时序数据库连载系列: 时序数据库一哥InfluxDB之存储机制解析
InfluxDB 的存储机制解析
本文介绍了InfluxDB对于时序数据的存储/索引的设计。由于InfluxDB的集群版已在0.12版就不再开源,因此如无特殊说明,本文的介绍对象都是指 InfluxDB 单机版
1. InfluxDB 的存储引擎演进
尽管InfluxDB自发布以来历时三年多,其存储引擎的技术架构已经做过几次重大的改动, 以下将简要介绍一下InfluxDB的存储引擎演进的过程。
1.1 演进简史
版本0.9.0之前
**基于 LevelDB的LSMTree方案**
版本0.9.0~0.9.4
**基于BoltDB的mmap COW B+tree方案**
版本0.9.5~1.2
**基于自研的 WAL + TSMFile 方案**(TSMFile方案是0.9.6版本正式启用,0.9.5只是提供了原型)
版本1.3~至今
**基于自研的 WAL + TSMFile + TSIFile 方案**
1.2 演进的考量
InfluxDB的存储引擎先后尝试过包括LevelDB, BoltDB在内的多种方案。但是对于InfluxDB的下述诉求终不能完美地支持:
时序数据在降采样后会存在大批量的数据删除
=> *LevelDB的LSMTree删除代价过高*单机环境存放大量数据时不能占用过多文件句柄
=> *LevelDB会随着时间增长产生大量小文件*数据存储需要热备份
=> *LevelDB只能冷备*大数据场景下写吞吐量要跟得上
=> *BoltDB的B+tree写操作吞吐量成瓶颈*存储需具备良好的压缩性能
=> *BoltDB不支持压缩*
此外,出于技术栈的一致性以及部署的简易性考虑(面向容器部署),InfluxDB团队希望存储引擎 与 其上层的TSDB引擎一样都是用GO编写,因此潜在的RocksDB选项被排除
基于上述痛点,InfluxDB团队决定自己做一个存储引擎的实现。
2 InfluxDB的数据模型
在解析InfluxDB的存储引擎之前,先回顾一下InfluxDB中的数据模型。
在InfluxDB中,时序数据支持多值模型,它的一条典型的时间点数据如下所示:
图 1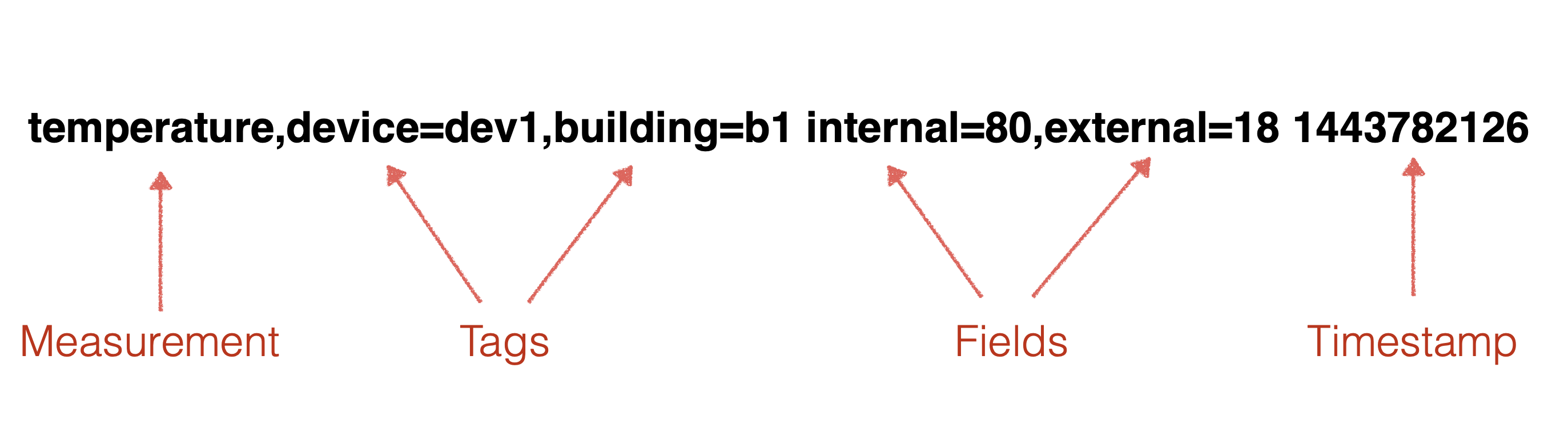
measurement:
指标对象,也即一个数据源对象。每个measurement可以拥有一个或多个指标值,也即下文所述的**field**。在实际运用中,可以把一个现实中被检测的对象(如:“cpu”)定义为一个measurementtags:
概念等同于大多数时序数据库中的tags, 通常通过tags可以唯一标示数据源。每个tag的key和value必须都是字符串。field:
数据源记录的具体指标值。每一种指标被称作一个“field”,指标值就是 “field”对应的“value”timestamp:
数据的时间戳。在InfluxDB中,理论上时间戳可以精确到 **纳秒**(ns)级别
此外,在InfluxDB中,measurement的概念之上还有一个对标传统DBMS的 Database 的概念,逻辑上每个Database下面可以有多个measurement。在单机版的InfluxDB实现中,每个Database实际对应了一个文件系统的 目录。
2.1 Serieskey的概念
InfluxDB中的SeriesKey的概念就是通常在时序数据库领域被称为 时间线 的概念, 一个SeriesKey在内存中的表示即为下述字符串(逗号和空格被转义)的 字节数组(github.com/influxdata/influxdb/model#MakeKey())
{measurement名}{tagK1}={tagV1},{tagK2}={tagV2},...
其中,SeriesKey的长度不能超过 65535 字节
2.2 支持的Field类型
InfluxDB的Field值支持以下数据类型:
| Datatype | Size in Mem | Value Range |
|---|---|---|
| Float | 8 bytes | 1.797693134862315708145274237317043567981e+308 ~ 4.940656458412465441765687928682213723651e-324 |
| Integer | 8 bytes | -9223372036854775808 ~ 9223372036854775807 |
| String | 0~64KB | String with length less than 64KB |
| Boolean | 1 byte | true 或 false |
在InfluxDB中,Field的数据类型在以下范围内必须保持不变,否则写数据时会报错 类型冲突。
同一Serieskey + 同一field + 同一shard
2.3 Shard的概念
在InfluxDB中, 能且只能 对一个Database指定一个 Retention Policy (简称:RP)。通过RP可以对指定的Database中保存的时序数据的留存时间(duration)进行设置。而 Shard 的概念就是由duration衍生而来。一旦一个Database的duration确定后, 那么在该Database的时序数据将会在这个duration范围内进一步按时间进行分片从而时数据分成以一个一个的shard为单位进行保存。
shard分片的时间 与 duration之间的关系如下
| Duration of RP | Shard Duration |
|---|---|
| < 2 Hours | 1 Hour |
| >= 2 Hours 且 <= 6 Months | 1 Day |
| > 6 Months | 7 Days |
新建的Database在未显式指定RC的情况下,默认的RC为 数据的Duration为永久,Shard分片时间为7天
注: 在闭源的集群版Influxdb中,用户可以通过RC规则指定数据在基于时间分片的基础上再按SeriesKey为单位进行进一步分片
3. InfluxDB的存储引擎分析
时序数据库的存储引擎主要需满足以下三个主要场景的性能需求
- 大批量的时序数据写入的高性能
- 直接根据时间线(即Influxdb中的 Serieskey )在指定时间戳范围内扫描数据的高性能
- 间接通过measurement和部分tag查询指定时间戳范围内所有满足条件的时序数据的高性能
InfluxDB在结合了1.2所述考量的基础上推出了他们的解决方案,即下面要介绍的 WAL + TSMFile + TSIFile的方案
3.1 WAL解析
InfluxDB写入时序数据时为了确保数据完整性和可用性,与大部分数据库产品一样,都是会先写WAL,再写入缓存,最后刷盘。对于InfluxDB而言,写入时序数据的主要流程如同下图所示:
图 2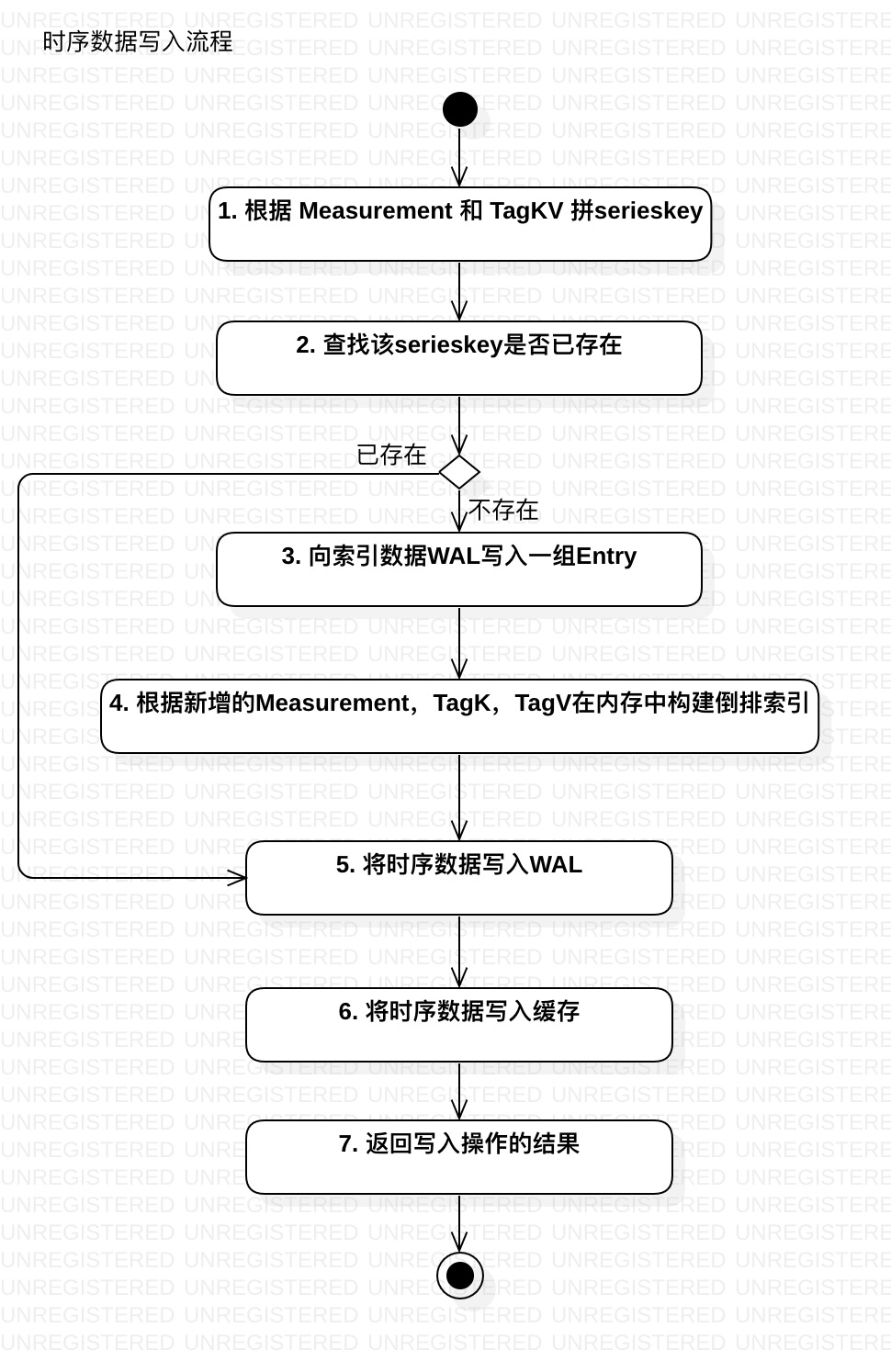
InfluxDB对于时间线数据和时序数据本身分开,分别写入不同的WAL中,其结构如下所示:
索引数据的WAL
由于InfluxDB支持对Measurement,TagKey,TagValue的删除操作,当然随着时序数据的不断写入,自然也包括 增加新的时间线,因此索引数据的WAL会区分当前所做的操作具体是什么,它的WAL的结构如下图所示
图 3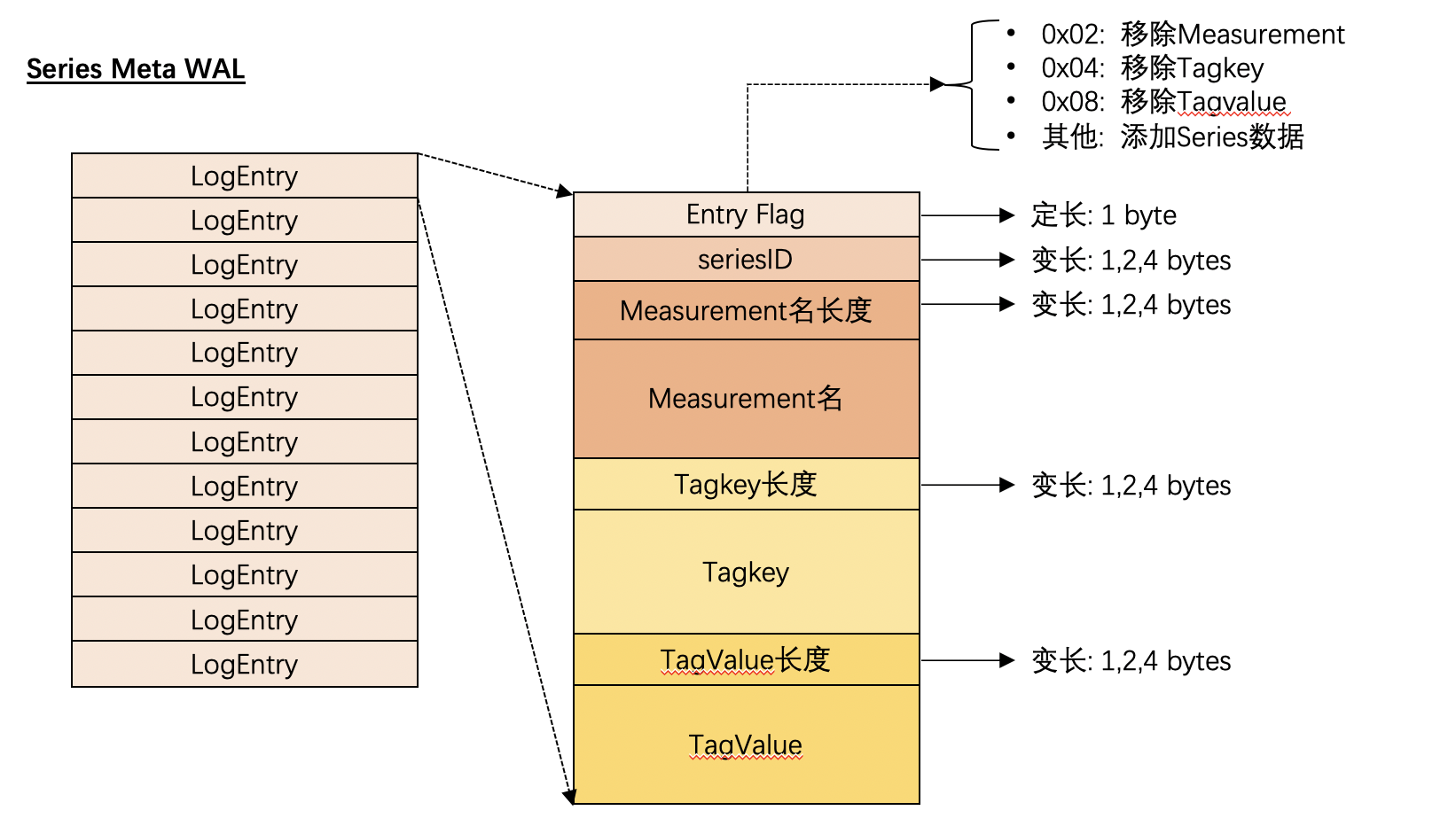
时序数据的WAL
由于InfluxDB对于时序数据的写操作永远只有单纯写入,因此它的Entry不需要区分操作种类,直接记录写入的数据即可
图 4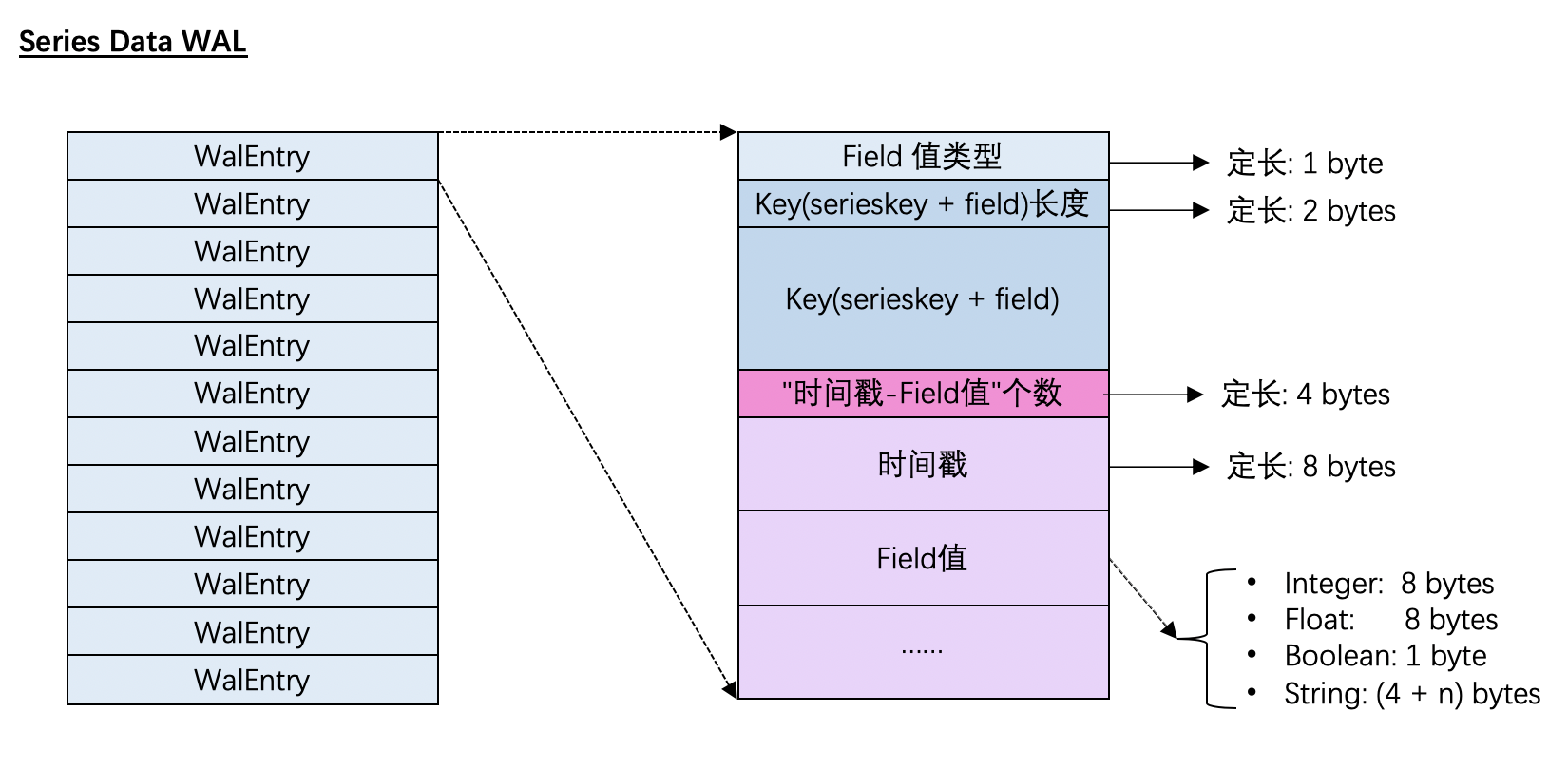
3.2 TSMFile解析
TSMFile是InfluxDB对于时序数据的存储方案。在文件系统层面,每一个TSMFile对应了一个 Shard。
TSMFile的存储结构如下图所示:
图 5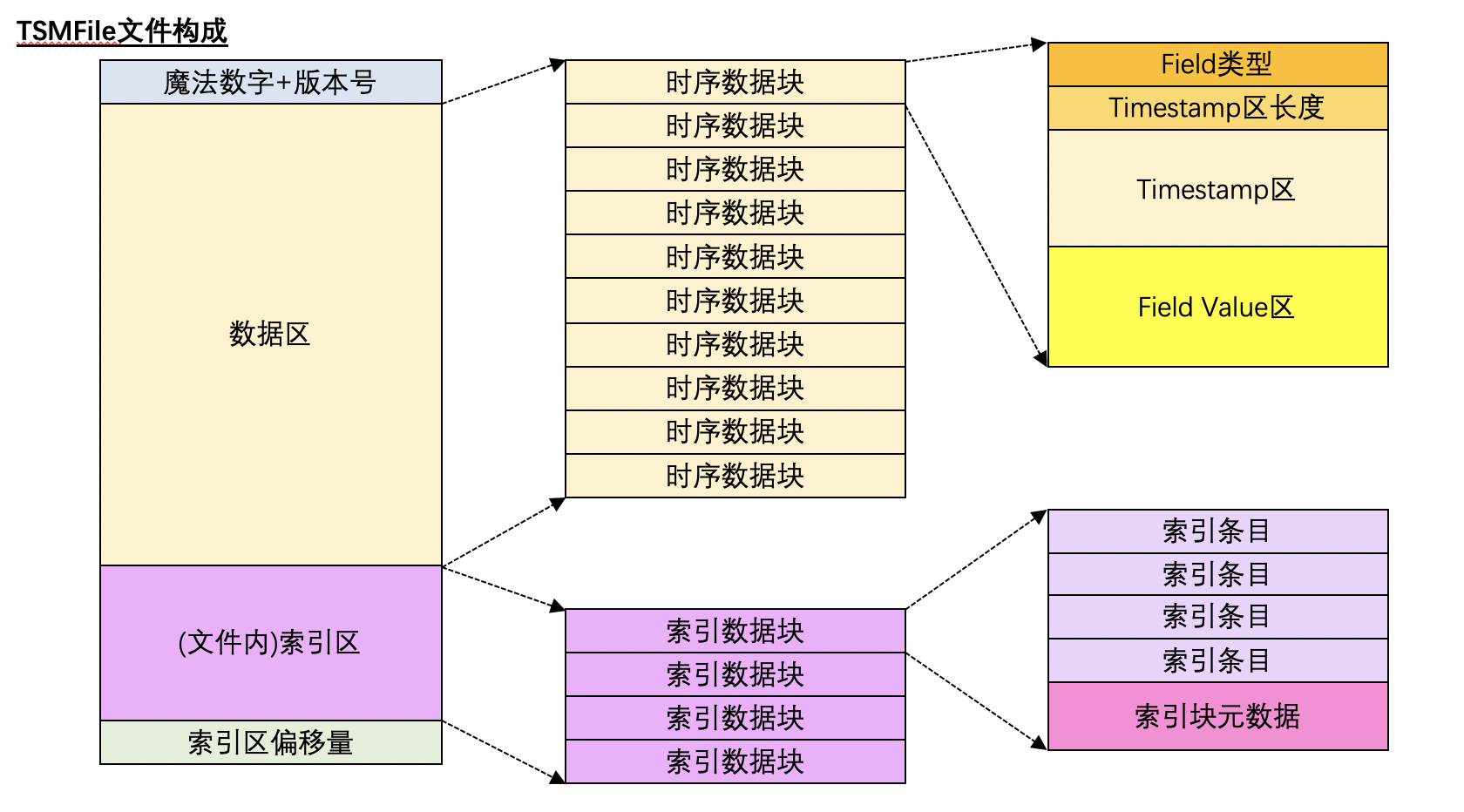
其特点是在一个TSMFile中将 时序数据(i.e Timestamp + Field value)保存在数据区;将Serieskey 和 Field Name的信息保存在索引区,通过一个基于 Serieskey + Fieldkey构建的形似B+tree的文件内索引快速定位时序数据所在的 数据块
注: 在当前版本中,单个TSMFile的最大长度为2GB,超过时即使是同一个Shard,也会继续新开一个TSMFile保存数据。本文的介绍出于简单化考虑,以下内容不考虑同一个Shard的TSMFile分裂的场景
索引块的构成
上文的索引块的构成,如下所示: *图 6*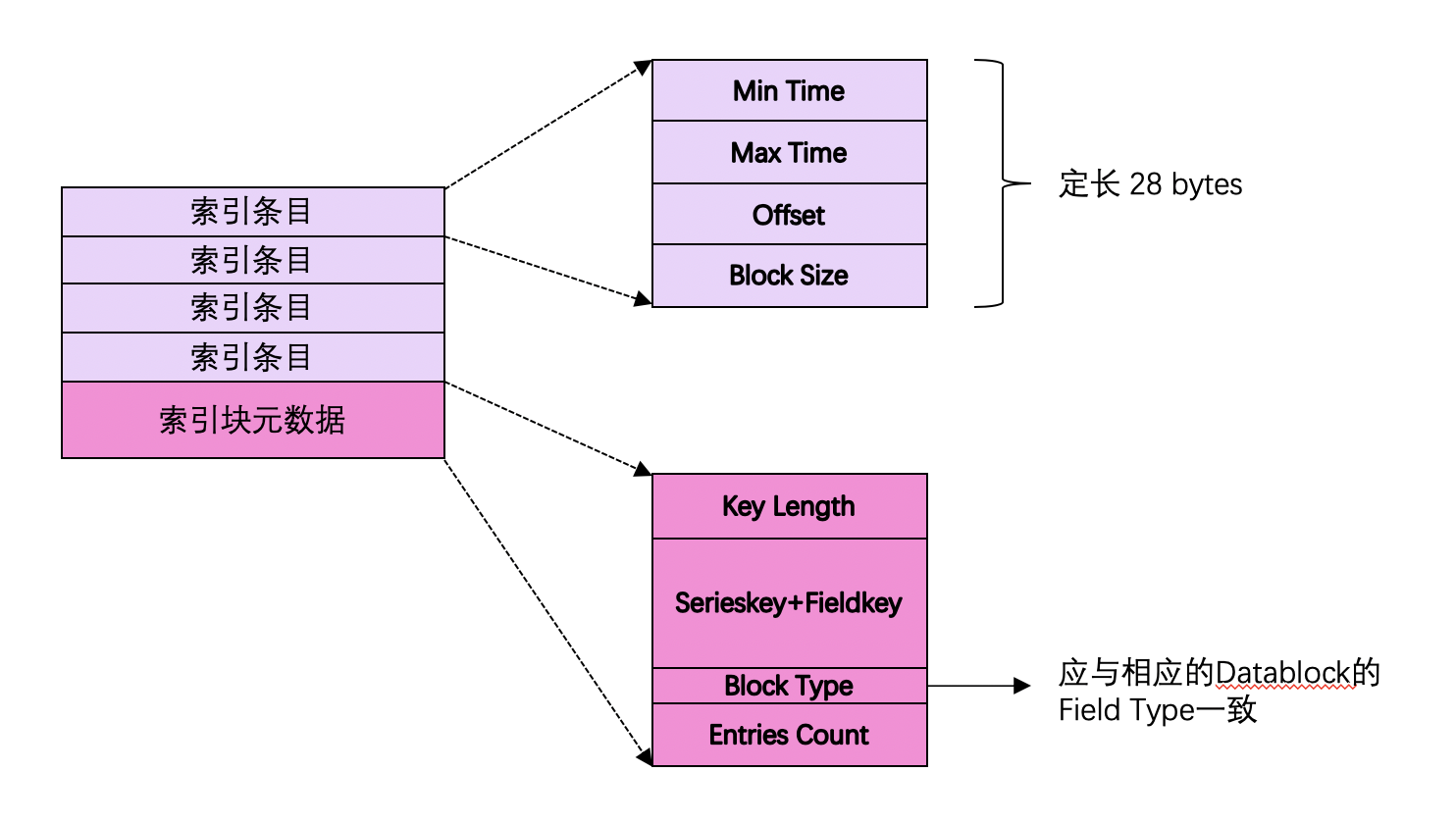
其中 **索引条目** 在InfluxDB的源码中被称为`directIndex`。在TSMFile中,索引块是按照 Serieskey + Fieldkey **排序** 后组织在一起的。
明白了TSMFile的索引区的构成,就可以很自然地理解InfluxDB如何高性能地在TSMFile扫描时序数据了:
1. 根据用户指定的时间线(Serieskey)以及Field名 在 **索引区** 利用二分查找找到指定的Serieskey+FieldKey所处的 **索引数据块**
2. 根据用户指定的时间戳范围在 **索引数据块** 中查找数据落在哪个(*或哪几个*)**索引条目**
3. 将找到的 **索引条目** 对应的 **时序数据块** 加载到内存中进行进一步的Scan
*注:上述的1,2,3只是简单化地介绍了查询机制,实际的实现中还有类似扫描的时间范围跨索引块等一系列复杂场景*
<br>
时序数据的存储
在图 2中介绍了时序数据块的结构:即同一个 Serieskey + Fieldkey 的 所有
时间戳 - Field值对被拆分开,分成两个区:Timestamps区和Value区分别进行存储。它的目的是:实际存储时可以分别对时间戳和Field值按不同的压缩算法进行存储以减少时序数据块的大小采用的压缩算法如下所示:
- Timestamp: Delta-of-delta encoding
Field Value:由于单个数据块的Field Value必然数据类型相同,因此可以集中按数据类型采用不同的压缩算法
- Float类: Gorrila's Float Commpression
- Integer类型: Delta Encoding + Zigzag Conversion + RLE / Simple8b / None
- String类型: Snappy Compression
- Boolean类型: Bit packing
做查询时,当利用TSMFile的索引找到文件中的时序数据块时,将数据块载入内存并对Timestamp以及Field Value进行解压缩后以便继续后续的查询操作。
3.3 TSIFile解析
有了TSMFile,第3章开头所说的三个主要场景中的场景1和场景2都可以得到很好的解决。但是如果查询时用户并没有按预期按照Serieskey来指定查询条件,而是指定了更加复杂的条件,该如何确保它的查询性能?通常情况下,这个问题的解决方案是依赖倒排索引(Inverted Index)。
InfluxDB的倒排索引依赖于下述两个数据结构
map<SeriesID, SeriesKey>map<tagkey, map<tagvalue, List<SeriesID>>>
它们在内存中展现如下:
图 7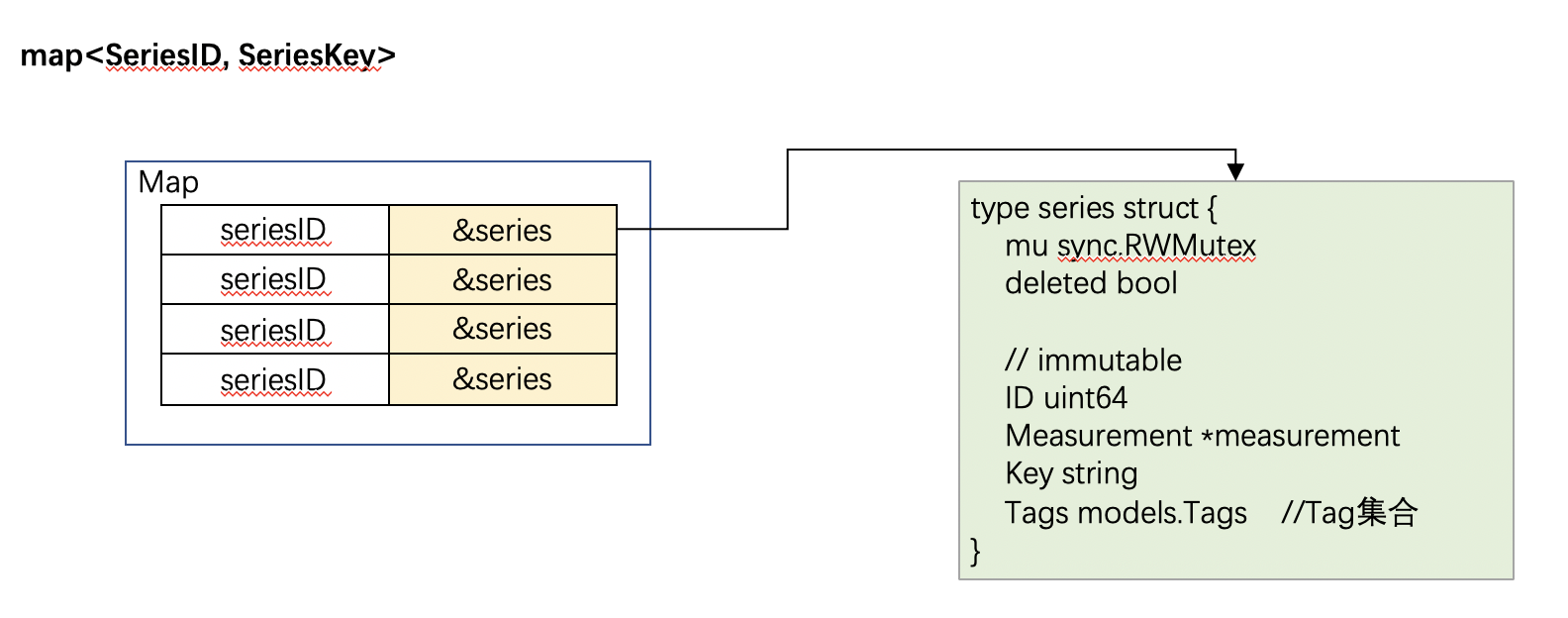
图 8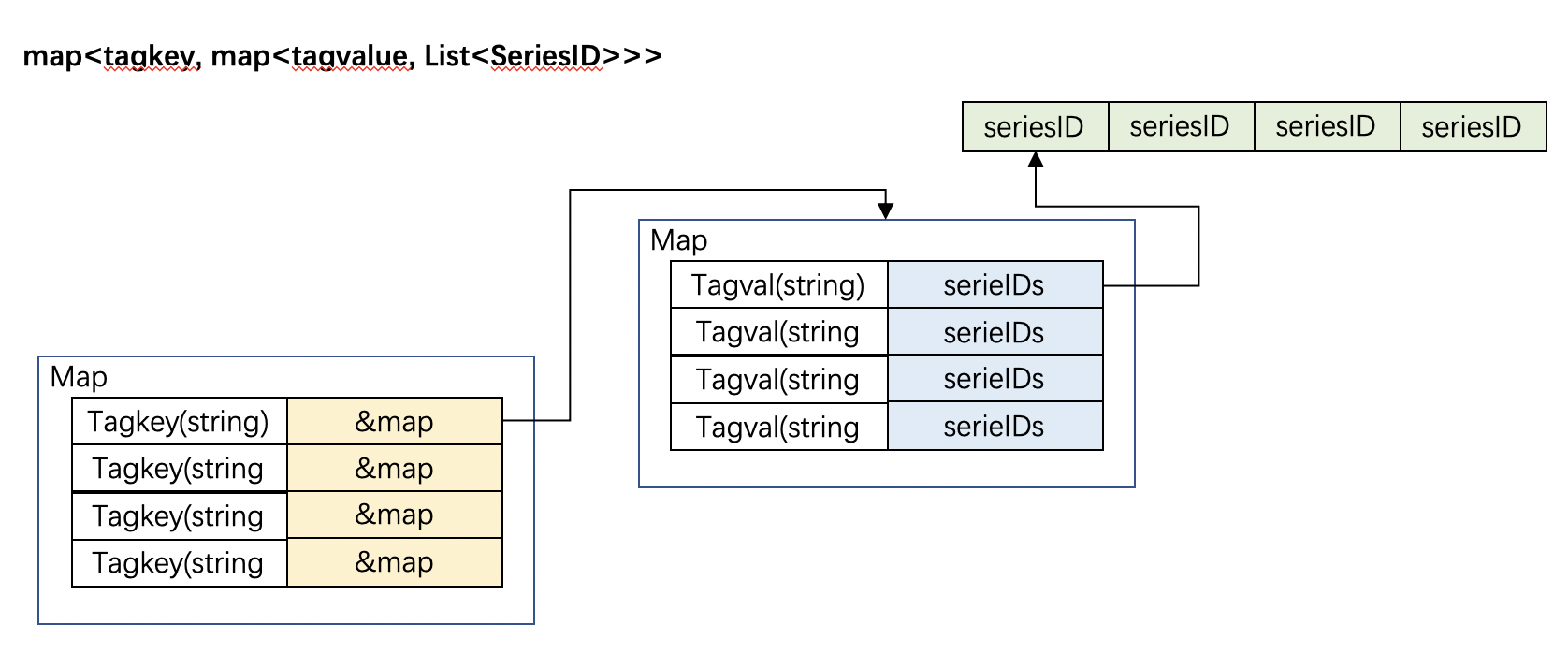
但是在实际生产环境中,由于用户的时间线规模会变得很大,因此会造成倒排索引使用的内存过多,所以后来InfluxDB又引入了 TSIFile
TSIFile的整体存储机制与TSMFile相似,也是以 Shard 为单位生成一个TSIFile。具体的存储格式就在此不赘述了。
4. 总结
以上就是对InfluxDB的存储机制的粗浅解析,由于目前所见的只有单机版的InfluxDB,所以尚不知道集群版的InfluxDB在存储方面有哪些不同。但是,即便是这单机版的存储机制,也对我们设计时序数据库有着重要的参考意义。
原文链接
更多技术干货 请关注阿里云云栖社区微信号 :yunqiinsight
时序数据库连载系列: 时序数据库一哥InfluxDB之存储机制解析的更多相关文章
- 时序数据库连载系列:指标届的独角兽Prometheus
简介 Prometheus是SoundCloud公司开发的一站式监控告警平台,依赖少,功能齐全.于2016年加入CNCF,广泛用于 Kubernetes集群的监控系统中,2018.8月成为继K8S之后 ...
- [翻译] InfluxDB 存储机制解析
原文地址: https://medium.com/dataseries/analysis-of-the-storage-mechanism-in-influxdb-b84d686f3697 TODO
- 时序数据库技术体系 – InfluxDB TSM存储引擎之TSMFile
本文转自 http://hbasefly.com/2018/01/13/timeseries-database-4/ 为了更加系统的对时序数据库技术进行全方位解读,笔者打算再写一个系列专题(嘿嘿,好像 ...
- InfluxDB 开源分布式时序、事件和指标数据库
InfluxDB 是一个开源分布式时序.事件和指标数据库.使用 Go 语言编写,无需外部依赖.其设计目标是实现分布式和水平伸缩扩展. 特点 schemaless(无结构),可以是任意数量的列 Scal ...
- [转帖]时序数据库技术体系 – InfluxDB TSM存储引擎之数据读取
时序数据库技术体系 – InfluxDB TSM存储引擎之数据读取 http://hbasefly.com/2018/05/02/timeseries-database-7/ 2018年5月2日 ...
- [转帖]时序数据库技术体系 – InfluxDB TSM存储引擎之数据写入
时序数据库技术体系 – InfluxDB TSM存储引擎之数据写入 http://hbasefly.com/2018/03/27/timeseries-database-6/ 2018年3月27日 ...
- [UML]UML系列——时序图(顺序图)sequence diagram
系列文章 [UML]UML系列——用例图Use Case [UML]UML系列——用例图中的各种关系(include.extend) [UML]UML系列——类图Class [UML]UML系列——类 ...
- Sql Server来龙去脉系列之四 数据库和文件
在讨论数据库之前我们先要明白一个问题:什么是数据库? 数据库是若干对象的集合,这些对象用来控制和维护数据.一个经典的数据库实例仅仅包含少量的数据库,但用户一般也不会在一个实例上创建太多 ...
- ASP.NET MVC+EF框架+EasyUI实现权限管理系列(2)-数据库访问层的设计Demo
原文:ASP.NET MVC+EF框架+EasyUI实现权限管理系列(2)-数据库访问层的设计Demo ASP.NET MVC+EF框架+EasyUI实现权限管系列 (开篇) (1)框架搭建 前言:这 ...
随机推荐
- 廖雪峰Java11多线程编程-3高级concurrent包-1ReentrantLock
线程同步: 是因为多线程读写竞争资源需要同步 Java语言提供了synchronized/wait/notify来实现同步 编写多线程同步很困难 所以Java提供了java.util.concurre ...
- go语言基本运算符
go语言基本运算符 1.算术运算符 以下假设A=10,B=20: 2.关系运算符 以下假设A=10,B=20: 3.逻辑运算符 以下假设A=true,B=false: 4.位运算符 十进制转二进制: ...
- 密码学笔记(4)——RSA的其他攻击
上一篇详细分析了几种分解因子的算法,这是攻击RSA密码最为明显的算法,这一篇中我们考虑是否有不用分解模数n就可以解密RSA的密文的方法,这是因为前面也提到,当n比较大的时候进行分解成素数的乘积是非常困 ...
- ansible 安装 使用 命令 笔记 生成密钥 管控机 被管控机 wget epel源
ansible 与salt对比 相同 都是为了同时在多台机器上执行相同的命令 都是python开发 不同 agent(saltstack需要安装.ansible不需要) 配置(salt配置麻烦,a ...
- Python学习day39-并发编程(各种锁)
figure:last-child { margin-bottom: 0.5rem; } #write ol, #write ul { position: relative; } img { max- ...
- C#用API可以改程序名字
[DllImport("user32.dll", EntryPoint = "FindWindow")] public static extern int Fi ...
- 启用或禁用对 Exchange Server 中的邮箱的 POP3 或 IMAP4 访问
https://docs.microsoft.com/zh-cn/Exchange/clients/pop3-and-imap4/configure-mailbox-access?view=exchs ...
- GitHub for Visual Studio使用讲解
从VS2015起(应该是吧?),微软已经在VS中集成了GitHub,方便开发者对项目进行版本控制. 扩展包下载地址:https://aka.ms/ghfvs 其实VS2015的安装包中已经自带了这个扩 ...
- DOS批处理脚本
先概述一下批处理是个什么东东.批处理的定义,至今我也没能给出一个合适的----众多高手们也都没给出----反正我不知道----看了我也不一定信服----我是个菜鸟,当然就更不用说了:但我想总结出一个“ ...
- Vue:$route 和 $router 的区别
参考: https://uzshare.com/view/788446 https://router.vuejs.org/zh/ $route 是“路由信息对象”,包括 path,params,has ...