python——pickle模块的详解
pickle模块详解
该pickle模块实现了用于序列化和反序列化Python对象结构的二进制协议。 “Pickling”是将Python对象层次结构转换为字节流的过程, “unpickling”是反向操作,从而将字节流(来自二进制文件或类似字节的对象)转换回对象层次结构。pickle模块对于错误或恶意构造的数据是不安全的。
pickle协议和JSON(JavaScript Object Notation)的区别 :
1. JSON是一种文本序列化格式(它输出unicode文本,虽然大部分时间它被编码utf-8),而pickle是二进制序列化格式;
2. JSON是人类可读的,而pickle则不是;
3. JSON是可互操作的,并且在Python生态系统之外广泛使用,而pickle是特定于Python的;
默认情况下,JSON只能表示Python内置类型的子集,而不能表示自定义类; pickle可以表示极其庞大的Python类型(其中许多是自动的,通过巧妙地使用Python的内省工具;复杂的案例可以通过实现特定的对象API来解决)。
pickle 数据格式是特定于Python的。它的优点是没有外部标准强加的限制,例如JSON或XDR(不能代表指针共享); 但是这意味着非Python程序可能无法重建pickled Python对象。
默认情况下,pickle数据格式使用相对紧凑的二进制表示。如果您需要最佳尺寸特征,则可以有效地压缩数据。
模块接口
要序列化对象层次结构,只需调用该dumps()函数即可。同样,要对数据流进行反序列化,请调用该loads()函数。但是,如果您想要更多地控制序列化和反序列化,则可以分别创建一个Pickler或一个Unpickler对象。
pickle模块提供以下常量:
pickle.HIGHEST_PROTOCOL-
整数, 可用的最高协议版本。这个值可以作为一个被传递协议的价值函数
dump()和dumps()以及该Pickler构造函数。
pickle.DEFAULT_PROTOCOL-
整数,用于编码的默认协议版本。可能不到
HIGHEST_PROTOCOL。目前,默认协议是3,这是为Python 3设计的新协议。
pickle模块提供以下功能,使酸洗过程更加方便:
pickle.dump(obj,file,protocol = None,*,fix_imports = True )-
将obj对象的编码pickle编码表示写入到文件对象中,相当于
Pickler(file,protocol).dump(obj)可供选择的协议参数是一个整数,指定pickler使用的协议版本,支持的协议是0到
HIGHEST_PROTOCOL。如果未指定,则默认为DEFAULT_PROTOCOL。如果指定为负数,则选择HIGHEST_PROTOCOL。文件参数必须具有接受单个字节的参数写方法。因此,它可以是为二进制写入打开的磁盘文件,
io.BytesIO实例或满足此接口的任何其他自定义对象。如果fix_imports为true且protocol小于3,则pickle将尝试将新的Python 3名称映射到Python 2中使用的旧模块名称,以便使用Python 2可读取pickle数据流。
pickle.dumps(obj,protocol = None,*,fix_imports = True )-
将对象的pickled表示作为
bytes对象返回,而不是将其写入文件。参数protocol和fix_imports具有与in中相同的含义
dump()。
pickle.load(file,*,fix_imports = True,encoding =“ASCII”,errors =“strict” )-
从打开的文件对象 文件中读取pickle对象表示,并返回其中指定的重构对象层次结构。这相当于
Unpickler(file).load()。pickle的协议版本是自动检测的,因此不需要协议参数。超过pickle对象的表示的字节将被忽略。
参数文件必须有两个方法,一个采用整数参数的read()方法和一个不需要参数的readline()方法。两种方法都应返回字节。因此,文件可以是为二进制读取而打开的磁盘文件,
io.BytesIO对象或满足此接口的任何其他自定义对象。可选的关键字参数是fix_imports,encoding和errors,用于控制Python 2生成的pickle流的兼容性支持。如果fix_imports为true,则pickle将尝试将旧的Python 2名称映射到Python 3中使用的新名称。编码和 错误告诉pickle如何解码Python 2编码的8位字符串实例; 这些默认分别为'ASCII'和'strict'。该编码可以是“字节”作为字节对象读取这些8位串的实例。使用
encoding='latin1'所需的取储存NumPy的阵列和实例datetime,date并且time被Python 2解码。
pickle.loads(bytes_object,*,fix_imports = True,encoding =“ASCII”,errors =“strict” )-
从
bytes对象读取pickle对象层次结构并返回其中指定的重构对象层次结构。pickle的协议版本是自动检测的,因此不需要协议参数。超过pickle对象的表示的字节将被忽略。
import numpy as np
import pickle
import io if __name__ == '__main__':
path = 'test'
f = open(path, 'wb')
data = {'a':123, 'b':'ads', 'c':[[1,2],[3,4]]}
pickle.dump(data, f)
f.close() f1 = open(path, 'rb')
data1 = pickle.load(f1)
print(data1)

对于python格式的数据集,我们就可以使用pickle进行加载了,下面与cifar10数据集为例,进行读取和加载:
import numpy as np
import pickle
import random
import matplotlib.pyplot as plt
from PIL import Image path1 = 'D:\\tmp\cifar10_data\cifar-10-batches-py\data_batch_1'
path2 = 'D:\\tmp\cifar10_data\cifar-10-batches-py\data_batch_2'
path3 = 'D:\\tmp\cifar10_data\cifar-10-batches-py\data_batch_3'
path4 = 'D:\\tmp\cifar10_data\cifar-10-batches-py\data_batch_4'
path5 = 'D:\\tmp\cifar10_data\cifar-10-batches-py\data_batch_5' path6 = 'D:\\tmp\cifar10_data\cifar-10-batches-py\\test_batch' if __name__ == '__main__':
with open(path1, 'rb') as fo:
data = pickle.load(fo, encoding='bytes') # print(data[b'batch_label'])
# print(data[b'labels'])
# print(data[b'data'])
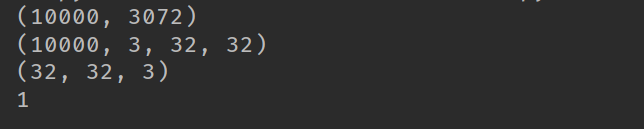
# print(data[b'filenames']) print(data[b'data'].shape) images_batch = np.array(data[b'data'])
images = images_batch.reshape([-1, 3, 32, 32])
print(images.shape)
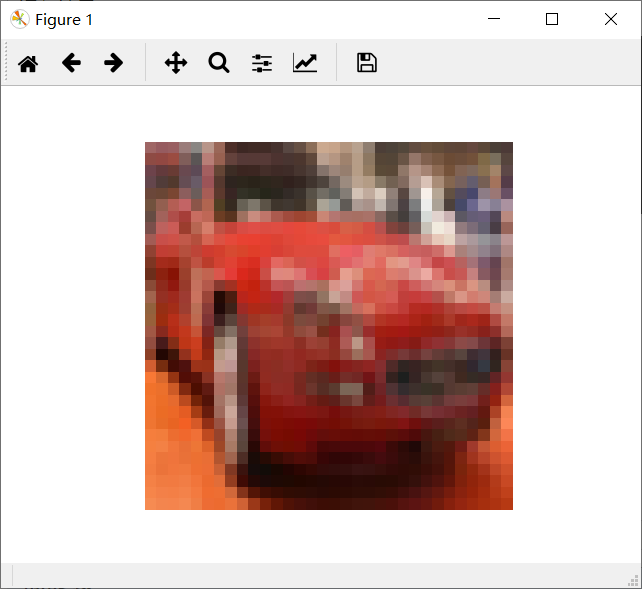
imgs = images[5, :, :, :].reshape([3, 32, 32])
img = np.stack((imgs[0, :, :], imgs[1, :, :], imgs[2, :, :]), 2) print(img.shape) plt.imshow(img)
plt.axis('off')
plt.show()
运行结果:
接下来就可以读取数据进行训练了。
python——pickle模块的详解的更多相关文章
- python之模块datetime详解
# -*- coding: utf-8 -*- #python 27 #xiaodeng #python之模块datetime详解 import datetime #data=datetime.dat ...
- Python Deque 模块使用详解,python中yield的用法详解
Deque模块是Python标准库collections中的一项. 它提供了两端都可以操作的序列, 这意味着, 你可以在序列前后都执行添加或删除. https://blog.csdn.net/qq_3 ...
- python json模块 超级详解
JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式.JSON的数据格式其实就是python里面的字典格式,里面可以包含方括号括起来的数组,也 ...
- python datetime模块参数详解
Python提供了多个内置模块用于操作日期时间,像calendar,time,datetime.time模块,它提供 的接口与C标准库time.h基本一致.相比于time模块,datetime模块的接 ...
- python re模块findall()详解
今天写代码,在写到郑泽的时候遇到了一个坑,这个坑是re模块下的findall()函数. 下面我将结合代码,记录一下 import re string="abcdefg acbdgef abc ...
- python时间模块time详解
在平常的代码中,我们常常需要与时间打交道.在Python中,与时间处理有关的模块就包括:time,datetime以及calendar.这篇文章,主要讲解time模块. 在开始之前,首先要说明这几点: ...
- Python: json模块实例详解
ref:https://www.jianshu.com/p/e29611244810 https://www.cnblogs.com/qq78292959/p/3467937.html https:/ ...
- python子进程模块subprocess详解与应用实例 之三
二.应用实例解析 2.1 subprocess模块的使用 1. subprocess.call >>> subprocess.call(["ls", " ...
- python子进程模块subprocess详解与应用实例 之一
subprocess--子进程管理器 一.subprocess 模块简介 subprocess最早是在2.4版本中引入的. subprocess模块用来生成子进程,并可以通过管道连接它们的输入/输出/ ...
随机推荐
- Python--day66--Django模板语言关于静态文件路径的灵活写法
静态文件路径的灵活写法: 正规的讲解: 静态文件相关 {% static %} {% load static %} <img src="{% static "images/h ...
- IDEA sql自动补全/sql自动提示/sql列名提示
一.启用idea的database插件 File->Settings->Plugins 搜索Database Tools and SQL 选择Enable 启用或者勾选 二.新建Datab ...
- Js中“==”和“===”的区别
从字面上来讲,‘==’代表相等,‘===’代表严格相等. 具体来讲,比较过程如下: 比较过程: ‘==’: 1. 首先判断两个值的类型是否相同,如果相同,进行‘===’判断. 2. ...
- 一图理解vue生命周期
博客园上传图不太清晰,可以查看我的CSDN https://blog.csdn.net/jiaoshuaiai/article/details/90046736 感谢: https://segment ...
- H3C擦除配置
- 2018-2-13-win10-uwp-异步进度条
title author date CreateTime categories win10 uwp 异步进度条 lindexi 2018-2-13 17:23:3 +0800 2018-2-13 17 ...
- [HNOI2019]白兔之舞
memset0 多合一无聊题 mod k=t,并且k是p-1的约数 单位根反演石锤了. 所以直接设f[i]表示走i步的方案数, 然后C(L,i)分配位置,再A^i进行矩乘得到f[i] 变成生成函数F( ...
- CodeForces - 1189 E.Count Pairs (数学)
You are given a prime number pp, nn integers a1,a2,…,ana1,a2,…,an, and an integer kk. Find the numbe ...
- 牛客2018国庆集训 DAY1 D Love Live!(01字典树+启发式合并)
牛客2018国庆集训 DAY1 D Love Live!(01字典树+启发式合并) 题意:给你一颗树,要求找出简单路径上最大权值为1~n每个边权对应的最大异或和 题解: 根据异或的性质我们可以得到 \ ...
- java面试-反射
1.什么是反射?有什么优缺点? 反射就是动态加载对象,并对对象进行剖析.在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法.对于任意一个对象,都能够调用它的任意一个方法.这种动态获取信 ...