spring-data-JPA repository自定义方法规则
一、自定义方法的规则


关键词 样品 JPQL片段
IsNotNull findByAgeNotNull ...其中x.age 不为空【年龄不为空】
喜欢 findByNameLike ...其中x.name是什么样的?【模糊查找是......】
不喜欢 findByNameNotLike ...其中x.name不喜欢?【模糊查找不是......】
从...开始 findByNameStartingWith ...其中x.name类似?(参数绑定附加%)【模糊匹配,类似使用%结尾】
EndingWith findByNameEndingWith ...其中x.name类似于?(参数与预置%绑定)【模糊匹配,类似使用%开始】
含 findByNameContaining ...其中x.name like?(参数绑定在%中)[模糊匹配,类似使用%开头和结尾]
排序依据 findByAgeOrderByName ...其中x.age =?order by x.name desc 【查找后排序】
不 findByNameNot ...其中x.name <>?【查找列不是...的】
在 findByAgeIn ...哪里x.age在?
NotIn findByAgeNotIn ...其中x.age不在?
真正 findByActiveTrue ...其中x.avtive = true
产品嫁接 findByActiveFalse ...其中x.active = false
和 findByNameAndAge ...其中x.name =?和x.age =?2
要么 findByNameOrAge ...其中x.name =?或x.age =?2
之间 findBtAgeBetween ...其中x.age之间?和?2
少于 findByAgeLessThan ...其中x.age <?
比...更棒 findByAgeGreaterThan ...其中x.age>?
在那之后 ... ...
一片空白 findByAgeIsNull ...其中x.age为空
自定义查找实例:
/**
* 根据id查用户
**/
List<User> findByIdOrName(Long id,String name); /**
* 根据id查用户
**/
User queryXXXXByName(String name); /**
* 根据id查name
**/
User readNameById(Long id); /**
* 查年龄为10岁的学生
**/
List<User> getByAge(int age);
三,Spring Data JPA分页查询:
/**
* 分页查询左右用户
* @param pageable
* @return
*/
Page<User> findAll(Pageable pageable); /**
* 分页查询id不是传入id的用户
* @param id
* @param pageable
* @return
*/
Page<User> findByIdNot(Long id,Pageable pageable);
【注意】分页查询,的结果页,,页接口继承自切片,这个接口有以下方法
public interface Slice<T> extends Iterable<T> {
int getNumber();//返回当前页码
int getSize();//返回当前页大小(可能不是一整页)
int getNumberOfElements();//返回当前的元素数量
List<T> getContent();//返回当前页的内容(查询结果)
boolean hasContent();//判断是否有内容存在
Sort getSort();//返回排序方式
boolean isFirst();//判断是不是第一页
boolean isLast();//判断是不是最后一页
boolean hasNext();//判断是否还有下一页
boolean hasPrevious();//判断是否上一页
Pageable nextPageable();//返回下一页
Pageable previousPageable();//返回上一页,如果当前已经是第一个,则返回,请求前一个可以是【null】。在调用此方法之前,客户端应该检查是否收到一个非值。
<S> Slice<S> map(Converter<? super T, ? extends S> var1);//用给定的映射,映射当前的内容,为Slice
}
方法名 关键字 SQL
findById 其中id =?
findByIdIs 是 其中id =?
findByIdEquals 等于 其中id =?
findByNameAndAge 和 where name =?和年龄=?
findByNameOrAge 要么 where name =?或年龄=?
findByNameOrderByAgeDesc 按顺序排列 where name =?按年龄顺序排列
findByAgeNotIn 不在 年龄不在(?)
findByStatusTrue 真正 where status = true
findByStatusFalse 假 其中status = false
findByAgeBetween 之间 年龄在哪?和?
findByNameNot 不 名称<>?
findByAgeLessThan 少于 年龄<?
findByAgeLessThanEqual LessThanEqual 年龄<=?
findByAgeGreaterThan 比...更棒 年龄>?
findByAgeGreaterThanEqual GreaterThanEqual 年龄> =?
findByAgeAfter 后 年龄>?
findByAgeBefore 之前 年龄<?
findByNameIsNull 一片空白 其中名称为空
findByNameNotNull 不为空 其中名称不为空
findByNameLike 喜欢 哪里的名字像?
findByNameNotLike 不喜欢 哪里的名字不像?
findByNameStartingWith 从...开始 名称如'?%'
findByNameEndingWith EndingWith 名称如'%?'
findByNameContaining 含 名称如'%?%'
代码中几个复杂的。
findByNameAndAgeAndSex:表示where name =?和年龄=?和性=?
findByNameInAndAgeIsNull:表示(?)中的名称和年龄为null
findByNameAndAgeInAndSexIn:表示where name =?年龄(?)和性别(?)
可以看出关键字是可以连用的,查找都是用findBy +表中列名,表的列名还有关键字等等拼接时,它们的首字母要大写。
二、懒加载引起的no-session解决方法之一,没有页面只有测试用例没有效果
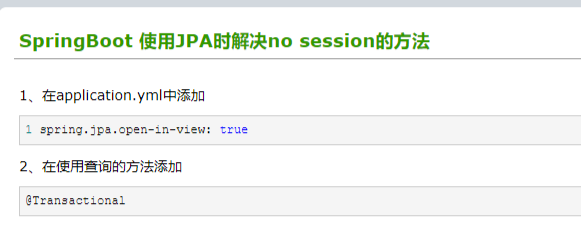
懒加载造成JPA提供的findOne方法和save 方法在关联表查询和保存时报错;所以适合单表操作,多表可以通过自定义方法分别执行
保存和更新需要通过@Query的方法执行
三、@Query注解的使用
1. 一个使用@Query注解的简单例子
@Query(value = "select name,author,price from Book b where b.price>?1 and b.price<?2")
List<Book> findByPriceRange(long price1, long price2);
2. Like表达式
@Query(value = "select name,author,price from Book b where b.name like %:name%")
List<Book> findByNameMatch(@Param("name") String name);
3. 使用Native SQL Query
所谓本地查询,就是使用原生的sql语句(根据数据库的不同,在sql的语法或结构方面可能有所区别)进行查询数据库的操作。
@Query(value = "select * from book b where b.name=?1", nativeQuery = true)
List<Book> findByName(String name);
4. 使用@Param注解注入参数
@Query(value = "select name,author,price from Book b where b.name = :name AND b.author=:author AND b.price=:price")
List<Book> findByNamedParam(@Param("name") String name, @Param("author") String author,
@Param("price") long price);
5. SPEL表达式(使用时请参考最后的补充说明)
'#{#entityName}'值为'Book'对象对应的数据表名称(book)。
public interface BookQueryRepositoryExample extends Repository<Book, Long>{
@Query(value = "select * from #{#entityName} b where b.name=?1", nativeQuery = true)
List<Book> findByName(String name);
}
6. 一个较完整的例子

public interface BookQueryRepositoryExample extends Repository<Book, Long> {
@Query(value = "select * from Book b where b.name=?1", nativeQuery = true)
List<Book> findByName(String name);// 此方法sql将会报错(java.lang.IllegalArgumentException),看出原因了吗,若没看出来,请看下一个例子
@Query(value = "select name,author,price from Book b where b.price>?1 and b.price<?2")
List<Book> findByPriceRange(long price1, long price2);
@Query(value = "select name,author,price from Book b where b.name like %:name%")
List<Book> findByNameMatch(@Param("name") String name);
@Query(value = "select name,author,price from Book b where b.name = :name AND b.author=:author AND b.price=:price")
List<Book> findByNamedParam(@Param("name") String name, @Param("author") String author,
@Param("price") long price);
}
7. 解释例6中错误的原因:
因为指定了nativeQuery = true,即使用原生的sql语句查询;否则表名需为实体类对象。使用java对象'Book'作为表名来查自然是不对的。只需将Book替换为表名book。
@Query(value = "select * from book b where b.name=?1", nativeQuery = true)
List<Book> findByName(String name);
@Param入参有此注解,则sql中用:name接收参数;否则用?1的占位符接收参数且顺序也要一致
8. 有同学提出来了,例子5中用'#{#entityName}'为啥取不到值啊?
先来说一说'#{#entityName}'到底是个啥。从字面来看,'#{#entityName}'不就是实体类的名称么,对,他就是。
实体类Book,使用@Entity注解后,spring会将实体类Book纳入管理。默认'#{#entityName}'的值就是'Book'。
但是如果使用了@Entity(name = "book")来注解实体类Book,此时'#{#entityName}'的值就变成了'book'。
只需要在用@Entity来注解实体类时指定name为此实体类对应的表名。在原生sql语句中,就可以把'#{#entityName}'来作为数据表名使用。
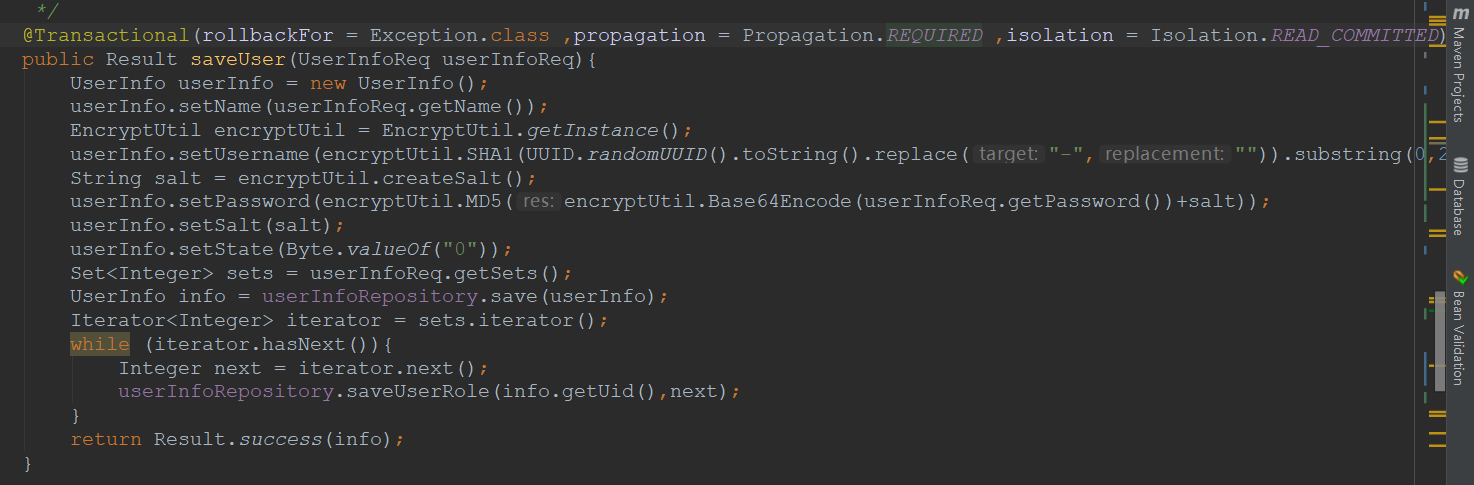
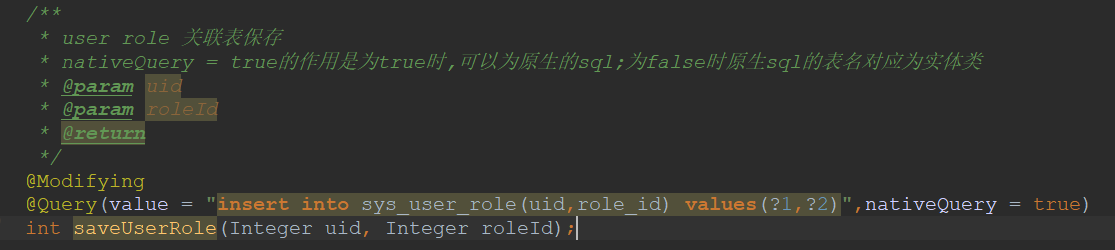
9. @Modifying注解
1、在@Query注解中编写JPQL实现DELETE和UPDATE操作的时候必须加上@modifying注解,以通知Spring Data 这是一个DELETE或UPDATE操作。
2、UPDATE或者DELETE操作需要使用事务,此时需要 定义Service层,在Service层的方法上添加事务操作。
spring-data-JPA repository自定义方法规则的更多相关文章
- spring data jpa方法命名规则
关键字 方法命名 sql where字句 And findByNameAndPwd where name= ? and pwd =? Or findByNameOrSex where name= ? ...
- spring data jpa 使用方法命名规则查询
按照Spring Data JPA 定义的规则,查询方法以findBy开头,涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性首字母需大写.框架在进行方法名解析时,会先把方法名多余的前缀 ...
- Spring Data JPA教程, 第八部分:Adding Functionality to a Repository (未翻译)
The previous part of my tutorial described how you can paginate query results with Spring Data JPA. ...
- 快速搭建springmvc+spring data jpa工程
一.前言 这里简单讲述一下如何快速使用springmvc和spring data jpa搭建后台开发工程,并提供了一个简单的demo作为参考. 二.创建maven工程 http://www.cnblo ...
- 【Spring】Spring Data JPA
原始JDBC操作数据库 传统JDBC方式实现数据库操作 package com.imooc.util; import java.io.InputStream; import java.sql.*; i ...
- spring data jpa(一)
第1章 Spring Data JPA的快速入门 1.1 需求说明 Spring Data JPA完成客户的基本CRUD操作 1.2 搭建Spring Data JPA的开发环境 1. ...
- Spring Data Jpa的四种查询方式
一.调用接口的方式 1.基本介绍 通过调用接口里的方法查询,需要我们自定义的接口继承Spring Data Jpa规定的接口 public interface UserDao extends JpaR ...
- 12 Spring Data JPA:springDataJpa的运行原理以及基本操作(下)
spring data jpaday1:orm思想和hibernate以及jpa的概述和jpa的基本操作 day2:springdatajpa的运行原理 day2:springdatajpa的基本操作 ...
- 黑马程序员spring data jpa 2019年第一版本
第一步首先创建一个maven工程,导入对于的pom依赖 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xs ...
- Spring Data JPA进阶——Specifications和Querydsl
Spring Data JPA进阶--Specifications和Querydsl 本篇介绍一下spring Data JPA中能为数据访问程序的开发带来更多便利的特性,我们知道,Spring Da ...
随机推荐
- POJ2226-Muddy Fields-二分图*
目录 目录 思路: (有任何问题欢迎留言或私聊 && 欢迎交流讨论哦 目录 题意:传送门 原题目描述在最下面. 一个nm的矩阵,有坑有草,可以用1x长度的木板盖住坑,但不能盖到草. ...
- 接口(Interfaces)与反射(reflection) 如何利用字符串驱动不同的事件 动态地导入函数、模块
标准库内部如何实现接口的 package main import ( "fmt" "io" "net/http" "os" ...
- USACO2008 Cow Cars /// oj23323
题目大意: N (1 ≤ N ≤ 50,000)头牛被编号为1-N,牛i可以在M(1 ≤ M ≤ N)条不同的高速路上以Si (1 ≤ Si ≤ 1,000,000) km/h的速度飞驰 为了避免相撞 ...
- Selenium(一)---Selenium的安装和使用
一.前言 最近在帮一个老师爬取网页内容,发现网页是动态加载的,为了拿到全部的网页数据,这里使用到了Selenium.Selenium 是一个用于Web应用程序测试的工具,它可以模拟真实浏览器,支持多种 ...
- 《数据结构与算法分析——C语言描述》ADT实现(NO.02) : 队列(Queue)
第三个结构——队列(Queue) 队列与上次的栈相反,是一种先进先出(FIFO)的线性表.写入时只暴露尾部,读取时只暴露头部. 本次只实现了数组形式的队列.原因是链表形式的队列极为简单,只需要实现简单 ...
- ios position:fixed 上滑下拉抖动
ios position:fixed 上滑下拉抖动 最近呢遇到一个ios的兼容问题,界面是需要一个头底部的固定的效果,用的position:fixed定位布局,写完测试发现安卓手机正常的,按时ios上 ...
- BBS论坛 项目表分析
一.项目表分析 from django.db import models from django.contrib.auth.models import AbstractUser # Create yo ...
- 2019-8-31-C#-字典-Dictionary-的-TryGetValue-与先判断-ContainsKey-然后-Get-的性能对比
title author date CreateTime categories C# 字典 Dictionary 的 TryGetValue 与先判断 ContainsKey 然后 Get 的性能对比 ...
- COGS2355 【HZOI2015】 有标号的DAG计数 II
题面 题目描述 给定一正整数n,对n个点有标号的有向无环图(可以不连通)进行计数,输出答案mod 998244353的结果 输入格式 一个正整数n 输出格式 一个数,表示答案 样例输入 3 样例输出 ...
- COGS2353 【HZOI2015】有标号的DAG计数 I
题面 题目描述 给定一正整数n,对n个点有标号的有向无环图(可以不连通)进行计数,输出答案mod 10007的结果 输入格式 一个正整数n 输出格式 一个数,表示答案 样例输入 3 样例输出 25 提 ...