深度学习图像分割——U-net网络
写在前面:
一直没有整理的习惯,导致很多东西会有所遗忘,遗漏。借着这个机会,养成一个习惯。
对现有东西做一个整理、记录,对新事物去探索、分享。
因此博客主要内容为我做过的,所学的整理记录以及新的算法、网络框架的学习。基本上是深度学习、机器学习方面的东西。
第一篇首先是深度学习图像分割——U-net网络方面的内容。后续将会尽可能系统的学习深度学习并且记录。
更新频率为每周大于等于一篇。
深度学习的图像分割来源于分类,分割即为对像素所属区域的一个分类。
有别于机器学习中使用聚类进行的图像分割,深度学习中的图像分割是个有监督问题,需要有分割金标准(ground truth)作为训练的标签。
在图像分割的过程中,网络的损失函数一般使用Dice系数作为损失函数,Dice系数简单的讲就是你的分割结果与分割金标准之间像素重合个数与总面积的比值。
【https://blog.csdn.net/liangdong2014/article/details/80573234,医学图像分割中常用的度量指标】
U-net参考文献:
U-net: Convolutional networks for biomedical image segmentation.
https://arxiv.org/pdf/1505.04597.pdf
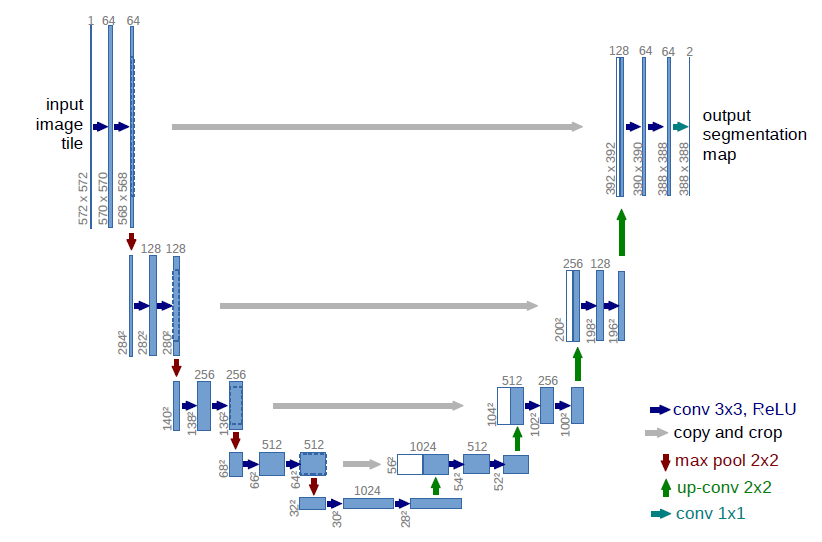
U-net网络结构
U-net网络是一个基于CNN的图像分割网络,主要用于医学图像分割上,网络最初提出时是用于细胞壁的分割,之后在肺结节检测以及眼底视网膜上的血管提取等方面都有着出色的表现。
最初的U-net网络结构如上图所示,主要由卷积层、最大池化层(下采样)、反卷积层(上采样)以及ReLU非线性激活函数组成。整个网络的过程具体如下:
最大池化层,下采样过程:
假设最初输入的图像大小为:572X572的灰度图,经过2次3X3x64(64个卷积核,得到64个特征图)的卷积核进行卷积操作变为568X568x64大小,
然后进行2x2的最大池化操作变为248x248x64。(注:3X3卷积之后跟随有ReLU非线性变换为了描述方便所以没写出来)。
按照上述过程重复进行4次,即进行 (3x3卷积+2x2池化) x 4次,在每进行一次池化之后的第一个3X3卷积操作,3X3卷积核数量成倍增加。
达到最底层时即第4次最大池化之后,图像变为32x32x512大小,然后再进行2次的3x3x1024的卷积操作,最后变化为28x28x1024的大小。
反卷积层,上采样过程:
此时图像的大小为28x28x1024,首先进行2X2的反卷积操作使得图像变化为56X56X512大小,然后对对应最大池化层之前的图像的复制和剪裁(copy and crop),
与反卷积得到的图像拼接起来得到56x56x1024大小的图像,然后再进行3x3x512的卷积操作。
按照上述过程重复进行4次,即进行(2x2反卷积+3x3卷积)x4次,在每进行一次拼接之后的第一个3x3卷积操作,3X3卷积核数量成倍减少。
达到最上层时即第4次反卷积之后,图像变为392X392X64的大小,进行复制和剪裁然后拼接得到392X392X128的大小,然后再进行两次3X3X64的卷积操作。
得到388X388X64大小的图像,最后再进行一次1X1X2的卷积操作。
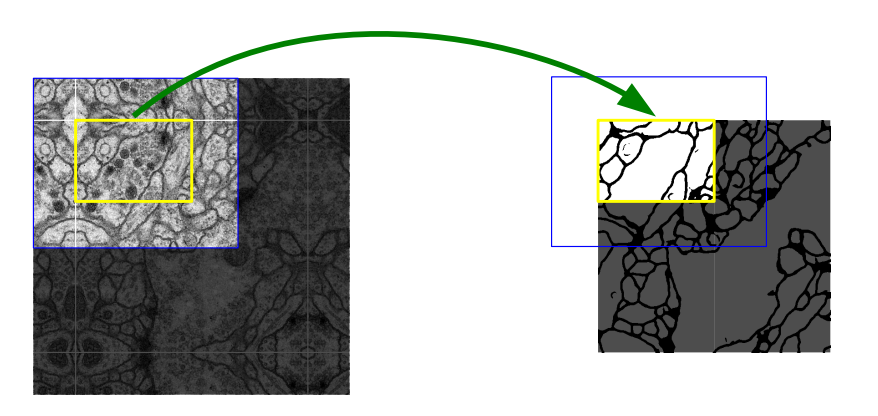
然后得到的结果大概是这样的(下图),需要通过黄色区域的分割结果去推断蓝色区域的分割结果,当然在实际应用中基本上都是选择保持图像大小不变的进行卷积(卷积后周围用0填充)。
【关于卷积、反卷积相关的内容可以参考:https://blog.csdn.net/qq_38906523/article/details/80520950】
讲完了具体怎么做的,再来讲讲U-net的优缺点,可以看到网络结构中没有涉及到任何的全连接层,同时在上采样过程中用到了下采样的结果,
使得在深层的卷积中能够有浅层的简单特征,使得卷积的输入更加丰富,自然得到的结果也更加能够反映图像的原始信息。
(CNN卷积网络,在浅层的卷积得到的是图像的简单特征,深层的卷积得到的是反映该图像的复杂特征)
像上面说的那样,U-net网络的结构主要是对RPN(Region Proposal Network)结构的一个发展,它在靠近输入的较浅的层提取的是相对小的尺度上的信息(简单特征),
靠近输出的较深的层提取的是相对大的尺度上的信息(复杂特征),通过加入shortcut(直接将原始信息不进行任何操作与后续的结果合并拼接)整合多尺度信息进行判断。
但是U-net网络结构仅在单一尺度上进行预测,不能很好处理尺寸变化的问题。
【天池医疗第一名队伍:https://tianchi.aliyun.com/forum/new_articleDetail.html?spm=5176.8366600.0.0.6021311f0WILtQ&raceId=231601&postsId=2947】
因此对于该网络的改进,就我而言,尝试过:1、在最后一层(最后一次下采样之后,第一次上采样之前)加入一个全连接层,目的是增加一个交叉熵损失函数,为了加入额外的信息(比如某张图是是否为某一类的东西)
2、对于每一次的上采样都进行一次输出(预测),将得到的结果进行一个融合(类似于FPN网络(feature pyramid networks),当然这个网络里有其他的东西)
3、加入BN(Batch Normalization)层
改进的结果自然是对于特定要处理的问题有一些帮助。
最后就是相应的代码,由于U-net网络结构较为简单,所以一般使用Keras去写的会比较多,我也是用Keras写的。后续整理了之后将代码的链接贴上。
深度学习图像分割——U-net网络的更多相关文章
- (转)零基础入门深度学习(6) - 长短时记忆网络(LSTM)
无论即将到来的是大数据时代还是人工智能时代,亦或是传统行业使用人工智能在云上处理大数据的时代,作为一个有理想有追求的程序员,不懂深度学习(Deep Learning)这个超热的技术,会不会感觉马上就o ...
- 深度学习——手动实现残差网络ResNet 辛普森一家人物识别
深度学习--手动实现残差网络 辛普森一家人物识别 目标 通过深度学习,训练模型识别辛普森一家人动画中的14个角色 最终实现92%-94%的识别准确率. 数据 ResNet介绍 论文地址 https:/ ...
- 【神经网络与深度学习】生成式对抗网络GAN研究进展(五)——Deep Convolutional Generative Adversarial Nerworks,DCGAN
[前言] 本文首先介绍生成式模型,然后着重梳理生成式模型(Generative Models)中生成对抗网络(Generative Adversarial Network)的研究与发展.作者 ...
- PYTHON深度学习6.2RNN循环网络
#简单的循环网络 #-*-coding:utf-8 -*- from keras.datasets import imdbfrom keras.preprocessing import sequenc ...
- 吴恩达深度学习笔记1-神经网络的编程基础(Basics of Neural Network programming)
一:二分类(Binary Classification) 逻辑回归是一个用于二分类(binary classification)的算法.在二分类问题中,我们的目标就是习得一个分类器,它以对象的特征向量 ...
- 零基础入门深度学习(6) - 长短时记忆网络(LSTM)
代码: def forward(self, x): ''' 根据式1-式6进行前向计算 ''' self.times += 1 # 遗忘门 fg = self.calc_gate(x, self.Wf ...
- <深度学习优化策略-3> 深度学习网络加速器Weight Normalization_WN
前面我们学习过深度学习中用于加速网络训练.提升网络泛化能力的两种策略:Batch Normalization(Batch Normalization)和Layer Normalization(LN). ...
- CNCC2017中的深度学习与跨媒体智能
CNCC2017中的深度学习与跨媒体智能 转载请注明作者:梦里茶 目录 机器学习与跨媒体智能 传统方法与深度学习 图像分割 小数据集下的深度学习 语音前沿技术 生成模型 基于贝叶斯的视觉信息编解码 珠 ...
- 人工智能深度学习Caffe框架介绍,优秀的深度学习架构
人工智能深度学习Caffe框架介绍,优秀的深度学习架构 在深度学习领域,Caffe框架是人们无法绕过的一座山.这不仅是因为它无论在结构.性能上,还是在代码质量上,都称得上一款十分出色的开源框架.更重要 ...
随机推荐
- 史上最简单的SpringCloud教程 | 第十二篇: 断路器监控(Hystrix Dashboard)(Finchley版本)
转载请标明出处: 原文首发于:https://www.fangzhipeng.com/springcloud/2018/08/30/sc-f12-dash/ 本文出自方志朋的博客 在我的第四篇文章断路 ...
- Java中的IO流(三)
上一篇<Java中的IO流(二)>把学习Java的字符流以及转换流作了一下记录,从本篇开始将把IO流中对文件或文件夹操作的对象File类的学习进行一下记录. 一,File类的构造函数及字段 ...
- iOS:动画(18-10-15更)
目录 1.UIView Animation 1-1.UIView Animation(基本使用) 1-2.UIView Animation(转场动画) 2.CATransaction(Layer版的U ...
- 集合栈计算机(The SetStack Computer, ACM/ICPC NWERC 2006,Uva12096)
集合栈计算机(The SetStack Computer, ACM/ICPC NWERC 2006,Uva12096) 题目描述 有一个专门为了集合运算而设计的"集合栈"计算机.该 ...
- lower_case_table_name
linux上是区分表名大小写的,但是可以通过 my.cnf文件中设置不区分! 1.找到my.cnf文件的所在地. find / -name my.cnf 找到这个文件的位置.我服务器上的位置是 /us ...
- RAC初体验(环境搭建)
实施阶段: 1.主机配置 2.安装Clusterware 3.安装Oracle Database 4.配置Listener 5.创建ASM 6.创建Database 一.主机配置 1.网络设置 I ...
- 关于CoreLocation定位服务的简单使用
在我们发微博,发表空间内容,以及在朋友圈发表动态的时候,会发现有一个位置信息的控件.iOS中是如何定位我们的位置信息的呢?基于此写一个小Demo,供大家参考使用. 在iOS中,用于定位时需要我们导入以 ...
- JS this总结
JS中一切皆对象,this关键字出现在对象定义时的成员(属性和方法)里,因此this指向的是一个JS对象,这个JS对象具体是哪一个的确定是在运行时确定的. 非严格模式: 1.作为对象成员:对象调用对象 ...
- Jquery无刷新上传单个文件
function ajax_photo(photo_type){ $(document).on('change','#sitephoto',function(){ ...
- python应用:爬虫框架Scrapy系统学习第四篇——scrapy爬取笔趣阁小说
使用cmd创建一个scrapy项目: scrapy startproject project_name (project_name 必须以字母开头,只能包含字母.数字以及下划线<undersco ...