看下目录结构变化
3.2爬虫代码解析
import scrapy
class QsbkSpider(scrapy.Spider):
name = 'qsbk'
allowed_domains = ['qiushibaike.com']
start_urls = ['http://qiushibaike.com/']
def parse(self, response):
pass
其实这些代码我们完全可以自己手动去写,而不用命令。只不过是不用命令,自己写这些代码比较麻烦。
要创建一个Spider,那么必须自定义一个类,继承自scrapy.Spider,然后在这个类中定义三个属性和一个方法。
- name:这个爬虫的名字,名字必须是唯一的。
- allow_domains:允许的域名。爬虫只会爬取这个域名下的网页,其他不是这个域名下的网页会被自动忽略。
- start_urls:爬虫从这个变量中的url开始。
- parse:引擎会把下载器下载回来的数据扔给爬虫解析,爬虫再把数据传给这个parse方法。这个是个固定的写法。这个方法的作用有两个,第一个是提取想要的数据。第二个是生成下一个请求的url。
3.3 修改settings.py代码
在做一个爬虫之前,一定要记得修改setttings.py中的设置。两个地方是强烈建议设置的。
- ROBOTSTXT_OBEY设置为False。默认是True。即遵守机器协议,那么在爬虫的时候,scrapy首先去找robots.txt文件,如果没有找到。则直接停止爬取。
- DEFAULT_REQUEST_HEADERS添加User-Agent。这个也是告诉服务器,我这个请求是一个正常的请求,不是一个爬虫。
3.4 完成的爬虫代码
# 3.4.1 爬虫部分代码
import scrapy
from abcspider.items import QsbkItem
class QsbkSpider(scrapy.Spider):
name = 'qsbk'
allowed_domains = ['qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
outerbox = response.xpath("//div[@id='content-left']/div")
items = []
for box in outerbox:
author = box.xpath(".//div[contains(@class,'author')]//h2/text()").extract_first().strip()
content = box.xpath(".//div[@class='content']/span/text()").extract_first().strip()
item = QsbkItem()
item["author"] = author
item["content"] = content
items.append(item)
return items
# 3.4.2 items.py部分代码
import scrapy
class QsbkItem(scrapy.Item):
author = scrapy.Field()
content = scrapy.Field()
# 3.4.3 pipeline部分代码
import json
class AbcspiderPipeline(object):
def __init__(self):
self.items = []
def process_item(self, item, spider):
self.items.append(dict(item))
print("="*40)
return item
def close_spider(self,spider):
with open('qsbk.json','w',encoding='utf-8') as fp:
json.dump(self.items,fp,ensure_ascii=False)
3.5 运行scrapy项目
运行scrapy项目。需要在终端,进入项目所在的路径,然后scrapy crawl [爬虫名字]即可运行指定的爬虫。如果不想每次都在命令行中运行,那么可以把这个命令写在一个文件中。以后就在pycharm中执行运行这个文件就可以了。
比如现在新创建一个文件叫做start.py,然后在这个文件中填入以下代码:
from scrapy import cmdline
cmdline.execute("scrapy crawl qsbk_spider".split())
Scrapy框架-scrapy框架快速入门的更多相关文章
- 实体框架(Entity Framework)快速入门--实例篇
在上一篇 <实体框架(Entity Framework)快速入门> 中我们简单了解的EF的定义和大体的情况,我们通过一步一步的做一个简单的实际例子来让大家对EF使用有个简单印象,看操作步骤 ...
- Keras深度学习框架安装及快速入门
1.下载安装Keras 如果你是安装的Anaconda组合套件,可以直接在Prompt上执行安装命令:pip install keras 注意:最下面为Successfully...表示安装成功! 2 ...
- uni-app跨平台框架介绍和快速入门
前言: 首先今天主要介绍的是一个多平台的前端框架uni-app,关于多平台的前端框架网上有很多成熟的解决方案比如说Taro,React Native,Flutter等这些都是一些非常优秀的前端跨平台的 ...
- Quartz.NET开源作业调度框架系列(一):快速入门step by step
Quartz.NET是一个被广泛使用的开源作业调度框架 , 由于是用C#语言创建,可方便的用于winform和asp.net应用程序中.Quartz.NET提供了巨大的灵活性但又兼具简单性.开发人员可 ...
- Quartz.NET开源作业调度框架系列(一):快速入门step by step-转
Quartz.NET是一个被广泛使用的开源作业调度框架 , 由于是用C#语言创建,可方便的用于winform和asp.net应用程序中.Quartz.NET提供了巨大的灵活性但又兼具简单性.开发人员可 ...
- Selenium框架切换-----Selenium快速入门(七)
上一篇说了窗口的切换,本篇说说框架的切换. 切换框架:是指切换html中的iframe标签元素或者frame标签元素,注意,并不包括frameset 以下是常用的方法: 方法 说明 WebDriver ...
- 实体框架(Entity Framework)快速入门
实体 框架 (Entity Framework )简介 实体框架Entity Framework 是 ADO .NET 中的一组支持 开发 面向数据的软件应用程序的技术.是微软的一个ORM框架. OR ...
- Python中定时任务框架APScheduler的快速入门指南
前言 大家应该都知道在编程语言中,定时任务是常用的一种调度形式,在Python中也涌现了非常多的调度模块,本文将简要介绍APScheduler的基本使用方法. 一.APScheduler介绍 APSc ...
- 面向对象存储框架:Obase快速入门
在项目中完成对象建模后,可以使用Obase来进行对象的管理(例如对象持久化),本篇教程将创建一个.NET Core控制台应用,来展示Obase的配置和对象的增删改查操作.本篇教程旨在指引简单入门. 本 ...
- 快速入门系列--WebAPI--03框架你值得拥有
接下来进入的是俺在ASP.NET学习中最重要的WebAPI部分,在现在流行的互联网场景下,WebAPI可以和HTML5.单页应用程序SPA等技术和理念很好的结合在一起.所谓ASP.NET WebAPI ...
随机推荐
- Java中数据库连接的一些方法资料汇总
Java中Connection方法笔记 http://www.cnblogs.com/bincoding/p/6554954.html ResultSet详解(转) https://www.cnbl ...
- Hive分析窗体函数之SUM,AVG,MIN和MAX
行 AVG(pnum) OVER(PARTITION BYpolno ORDER BY createtime ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOW ...
- flask os.environ 的作用
使用环境变量取值, 是为了增强系统的适应性, 在某些场景下, 设置环境变量比较方便. 假如, 你有一套代码, 部署在不同的系统中, 恰好这些系统有权限且很容易地设置环境变量, 那么, 这时候通过环境变 ...
- pl/sql 实例精解 06
1. 简单循环 1: LOOP 2: statement1; 3: statement2; 4: EXIT WHEN condition; 5: END LOOP; 6: statement3; 也可 ...
- python 的简单抓取图片
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片鼠标右键的 ...
- datagrid后台分页js
$(function () { gridbind(); bindData(); }); //表格绑定function gridbind() { $('#dg').datagrid({ title: ' ...
- head管理EC下载,配置启动
参考文档:https://blog.csdn.net/yx1214442120/article/details/55102298
- URL编码,空格和+
下表中列出了一些URL特殊符号及编码 + URL 中+号表示空格 %2B 空格 URL中的空格可以用+号或者编码 %20 / 分隔目录和子目录 %2F ? 分隔实际的URL和参数 %3F % 指定特殊 ...
- (转)Java锁、自旋锁、CAS机制
转自:http://www.jb51.net/article/55381.htm 转自:http://blog.csdn.net/aesop_wubo/article/details/7537278 ...
- 蓝桥杯 第三届C/C++预赛真题(3) 比酒量(数学题)
有一群海盗(不多于20人),在船上比拼酒量.过程如下:打开一瓶酒,所有在场的人平分喝下,有几个人倒下了.再打开一瓶酒平分,又有倒下的,再次重复...... 直到开了第4瓶酒,坐着的已经所剩无几,海盗船 ...