Elasticsearch系列---实战零停机重建索引
前言
我们使用Elasticsearch索引文档时,最理想的情况是文档JSON结构是确定的,数据源源不断地灌进来即可,但实际情况中,没人能够阻拦需求的变更,在项目的某个版本,可能会对原有的文档结构造成冲击,增加新的字段还好,如果要修改原有的字段,只能重建索引了。
概要
本篇以实战方式讲解如何零停机完成索引重建的三种方案。
外部数据导入方案
整体介绍
系统架构设计中,有关系型数据库用来存储数据,Elasticsearch在系统架构里起到查询加速的作用,如果遇到索引重建的操作,待系统模块发布新版本后(若重建索引不是因为客户端修改导致的,可以不停机发版,直接操作),可以从数据库将数据查询出来,重新灌到Elasticsearch即可。
执行步骤
建议的功能方案:数据库 + MQ + 应用模块 + Elasticsearch,可以在MQ控制台发送MQ消息来触发重导数据,按批次对数据进行导入,整个过程异步化处理,请求操作示意如下所示:
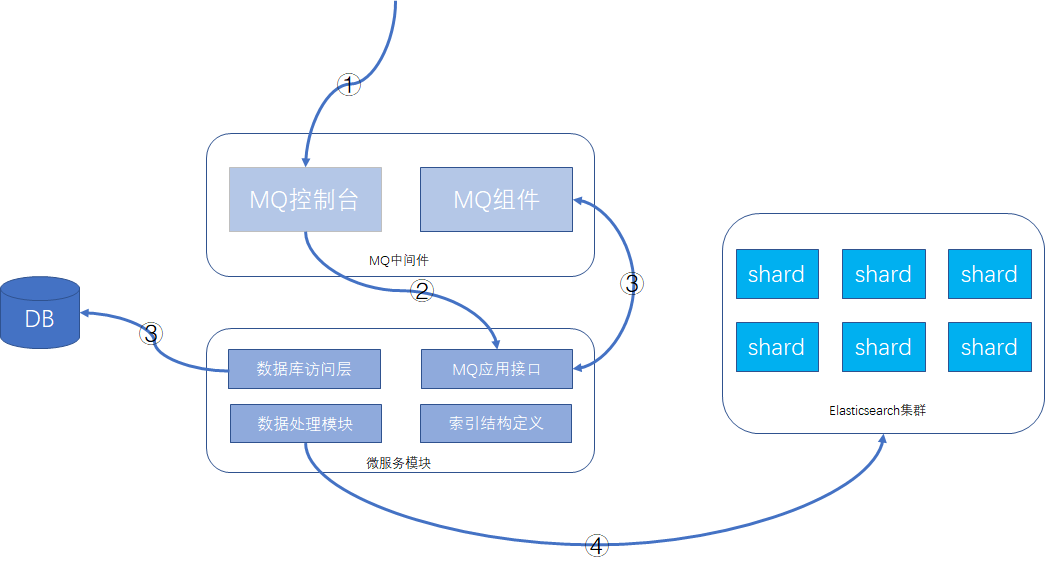
详细操作步骤:
- 通过MQ的web控制台或cli命令行,发送指定的MQ消息
- MQ消息被微服务模块的消费者消费,触发ES数据重新导入功能
- 微服务模块从数据库里查询数据的总数及批次信息,并将每个数据批次的分页信息重新发送给MQ消息,分页信息包含查询条件和偏移量,此MQ消息还是会被微服务的MQ消息者接收处理。
- 微服务根据接收的查询条件和分页信息,从数据库获取到数据后,根据索引结构的定义,将数据组装成ES支持的JSON格式,并执行bulk命令,将数据发送给Elasticsearch集群。
这样就可以完成索引的重建工作。
方案特点
MQ中间件的选型不做具体要求,常见的rabitmq、activemq、rocketmq等均可。
在微服务模块方面,提供MQ消息处理接口、数据处理模块需要事先开发的,一般是创建新的索引时,配套把重建的功能也一起做好。整体功能共用一个topic,针对每个索引,有单独的结构定义和MQ消息处理tag,代码尽可能复用。处理的批次大小需要根据实际的情况设置。
微服务模块实例会部署多个,数据是分批处理的,批次信息会一次性全部先发送给MQ,各个实例处理的数据相互不重叠,利用MQ消息的异步处理机制,可以充分利用并发的优势,加快数据重建的速度。
方案缺点
- 对数据库造成读取压力,短时间内大量的读操作,会占用数据库的硬件资源,严重时可能引起数据库性能下降。
- 网络带宽占用多,数据毕竟是从一个库传到另一个库,虽说是内网,但大量的数据传输带宽占用也需要注意。
- 数据重建时间稍长,跟迁移的数据量大小有关。
基于scroll+bulk+索引别名方案
整体介绍
利用Elasticsearch自带的一些工具完成索引的重建工具,当然在方案实际落地时,可能也会依赖客户端的一些功能,比如用Java客户端持续的做scroll查询、bulk命令的封装等,但与上一方案相比,最明显的区别就是:数据完全自给自足,不依赖其他数据源。
执行步骤
假设原索引名称是music,新的索引名称为music_new,Java客户端使用别名music_alias连接Elasticsearch,该别名指向原索引music。
- 若Java客户端没有使用别名,需要给客户端分配一个:
PUT /music/_alias/music_alias - 新建索引music_new,将mapping信息,settings信息等按新的要求全部定义好。
- 使用scroll api将数据批量查询出来
GET /music/_search?scroll=1m
{
"query": {
"match_all": {}
},
"sort": ["_doc"],
"size": 1000
}
- 采用bulk api将scoll查出来的一批数据,批量写入新索引
POST /_bulk
{ "index": { "_index": "music_new", "_type": "children", "_id": "1" }}
{ "name": "wake me, shake me" }
- 反复执行步骤3和步骤4,查询一批导入一批,可以借助Java Client或其他语言的API支持。
- 切换别名music_alias到新的索引music_new上面,此时Java客户端仍然使用别名访问,也不需要修改任何代码,不需要停机。
POST /_aliases
{
"actions": [
{ "remove": { "index": "music", "alias": "music_alias" }},
{ "add": { "index": "music_new", "alias": "music_alias" }}
]
}
- 验证别名查询的是否为新索引的数据
方案特点
在数据传输上基本自给自足,不依赖于其他数据源,Java客户端不需要停机等待数据迁移,网络传输占用带宽较小。
只是scroll查询和bulk提交这部分,数据量大时需要依赖一些客户端工具。
补充一点
在Java客户端或其他客户端访问Elasticsearch集群时,使用别名是一个好习惯。
Reindex API方案
Elasticsearch v6.3.1已经支持Reindex API,它对scroll、bulk做了一层封装,能够 对文档重建索引而不需要任何插件或外部工具。
最基础的命令:
POST _reindex
{
"source": {
"index": "music"
},
"dest": {
"index": "music_new"
}
}
响应结果:
{
"took": 180,
"timed_out": false,
"total": 4,
"updated": 0,
"created": 4,
"deleted": 0,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}
注意:
如果不手动创建新索引music_new的mapping信息,那么Elasticsearch将启动自动映射模板对数据进行类型映射,可能不是期望的类型,这点要注意一下。
version_type 属性
使用reindex api也是创建快照后再执行迁移的,这样目标索引的数据可能会与原索引有差异,version_type属性可以决定乐观锁并发处理的规则。
reindex api可以设置version_type属性,如下:
POST _reindex
{
"source": {
"index": "music"
},
"dest": {
"index": "music_new"
"version_type": "internal"
}
}
version_type属性含义如下:
- internal:直接拷贝文档到目标索引,对相同的type、文档ID直接进行覆盖,默认值
- external:迁移文档到目标索引时,保留version信息,对目标索引中不存在的文档进行创建,已存在的文档按version进行更新,遵循乐观锁机制。
op_type 属性和conflicts 属性
如果op_type设置为create,那么迁移时只在目标索引中创建ID不存在的文档,已存在的文档,会提示错误,如下请求:
POST _reindex
{
"source": {
"index": "music"
},
"dest": {
"index": "music_new",
"op_type": "create"
}
}
有错误提示的响应,节选部分:
{
"took": 11,
"timed_out": false,
"total": 5,
"updated": 0,
"created": 1,
"deleted": 0,
"batches": 1,
"version_conflicts": 4,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": [
{
"index": "music_new",
"type": "children",
"id": "2",
"cause": {
"type": "version_conflict_engine_exception",
"reason": "[children][2]: version conflict, document already exists (current version [17])",
"index_uuid": "dODetUbATTaRL-p8DAEzdA",
"shard": "2",
"index": "music_new"
},
"status": 409
}
]
}
如果加上"conflicts": "proceed"配置项,那么冲突信息将不展示,只展示冲突的文档数量,请求和响应结果将变成这样:
请求:
POST _reindex
{
"conflicts": "proceed",
"source": {
"index": "twitter"
},
"dest": {
"index": "new_twitter",
"op_type": "create"
}
}
响应:
{
"took": 12,
"timed_out": false,
"total": 5,
"updated": 0,
"created": 1,
"deleted": 0,
"batches": 1,
"version_conflicts": 4,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}
query支持
reindex api支持数据过滤、数据排序、size设置、_source选择等,也支持脚本执行,这里提供一个简单示例:
POST _reindex
{
"size": 100,
"source": {
"index": "music",
"query": {
"term": {
"language": "english"
}
},
"sort": {
"likes": "desc"
}
},
"dest": {
"index": "music_new"
}
}
小结
本篇介绍了零停机索引重建操作的三个方案,从自研功能、scroll+bulk到reindex,我们作为Elasticsearch的使用者,三个方案的参与度是逐渐弱化的,但稳定性却是逐渐上升的,我们需要清楚地去了解各个方案的优劣,适宜的场景,然后根据实际的情况去权衡,哪个方案更适合我们的业务模型,仅供参考,谢谢。
专注Java高并发、分布式架构,更多技术干货分享与心得,请关注公众号:Java架构社区
可以扫左边二维码添加好友,邀请你加入Java架构社区微信群共同探讨技术

Elasticsearch系列---实战零停机重建索引的更多相关文章
- ElasticSearch(三十)基于scoll+bulk+索引别名实现零停机重建索引
1.为什么要重建索引? 总结,一个type下的mapping中的filed不能被修改,所以如果需要修改,则需要重建索引 2.怎么zero time重建索引? 一个field的设置是不能被修改的,如果要 ...
- ELK学习总结(4-1)elasticsearch更改mapping(不停服务重建索引)
elasticsearch更改mapping(不停服务重建索引)原文 http://donlianli.iteye.com/blog/1924721Elasticsearch的mapping一旦创建, ...
- elasticsearch更改mapping(不停服务重建索引)
转载地址:http://donlianli.iteye.com/blog/1924721?utm_source=tuicool&utm_medium=referral Elasticsearc ...
- Elasticsearch系列---实战搜索语法
概要 本篇介绍Query DSL的语法案例,查询语句的调试,以及排序的相关内容. 基本语法 空查询 最简单的搜索命令,不指定索引和类型的空搜索,它将返回集群下所有索引的所有文档(默认显示10条): G ...
- Elasticsearch系列---生产集群的索引管理
概要 索引是我们使用Elasticsearch里最频繁的部分日常的操作都与索引有关,本篇从运维人员的视角,来玩一玩Elasticsearch的索引操作. 基本操作 在运维童鞋的视角里,索引的日常操作除 ...
- es之零停机重新索引数据
实际生产,对于文档的操作,偶尔会遇到这种问题: 某一个字段的类型不符合后期的业务了,但是当前的索引已经创建了,我们知道es在字段的mapping建立后就不可再次修改mapping的值 比如: 1): ...
- 【ElasticSearch】ElasticSearch-索引优化-自定义索引
ElasticSearch-索引优化-自定义索引 es 指定 索引 字段_百度搜索 [es]创建索引和映射 - 匡子语 - 博客园 reindex,增加字段,并新增数据 - Elastic中文社区 e ...
- elasticsearch 5.x 系列之七 基于索引别名的零停机升级服务
一,写在前面的话,elasticsearch 建立索引时的Mapping 设置 建议你在设计索引的初期,就把索引的各个字段设计好,因为,elasticsearch 的各个字段,定义好类型后,就无法进行 ...
- Elasticsearch如何修改Mapping结构并实现业务零停机
Elasticsearch 版本:6.4.0 一.疑问 在项目中后期,如果想调整索引的 Mapping 结构,比如将 ik_smart 修改为 ik_max_word 或者 增加分片数量 等,但 El ...
随机推荐
- CentOS7.0下安装FTP服务的方法
http://www.jb51.net/article/106604.htm 本篇文章主要介绍了CentOS7.0下安装FTP服务的方法,小编觉得挺不错的,现在分享给大家,也给大家做个参考.一起跟 ...
- 深度学习——GAN
整理自: https://blog.csdn.net/woaidapaopao/article/details/77806273?locationnum=9&fps=1 思想 表达式 实际计算 ...
- layui图片上传之后后台如何修改图片的后缀名以及返回数据给前台
const pathLib = require('path');//引入node.js下的一个path模块的方法,主要处理文件的名字等工作,具体可看文档 const fs = require(''fs ...
- 【36.11%】【codeforces 725C】Hidden Word
time limit per test2 seconds memory limit per test256 megabytes inputstandard input outputstandard o ...
- koa2入门--01.ES6简单复习、koa2安装以及例子
1.ES6简单复习 /*let 和 const: let用于定义一个块作用域的变量,const 定义一个常量 */ let a = 'test'; const b = 2; /*对象的属性和方法的简写 ...
- AI炼丹 - 深度学习必备库 numpy
目录 深度学习必备库 - Numpy 1. 基础数据结构ndarray数组 1.1 为什么引入ndarray数组 1.2 如何创建ndarray数组 1.3 ndarray 数组的基本运算 1.4 n ...
- CentOS 下 git 401 Unauthorized while accessing 问题解决
The requested URL returned error: 401 Unauthorized while accessing 这个一般是旧版git的问题,需要安装新版的.CentOS 想下载最 ...
- 什么是特性(Attribute)?
由面向对象思想,我们诞生了很多种面向对象编程语言,比如常用的Java,C#,这些语言中都共有类(Class)的概念,并用各自的方式去阐述.编写Class,或许方式不同,但它们都有一个共同点,即“类是对 ...
- jenkins邮件通知html魔板
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 第一次看CCControl
Control中有九种可能的事件,定义在.h文件中,另外还定义四种状态,用来表示控件高亮等. 在初始化控件的时候: bool Control::init() { if (Layer::init()) ...