Affinity Propagation
1. 调用方法:
AffinityPropagation(damping=0.5, max_iter=200, convergence_iter=15, copy=True, preference=None, affinity=’euclidean’, verbose=False)
参数:
damping : float, optional, default: 0.5 防止更新过程中数值震荡
max_iter : int, optional, default: 200
convergence_iter : int, optional, default: 15
如果类簇数目在达到这么多次迭代以后仍然不变的话,就停止迭代。
copy : boolean, optional, default: True
Make a copy of input data.
preference : array-like, shape (n_samples,) or float, optional
每个points的preference。具有更大preference的点更可能被选为exemplar。类簇的数目受此值的影响,如果没有传递此参数,它们 会被设置成input similarities的中值。???
affinity : string, optional, default=``euclidean``
度量距离的方式,推荐precomputed and euclidean这两种,euclidean uses the negative squared euclidean distance between points.
verbose : boolean, optional, default: False
属性:
cluster_centers_indices_ : array, shape (n_clusters,)
类簇中心的索引
cluster_centers_ : array, shape (n_clusters, n_features)
类簇中心 (if affinity != precomputed)
labels_ : array, shape (n_samples,)
每个point的标签
affinity_matrix_ : array, shape (n_samples, n_samples)
Stores the affinity matrix used in fit.
n_iter_ : int
达到收敛需要的迭代次数。
2. scikit-learn介绍
http://scikit-learn.org/stable/modules/clustering.html#affinity-propagation
3. 算法复杂性
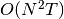 ,与样本数成正比。
,与样本数成正比。
4.算法描述
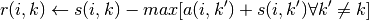
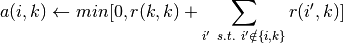
引入阻尼因子:
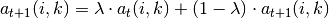
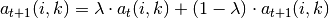
Affinity Propagation的更多相关文章
- AP(affinity propagation)研究
待补充…… AP算法,即Affinity propagation,是Brendan J. Frey* 和Delbert Dueck于2007年在science上提出的一种算法(文章链接,维基百科) 现 ...
- Affinity Propagation Algorithm
The principle of Affinity Propagation Algorithm is discribed at above. It is widly applied in many f ...
- Affinity Propagation Demo2学习【可视化股票市场结构】
这个例子利用几个无监督的技术从历史报价的变动中提取股票市场结构. 使用报价的日变化数据进行试验. Learning a graph structure 首先使用sparse inverse(相反) c ...
- Affinity Propagation Demo1学习
利用AP算法进行聚类: 首先导入需要的包: from sklearn.cluster import AffinityPropagation from sklearn import metrics fr ...
- AP聚类算法(Affinity propagation Clustering Algorithm )
AP聚类算法是基于数据点间的"信息传递"的一种聚类算法.与k-均值算法或k中心点算法不同,AP算法不需要在运行算法之前确定聚类的个数.AP算法寻找的"examplars& ...
- knn/kmeans/kmeans++/Mini Batch K-means/Affinity Propagation/Mean Shift/层次聚类/DBSCAN 区别
可以看出来除了KNN以外其他算法都是聚类算法 1.knn/kmeans/kmeans++区别 先给大家贴个简洁明了的图,好几个地方都看到过,我也不知道到底谁是原作者啦,如果侵权麻烦联系我咯~~~~ k ...
- [Python] 机器学习库资料汇总
声明:以下内容转载自平行宇宙. Python在科学计算领域,有两个重要的扩展模块:Numpy和Scipy.其中Numpy是一个用python实现的科学计算包.包括: 一个强大的N维数组对象Array: ...
- 【转帖】Python在大数据分析及机器学习中的兵器谱
Flask:Python系的轻量级Web框架. 1. 网页爬虫工具集 Scrapy 推荐大牛pluskid早年的一篇文章:<Scrapy 轻松定制网络爬虫> Beautiful Soup ...
- {Reship}{Code}{CV}
UIUC的Jia-Bin Huang同学收集了很多计算机视觉方面的代码,链接如下: https://netfiles.uiuc.edu/jbhuang1/www/resources/vision/in ...
随机推荐
- 用python做推荐系统(一)
一.简介: 推荐系统是最常见的数据分析应用之一,包含淘宝.豆瓣.今日头条都是利用推荐系统来推荐用户内容.推荐算法的方式分为两种,一种是根据用户推荐,一种是根据商品推荐,根据用户推荐主要是找出和这个用户 ...
- jSignature签字板保存为图片
这是本人的第一篇博客,还不会使用.有些简陋,勿怪! 今天要讲的是使用jquery插件jSignature做一个手写板签字的功能,并将签字笔迹保存为图片. 第一步:环境准备 jquery.jSignat ...
- Java String类相关知识梳理(含字符串常量池(String Pool)知识)
目录 1. String类是什么 1.1 定义 1.2 类结构 1.3 所在的包 2. String类的底层数据结构 3. 关于 intern() 方法(重点) 3.1 作用 3.2 字符串常量池(S ...
- Class 'org.apache.tomcat.jdbc.pool.DataSource' not found
把项目移动到新的运行环境时,明明包都导入了,项目也放进tomcat里面了,但是还会找不到该类 解决方法:项目右键选择底下的Properties ->project facets ->jav ...
- TieredMergePolicy
setFloorSegmentMB多少MB一个层级,在此区间的segment分为一个floor. setMaxMergeAtOnce一次merge多少个segment. setSegmentsPerT ...
- mock造数据
前端开发,需要和后台联调:很多时候,前端开发并不需要等后台完全写好接口在去联调,自己可以写死数据,渲染数据,加样式.后台人员有时会很忙,他没有时间写好返回所有的数据等等,特别是新开一个项目,从零开始的 ...
- 字符串转hash
#include<bits/stdc++.h> using namespace std; unsigned hash[]; ; int ans; int main() { ;k<=; ...
- 【LC_Lesson1】--字符串反转练习
LeetCode算法练习题目一: 给定一个字符串,要求将该字符串反转后输出 努力学习,天天向上.借助LeetCode的题目,练习编码能力,数据结构,以及C++和Python的编码能力. 一. 算法实现 ...
- dp-最长公共子序列(LCS)
字符序列 与 字符字串的区别 序列是可以不连续的字符串 , 字串必须要是连续的 . 问题描述 : 给定两串字符串 abcde 和 acdf , 找出 2 串中相同的字符序列,观察知 相同的字符序列为 ...
- PTA - dfs
地道战是在抗日战争时期,在华北平原上抗日军民利用地道打击日本侵略者的作战方式.地道网是房连房.街连街.村连村的地下工事,如下图所示. 我们在回顾前辈们艰苦卓绝的战争生活的同时,真心钦佩他们的聪明才智. ...